Работа с DSL: создание собственного анализатора с использованием библиотек Python
В нашем блоге на Хабре мы пишем не только о темах, связанных с информационной безопасностью, но уделяем значительное внимание вопросам разработки софта — например, ведем цикл о создании и внедрении инструментов DevOps. Сегодня же речь пойдет об использовании предметно-ориентированных языков (Domain-specific language, DSL) для решения конкретных задач с помощью Python.
Материал подготовлен на основе выступления разработчика Positive Technologies Ивана Цыганова на конференции PYCON Russia (слайды, видео).
Задача
Представим, что мы решили написать свою собственную систему ротации логов. Очевидно, что ее необходимо настраивать. Структура реального конфига Log Rotate похожа на словарь в Python. Давайте попробуем пойти этим путём и запишем нашу конфигурацию в словарь.
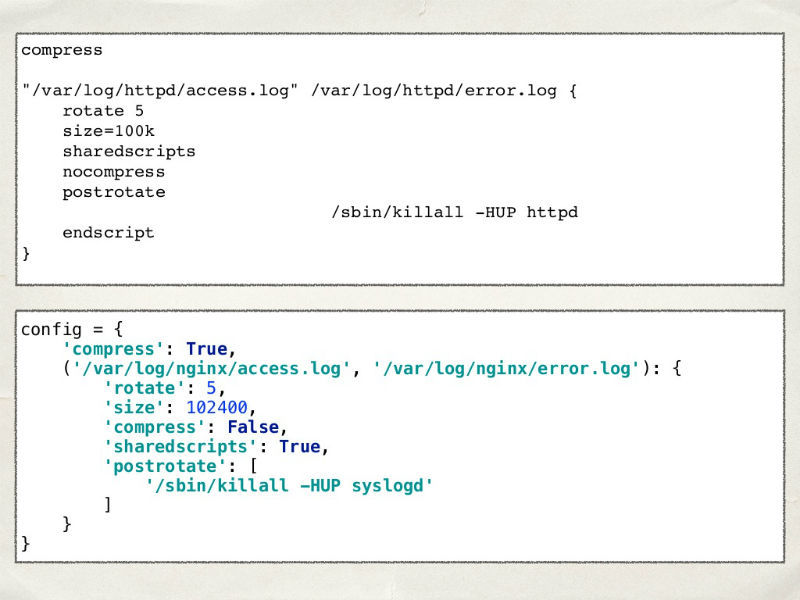
Вроде бы все хорошо — список файлов есть, период ротации тоже есть, все совпадает. Единственное отличие — в Log Rotate мы можем указывать единицы измерения размера файла, а в нашей конфигурации — пока нет. Первая мысль — разрешить задавать их в специальной строке и обрабатывать ее, разбивая по пробелу.

Это хороший способ, который будет работать до момента, пока пользователи нашей системы не попросят дать им возможность указывать некую дельту к используемому размеру (»1 мегабайт + 100 килобайт»). Зачем им это нужно они не сказали, но мы ведь любим своих пользователей. Чтобы реализовать такую функциональность, воспользуемся регулярными выражениями.

Вроде бы работает, но пользователи теперь хотят не только поддержки операций сложения, вычитания, умножения и деления, но и всей арифметики. И здесь становится ясно, что для решения подобной задачи использовать регулярные выражения — не очень хорошая идея. Куда лучше для этого подойдет предметно-ориентированный язык.
Что такое DSL
Согласно определению Мартина Фаулера, предметно-ориентированный язык (DSL) — это язык с ограниченными выразительными возможностями, ориентированный на некую конкретную предметную область.
Существуют внутренние и внешние DSL. К первым относятся такие библиотеки как PonyORM, WTForm и Django models, а ко вторым SQl, REGEXP, TeX/LaTeX. Внутренние DSL представляют собой некое расширение базового языка, а внешние — это абсолютно независимые языки.
В случае разработки внутреннего DSL для нашей задачи мы можем создать функцию или константу, которую можно будет использовать внутри конфигурационного файла.

Но ограничения, накладываемые базовым языком сохранятся и избавиться при записи от лишних скобок и знаков умножения между числом и переменной (MB, KB) нам никак не удастся.
При использовании же внешнего DSL мы сможем сами придумывать синтаксис — это позволит нам избавиться от ненужных нам скобок и знаков умножения. Но нам придется разработать анализатор нашего языка.
Вернемся к нашей задаче
А что если нам потребуется хранить файл конфигурации отдельно от кода? С этим не будет проблем. Просто сохраним наш словарь с конфигурацией в YAML-файл и разрешим пользователям редактировать его.
Технически, этот YAML — уже и есть внешний DSL, при этом для него не нужны никакие анализаторы для разбора. Можно его загрузить, используя существующие библиотеки, и обработать только поле size:

Анализаторы в Python
Взглянем на то, что в Python есть для написания анализаторов.
Библиотека PLY (Python Lex-Yacc)
Анализатор состоит из лексического и синтаксического анализаторов. Исходный текст попадает на вход лексического анализатора, задача которого — разбить текст на поток токенов, то есть примитивов нашего языка. Этот поток токенов попадает в синтаксический анализатор, который проверяет правильность их расположения друг относительно друга. Если все в порядке, то выполняется либо генерация кода, либо его выполнение, либо построение абстрактного синтаксического дерева.
Токены описываются регулярными выражениями: четыре токена для арифметических операций, токен для единиц измерения, цифр и скобок. Если нашему лексическому анализатору подать на вход выражение ниже, то он разберет его в следующий поток токенов:

Но если ему передать семантически неправильную строку, то мы получим бессмысленный набор токенов:

Для того, чтобы избежать лишней работы по анализу правильности расположения токенов нам необходимо описать грамматику нашего языка.

Мы определяем, что выражение может быть цифрой или цифрой, за которой следует единица измерения, выражением в скобках, или двумя выражениями, разделенными некоторой операцией.
Для каждого правила нужно объяснение того, что синтаксическому анализатору делать, при возникновении описываемых им условий. Поскольку мы имеем дело с арифметикой, то также желательно соблюдение всех ее правил — с приоритетом операций умножения, скобок и так далее.
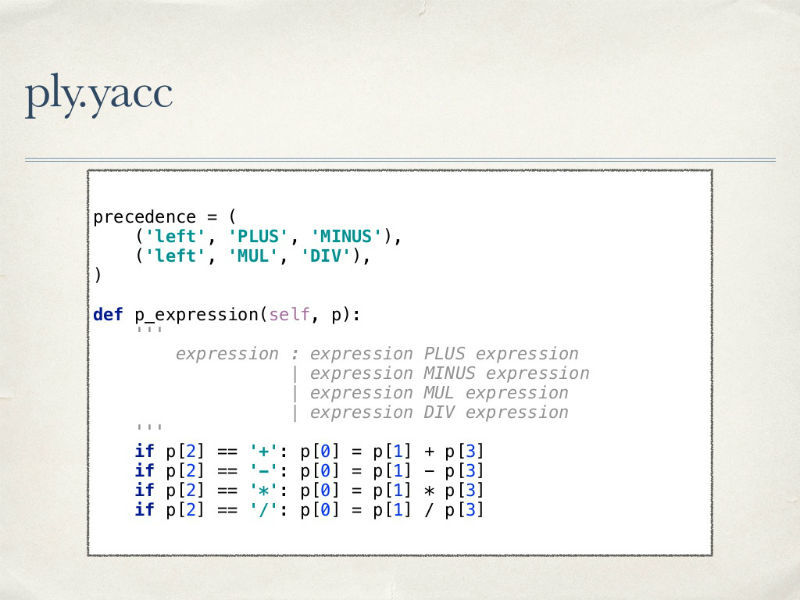
У использования инструмента PLY есть целый ряд преимуществ: он гибкий, предоставляет удобные механизмы отладки анализаторов, отличные методы обработки ошибок, код самой библиотеки хорошо читаем.
Однако совсем без минусов не обойтись — порог входа при начале использования инструмента очень высок, а анализаторы с использованием PLY получаются действительно многословными.
Библиотека funcparserlib
Еще один интересный инструмент для создания анализаторов — библиотека funcparserlib. Это комбинатор функциональных парсеров. Разработка анализатора с применением этой библиотеки также начинается с объявления токенов в виде регулярных выражений. Затем описывается сам парсер — задаются примитивы, описываются используемые операции, которые для удобства обработки еще и группируются по приоритету (умножение и деление/сложение и вычитание).

Теперь нужно описать всю оставшуюся грамматику — для этого мы объявляем описываем как будут выглядеть выражения, а затем описываем приоритеты операций.

К преимуществам funcparserlib можно отнести компактность этой библиотеки и ее гибкость. Из-за этой же компактности многое в ней приходится делать руками — из коробки доступно не так много возможностей. И так как эта библиотека является комбинатором функциональных парсеров — она придется по душе любителям функционального программирования.
Библиотека pyparsing
Еще один вариант для создания анализатора — библиотека pyparsing. Сразу взглянем на код парсера:
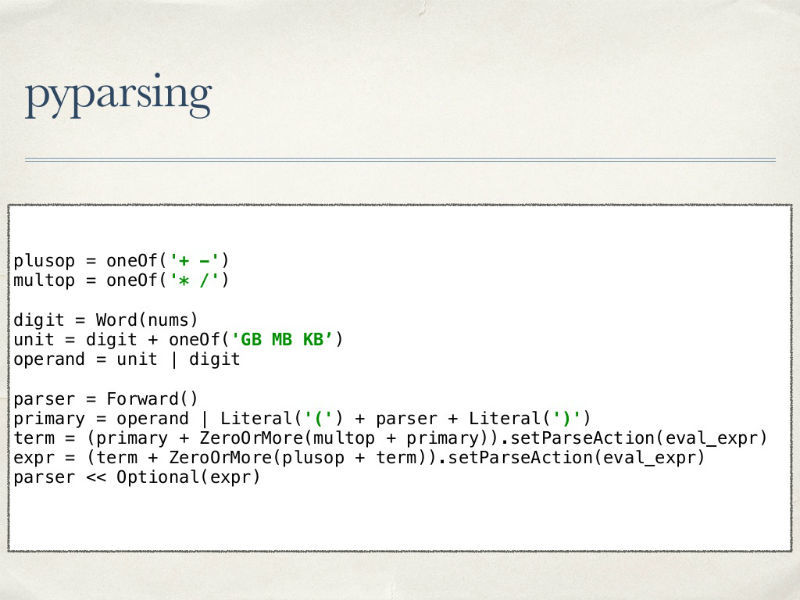
Нигде не описываются токены, все внимание уделяется сразу конечному языку и описанию операций над выражениями с учетом приоритетов.
В pyparsing «из коробки» есть полезные базовые элементы, например методы работы с приоритетами — это упрощает код и делает его более понятным. Кроме того, существует возможность расширения функциональности и создания собственных компонент. С другой стороны — инструмент не может похвастать наличием качественной документации, а отлаживать получившийся компактный анализатор гораздо сложнее чем многословный анализатор с использованием PLY.
Что насчет быстродействия
Поговорим о скорости работы в случае использования каждой из описанных библиотек. Наш анализ показывает, что при обработке несложных кейсов, быстрее всех оказывается PLY.

В ходе тестов мы «скормили» всем анализаторам задачу сложения всех чисел от нуля до 9999. Вот какой результат в миллисекундах показали кандидаты:

Сообщения об ошибках
Не стоит забывать, что мы писали наш анализатор для того, чтобы распарсить одно из полей в конфиге системы ротации логов. Очевидно, что если в работе анализатора возникнут какие-то ошибки, пользователю нужно сообщить об этом в понятном формате — в какой строке, на какой позиции и что именно пошло не так.
Еще один плюс PLY — в библиотеке есть встроенный механизм обработки ошибок, возникающих на этапах лексического и синтаксического анализа. При этом не теряется состояние парсера — после ошибки можно попытаться продолжить работу

Что в итоге выбрать
Конечный выбор инструмента создания парсера зависит от стоящих задач и условий их выполнения. Можно выделить ряд таких комбинаций:
- Если нужно быстро все описать, а быстродействие не главное — вполне подойдет pyparsing.
- В случае, если вы любите функциональное программирование, а быстродействие также не очень важно — очевидным выбором будет funcparserlib.
- Но если скорость работы важнее всего и также хотелось бы описывать все правила «как полагается» по учебникам — конечно, нужно выбрать PLY.
Если существует возможность обработки пользовательских данных средствами самого языка — стоит так и сделать, или использовать регулярные выражения. В более сложных случаях есть смысл начать с применения внутренного DSL, а если этот вариант не подходит — начать использовать готовые языки для структурирования данных (Yaml, Json, XML). Писать собственные анализаторы следует в крайних случаях, когда ничего из перечисленного выше не позволяет решить задачу.
Комментарии (1)
 KvanTTT
KvanTTT
11 января 2017 в 17:41
0↑
↓
А ANTLR рассматривали в качестве генератора лексера и парсера? Рантайм под Python2 и Python3 есть.
