[Перевод] Наша проблема c зависимостями
На протяжении десятилетий повторное использование ПО чаще обсуждалось, чем реально имело место. Сегодня ситуация обратная: разработчики каждый день повторно используют чужие программы, в виде программных зависимостей, а сама проблема остаётся практически неизученной.
Мой собственный опыт включает десятилетие работы с внутренним репозиторием Google, где зависимости установлены как приоритетная концепция, а также разработку системы зависимостей для языка программирования Go.
Зависимости несут серьёзные риски, которые слишком часто упускаются из виду. Переход к простому повторному использованию малейших фрагментов ПО произошёл так быстро, что мы ещё не выработали лучшие практики для эффективного выбора и использования зависимостей. Даже для принятия решения, когда они уместны, а когда нет. Цель этой статьи — оценить риски и стимулировать поиск решений в этой области.
В современной разработке зависимость — это дополнительный код, который вызывается из программы. Добавление зависимости позволяет избежать повторения уже сделанной работы: проектирования, написания, тестирования, отладки и поддержки определенной единицы кода. Назовем эту единицу кода пакетом, хотя в некоторых системах вместо пакета используются дргуие термины, такие как библиотека или модуль.
Принятие внешних зависимостей — старая практика: большинство программистов загружали и устанавливали необходимую библиотеку, будь то PCRE или zlib из C, Boost или Qt из C++, JodaTime или Junit из Java. В этих пакетах высококачественный отлаженный код, для создания которого требуется значительный опыт. Если программа нуждается в функциональности такого пакета, гораздо проще вручную загрузить, установить и обновлять пакет, чем разработать эту функциональность с нуля. Но большие первоначальные затраты означают, что ручная реализация повторного использования дорого обходится: крошечные пакеты проще написать самому.
Менеджер зависимостей (иногда называемый диспетчером пакетов) автоматизирует загрузку и установку пакетов зависимостей. Поскольку менеджеры зависимостей упрощают загрузку и установку отдельных пакетов, снижение постоянных затрат делает небольшие пакеты экономичными для публикации и повторного использования.
Например, менеджер зависимостей Node.js под навзанием NPM предоставляет доступ к более чем 750 000 пакетов. Один из них, escape-string-regexp, содержит единственную функцию, которая экранирует операторы регулярных выражений по входным данным. Вся реализация:
var matchOperatorsRe = /[|\\{}()[\]^$+*?.]/g;
module.exports = function (str) {
if (typeof str !== 'string') {
throw new TypeError('Expected a string');
}
return str.replace(matchOperatorsRe, '\\$&');
};
До появления менеджеров зависимостей невозможно было представить публикацию восьмистрочной библиотеки: слишком много накладных расходов и слишком мало пользы. Но NPM свёл накладные расходы почти к нулю, в результате чего почти тривиальная функциональность может быть упакована и повторно использована. В конце января 2019 года зависимость escape-string-regexp встроена почти в тысячу других пакетов NPM, не говоря уже о всех пакетах, которые разработчики пишут для собственного использования и не публикуют в открытом доступе.
Теперь менеджеры зависимостей появились практически для каждого языка программирования. Maven Central (Java), Nuget (.NET), Packagist (PHP), PyPI (Python) и RubyGems (Ruby) — в каждом из них более 100 000 пакетов. Появление такого распространённого повторного использования мелких пакетов — одно из крупнейших изменений в разработке программного обеспечения за последние два десятилетия. И если мы не будем более осторожны, это приведёт к серьёзным проблемам.
В контексте данного обсуждения пакет — это код, загружаемый из интернета. Добавление зависимости поручает работу по разработке этого кода — проектирование, написание, тестирование, отладку и поддержку — кому-то другому в интернете, кого вы обычно не знаете. Используя этот код, вы подвергаете собственную программу воздействию всех сбоев и недостатков зависимости. Выполнение вашего софта теперь буквально зависит от кода незнакомца из интернета. Если сформулировать таким образом, всё звучит очень небезопасно. Зачем кому-то вообще соглашаться на такое?
Мы соглашаемся, потому что это легко, потому что всё вроде работает, потому что все остальные тоже так делают, и самое главное — потому что это кажется естественным продолжением вековой устоявшейся практики. Но есть важная разница, которую мы игнорируем.
Десятилетия назад большинство разработчиков тоже доверяли другим писать программы, от которых они зависели, такие как операционные системы и компиляторы. Это программное обеспечение покупалось из известных источников, часто с каким-то соглашением о поддержке. Тут ещё остаётся место для ошибок или откровенного вредительства. Но мы хотя бы знали, с кем имеем дело и, как правило, могли использовать коммерческие или правовые меры воздействия.
Феномен ПО с открытыми исходниками, которые распространяются бесплатно через интернет, во многом вытеснил старые практики закупки ПО. Когда повторное использование было ещё трудным, мало проектов внедрило такие зависимости. Хотя их лицензии обычно отказывались от каких-либо «гарантий коммерческой ценности и пригодности для конкретной цели», проекты построили себе хорошую репутацию. Пользователи в значительной степени учитывали эту репутацию в принятии своих решений. Вместо коммерческих и юридических мер воздействия пришла репутационная поддержка. Многие распространённые пакеты той эпохи по-прежнему пользуются хорошей репутацией: например, BLAS (опубликован в 1979), Netlib (1987), libjpeg (1991), LAPACK (1992), HP STL (1994) и zlib (1995).
Пакетные менеджеры свели модель повторного использования кода до предельной простоты: теперь разработчики могут совместно использовать код с точностью до отдельных функций в десятки строк. Это большое техническое достижение. Существует бесчисленное множество доступных пакетов, и проект может включать в себя большое их количество, но коммерческие, юридические или репутационные механизмы доверия к коду остались в прошлом. Мы доверяем большему количеству кода, хотя причин для доверия стало меньше.
Стоимость принятия плохой зависимости можно рассматривать как сумму всех возможных плохих исходов на серии из цены каждого плохого исхода, умноженной на его вероятность (риск).
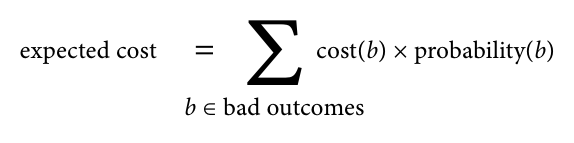
Цена плохого исхода зависит от контекста, в котором используется зависимость. На одном конце спектра находится личный хобби-проект, где цена большинства плохих исходов близка к нулю: вы просто развлекаетесь, ошибки не имеют никакого реального влияния, кроме как чуть больше потраченного времени, а их отладка может даже приносить удовольствие. Таким образом, вероятность риска почти не имеет значения: она умножается на ноль. На другом конце спектра — производственный софт, который должен поддерживаться годами. Здесь стоимость зависимости может оказаться очень высокой: серверы могут упасть, конфиденциальные данные могут быть разглашены, клиенты могут пострадать, компании вообще могут обанкротиться. В продакшне гораздо важнее оценить и максимально снизить риск серьёзного отказа.
Независимо от ожидаемой цены, есть некоторые подходы для оценки и снижения рисков добавления зависимостей. Вполне вероятно, что пакетные менеджеры следует оптимизировать для снижения этих рисков, в то время как они до настоящего времени уделяли основное внимание сокращению затрат на загрузку и установку.
Вы бы не наняли разработчика, о котором никогда не слышали и ничего не знаете. Сначала вы узнаете что-то о нём: проверите ссылки, проведёте собеседование и так далее. Прежде чем зависеть от пакета, который вы нашли в интернете, также разумно немного узнать об этом пакете.
Базовая проверка может дать представление о вероятности возникновения проблем при попытке использования этого кода. Если в ходе проверки обнаружатся незначительные проблемы, вы можете принять меры по их устранению. Если проверка выявит серьёзные проблемы, возможно, лучше не использовать пакет: возможно, вы найдёте более подходящий или, может, нужно разработать его самостоятельно. Помните, что пакеты с открытым исходным кодом публикуются авторами в надежде, что они будут полезны, но без гарантии удобства использования или поддержки. При сбое в продакшне именно вам придётся его отлаживать. Как предупреждала первая Стандартная общественная лицензия GNU, «весь риск, связанный с качеством и производительностью программы, лежит на вас. Если программа окажется дефектной, вы берёте на себя расходы на всё необходимое обслуживание, ремонт или исправление».
Дальше изложим некоторые соображения по проверке пакета и принятии решения о том, следует ли от него зависеть.
Дизайн
Документация пакета ясна? У API чёткий дизайн? Если авторы могут хорошо объяснить API и дизайн человеку, то это увеличивает вероятность, что они также хорошо объяснили реализацию компьютеру в исходном коде. Написание кода для чёткого, хорошо продуманного API проще, быстрее и, вероятно, менее подвержено ошибкам. Задокументировали ли авторы, чего они ожидают от клиентского кода, для совместимости с будущими обновлениями? (Среди примеров — документы совместимости C++ и Go).
Качество кода
Хорошо ли написан код? Прочтите некоторые фрагменты. Похоже ли, что авторы осторожны, добросовестны и последовательны? Похож ли он на код, который вы хотите отладить? Возможно, вам придётся это делать.
Разработайте собственные систематические способы проверки качества кода. Что-то простое, например, компиляция на C или C++ с включенными важными предупреждениями компилятора (например, -Wall), может дать представление, насколько серьёзно разработчики поработали, чтобы избежать различных неопределённых поведений. Последние языки, такие как Go, Rust и Swift, используют ключевое слово unsafe для обозначения кода, который нарушает систему типов; посмотрите, сколько там небезопасного кода. Также полезны более продвинутые семантические инструменты, такие как Infer или SpotBugs. Линтеры менее полезны: следует игнорировать стандартные советы по таким темам, как стиль скобок, и сосредоточиться на семантических проблемах.
Не забывайте о методах разработки, с которыми вы, возможно, не знакомы. Например, библиотека SQLite поставляется как один файл с 200 000 кода и заголовком на 11 000 строк — в результате слияния множества файлов. Сам размер этих файлов сразу поднимает красный флаг, но более тщательное исследование приведёт к фактическому исходному коду разработки: традиционному файловому дереву с более чем сотней исходных файлов на C, тестами и скриптами поддержки. Получается, что однофайловый дистрибутив строится автоматически из оригинальных исходников: так проще для конечных пользователей, особенно тех, у кого нет менеджеров зависимостей. (Скомпилированный код также быстрее работает, поскольку компилятор видит больше возможностей оптимизации).
Тестирование
Есть ли в коде тесты? Вы можете ими управлять? Они проходят? Тесты устанавливают, что основная функциональность кода верна, и сигнализируют о том, что разработчик серьёзно старается сохранить её. Например, дерево разработки SQLite содержит невероятно подробный набор тестов с более чем 30 000 отдельных тестовых случаев. Есть документация для разработчиков, объясняющая стратегию тестирования. С другой стороны, если тестов мало или нет вообще, или если тесты не проходят, это серьёзный красный флаг: будущие изменения в пакете, вероятно, приведут к регрессиям, которые можно было легко обнаружить. Если вы настаиваете на тестах в своём коде (так ведь?), то должны обеспечить тесты для кода, который передаёте другим.
Предполагая, что тесты существуют, запускаются и проходят, то можете собрать дополнительную информацию, запустив инструменты для анализа покрытия кода, обнаружения состояний гонки, проверки выделения памяти и обнаружения утечек памяти.
Отладка
Найдите баг-трекер этого пакета. Много ли открытых сообщений об ошибках? Как давно они открыты? Сколько ошибок исправлено? Есть ли баги, исправленные в последнее время? Если там много открытых вопросов о настоящих багов, особенно не закрытых в течение длительного времени, это плохой знак. С другой стороны, если ошибки редко встречаются и быстро исправляются, это здорово.
Поддержка
Посмотрите на историю коммитов. Как долго код активно поддерживается? Сейчас он активно поддерживается? Пакеты, которые активно поддерживались в течение длительного периода времени, скорее всего, будут продолжать поддерживаться. Сколько человек работает над пакетом? Многие пакеты — это личные проекты, которые разработчики создают для развлечения в свободное время. Другие — результат тысяч часов работы группы платных разработчиков. В общем, у пакетов второго типа обычно быстрее исправляют ошибки, стабильно внедряют новые функции и в целом они лучше поддерживаются.
С другой стороны, некоторый код действительно «идеален». Например, escape-string-regexp из NPM, может, больше никогда не понадобится изменять.
Использование
Сколько пакетов зависит от этого кода? Пакетные менеджеры часто дают такую статистику, или можно посмотреть в интернете, как часто другие разработчики упоминают этот пакет. Большее количество пользователей означает хотя бы то, что у многих код работает достаточно хорошо, а ошибки в нём будут замечать оперативнее. Широкое использование также является частичной гарантией продолжения обслуживания: если широко используемый пакет теряет мейнтейнера, то очень вероятно, что его роль возьмёт на себя заинтересованный пользователь.
Например, невероятно широко используются библиотеки вроде PCRE, Boost или JUnit. Это делает более вероятным — хотя, конечно, не гарантирует — что ошибки, с которыми вы могли столкнуться, уже исправлены, потому что другие столкнулись с ними раньше вас.
Безопасность
Будет ли этот пакет работать с небезопасными входными данными? Если да, то насколько он устойчив к вредоносным данным? Есть ли у него баги, которые упоминаются в Национальной базе уязвимостей (NVD)?
Например, когда в 2006 году мы с Джеффом Дином начали работать над поиском по коду Google Code Search (grep по публичным базам кода), очевидным выбором казалась популярная библиотека регулярных выражений PCRE. Однако в разговоре с командой безопасности Google мы узнали, что у PCRE есть длинная история проблем, таких как переполнение буфера, особенно в парсере. Мы сами убедились в этом, поискав PCRE в NVD. Это открытие не сразу заставило нас отказаться от PCRE, но заставило более тщательно подумать о тестировании и изоляции.
Лицензирование
Правильно ли лицензирован код? У него вообще есть лицензия? Приемлема ли лицензия для вашего проекта или компании? Удивительная часть проектов на GitHub не имеют чёткой лицензии. Ваш проект или компания могут наложить дополнительные ограничения на лицензии зависимостей. Например, Google запрещает использовать код под лицензиями типа AGPL (слишком жёсткие) и типа WTFPL (слишком расплывчатые).
Зависимости
Имеет ли у этого пакета собственные зависимости? Недостатки в косвенных зависимостях так же вредны, как и недостатки в прямых зависимостях. Пакетные менеджеры могут перечислить все транзитивные зависимости данного пакета, и каждый из них в идеале следует проверить, как описано в этом разделе. Пакет со многими зависимостями потребует немалой работы.
Многие разработчики никогда не смотрели на полный список транзитивных зависимостей своего кода и не знают, от чего они зависят. Например, в марте 2016 года сообщество пользователей NPM обнаружило, что многие популярные проекты — включая Babel, Ember и React — косвенно зависят от крошечного пакета под названием left-pad из 8-строчной функции. Они обнаружили это, когда автор left-pad удалил пакет из NPM, непреднамеренно сломав большинство сборок пользователей Node.js. И left-pad вряд ли является исключительным в этом отношении. Например, 30% из 750 000 пакетов в NPM зависят — по крайней мере косвенно — от escape-string-regexp. Адаптируя наблюдение Лесли Лэмпорта о распределённых системах, пакетный менеджер легко создаёт ситуацию, где сбой пакета, о существовании которого вы даже не знали, может сделать ваш собственный код непригодным для использования.
Процесс проверки должен включать запуск собственных тестов пакета. Если пакет прошел проверку и вы решили сделать свой проект зависимым от него, следующим шагом должно быть написание новых тестов, ориентированных на функциональность конкретно вашего приложения. Эти тесты часто начинаются как короткие автономные программы, чтобы убедиться, что вы можете понять API пакета и что он делает то, что вы думаете (если вы не можете понять или он не делает что надо, немедленно остановитесь!). Затем стоит приложить дополнительные усилия, чтобы превратить эти программы в автоматические тесты, которые будут запускаться с новыми версиями пакета. Если вы нашли ошибку и у вас есть потенциальное исправление, вы сможете легко перезапустить эти тесты для конкретного проекта и убедиться, что исправление не сломало ничего другого.
Особое внимание стоит уделить проблемным областям, выявленным во время базового обзора. Для Code Search из прошлого опыта мы знали, что PCRE иногда требуется много времени для выполнения определённых регулярных выражений. Наш первоначальный план состоял в том, чтобы сделать отдельные пулы потоков для «простых» и «сложных» регулярных выражений. Одним из первых тестов стал эталон, который сравнивал pcregrep с несколькими другими реализациями grep. Когда мы обнаружили, что для одного базового тестового случая pcregrep оказался в 70 раз медленнее, чем самый быстрый grep, мы начали переосмысливать наш план использования PCRE. Несмотря на то, что мы в конечном итоге полностью отказались от PCRE, этот тест остаётся в нашей базе кода и сегодня.
Зависимость от пакета — это решение, от которого вы в будущем можете отказаться. Возможно, обновления уведут пакет в новом направлении. Возможно, будут найдены серьёзные проблемы безопасности. Возможно, появится лучший вариант. По всем этим причинам стоит приложить усилия, чтобы упростить миграцию проекта на новую зависимость.
Если пакет вызывается из многих мест в исходном коде проекта, для перехода на новую зависимость потребуется внести изменения во все эти различные места. Хуже того, если пакет представлен в API вашего собственного проекта, то миграция на новую зависимость потребует внесения изменений в весь код, вызывающий ваш API, а это уже может оказаться вне вашего контроля. Чтобы избежать таких затрат, имеет смысл определить собственный интерфейс вместе с тонкой обёрткой, реализующей этот интерфейс с помощью зависимости. Обратите внимание, что обёртка должна включать только то, что требуется проекту от зависимости, а не всё, что предлагает зависимость. В идеале это позволяет позже заменить другую, одинаково подходящую зависимость, изменив только враппер. Миграция тестов для каждого проекта на использование нового интерфейса проверяет реализацию интерфейса и обёртки, а также упрощает тестирование любых потенциальных замен для зависимости.
Для Code Search мы разработали абстрактный класс Regexp, который определяет интерфейс Code Search, необходимый из любого механизма регулярных выражений. Затем написали тонкую обёртку вокруг PCRE, реализующую этот интерфейс. Такой метод облегчил тестирование альтернативных библиотек и предотвратил случайное внедрие знания внутренних компонентов PCRE в остальное дерево исходных текстов. Это, в свою очередь, гарантирует, что при необходимости будет легко переключиться на другую зависимость.
Также может быть целесообразно изолировать зависимость во время выполнения, чтобы ограничить возможный ущерб, вызванный ошибками в ней. Например, Google Chrome позволяет пользователям добавлять в браузер зависимости — код расширений. Когда Chrome впервые запустили в 2008 году, он представил критическую функцию (теперь стандартную во всех браузерах) изоляции каждого расширения в песочнице, работающей в отдельном процессе операционной системы. Потенциальный эксплоит в плохо написанном расширении не имел автоматического доступа ко всей памяти самого браузера и не мог совершить неуместных системных вызовов. Для Code Search, пока мы не отбросили PCRE полностью, план состоял в том, чтобы по крайней мере изолировать парсер PCRE в аналогичной песочнице. Сегодня ещё одним вариантом будет лёгкая песочница на основе гипервизора, такая как gVisor. Изоляция зависимостей снижает связанные риски выполнения этого кода.
Даже с этими примерами и другими готовыми опциями изоляция подозрительного кода во время выполнения по-прежнему слишком сложна и редко выполняется. Истинная изоляция потребует полностью безопасного для памяти языка, без аварийного выхода в нетипизированный код. Это сложные не только в полностью небезопасных языках, таких как C и C++, но и в языках, которые обеспечивают ограничивают небезопасные операции, такие как Java при включении JNI, или как Go, Rust и Swift, при включении своих функций unsafe. Даже в таком безопасном для памяти языке, как JavaScript, код часто имеет доступ к гораздо большему, чем ему нужно. В ноябре 2018 г. оказалось, что последняя версия пакета npm event-stream (функциональный потоковый API для событий JavaScript) содержит запутанный вредоносный код, добавленный два с половиной месяца назад. Код собирал биткоин-кошельки у пользователей мобильного приложения Copay, получал доступ к системным ресурсам, совершенно не связанным с обработкой потоков событий. Одним из многих возможных способов защиты от такого рода проблем была бы лучшая изоляция зависимостей.
Если зависимость кажется слишком рискованной и вы не можете её изолировать, лучшим вариантом может быть полный отказ от неё или хотя бы исключение наиболее проблемных частей.
Например, когда мы лучше поняли риски PCRE, наш план для Google Code Search превратился из «использовать библиотеку PCRE напрямую» в «использовать PCRE, но поместить парсер в песочницу», потом в «написать новый парсер регулярных выражений, но сохранить движок PCRE», затем в «написать новый парсер и подключить его к другому, более эффективному движку с открытым исходным кодом». Позже мы с Джеффом Дином переписали также и движок, так что никаких зависимостей не осталось, и мы открыли результат: RE2.
Если вам нужна лишь небольшая часть зависимости, проще всего сделать копию того, что вам нужно (конечно, сохраняя соответствующие авторские права и другие юридические уведомления). Вы берёте на себя ответственность за исправление ошибок, техническое обслуживание и т. д., Но вы также полностью изолированы от более крупных рисков. В сообществе разработчиков Go есть поговорка на этот счёт: «Немного копирования лучше, чем немного зависимости».
Долгое время общепринятой мудростью в программном обеспечении было: «Если работает, ничего не трогай». Обновление несёт риск введения новых ошибок; без соответствующей награды — если вам не нужна новая функция, зачем рисковать? Такой подход игнорирует два аспекта. Во-первых, это стоимость постепенного обновления. В программном обеспечении сложность внесения изменений в код не масштабируется линейно: десять маленьких изменений — это меньше работы и легче, чем одно соответствующее большое изменение. Во-вторых, трудность обнаружения уже исправленных ошибок. Особенно в контексте безопасности, где известные ошибки активно эксплуатируются, каждый день без обновления повышает риски, что злоумышленники могут воспользоваться багов в старом коде.
Например, рассмотрим историю компании Equifax от 2017 года, о которой подробно рассказали руководители в показаниях перед Конгрессом. 7 марта была раскрыта новая уязвимость в Apache Struts и выпущена исправленная версия. 8 марта Equifax получил уведомление US-CERT о необходимости обновления любых видов использования Apache Struts. Equifax запустила сканирование исходного кода и сети 9 и 15 марта соответственно; ни одно сканирование не обнаружило уязвимых веб-серверов, открытых в интернет. 13 мая злоумышленники нашла такие сервера, которые специалисты Equifax не обнаружили. Они использовали уязвимость Apache Struts для взлома сети Equifax, а в течение следующих двух месяцев украли подробную личную и финансовую информацию о 148 миллионах человек. Наконец, 29 июля Equifax заметила взлом и публично объявила о нём 4 сентября. К концу сентября исполнительный директор Equifax, а также CIO и CSO подали в отставку, и началось расследование в Конгрессе.
Опыт Equifax приводит к тому, что хотя менеджеры пакетов знают версии, которые они используют во время сборки, вам нужны другие механизмы для отслеживания этой информации в процессе развёртывания в продакшне. Для языка Go мы экспериментируем с автоматическим включением манифеста версии в каждый двоичный файл, чтобы процессы развёртывания могли сканировать двоичные файлы на наличие зависимостей, требующих обновления. Go также делает эту информацию доступной во время выполнения, так что серверы могут обращаться к базам данных известных ошибок и самостоятельно сообщать в систему мониторинга, когда они нуждаются в обновлении.
Быстрое обновление важно, но обновление означает добавление нового кода в проект, что должно означать обновление оценки рисков использования зависимости на основе новой версии. Как минимум, вы хотите просмотреть различия, показывающие изменения, вносимые из текущей версии в обновлённые версии, или, по крайней мере, прочитать заметки о выпуске, чтобы определить наиболее вероятные проблемные области в обновлённом коде. Если изменяется много кода, так что различия трудно понять, это также информация, которую можно включить в обновление оценки риска.
Кроме того, необходимо повторно выполнить тесты, написанные специально для проекта, чтобы убедиться, что обновлённый пакет по крайней мере так же подходит для проекта, как и более ранняя версия. Также имеет смысл повторно запустить собственные тесты пакета. Если у пакета собственные зависимости, вполне возможно, что конфигурация проекта использует другие версии этих зависимостей (более старые или более новые), чем те, которые используют авторы пакета. Выполнение собственных тестов пакета позволяет быстро выявить проблемы, характерные для конфигурации.
Опять же, обновления не должны быть полностью автоматическими. Перед развёртыванием обновленных версий необходимо убедиться, что они подходят для вашей среды.
Если процесс обновления включает повторное выполнение уже написанных интеграционных и квалификационных тестов, то в большинстве случаев задержка обновления более рискованна, чем быстрое обновление.
Окно для критических обновлений безопасности особенно маленькое. После взлома Equifax группы судебной безопасности обнаружили доказательства, что злоумышленники (возможно, разные) успешно воспользовались уязвимостью Apache Struts на затронутых серверах 10 марта, всего через три дня после того, как она была публично раскрыта. Но они запустили там только одну команду whoami.
Даже после всего этого работа не закончена. Важно продолжать следить за зависимостями и в каких-то случаях даже отказаться от них.
Во-первых, убедитесь, что вы продолжаете использовать конкретные версии пакетов. Большинство пакетных менеджеров теперь позволяют легко или даже автоматически записывать криптографический хэш ожидаемого исходного кода для данной версии пакета, а затем проверять этот хэш при повторной загрузке пакета на другой компьютер или в тестовой среде. Это гарантирует, что в билде будет использоваться тот же исходный код зависимостей, который вы проверяли и тестировали. Такого рода проверки помешали злоумышленнику event-stream, автоматически внедрить вредоносный код в уже выпущенную версию 3.3.5. Вместо этого злоумышленник ему пришлось создать новую версию 3.3.6 и ждать, что люди обновятся (не просматривая внимательно изменения).
Также важно следить за появлением новых косвенных зависимостей: обновления могут легко внедрить новые пакеты, от которых теперь зависит успех вашего проекта. Они также заслуживают вашего внимания. В случае event-stream вредоносный код был скрыт в другом пакете flatMap-stream, который в новой версии event-stream добавился в качестве новой зависимости.
Ползучие зависимости также могут влиять на размер проекта. Во время разработки Google Sawzall — языка JIT-обработки логов — авторы в разное время обнаружили, что основной бинарник интерпретатора содержит не только JIT Sawzall, но и (неиспользуемые) интерпретаторы PostScript, Python и JavaScript. Каждый раз виновником оказывались неиспользуемые зависимости, объявленные какой-то библиотекой Sawzall, в сочетании с тем, что система сборки Google полностью автоматически использовала новую зависимость. Вот почему компилятор Go выдаёт ошибку при импорте неиспользуемого пакета.
Обновление — естественное время для пересмотра решения об использовании изменяющейся зависимости. Также важно периодически пересматривать любую зависимость, которая не меняется. Кажется ли правдоподобным, что нет проблем с безопасностью или других ошибок для исправления? Проект заброшен? Возможно, пришло время планировать замену этой зависимости.
Ещё важно перепроверить журнал безопасности каждой зависимости. Например, Apache Struts раскрыл серьёзные уязвимости удалённого выполнения кода в 2016, 2017 и 2018 годах. Даже если у вас много серверов, которые его запускают и быстро обновляют, такой послужной список наводит на мысль, а стоит ли его вообще использовать.
Эпоха повторного использования программного обеспечения, наконец, наступила, и я не хочу преуменьшать преимущества: это принесло чрезвычайно позитивную трансформацию разработчикам. Тем не менее, мы приняли эту трансформацию, не полностью продумав потенциальные последствия. Прежние причины доверять зависимостям теряют актуальность в то самое время, когда у нас больше зависимостей, чем когда-либо.
Критический анализ конкретных зависимостей, который я описал в этой статье, представляет собой значительный объём работы и остаётся скорее исключением, чем правилом. Но я сомневаюсь, что есть разработчики, которые действительно прилагают усилия, чтобы сделать это для каждой возможной новой зависимости. Я сделал только часть этой работы для части собственных зависимостей. В основном всё решение сводится к следующему: «давайте посмотрим, что произойдёт». Слишком часто что-то большее кажется слишком большим усилием.
Но атаки Copay и Equifax являются чёткими предупреждениями о реальных проблемах в том, как мы сегодня используем зависимости программного обеспечения. Мы не должны игнорировать предупреждения. Предлагаю три общие рекомендации.
- Распознать проблему. Надеюсь, эта статья убедила вас, что есть проблема, которую стоит решить. Нам нужно много людей, чтобы сосредоточить значительные усилия на её решении.
- Установить лучшие практики на сегодняшний день. Мы должны установить лучшие практики для управления зависимостями, используя то, что доступно сегодня. Это означает разработку процессов, которые оценивают, уменьшают и отслеживают риск начиная с первоначального решения о принятии зависимости до её использования в продакшне. На самом деле, как некоторые инженеры специализируются на тестировании, так и нам могут понадобиться инженеры, специализирующиеся на управлении зависимостями.
- Разработать лучшую технологию для зависимостей. Пакетные менеджеры существенно снизили стоимость загрузки и установки зависимостей. Будущие усилия в области развития следует сосредоточить на сокращении расходов на оценку и обслуживание зависимостей. Например, каталоги пакетов могут найти дополнительные способы предоставить разработчикам возможность поделиться своими результатами. Инструменты сборки должны, по крайней мере, упростить выполнение собственных тестов пакета. Более агрессивно, инструменты сборки и системы управления пакетами могут также работать вместе, чтобы позволить авторам пакетов тестировать новые изменения на всех общедоступных клиентах их API. Языки должны обеспечить простые способы изоляции подозрительного пакета.
Есть много хорошего программного обеспечения. Давайте вместе поработаем и выясним, как его безопасно использовать.
