Расширяем и дополняем Kubernetes (обзор и видео доклада)

8 апреля на конференции Saint HighLoad++ 2018, в рамках секции «DevOps и эксплуатация», прозвучал доклад «Расширяем и дополняем Kubernetes», в создании которого участвовали три сотрудника компании «Флант». В нём мы рассказываем о многочисленных ситуациях, в которых нам хотелось расширить и дополнить возможности Kubernetes, но для чего мы не находили готового и простого решения. Необходимые решения у нас появились в виде Open Source-проектов, и им тоже посвящено это выступление.
По традиции рады представить видео с докладом (50 минут, гораздо информативнее статьи) и основную выжимку в текстовом виде. Поехали!
Ядро и дополнения в K8s
Kubernetes меняет отрасль и подходы к администрированию, которые давно устоялись:
- Благодаря его абстракциям, мы оперируем уже не такими понятиями, как настройка конфига или запуск команды (Chef, Ansible…), а пользуемся группировкой контейнеров, сервисами и т.п.
- Мы можем готовить приложения, не задумываясь о нюансах той конкретной площадки, на которой оно будет запущено: bare metal, облако одного из провайдеров и т.п.
- С K8s как никогда стали доступны лучшие практики по организации инфраструктуры: техники масштабирования, самовосстановления, отказоустойчивости и т.п.
Однако, разумеется, всё не так гладко: с Kubernetes пришли и свои — новые — вызовы.
Kubernetes не является комбайном, который решает все проблемы всех пользователей. Ядро Kubernetes отвечает только за набор минимально необходимых функций, что присутствуют в каждом кластере:
В ядре Kubernetes определяется базовый набор примитивов — для группировки контейнеров, управления трафиком и так далее. Подробнее о них мы рассказывали в докладе 2-летней давности.
С другой стороны, K8s предлагает замечательные возможности по расширению доступных функций, что помогают закрыть и другие — специфичные — потребности пользователей. За дополнения в Kubernetes отвечают администраторы кластеров, которые должны установить и настроить всё необходимое для того, чтобы их кластер «обрёл нужную форму» [для решения их специфичных задач]. Что же это за дополнения такие? Рассмотрим некоторые примеры.
Примеры дополнений
Установив Kubernetes, мы можем удивиться, что сеть, столь необходимая для взаимодействия pod’ов как в рамках узла, так и между узлами, сама по себе не работает. Ядро Kubernetes не гарантирует нужные связи — вместо этого, оно определяет сетевой интерфейс (CNI) для сторонних дополнений. Мы должны установить одно из таких дополнений, которое и будет отвечать за конфигурацию сети.

Близкий пример — решения для хранения данных (локальный диск, сетевое блочное устройство, Ceph…). Изначально они были в ядре, но с появлением CSI ситуация меняется на аналогичную уже описанной: в Kubernetes интерфейс, а его реализация — в сторонних модулях.
Среди прочих примеров:
- Ingress-контроллеры (их обзор см. в нашей недавней статье).
- cert-manager:

- Операторы — это целый класс дополнений (к которым относится и упомянутый cert-manager), они определяют примитив (ы) и контроллер (ы). Логика их работы ограничена только нашей фантазией и позволяет превращать готовые компоненты инфраструктуры (например, СУБД) в примитивы, работать с которыми гораздо проще (чем с набором из контейнеров и их настроек). Операторов написано огромное множество — пусть многие из них ещё и не готовы к production, это лишь вопрос времени:
- Метрики — очередная иллюстрация, как в Kubernetes отделили интерфейс (Metrics API) от реализации (сторонние дополнения, такие как Prometheus adapter, Datadog cluster agent…).
- Для мониторинга и статистики, где на практике нужны не только Prometheus и Grafana, но и kube-state-metrics, node-exporter и т.п.
И это далеко не полный список дополнений… Например, мы в компании «Флант» на каждый Kubernetes-кластер на сегодняшний день устанавливаем 29 дополнений (все они в общей сложности создают 249 объектов Kubernetes). Проще говоря, мы не видим жизни кластера без дополнений.
Автоматизация
Операторы созданы для автоматизации рутинных операций, с которыми мы повседневно сталкиваемся. Вот примеры из жизни, отличным решением для которых будет написание оператора:
- Есть приватный (т.е. требующий логина) registry с образами для приложения. Предполагается, что каждому pod’у привязывается специальный секрет, позволяющий аутентифицироваться в registry. Наша задача — обеспечить нахождение этого секрета в namespace’е, чтобы pod’ы могли скачивать образы. Приложений (каждому из которых нужен секрет) может быть очень много, а сами секреты полезно регулярно обновлять, так что вариант с раскладыванием секретов руками отпадает. Тут и приходит на помощь оператор: мы создаём контроллер, который будет дожидаться появления namespace’а и по этому событию добавит секрет в namespace.
- Пусть по умолчанию доступ из pod’ов к интернету запрещён. Но иногда он может требоваться: логично, чтобы механизм разрешения доступа работал просто, не требуя специфичных навыков, — например, по наличию определённого лейбла в namespace’е. Как нам тут поможет оператор? Создаётся контроллер, который ожидает появления лейбла в namespace’е и добавляет соответствующий policy для доступа в интернет.
- Схожая ситуация: пусть нам потребовалось добавлять на узел определённый taint, если на нём есть аналогичный лейбл (с каким-то префиксом). Действия с оператором очевидны…
В любом кластере надо решать рутинные задачи, а правильно это делать — с помощью операторов.
Подытоживая все описанные истории, мы для себя пришли к выводу, что для комфортной работы в Kubernetes требуется: а) устанавливать дополнения, б) разрабатывать операторы (для решения повседневных админских задач).
Как написать оператор для Kubernetes?
В целом схема проста:
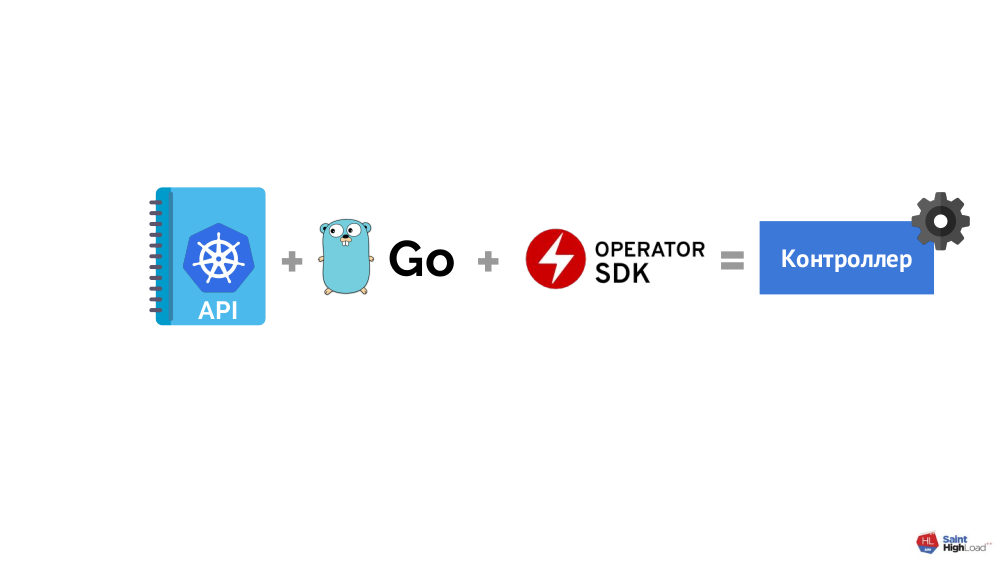
…, но тут выясняется, что:
- Kubernetes API — достаточно нетривиальная вещь, которая требует немало времени для освоения;
- программирование тоже не для каждого (язык Go выбран как предпочтительный, потому что для него есть специальный фреймворк — Operator SDK);
- с фреймворком как таковым аналогичная ситуация.
Итог: для написания контроллера (оператора) приходится потратить существенные ресурсы для изучения матчасти. Это было бы оправдано для «больших» операторов — скажем, для СУБД MySQL. Но если мы вспомним описанные выши примеры (раскладывание секретов, доступ pod’ов в интернет…), которые хочется тоже делать правильно, то мы поймём, что затрачиваемые усилия перевесят нужный сейчас результат:

В общем, возникает дилемма: потратить много ресурсов и обрести правильный инструмент для написания операторов или действовать «по старинке» (но быстро). Для её решения — нахождения компромисса между этими крайностями — мы создали свой проект: shell-operator (см. также его недавний анонс на хабре).
Shell-operator
Как он работает? В кластере есть pod, в котором лежит Go-бинарник с shell-operator. Рядом с ним хранится набор хуков(подробнее о них — см. ниже). Сам shell-operator подписывается на определённые события в Kubernetes API, по факту наступления которых он запускает соответствующие хуки.
Как shell-operator понимает, какие хуки при каких событиях вызывать? Эту информацию передают shell-operator’у сами хуки и делают они это очень просто.
Хук — это скрипт на Bash или любой другой исполняемый файл, который поддерживает единственный аргумент --config и в ответ на него выдаёт JSON. Последний определяет, какие объекты его интересуют и на какие события (для этих объектов) следует реагировать:

Проиллюстрирую реализацию на shell-operator одного из наших примеров — раскладывание секретов для доступа к приватному registry с образами приложения. Она состоит из двух этапов.
Практика: 1. Пишем хук
Первым делом в хуке обработаем --config, указав, что нас интересуют namespace’ы, а конкретно — момент их создания:
[[ $1 == "--config" ]] ; then
cat << EOF
{
"onKubernetesEvent": [
{
"kind": "namespace",
"event": ["add"]
}
]
}
EOF
…
Как будет выглядеть логика? Тоже довольно просто:
…
else
createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH)
kubectl create -n ${createdNamespace} -f - << EOF
Kind: Secret
...
EOF
fi
Первым шагом мы узнаём, какой namespace был создан, а вторым — создаём через kubectl секрет для этого пространства имён.
Практика: 2. Собираем образ
Осталось передать созданный хук shell-operator’у — как это сделать? Сам shell-operator поставляется в виде Docker-образа, так что наша задача — добавить хук в специальный каталог в этом образе:
FROM flant/shell-operator:v1.0.0-beta.1
ADD my-handler.sh /hooks
Останется собрать его и push’нуть:
$ docker build -t registry.example.com/my-operator:v1 .
$ docker push registry.example.com/my-operator:v1
Финальный штрих — задеплоить образ в кластер. Для этого напишем Deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-operator
spec:
template:
spec:
containers:
- name: my-operator
image: registry.example.com/my-operator:v1 # 1
serviceAccountName: my-operator # 2
В нём нужно обратить внимание на два момента:
- указание только что созданного образа;
- это системный компонент, которому (как минимум) нужны права на то, чтобы подписаться на события в Kubernetes и чтобы раскладывать секреты по namespace’ам, поэтому мы создаём для хука ServiceAccount (и набор правил).
Результат — мы решили нашу проблему родным для Kubernetes способом, создав оператор для раскладывания секретов.
Другие возможности shell-operator
Чтобы ограничить объекты выбранного вами типа, с которыми будет работать хук, их можно фильтровать, отбирая по определённым лейблам (или с помощью matchExpressions):
"onKubernetesEvent": [
{
"selector": {
"matchLabels": {
"foo": "bar",
},
"matchExpressions": [
{
"key": "allow",
"operation": "In",
"values": ["wan", "warehouse"],
},
],
}
…
}
]
Предусмотрен механизм дедупликации, который — с помощью jq-фильтра — позволяет преобразовывать большие JSON’ы объектов в маленькие, где остаются только те параметры, за изменением которых мы хотим следить.
При вызове хука shell-operator передаёт ему данные про объект, которые могут использоваться для любых нужд.
События, при наступлении которых вызываются хуки, не ограничены Kubernetes events: в shell-operator предусмотрена поддержка вызова хуков по времени (аналогично crontab в традиционном планировщике), а также специального события onStartup. Все эти события могут комбинироваться и назначаться на один и тот же хук.
И ещё две особенности shell-operator:
- Он работает асинхронно. С момента получения события Kubernetes (например, создание объекта) в кластере могли произойти и другие события (например, удаление того же объекта), и это необходимо учитывать в хуках. Если хук выполнился с ошибкой, то по умолчанию он будет повторно вызываться до успешного завершения (это поведение можно изменить).
- Он экспортирует метрики для Prometheus, с помощью которых можно понять, работает ли shell-operator, узнать количество ошибок по каждому хуку и текущий размер очереди.
Подводя итог этой части доклада:

Установка дополнений
Для комфортной работы с Kubernetes была также упомянута необходимость установки дополнений. О ней я расскажу на примере пути нашей компании к тому, как мы делаем это сейчас.
Работу с Kubernetes мы начинали с нескольких кластеров, единственным дополнением в которых был Ingress. В каждый кластер его требовалось ставить по-разному, и мы сделали несколько YAML-конфигураций для разных окружений: bare metal, AWS…
Кластеров становилось больше — больше становилось и конфигураций. Кроме того, мы улучшали сами эти конфигурации, в результате чего они стали довольно разнородными:
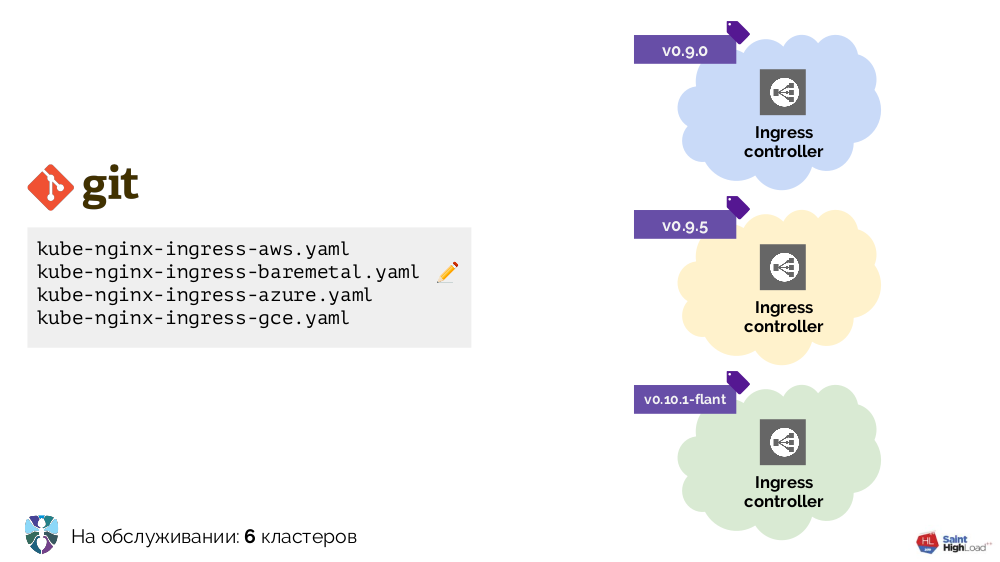
Чтобы привести всё в порядок, мы начали со скрипта (install-ingress.sh), который принимал аргументом тип кластера, в который будем деплоиться, генерировал нужную YAML-конфигурацию и выкатывал её в Kubernetes.
Если вкратце, то дальнейший наш путь и связанные с ним рассуждения были таковы:
- для работы с YAML-конфигурациями требуется шаблонизатор (на первых этапах это простой sed);
- с ростом числа кластеров пришла необходимость для автоматического обновления (самое раннее решение — положили скрипт в Git, по cron’у его обновляем и запускаем);
- схожий скрипт потребовался для Prometheus (
install-prometheus.sh), однако он примечателен тем, что требует гораздо больше вводных данных, а также их хранение (по-хорошему — централизованное и в кластере), причём некоторые данные (пароли) можно было автоматически генерировать:
- риск выкатить что-то неправильное на растущее число кластеров постоянно рос, поэтому мы поняли, что инсталляторам (т.е. двум скриптам: для Ingress и Prometheus) понадобилось стейджирование (несколько веток в Git, несколько cron’ов на их обновление в соответствующих: стабильных или тестовых — кластерах);
- с
kubectl applyстало сложно работать, потому что он не является декларативным и умеет только создавать объекты, но не принимать решения по их статусу/удалять их; - не хватало некоторых функций, которые мы на тот момент совсем не реализовали:
- полноценного контроля результата обновления кластеров,
- автоматического определения некоторых параметров (вводных для скриптов установки) на основе данных, что можно получить из кластера (discovery),
- его логичного развития в виде continuous discovery.
Весь этот накопленный опыт мы реализовали в рамках другого своего проекта — addon-operator.
Addon-operator
В его основе — уже упомянутый shell-operator. Вся система же выглядит следующим образом:
К хукам shell-operator’а добавляются:
- хранилище values,
- Helm-чарт,
- компонент, который следит за хранилищем values и — в случае каких-либо изменений — просит Helm перевыкатить чарт.

Таким образом, мы можем среагировать на событие в Kubernetes, запустить хук, а из этого хука — внести изменения в хранилище, после чего будет перевыкачен чарт. В получившейся схеме мы выделяем набор хуков и чарт в один компонент, который называем модулем:
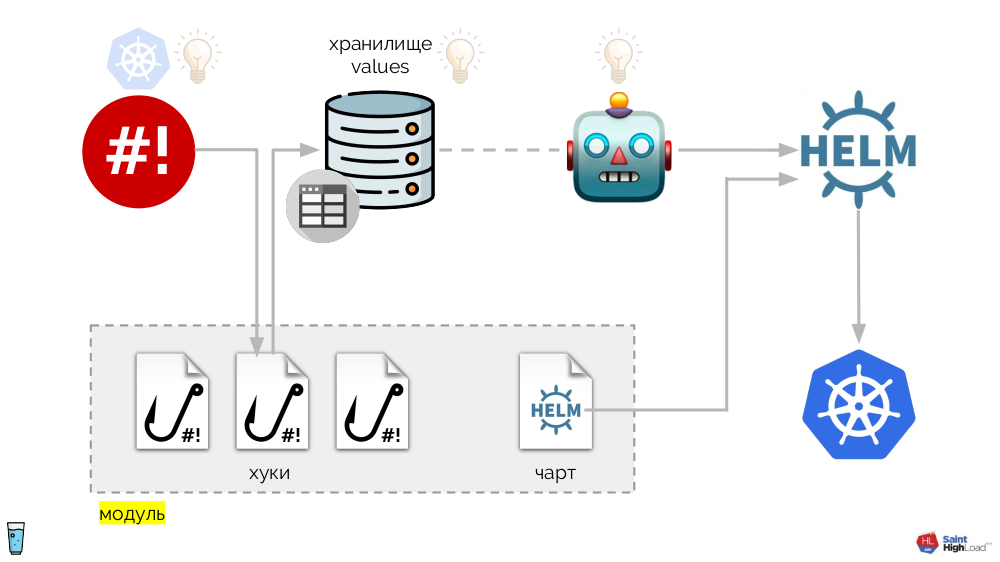
Модулей может быть множество, а к ним мы добавляем глобальные хуки, глобальное хранилище values и компонент, который следит за этим глобальным хранилищем.
Теперь, когда в Kubernetes что-то происходит, мы можем на это отреагировать с помощью глобального хука и изменить что-то в глобальном хранилище. Это изменение будет замечено и вызовет выкат всех модулей в кластере:
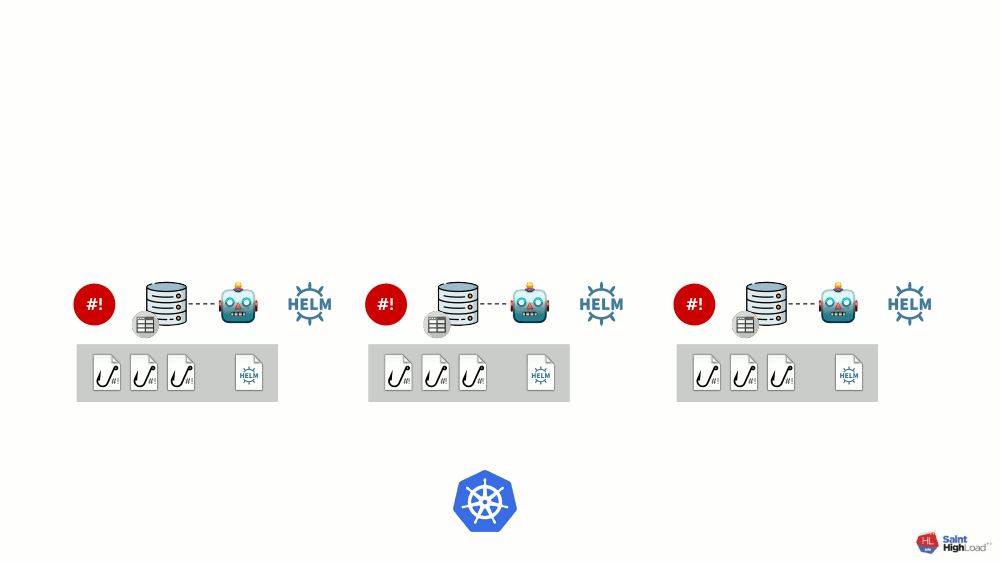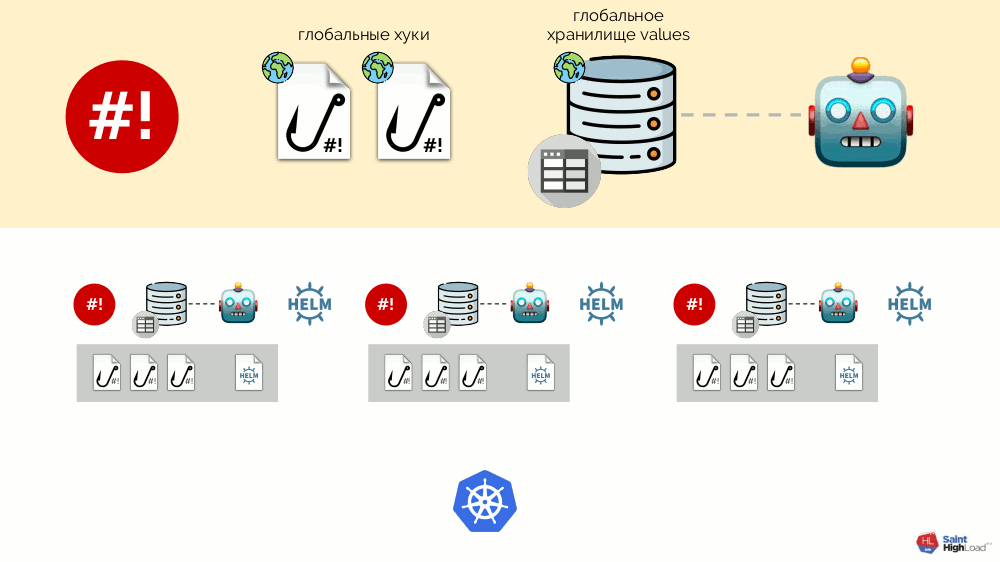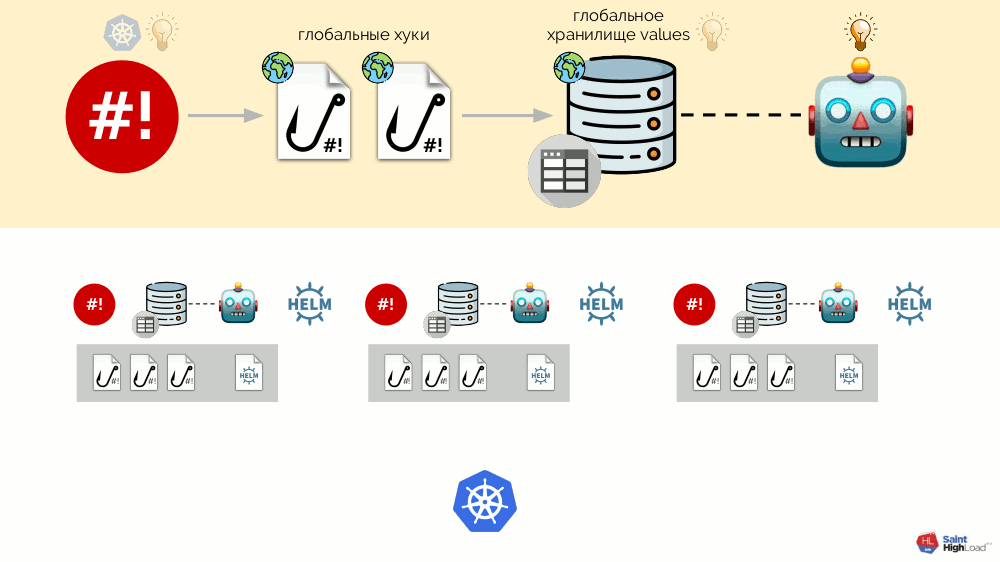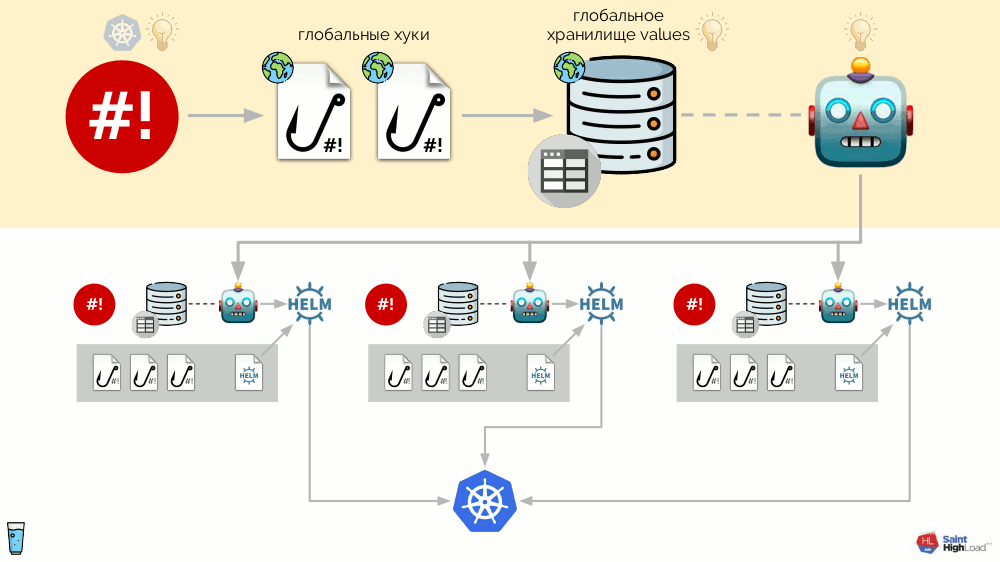
Эта схема удовлетворяет всем требованиям к установке дополнений, что были озвучены выше:
- За шаблонизацию и декларативность отвечает Helm.
- Вопрос автообновления решён с помощью глобального хука, который по расписанию ходит в registry и, если видит там новый образ системы, перевыкатывает её (т.е. «сам себя»).
- Хранение настроек в кластере реализовано с помощью ConfigMap, в котором записаны первичные данные для хранилищ (при старте они загружаются в хранилища).
- Проблемы генерации паролей, discovery и continuous discovery решены с помощью хуков.
- Стейджирование достигнуто благодаря тегам, которые Docker поддерживает из коробки.
- Контроль результата производится с помощью метрик, по которым мы можем понять статус.
Вся эта система реализована в виде единственного бинарника на Go, который и получил название addon-operator. Благодаря этому схема выглядит проще:

Главный компонент на этой схеме — набор модулей (выделены серым цветом внизу). Теперь мы можем небольшими усилиями написать модуль для нужного дополнения и быть уверенными, что оно будет установлено в каждый кластер, будет обновляться и реагировать на нужные ему события в кластере.
«Флант» использует addon-operator на 70+ Kubernetes-кластерах. Текущий статус — альфа-версия. Сейчас мы готовим документацию, чтобы выпустить бету, а пока в репозитории доступны примеры, на основе которых можно создать свой addon.
Где взять сами модули для addon-operator? Публикация своей библиотеки — следующий этап для нас, мы планируем это сделать летом.
Видео и слайды
Видео с выступления (около часа):
Презентация доклада:
https://speakerdeck.com/flant/rasshiriaiem-i-dopolniaiem-kubernetes
P.S.
Другие доклады в нашем блоге:
Возможно, вас также заинтересуют следующие публикации:
