Разрабатываем систему мониторинга на 55000 видео-потоков RTP
Добрый день!
Недавно прочитал очень интересную статью про обработку 50 гигабит/с на сервере и вспомнил, что у меня в черновиках лежит статья про то, как мы год назад разрабатывали систему мониторинга видео-потоков с общим объёмом трафика до 100 Гбит/с. Ещё раз «вычитал» её и решил представить на суд разработчиков. Статья больше посвящена анализу протоколов и поиску архитектурного решения, нежели тюнингу всевозможных подсистем linux«а, потому что мы пошли по пути распределения нагрузки между сервером и сетевыми пробниками, которые подключаются к транспортным потокам 10 Gigabit Ethernet.

Если интересно, как мы смогли измерить характеристики сетевых потоков от 55 тысяч видео-камер, прошу под кат.
В этой статье я планирую рассказать про:
- то, что является объектом мониторинга, как к нему подключаться;
- параметры видео-потоков, которые нужно измерять;
- нюансы… понятное дело: в каждой задаче есть нюансы;
- муки выбора подходящей архитектуры;
- RTP-протокол и его свойства, позволяющие приёмнику анализировать качество потока;
- идентификацию RTP-пакетов в магистральном трафике;
- итоговую архитектуру системы;
- преимущества и недостатки выбранного решения.
Что мониторим?
Мониторить нужно несколько 10G транспортных Ethernet-линков, по которым передаются десятки тысяч видео-потоков. Первая инсталляция — 22 тысячи камер, вторая — 55 тысяч. Средний битрейт камеры — 1 Мегабит/с. Есть камеры с 2 мегабит/с и с 500 килобит/с.
Видео передаётся по протоколам RTP-over-UDP и RTP-over-RTSP-over-TCP, а установка соединений происходит по RTSP. При этом с одного IP-адреса может идти как один поток (один адрес — одна камера), так и несколько (один адрес — один encoder, то есть от 1 до 16 потоков).
Подключение к ethernet-линкам возможно только в режиме мониторинга, при помощи оптических ответвителей, другими словами — в неинтрузивном режиме. Такое подключение предпочтительнее, поскольку в этом случае трафик не проходит сквозь оборудование и, следовательно, оно никак не может повлиять на качество предоставляемых услуг (падение уровня оптического сигнала на сплиттере считаем совсем незначительным). Для операторов это крайне важный аргумент. А для разработчиков из такого подключения следует немаловажный нюанс — за потоками всегда придётся наблюдать «со стороны», т.к. передавать в сеть пакеты нельзя (например, нельзя послать пинг и получить ответ). Значит, работать придётся в условиях недостатка информации.
А что измеряем?
Оценка качества потока строится на базе анализа заголовков транспортного протокола RTP и заголовков h.264 NAL-unit«ов. Качество картинки не измеряется. Вместо этого анализируется транспортный поток видео-кадров по следующим критериям:
- пакеты не теряются;
- пакеты не меняют свой порядок;
- количество кадров соответствует SLA;
- битрейт соответствует SLA;
- пакетный джиттер в норме;
- и, наконец, что камера вообще передаёт пакеты.
RTP может «идти» как поверх UDP, так и (преимущественно, в 90% случаев) поверх RTSP/TCP в режиме «Interleaving data». Да-да, несмотря на то, что в RFC по RTSP сказано, что режим Interleaving Data лучше не использовать — см. 10.12, rfc2326).
Итого: система мониторинга представляет собой комплекс, подключаемый в неинтрузивном режиме к n-ному количеству 10-гигабитных линков Ethernet, который непрерывно «наблюдает» за передачей всех присутствующих в трафике видео-потоков RTP и проводит измерения с определённым интервалом времени, чтобы потом сохранить их в базу. По данным из базы регулярно строятся отчёты для всех камер.
И что тут сложного?
В процессе поиска решения сразу зафиксировали несколько проблем:
- Неинтрузивное подключение. Система мониторинга подключается к уже работающим каналам, в которых большинство соединений (по RTSP) уже установлены, сервер и клиент уже знают, по каким портам происходит обмен, но нам это заранее неизвестно. Well-known порт есть только для протокола RTSP, а вот UDP-потоки могут идти по произвольным портам (к тому же, оказалось, что нередко они нарушают требование SHOULD чётности/нечётности портов, см. rfc3550). Как определить, что тот или иной пакет от какого-то IP-адреса принадлежит к видео-потоку? Например, протокол BitTorrent ведёт себя аналогично — на этапе установки соединения клиент и сервер договариваются о портах, а потом весь UDP-трафик выглядит как «просто битовый поток».
- В подключенных линках могут быть не только видео-потоки. Могут быть и HTTP, и BitTorrent, и SSH, и любые другие протоколы, которыми мы сегодня пользуемся. Следовательно, система должна правильно идентифицировать видео-потоки, чтобы отделить их от остального трафика. Как это проделать в реальном времени с 8-ю десяти-гигабитными линками? Они, конечно, обычно не заполняются на 100%, поэтому суммарно трафика будет не 80 гигабит/с, а примерно 50–60, но и это не так уж мало.
- Масштабируемость. Там, где уже много видео-потоков, их может стать ещё больше, поскольку видео-наблюдение уже давно оправдало себя как эффективный инструмент. Это говорит о том, что должен быть запас по производительности и резерв по линкам.
Ищем подходящее решение…
Мы, естественно, стремились максимально использовать собственный опыт. К моменту принятия решения у нас уже была реализация обработки ethernet-пакетов на FPGA-powered девайсе Беркут-МХ (проще — MX). С помощью Беркут-MX мы умели получать из заголовков Ethernet-пакетов нужные поля для анализа. Опыта обработки такого объёма трафика средствами «обычных» серверов у нас не было, увы, поэтому на подобное решение смотрели с некоторой опаской…
Казалось бы, оставалось просто применить метод к RTP-пакетам и золотой ключик был бы у нас в кармане, но MX умеет только обрабатывать трафик, в него не заложены возможности учёта и хранения статистики. Для хранения найденных соединений (комбинаций IP-IP-порт-порт) в ПЛИС не хватит памяти, ведь в 2×10-гигабитном линке, заходящем на вход, может быть около 15 тысяч видео-потоков, и по каждому нужно «помнить» количество принятых пакетов, количество потерянных пакетов и так далее… Более того, поиск на такой скорости и по такому количеству данных при условии обработки без потерь становится нетривиальной задачей.
Чтобы найти решение, пришлось «копнуть глубже» и разобраться в том, по каким алгоритмам мы будем измерять качество и идентифицировать видео-потоки.
Что можно измерить по полям RTP-пакета?
Формат пакета RTP описан в rfc3550.

Из описания видно, что с точки зрения измерений качества в RTP-пакете нас интересуют следующие поля:
- sequence number — 16-ти разрядный счётчик, увеличивающийся с каждым отправленным пакетом;
- timestamp — временная метка, для h.264 величина дискрета составляет 1/90000 c (т.е. соответствует частоте 90 КГц);
- Marker-бит. В rfc3550 в общем виде описано, что этот бит предназначен для обозначения «значимых» событий, а по факту этим битом чаще всего камеры маркируют начало видео-кадра и специализированные пакеты с SPS/PPS-информацией.
Вполне очевидно, что sequence number позволяет определить следующие параметры потока:
- потери пакетов (frame loss);
- повторную посылку пакета (duplicate);
- изменение порядка прихода (reordering);
- перезагрузку камеры, при большом «разрыве» в последовательности.
Timestamp позволяет измерить:
- вариацию задержки (ещё называют джиттером). При этом на приёмной стороне должен работать 90 КГц счётчик;
- в принципе, задержку прохождения пакета. Но для этого нужно синхронизировать время камеры с timestamp«ом, а это возможно, если камера передаёт sender reports (RTCP SR), что в общем случае неверно, т.к. в реальной жизни многие камеры игнорируют посылку RTCP SR (примерно половина камер, с которыми нам довелось поработать).
Ну, а M-бит позволяет измерить частоту кадров. Правда, SPS/PPS-кадры протокола h.264 вносят погрешность, т.к. видео-кадрами не являются. Но её можно нивелировать, использовав информацию из заголовка NAL-unit«а, который всегда идёт следом за RTP-заголовком.
Подробные алгоритмы измерения параметров выходят за рамки статьи, не буду заглубляться. Если интересно, то в rfc3550 есть пример кода вычисления потерь и формулы для вычисления джиттера. Главный же вывод заключается в том, что для измерений базовых характеристик транспортного потока достаточно всего лишь нескольких полей из RTP-пакетов и NAL-юнитов. А остальная информация в измерениях не участвует и её можно и нужно отбросить!

Как идентифицировать RTP-потоки?
Для ведения статистики информацию, полученную из RTP-заголовка, необходимо «привязать» к некоторому идентификатору камеры (видео-потока). Камеру можно однозначно идентифицировать по следующим параметрам:
- IP-адреса источника и получателя
- Порты источника и получателя
- SSRC. Имеет особое значение тогда, когда с одного IP вещается несколько потоков, т.е. в случае с многопортовым энкодером.
Что интересно, мы сначала сделали идентификацию камер только по IP источника и SSRC, полагаясь на то, что SSRC должен быть случайным, но на практике оказалось, что многие камеры устанавливают SSRC в фиксированное значение (скажем, 256). Видимо, это связано с экономией ресурсов. В итоге нам пришлось к идентификатору камеры добавить ещё и порты. Это решило проблему уникальности полностью.
Как отделить RTP-пакеты от остального трафика?
Остался вопрос: как Беркут-MX, приняв пакет, поймёт, что это RTP? RTP-заголовок не имеет такой явной идентификации, как IP, у него нет контрольной суммы, передаваться он может по UDP с номерами портов, которые выбираются динамически при установке соединения. А в нашем случае большинство соединений уже давно установлены и ждать переустановки можно очень долго.
Для решения этой задачи в rfc3550 (Appendix A.1) рекомендуется проверять биты версии RTP — это два бита, и поле Payload Type (PT) — семь бит, которое в случае с динамическим типом принимает небольшой диапазон. Мы на практике выяснили, что для того множества камер, c которым мы работаем, PT укладывается в диапазон от 96 до 100.
Есть ещё один фактор — чётность порта, но как показала практика, не всегда соблюдается, поэтому от него пришлось отказаться.
Таким образом, поведение Беркут-MX следующее:
- получаем пакет, разбираем на поля;
- если версия равна 2 и payload type находится в заданных пределах, то отправляем заголовки серверу.
Очевидно, что при таком подходе есть ложноположительные срабатывания, т.к. под такие простые критерии могут попадать не только RTP-пакеты. Но для нас важно, что RTP-пакет мы точно не пропустим, а «неправильные» пакеты отфильтрует уже сервер.
Для фильтрации ложных случаев сервер использует механизм, который регистрирует источник видео-трафика по нескольким последовательно принятым пакетам (в пакете же есть sequence number!). Если несколько пакетов пришло с последовательными номерами, то это не случайное совпадение и начинаем работать с этим потоком. Этот алгоритм оказался весьма надёжным.
Двигаемся дальше…
Поняв, что вся информация, идущая в пакетах, для измерения качества и идентификации потоков не нужна, мы решили всю highload & time-critical работу по приёму и вычленению полей RTP-пакетов взвалить на Беркут-MX, то бишь на FPGA. Он «находит» видео-поток, разбирает пакет, оставляет только нужные поля и в UDP-туннеле отправляет на обычный сервер. Сервер проводит измерения по каждой камере и сохраняет результаты в базу данных.
В итоге сервер работает не с 50–60 Гигабит/с, а максимум с 5% (именно такая получилась пропорция отсылаемых данных к среднему размеру пакета). То есть на входе всей системы 55 Гигабит/с, а на сервер попадает всего-то не более 3 Гигабит/с!
В итоге у нас получилась такая архитектура:

И первый результат в такой конфигурации мы получили через две недели после постановки начального ТЗ!
Чем в итоге занят сервер?
Итак, что же делает сервер в нашей архитектуре? Его задачи:
- слушать UDP-сокет и вычитывать из него поля с упакованными заголовками;
- разбирать приходящие пакеты и доставать оттуда поля RTP заголовков вместе с идентификаторами камеры;
- соотносить полученные поля с теми, что были получены прежде, и понимать, потерялись ли пакеты, посылались ли пакеты повторно, менялся ли порядок прихода, какая была вариация задержки прохождения пакета (джиттер) и т.д.;
- фиксировать измеренное в базе с привязкой ко времени;
- анализировать базу и генерировать отчёты, посылать трапы о критических событиях (высокие потери пакетов, пропадание пакетов от какой-то камеры и т.п.).
При том, что суммарный трафик на входе сервера составляет около 3 Гигабит/с, сервер справляется даже при условии, что мы не используем никаких DPDK, а работаем просто через linux«овый сокет (предварительно увеличив размер буфера для сокета, конечно). Более того, можно будет подключать новые линки и MX’ы, потому что запас по производительности остаётся.
Вот как выглядит top сервера (это top только одного lxc-контейнера, отчёты генерируются в другом):
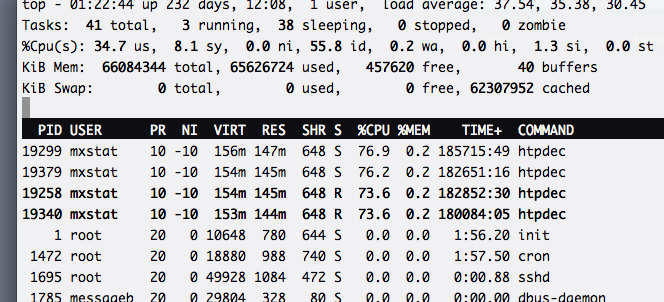
Из него видно, что вся нагрузка по расчёту параметров качества и учёту статистики распределена по четырём процессам равномерно. Нам удалось добиться такого распределения за счёт применения хеширования в FPGA: по IP считается хеш-функция, а младшие биты полученного хеша определяют номер UDP-порта, на который уйдёт статистика. Соответственно, каждый процесс, слушающий свой порт, получает примерно одинаковое количество трафика.
Cons and pros
Настало время похвастаться и признаться в недостатках полученного решения.
Начну с плюсов:
- отсутствие потерь на стыке с 10G-линками. Поскольку весь «удар» на себя берёт ПЛИС, мы можем не сомневаться в том, что будет проанализирован каждый пакет;
- для мониторинга 55000 камер (и более) требуется всего один сервер с одной 10G карточкой. Мы пока используем сервера на базе 2х Xeon c 4 мя ядрами по 2400 МГц каждое. Хватает с запасом: параллельно со сбором информации генерируются отчёты;
- мониторинг 8-ми «десяток» (10G линков) укладывается всего в 2–3 юнита: не всегда под систему мониторинга есть много места и питания в стойке;
- при подключении линков от MX«ов через коммутатор можно добавлять новые линки без остановки мониторинга, т.к. никакие платы в сервер вставлять не надо и для этого не требуется его выключать;
- сервер не перегружен данными, он получает только то, что необходимо;
- заголовки с MX«а приходят в jumbo Ethernet-пакете, значит процессор не захлебнётся прерываниями (к тому же мы не забываем и про interrupt coalescing).
Справедливости ради рассмотрю и недостатки:
- из-за жёсткой оптимизации под конкретную задачу добавление поддержки новых полей или протоколов требует изменений в коде ПЛИС. Это приводит к бОльшим затратам времени, чем если бы мы делали это же на процессоре. Как в разработке и тестировании, так и при деплое;
- видео-информация не анализируется вообще. Камера может снимать сосульку, висящую перед ней, или быть повёрнутой не в ту сторону. Этот факт останется незамеченным. Мы, конечно, предоставили возможность записи видео с выбранной камеры, но не перебирать же оператору все 55000 камер!
- сервер и FPGA-powered девайсы — это дороже, чем просто один-два сервера ;)
Резюме
В конечном итоге у нас получился программно-аппаратный комплекс, в котором мы можем контролировать и ту часть, которая парсит пакеты на интерфейсах, и ту, которая ведёт статистику. Полный контроль над всеми узлами системы буквально спас нас, когда камеры начали переводить на RTSP/TCP interleaved mode. Потому что в этом случае заголовок RTP перестал располагаться в пакете по фиксированному смещению: он может находиться где угодно, даже на границе двух пакетов (первая половина в одном, вторая — в другом). Соответственно, алгоритм получения RTP-заголовка и его полей претерпел кардинальные изменения. Нам пришлось сделать TCP reassembling на сервере для всех 50000 соединений — отсюда и довольно высокая нагрузка в top«е.
Мы никогда до этого не работали в сфере высоконагруженных приложений, но нам удалось решить задачу за счёт наших скилов в FPGA и получилось довольно-таки неплохо. Даже остался запас — например, к системе с 55000 камерами можно подключить ещё 20–30 тысяч потоков.
Тюнинг linux«овых подсистем (распределение очередей по прерываниям, увеличение приёмных буферов, директивное выделение ядер на конкретные процессы и т.п.) я оставил за рамками статьи, т.к. эта тема и так уже очень хорошо освещена.
Я описал далеко не всё, граблей было собрано немало, поэтому не стесняйтесь задавать вопросы :)
Большое спасибо всем, кто дочитал до конца!
