Распознавание номеров. Как мы получили 97% точности для Украинских номеров. Часть 2
Продолжаем рассказ о том как распознавать номерные знаки для тех кто умеет писать приложение «hello world» на python-е! В этой части научимся тренировать модели, которые ищут регион заданного объекта, а также узнаем как написать простенькую RNN-сеть, которая будет справляться с чтением номера лучше чем некоторые коммерческие аналоги.
В этой части я расскажу как тренировать Nomeroff Net под Ваши данные, как получить высокое качество распознавания, как настроить поддержку GPU и ускорить все на порядок…
Конечно же, находить можно не только номер, а любой другой объект, потребность в поиске которого у вас возникла. Например можно, но аналогии, поискать кредитную карту и считать ее реквизиты. В общем, нахождение маски, в которую вписан объект на изображении называют задачей «Instance Segmentation» (об этом я уже писал в первой части).
Сейчас мы разберемся как натренировать сеть для решения этой задачи. На самом деле тут программирования мало, все сводится к монотонной, нудной, однообразной разметке данных. Да-да, после того как вы разметите свою первую сотню вы поймете о чем я :)
Итак, алгоритм подготовки данных следующий:
- Берем изображения размером не менее 300×300, сбрасываем все в одну папку
- Загружаем инструмент для нанесения разметки VGG Image Annotator (VIA), можно размечать прямо онлайн, на выходе будет директория с фото и сформированный вами json-файл с разметкой. Таких папок нужно две, в одной под названием train поместите основную часть примеров, во вторую val приблизительно 20–30% от числа примеров первой паки (Конечно же, в этих папках не должно быть одинаковых фотографии). Можете посмотреть пример размеченных данных для проекта Nomeroff Net. По количеству — чем больше тем лучше. Некоторые специалисты рекомендуют 5 000 примеров, мы обленились, набрав чуть более 1 000 так как результат нас вполне устроил.

- Чтоб приступить к обучению вам нужно загрузить с Github сам проект Nomeroff Net, установить Mask RCNN со всеми зависимостями и можно попробовать запустить скрипт тренировки train/mrcnn.ipynb на наших данных
- Сразу предупреждаю, это работает не быстро. Если у Вас нет GPU это может занять дни. Чтоб существенно ускорить процесс обучения желательно установить tensorflow с поддержкой GPU.
- Если тренировка на нашем датасета у вас прошла успешно, теперь можно смело переключатся на свой.
-
Обратите внимание — мы не обучаем все «с нуля», мы дотренировываем модель, обученную на данных COCO dataset, которую Mask RCNN закачает при первом запуске
- Вы можете дотренировывать не coco, а нашу модель mask_rcnn_numberplate_0700.h5, при этом укажите путь к этой модели в конфигурационном параметре WEIGHTS (по умолчанию «WEIGHTS»: «coco»)
- Из параметров, которые можно протюнить это: EPOCH, STEPS_PER_EPOCH
- Результат после каждой эпохи будет сбрасываться в папку ./logs/numberplate<дата запуска>/
Чтоб опробовать натренированную модель в деле, в примерах проекта замените MASK_RCNN_MODEL_PATH
на путь к своей модели.
После того, как области с номерными знаками найдены, нужно попробовать определить какого государства/типа номер мы распознаем. Тут универсализация работает против качества распознавания. Поэтому, в идеале, нужно тренировать классификатор, который не просто определяет какой страны номер, но и разновидность оформления этого номера (расположение символов, варианты символов для заданной разновидности номера).
В нашем проекте мы реализовали поддержку распознавания номеров Украины, РФ и Европейские номера в целом. Качество распознавания европейских номеров немного хуже, так как там номера с разным дизайном и увеличенным количеством встречающихся символов. Возможно, со временем, будут отдельные модули распознавания для «eu-ee», «eu-pl», «eu-nl», …
Перед классификацией номерного знака его нужно «вырезать» из изображения и нормализировать, другими словами по максимуму убрать все искажения и получить аккуратный прямоугольник, который будет подвергаться дальнейшему анализу. Эта задача оказалась достаточно нетривиальной, мне даже пришлось вспомнить школьную математику и написать специализированную реализацию алгоритма кластеризации k-means:). Модуль, который это все процессит называется RectDetector, вот как выглядят нормализованные номера, которые далее будем классифицировать и распознавать.

Чтоб как-то автоматизировать процесс создания датасета для классификации номеров мы разработали небольшую админку на nodejs. С помощью этой админки вы можете разметить надпись на номерном знаке и класс к которому его относить. Классификаторов может быть несколько. В нашем случае по типу номера и по тому зарисован/закрашен ли он на фото.
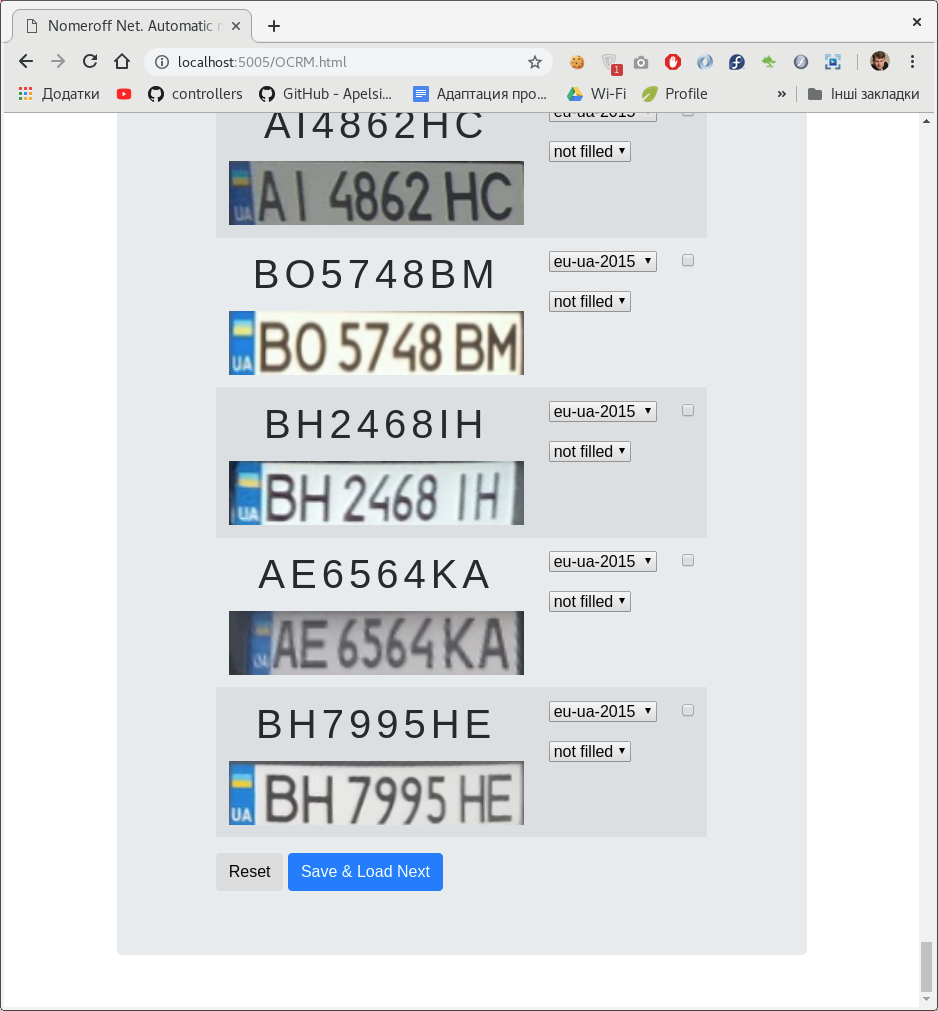
После того как разметили датасет, делим его на тренировочную, валидационную и тестовую выборки. В качестве примера скачайте наш датасет autoriaNumberplateOptionsDataset-2019–03–06.zip, чтоб посмотреть как там все устроено.
Так как выборка уже размечена (отмодерирована), то вам нужно в рандомных json-файлах поменять «isModerated»:1 на «isModerated»:0 и после этого запустить админку.
Тренируем классификатор:
Скрипт тренировки train/options.ipynb поможет получить Вам свой вариант модели. На нашем примере видно что для классификации регионов/типов номерных знаков мы получили точность 98.8%, для классификации «закрашен ли номер?» 99,4% на нашем датасете. Согласитесь, неплохо получилось.
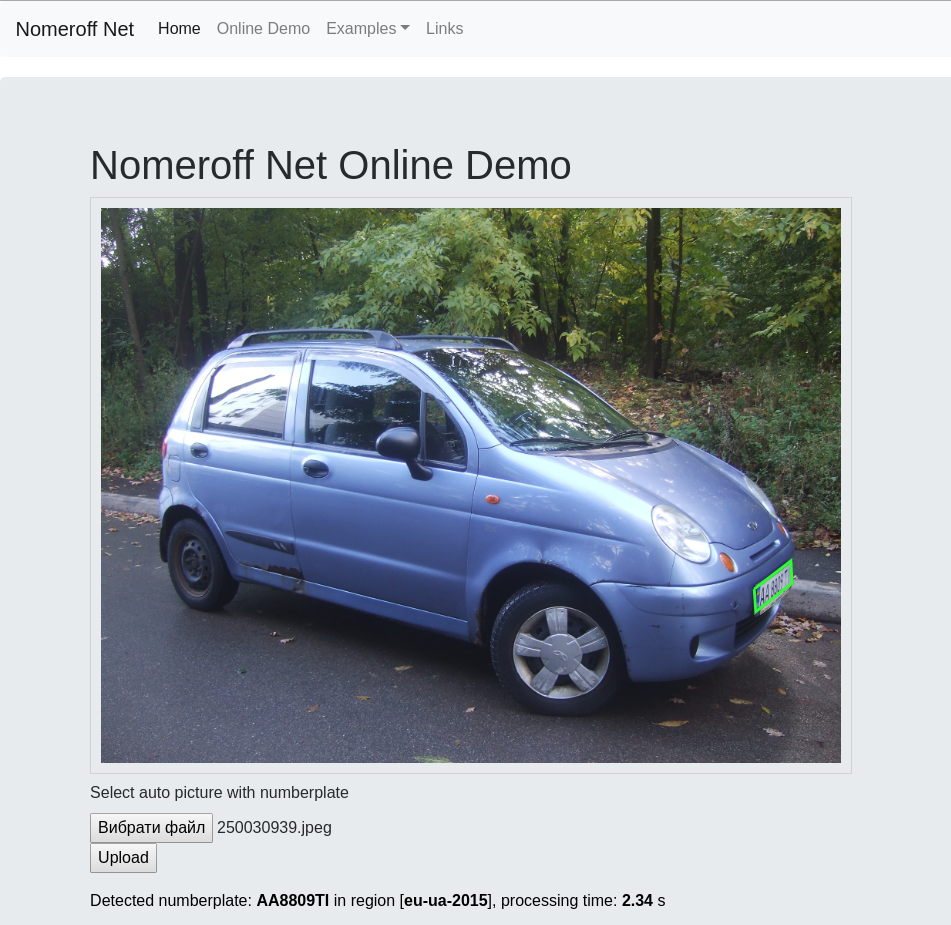
Ну вот мы нашли область с номером и нормализировали ее в прямоугольник, который содержит надпись с номером. Как нам прочитать текст? Проще всего прогнать его через FineReader или Tesseract. Качество будет «не очень», но при хорошем разрешении области с номером сможете получить точность на уровне 80%. На самом деле это неплохая точность, но если я Вам скажу что можете получить 97% и при этом потратите значительно меньше компьютерных ресурсов? Звучит неплохо — попробуем. Для этих целей подойдет немного необычная архитектура, в которой используются как сверточные так и рекурентные слои. Архитектура этой сети выглядит приблизительно так: 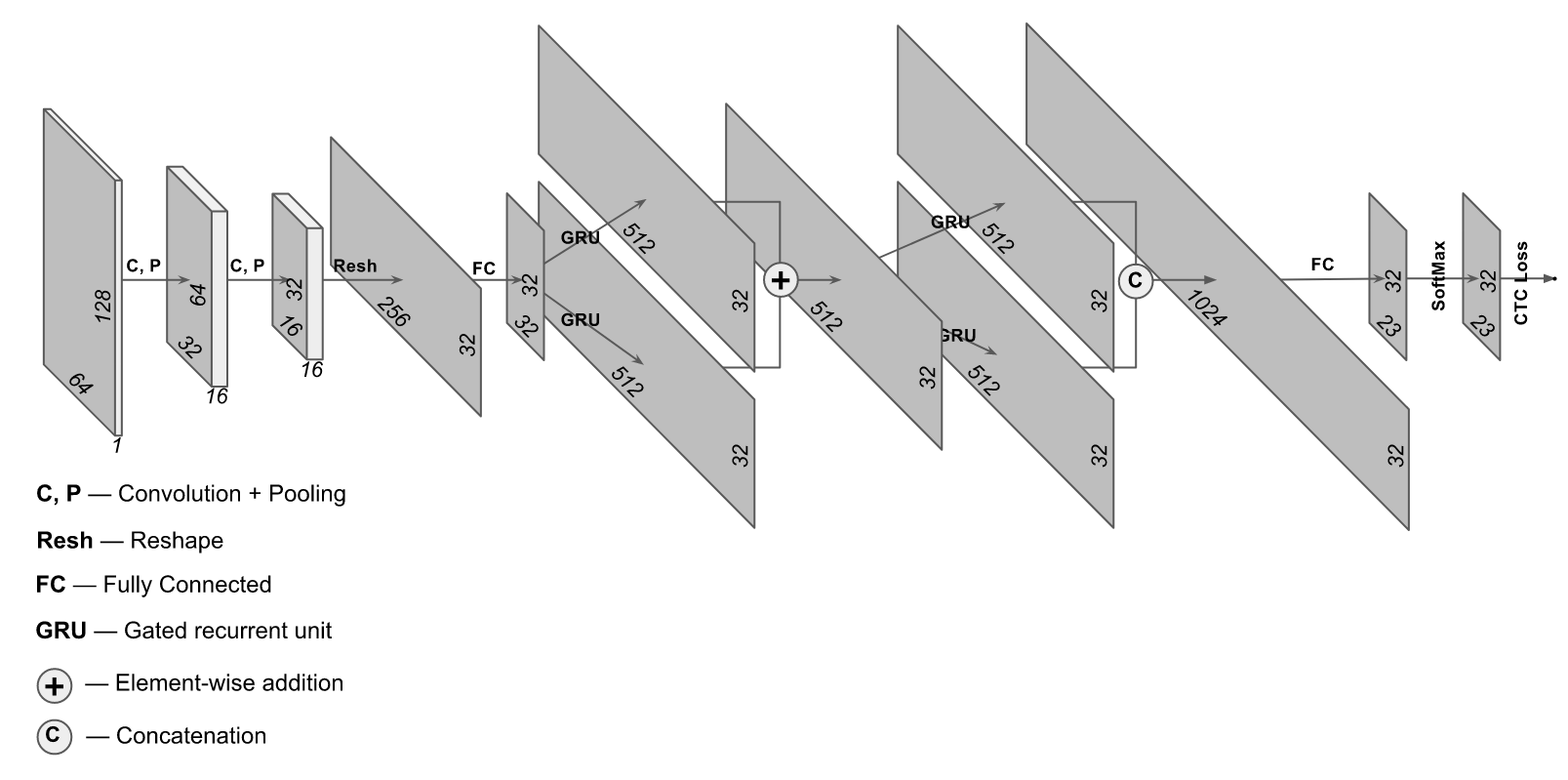
Реализация взята с сайта https://supervise.ly/, мы ее немного модифицировали для тренировки на реальных фото (на сайте supervisely подан вариант для синтетической выборки)
Теперь начинается самая увлекательная часть, разметить хотя бы 5 000, номеров :). Мы разметили около ~15 000 Украинских, ~6500 Европейских и ~5000 РФ. Это была самая сложна часть разработки. Вы даже не представляете сколько раз я засыпал на стуле у компа модерируя по нескольку часов в день очередную порцию номеров. Но настоящий герой разметки dimabendera — он разметил 2/3 всего контента, (поставьте ему плюс если понимаете как скучно было делать всю эту работу :))
Можно попробовать этот процесс как-то автоматизировать, например, предварительно распознав каждое изображение Tesseract-ом, а потом уже поправить ошибки с помощью нашей админки.
Обратите внимание: для разметки классификатора и OCR на номере используется одна и та же админка. Одни и те же данные вы сможете загрузить и туда и туда, кроме зарисованных номеров, конечно.
Если вы разметите хотя бы 5000 номеров и сможете обучить свою OCR — смело оформляйте себе премию у начальства, уверен, это испытание не для слабаков!
Приступаем к тренировке
Скрипт train/ocr-ru.ipynb тренирует модель для номеров РФ, там же примеры для Украины и Европы. Обратите внимание, в настройках тренировки там только одна эпоха (один проход).
Особенностью тренировки такого датасета будет очень разный результат при каждой попытке, перед каждой тренировкой данные перемешиваются в случайном порядке, иногда более удачно для тренировки иногда «не очень». Я вам рекомендую пробовать хотя бы 5 раз, при этом контролировать точность на тестовых данных. При разных попытках запуска у нас точность могла «прыгать» от 87% до 97%.
Несколько рекомендаций:
- Не нужно инициализировать все по-новой просто перезапускаем строку model = ocrTextDetector.train (mode=MODE) пока не получим ожидаемый результат
- Одна из причин плохой точности недостаточное количество данных. Если не устраивает — размечаем еще и еще, в какой-то момент качество расти перестает, для каждого датасета по-разному, можно ориентироваться на цифру 10 000 размеченных примеров
- Тренировка будет проходить быстрее, если у вас установлен драйвер CuDNN от NVIDIA, поменяйте значение MODE = «gpu» в сценарии обучения и вместо слоя GRU подключится CuDNNGRU, что приведет к трехкратному ускорению.
Если вы счастливый обладатель GPU от NVIDIA, то вы можете в разы все ускорить: и тренировку моделей и инференс (режим распознавания) номеров. Проблема заключается в том чтоб корректно все установить и скомпилировать.
Мы на своих серверах ML используем Fedora Linux (так сложилось исторически). Приблизительная последовательность действий для тех кто использует эту OS следующая:
- Ставим драйвер GPU для вашей версии OS, вот тут для Fedora
- Подключаем репозиторий NVIDIA и ставим оттуда набор пакетов CUDA, вот тут для CentOS/Fedora
- Ставим bazel, и собираем tensorflow из исходников по этой доке
- Так же желательно установить старую версию компилятора gcc, который называется cuda-gcc, у меня все нормально собиралось на cuda-gcc 6.4. При настройке сборки указывайте путь именно к cuda-gcc
Если собрать tensorflow с поддержкой gpu не получится, можно запустить все через docker, при этом кроме docker-а нужно доустановить пакет nvidia-docker2. Внутри docker-контейнера можно запустить jupyter notebook, и далее запускать все там.jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Полезные ссылки
Также хочу поблагодарить хабраюзеров 2expres, glassofkvass за предоставленные фото с номерами и dimabendera за то что написал большую часть кода и разметил большую часть данных проекта Nomeroff Net.
