Эволюция процесса деплоя в проекте

Денис Яковлев (2ГИС)
Меня зовут Денис, я работаю в компании 2ГИС, около полутора лет занимаюсь вопросами continuous delivery для проектов веб-отдела. До этого работал в копании Parallels и там прошел путь от QA инженера до team lead«а.
Про deploy. Если мы с вами выпускаем не коробочный продукт, а пишем какой-нибудь сервис, который работает где-то, как многие называют, в дикой природе, на серверах, куда заходят пользователи, то нам недостаточно просто разработать этот сервис и протестировать, нам нужно еще его в эту дикую природу как-то задеплоить, т.е. доставить туда код вместе со всем необходимым для его работы.
Из чего это состоит? Нам нужно доставить, прежде всего, код — то, над чем мы работали большое количество времени, тестировали и прочее.
Мы можем сделать это многими способами, общедоступными и не очень, мы можем как-нибудь заливать, можем подключить наши серваки к системе контроля версий и просто пулиться.
Дальше, данные.

Если у нас база данных, т.е. мы используем в нашем сервисе базу данных, у нас периодически возникает потребность с этими данными что-то делать. Нам нужно либо менять структуру базы данных, либо менять сами данные, т.е. если мы постоянно пишем какую-то новую функциональность, мы развиваемся, у нас неизбежно это происходит. В основном это осуществляется с помощью миграции. Наверное, все уже знают этот механизм. Если мы в разработке используем какой-то общепринятый фреймворк, не нами написанный, а который существует, все его знают, там миграции встроенные, т.е. обычными командами мы это все выполняем. Например, yii migrate, django-admin migrate.

Мало какой сервис не требует конфигурации. Мы заделиверили код, данные проапдейтили, у нас какие-то изменения случились, мы должны сконфигурировать. У нас есть конфиг файлы, там есть какие-то значения, мы их меняем, и в процессе жизни у нас тоже в эти конфиг файлы либо добавляются новые значения, либо старые деприкейтятся, они дропаются. После того, как у нас все это поменялось, нам нужно либо сервисы какие-нибудь рестартовать, либо оставить как есть.

Если мы не обошлись без использования стороннего программного обеспечения, мы должны позаботиться о том, что это ПО надо на наши сервера как-то поставить, сконфигурировать определенным образом, который нужен нам, и своевременно его апгрейдить. Или не апгрейдить, если вдруг в новой версии софта вышла какая-нибудь бага, чтобы у нас все не полегло.
Какие возникают решения «в лоб»?

У нас есть один сервачок, мы идем и делаем все это ручками, потому что все шаги известны, все известно, как делать. И у нас есть, допустим, команда разработки и команда эксплуатации — админ какой-нибудь сидит. Команда разработки пишет документацию о том, что вот сейчас такой релиз и для его успешного деплоя нужно сделать то-то, то-то и то-то. Админ смотрит на эту документацию, идет по SSH на сервак и это ручками и выполняется. Так он раз сходил, два сходил, потом ему это надоело.

Он, естественно берет, то, что общедоступно и под рукой. Он берет Bash, Perl и все это автоматизирует, потому что зачем все это делать руками, когда можно все это автоматизировать и просто запускать Bash.
Плюсы:

Это все просто, хорошо, быстро, мы работаем, код деливерится, мы ничего не замечаем, но это хорошо только до определенного времени, для простых проектов. У нас есть, допустим, один сервачок, на нем база данных, на ней наш код лежит — это вполне менеджебл одним человеком, и он может вполне с этим справляться.
Минусы:

Но мы же хотим развиваться, мы развиваемся. Наш сервис становится сложным, у нас появляются новые сервисы, приходит больше пользователей, мы больше не обходимся одним серваком, у нас уже появляются новые составляющие, т.е. у нас уже не один сервер с кодом, а у нас уже большой боевой контур, состоящий из нескольких серверов, компонентов и прочее. И у нас в связи с этой возрастающей сложностью, т.е. с нашим развитием, появляются проблемы, которых раньше не было. У нас увеличивается количество документации, т.е. информации о том, как специально обученному человеку провести релиз. Даже если у этого человека давно заготовлены скрипты, которые в определенных условиях хорошо выполняли свою работу, сложность этих скриптов у него тоже возрастает, их количество растет, теперь нужно не один сервер апгрейдить, а нужно апгрейдить базу, апгрейдить код, еще что-то надо делать. Сложность возрастает. Скрипты — это тоже тот софт, в котором могут быть баги, это тоже начинает приносить определенную головную боль.
Так как мы начали все это очень быстро делать, пока мы не испытывали особых проблем, у нас присутствует какое-то количество ручного труда. Сначала это не сильно заметно, а потом это нарастает как снежный ком, а ручной труд — это дополнительный источник человеческих ошибок. Кто-то что-то не так и не туда записал, или записал туда, но не так, второй неправильно скопипастил, и в итоге получается такая ситуация, когда очень много ошибок, и все они возникают, и не понятно, когда они закончатся и откуда берутся. В итоге, у нас этот специально обученный человек, который отвечал за релизы, только и делает, что релизит. Т.е. у него нет времени на какие-то другие его задачи, нет времени даже поесть. Он выкатил один релиз, пока его выкатывал, пришел второй релиз, во время этого релиза случились какие-то ошибки, потом еще пришел патч на этот релиз. В общем, этот большой такой головняк, нервозность возрастает, а бизнес к нам приходит и говорит: «Чего вы не можете до клиентов доставить код? Это ведь просто и быстро, а у нас тут еще вагон фич идет дальше, давайте чего-то с этим делать!».
Определенное время существует такой подход в нашей индустрии, как «Infrastructure as a code», который говорит нам, что мы должны подходить к описанию конфигурации нашего приложения так же, как мы подходим к разработке программного обеспечения. Так Кейф Моррис сказал:

Это немного больше, чем простая автоматизация, потому что автоматизация — это мы просто берем и все, что мы ручками делаем, загоняем в скрипт, и он работает. В подходе «Infrastructure as a code» мы используем все практики, тулзы и подходы. Мы берем это из разработки программного обеспечения нашего сервиса и применяем к описанию инфраструктуры. Т.е. если появился новый подход, соответственно, для его реализации со временем появляются и тулзы, т.е. программное обеспечение.
Какие инструменты есть?
Есть такой класс продуктов — Сonfiguration Management System, т.е. CMS (не путать с Content management system!). Типичные представители — Ansible, Chef, SaltStack, Puppet. Они созданы для того, чтобы нам, как разработчикам или как компаниям, помочь в управлении инфраструктурой. И одной из задач, одним из use case«ов применения такого ПО является приведение нашей системы в определенное описанное нами состояние. Т.е. если у нас есть, нам выделили абстрактный сервак, там ничего нет или там есть какая-нибудь голая ось, то с помощью таких инструментов мы приводим сервак в нужное нам состояние.
Давайте посмотрим на некоторые из этих инструментов. Я выбрал те, которые используются у нас в компании, чтобы на примерах объяснить. Во-первых, Anisble.

Это ПО достаточно простое для понимания, написано на Python, модульное, достаточно легко устанавливается и, как мы для себя отметили в компании, порог вхождения для использования Ansible достаточно низкий. Т.е. если мы берем человека, говорим: вот тебе Ansible, разберись и начни его использовать, он к концу недели бодренько пишет, все это там понимает.
Что нам нужно сделать после того, как мы установили Ansible?

Нам сначала нужно написать, а что у нас вообще есть, с чем нам хочется работать? Т.е. мы простой текстовый файлик создаем, и пишем как на примере выше, что у нас есть группа [webservers], у нас есть два экзампла — www.example1.com и www.example2.com, группа [dbservers], т.е. db1, db2. Это наш, грубо говоря, боевой контур, и с ним мы хотим работать.
Дальше, в Ansible есть такая сущность — playbook«и:

Playbook — это набор инструкций, т.е. те шаги, которые Ansible предстоит сделать, чтобы наши сервера привести в то состояние, которое нам нужно. Т.е. playbook«и состоят из hosts (мы указываем, с какими хостами мы хотим работать) и tasks –указываем те шаги, которые Ansible нужно сделать. И есть командочка — мы говорим: «Запусти этот playbook, информацию о хостах возьми из этого файла».
Пример playbook«а:

Мы указываем hosts (если кто запомнил — webservers). Это та группа хостов, которая у нас указана в Ansible инвенторе. Мы говорим, что хотим поставить nginx на те сервера, которые мы указали там.
Tasks состоят у нас в данном случае из двух шагов:
- мы сначала объявляем имя, чтоб нам потом можно было самим разобраться, что мы делаем, т.е. мы пишем Install nginx — этот шаг отвечает у нас за установку nginx«а и пишем в данном случае yum — это модуль Ansible, отвечающий за установку через yum. Мы говорим: «yum, поставь нам пакет nginx последней версии».
- следующий шаг — мы должны сконфигурировать nginx, поэтому мы модулю template говорим: «У нас в рамках этого playbook«а есть файл default.conf, положи его, пожалуйста, по этому пути, и после того, как ты это сделал, т.е. notify, перестартуй nginx».
Мы запускаем командочку ansible-playbook с этим playbook«ом, и после выполнения этого playbook«а у нас на серверах группы webservers получается установленный nginx, настроенный как нам надо.
Архитектура выглядит примерно так:
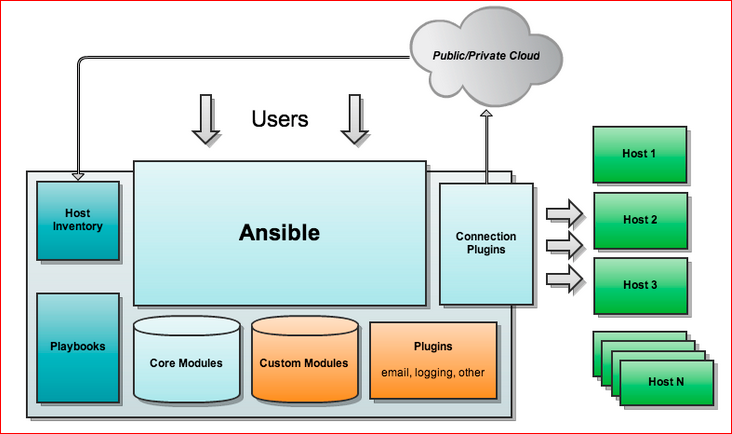
Я взял это из Интернета, эту картинку можно свободно нагуглить. У нас есть Host Inventory, Playbooks, Core Modules — это модули, которые написаны самой командой Ansible, что, как раз, отвечает yum, apt и прочее; Custom Modules — это то, что там написано комьюнити или еще какими-нибудь контрибуторами; Plugins. Запускается Ansible, идет по хостам и выполняет то, что ему нужно. Примечательно то, что на тех хостах, с которыми мы работаем, нам дополнительного ПО не надо, т.е. у нас как наши серваки стояли-работали, так они и работают. Там должен быть, по-моему, только Python, но Python есть практически везде.
С этим вкратце понятно, давайте для сравнения посмотрим Chef.

Chef — это того же класса ПО, но написано другой компанией. По моему мнению, оно немного сложнее, даже может быть намного сложнее, чем Ansible, потому что у нас, если человек к концу недели начинает писать и разбирается в Ansible, и начинает уже выдавать какой-то код, а с Chef ему несколько недель разбираться, как там что работает, какие фишки, чтобы выдавать какой-то результат.
Какими мы здесь оперируем терминами?

- Cookbooks — это рецепты. Если в случае Ansible человекочитаемо все, хорошо, понятно, то в случае с Chef cookbooks — это у нас Ruby, здесь потребуется какое-то время, чтобы освоить, если не полностью, но какой-то базовый уровень этого языка программирования.
- Еще у нас есть Roles — способы группировки Cookbooks. Допустим, у нас есть роль «вебсервер» для настройки вебсервера. Нам нужно поставить nginx, сконфигурить, еще что-то сделать, поприседать и прочее. Это у нас разбито на несколько cookbooks, и мы делаем отдельную роль — «вебсервер», в которой говорим, что эти cookbooks туда входят, и эту роль назначаем на нужные нам серваки. И тогда мы видим, что у нас есть столько-то вебсерверов, и такими способами мы приводим их в нужное состояние.
- Есть у нас Environment — описание нашего окружения, т.е. если у нас есть девелопмент окружение, стейжинг окружение, есть продакш окружение, которое отличается какими-то настройками, т.е. мы здесь имеем возможность, по-моему, в JSON описать, объявить список переменных, которыми отличаются наши окружения, соответственно значения для каждого окружения прописать.
Chef существует в нескольких конфигурациях, т.е. как его можно установить.
- Chef server.
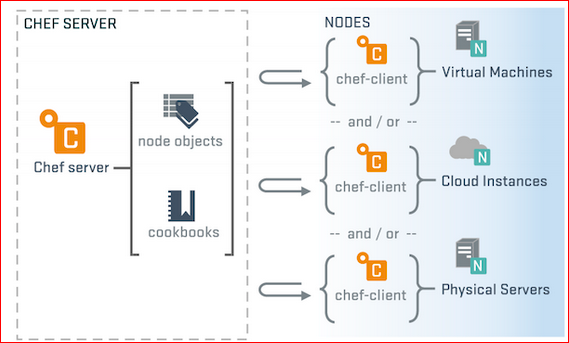
Мы ставим отдельный сервак где-то в нашем окружении, в котором хранятся все наши cookbooks, роли, environment, ноды с описанием и прочее.
На каждой ноде нашей стоит клиентское ПО — Chef client, которое настроено на этот сервак. И оно ходит туда за описанием этой ноды, т.е. она приходит и
говорит: «Я такая вот нода, скажи мне, пожалуйста, что у меня есть по ролям, по каким-нибудь дополнительным настройкам, по рецептам, что мне нужно
сделать?». Chef сервак ей отвечает: «Вот, выполняй, пожалуйста, эти рецепты с такими вот входными параметрами», и утилитка все это применяет.Если кто обратил внимание, в Ansible немного по-другому, т.е. в случае с Chef сервером, мы, во-первых, ставим дополнительное ПО на наши ноды, и мы заходим
на сами ноды, либо как-то удаленно должны позвать этот Chef client. В Ansible мы говорим Ansible playbook на нашей рабочей тачке, и он идет сам по SSH
выполняет все на наших серверах.Но это одна конфигурация Chef.
- Дальше у нас есть Chef zero — это лайтовый вариант Chef Server, т.е. без gui, он in memory, т.е. мы просто его такого легковесного подняли, загрузили туда всю нашу информацию для тестирования, проверили все это, задеплоили, убили Chef zero, и у нас все освободилось — все хорошо.
- Также есть Chef solo — это open source версия утилитки Chef client, которая в отличие от первых двух случаев не требует подключения к какому-то внешнему серваку. Нам тут не нужен ни Chef server, ни Chef zero, мы просто в этом случае говорим Chef solo, что: «У нас есть путь, по которому лежат наши рецепты, выполни, пожалуйста, оттуда такие-то вот рецепты». В такой конфигурации мы получаем, что все наши cookbooks, рецепты должны находиться в нужный нам момент времени на том же инстансе, где у нас расположен Chef solo.
Это простой пример, как выглядит установка nginx на Chef в рецептах.

Я хочу отметить, что это очень маленькая часть функциональности этих всех инструментов, которые я упомянул, т.е. там есть гораздо больше возможностей, use case«ов, составляющих и прочее. Это большие сложные инструменты, они решают широкий круг задач, но сейчас в рамках этого доклада, мы говорим только об одном use case«е — как нам задеплоиться.
Допустим, мы что-то посмотрели, определились, решили, что нам подходит какой-то инструмент, и что же нас ждет помимо каких-то технических вопросов? Мы же работаем в команде. Мы можем сказать, что с сегодняшнего дня мы используем, допустим, Ansible. Хорошо, что мы дальше получаем?
Получаем новые процессные вопросы — это зона ответственности, т.е. я, как team leader, решаю, что теперь мы используем Ansible, но у меня стоит вопрос, кто у меня должен писать playbooks?

Разработчики? Они ко мне приходят и говорят: «Мы не будем писать playbooks, потому что мы не знаем боевую конфигурацию». Хорошо, я иду к админам и говорю: «Теперь вы пишете playbooks». Они говорят: «Мы playbooks писать, извини, не будем, потому что мы не знаем приложения». Это пример из воздуха для понимания. И эту ситуацию мы должны как-то резолвить, потому что получается, что знания для написания playbooks, рецептов у нас размазаны. Часть знаний у нас есть в одной команде, часть — в другой команде.
Приведу пример, как такую штуку мы решали у себя в отделе. У нас есть много продуктов, сервисов, и они разной степени сложности. И один очень сложный высоконагруженный наш проект — это Web API. Мы сделали так: у нас админы взяли Chef, написали всю базу. У нас 3 датацентра по 18 серверов, децентрализация и прочее. И такие таски админы взяли на себя, написали всю эту конфигурацию, раздеплоились во все датацентры, убедились, что все это работает. Потом в процессе жизни продукта, когда меняются те параметры, о которых админы не знают, как я приводил пример — т.е. у нас в кофиге что-то поменялось, мы начали использовать другие еще какие-то утилитки… Это все то, что решается в процессе разработки продукта. Админы пришли, научили разработчиков писать playbooks, рассказали, что такое Chef, с чем его едят, как готовить, и потом после этого момента команда разработки сама начала писать эти playbooks. Когда изменения у нас критичные или очень сложные, рискованные, то команда разработки берет, и сама это пишет и просто на ревью отдает админам, и они смотрят, как это будет ложиться в текущую инфраструктуру и оставляет какие-то комментарии.
Другие же сервисы попроще. Они взяли, и посмотрели, что Chef для нас — это слишком сложно, избыточно и прочее. Они взяли Ansible, сами написали, быстренько разобрались, сами все написали, пришли к админам и сказали: «Посмотрите, можно ли так?». Те посмотрели и сказали: «Да, нет, не знаю, может быть».
С зоной ответственности возникает вопрос. Серебряной пули, как и практически везде, нет. Нужно так резолвить, наверное, в каждом проекте, в каждом сервисе по-своему.
И, естественно, у нас меняется workflow. У нас появляются новые таски, инструментарии, и workflow разработки у нас меняется.
Если с написанием, все понятно — мы чего-то посмотрели, изучили, нам предоставили инстанс этого Chef сервера или еще что-то, мы взяли любимый текстовый редактор, как-то приноровились, начали писать… Но возникает следующий вопрос — нам же надо как-то это все тестировать, потому что у нас получается точно такой же код, как он себя ведет, нам нужно тоже понимать. И если на этом моменте не дай бог, разработчики свой сервис деплоят себе же на рабочей тачке, то здесь все плохо и печально и без виртуализации здесь не обойдешься. Потому что мне надо поднять тачку, вдруг я там написал что-то плохое, что все сломалось, мне нужно это все быстренько убить, передеплоить, пофиксить, передеплоить, посмотреть, как что работает… Я знаю, я видел такие команды, видел такие компании, которые до сих пор виртуализацию не используют вообще никак. Может, это нормально так, допустимо, но я лично не понимаю, как можно без виртуализации жить. Если мы деплоимся на своей тачке, и виртуализации нет, то в этом моменте она просто необходима.
Vagrant — это не инструмент для тестирования, но это то, что может нам помочь быстро посмотреть. Что это такое Vagrant? Это ПО для создания виртуальной среды. Это обертка над многими провайдерами виртуализации, как виртуал бокс, ВМ варь и прочее. И плюс — у него еще есть интеграция с вышеуказанными системами конфигурации, т.е. с Chef, Ansible, с Puppet.
Чтобы развернуть мне тачку, т.е. я поставил себе Vagrant и мне нужно просто сделать vagrant init — это я указываю, дистрибутив чего мне нужно.

У меня в текущей директории появляется vagrant файл — конфигурационный файл моей будущей виртуалки. И в этой же директории я говорю: «vagrant up» и через некоторое время на моем хосте поднимается виртуальная машина, где я могу делать, что хочу, потом ее грохнуть и еще чего-нибудь, т.е. делаю с ней, что хочу.
Вот быстренький пример, про Chef solo:

В Vagrant файле я пишу, что у меня в provision’e Chef solo, мои cookbooks располагаются вот там-то и, пожалуйста, на эту машину добавь мне рецепт, который у меня называется «apache» и отвечает за установку apache.
Тогда, когда я говорю «vagrant up» для этой машины, она поднимается, и выполняется этот рецепт, который устанавливает apache.
Vagrant«a самого не достаточно для тестирования. Я видел в программе RootConf«а есть отдельный доклад по поводу того, как тестировать инфраструктуру. Там рассказывают именно о тестовых фреймворках, который позволяют тестировать инфраструктуру. Я знаю, что существует test kitchen, который основан на Vagrant«e, и он позволяет писать тесты, когда у нас он поднимает виртуальную машину, и ему указываешь: привяжи мне систему, виртуализацию… Потом говоришь: у меня есть набор тестов, которые выглядят достаточно просто, нам же нужно проверить, что у нас все поставилось, что демоны запустились, нужные нам файлы лежат в определенном месте. Собственно, мы пишем такого рода тесты, и он их после поднятия виртуальной машины, прогоняет и говорит «OK» либо «не OK».
Это все самые простые варианты, т.е. тестирование инфраструктуры — это тоже отдельная большая тема. Мы с вами чуть-чуть приоткрыли дверку в этот мир, но там еще много вопросов, много техник и прочее.
Что бы хотелось порекомендовать, с чего начать? Инструменты большие, информации много, хочется взять попробовать. От себя могу сказать, что рекомендации такие — если у нас есть какой-нибудь маленький простой сервис, то берите то, что уже известно, т.е. поставить nginx или postgres и прочее. Попробовать начать с маленького, написать рецепт, playbook, выполнить простые общеизвестные действия, тогда можно будет понять, нужно вам это на данном этапе, или вас до сих пор баш-скрипты устраивают, или ручками вы делаете. Понять, нужно ли вам это. И понять, что вам удобнее.
Я тут ссылочки привел:
- https://galaxy.ansible.com
- https://supermarket.chef.io/cookbooks
- https://docs.ansible.com/playbooks_best_practices.html
У каждого инструмента существуют комьюнити, бестпрактисы, репозитории с написанными cookbooks, т.е. все известное ПО, которое нужно устанавливать, конфигурить и прочее. По поводу этого уже написаны все playbooks, выработаны бестпрактисы, и мы идем в эти супермаркеты или в Galaxy и просто берем, что нам нужно — как кубики — и выполняем, формируем, так у нас получается готовая инфраструктура.
По поводу такого немаловажного аспекта, как стоимость, можно сказать, что эти продукты в основном бесплатные. Сhef начал с 12-ой версии хотеть денег, поэтому многие сидят на 11-ой версии до сих пор, а Ansible хотят денег за веб-морду, Ansible tower это, по-моему, называется. А в остальных конфигурациях все это можно взять бесплатно и быстро применить.
Контакты
» Блог компании 2ГИС
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior.
Комментарии (1)
 kafeman
kafeman
11 января 2017 в 16:52
0↑
↓
FTP/SFTP, rsync, git pull… Интересно, старые добрые пакетные менеджеры уже не в моде?И еще не понятно: такая большая часть статьи посвящена Ansible и Chef, но это же, как вы сами пишете, только менеджеры конфигурации. А статья называется «деплой», и это подразумевает нечто большее, разве не так? Прежде чем что-то конфигурировать, это что-то нужно еще собрать/скомпилировать (возможно, стоило бы получше раскрыть тему CI и build-серверов?) и как-нибудь красиво доставить на сервер (например, упомянутыми выше менеджерами пакетов).
