[Перевод] Повышаем производительность кода: сначала думаем о данных

Занимаясь программированием рендеринга графики, мы живём в мире, в котором обязательны низкоуровневые оптимизации, чтобы добиться GPU-фреймов длиной 30 мс. Для этого мы используем различные методики и разработанные с нуля новые проходы рендеринга с повышенной производительностью (атрибуты геометрии, текстурный кеш, экспорт и так далее), GPR-сжатие, скрывание задержки (latency hiding), ROP…
В сфере повышения производительности CPU в своё время применялись разные трюки, и примечательно то, что сегодня они используются для современных видеокарт ради ускорения вычислений ALU (Низкоуровневая оптимизация для AMD GCN, Быстрый обратный квадратный корень в Quake).
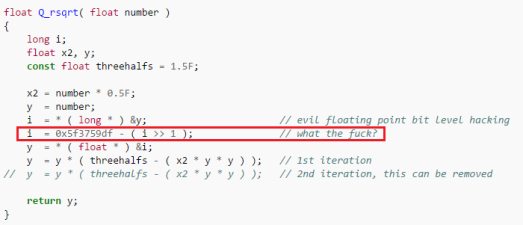
Быстрый обратный квадратный корень в Quake
Но в последнее время, особенно в свете перехода на 64 бита, я заметил рост количества неоптимизированного кода, словно в индустрии стремительно теряются все накопленные ранее знания. Да, старые трюки вроде быстрого обратного квадратного корня на современных процессорах контрпродуктивны. Но программисты не должны забывать о низкоуровневых оптимизациях и надеяться, что компиляторы решат все их проблемы. Не решат.
Эта статья — не исчерпывающее хардкорное руководство по железу. Это всего лишь введение, напоминание, свод базовых принципов написания эффективного кода для CPU. Я хочу «показать, что низкоуровневое мышление сегодня всё ещё полезно», даже если речь пойдёт о процессорах, которые я мог бы добавить.
В статье мы рассмотрим кеширование, векторное программирование, чтение и понимание ассемблерного кода, а также написание кода, удобного для компилятора.
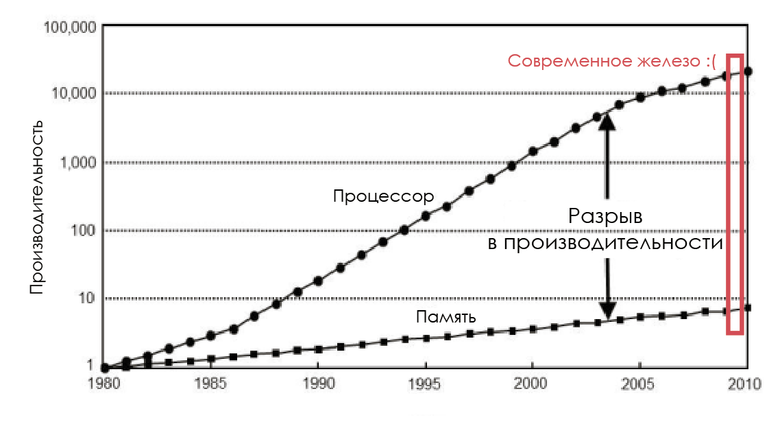
Не забывайте о разрыве
В 1980-е частота шины памяти равнялась частоте CPU, а задержка была почти нулевой. Но производительность процессоров логарифмически росла в соответствии с законом Мура, а производительность чипов ОЗУ увеличивалась непропорционально, так что вскоре память стала узким местом. И дело не в том, что нельзя создать более быструю память: можно, но невыгодно экономически.
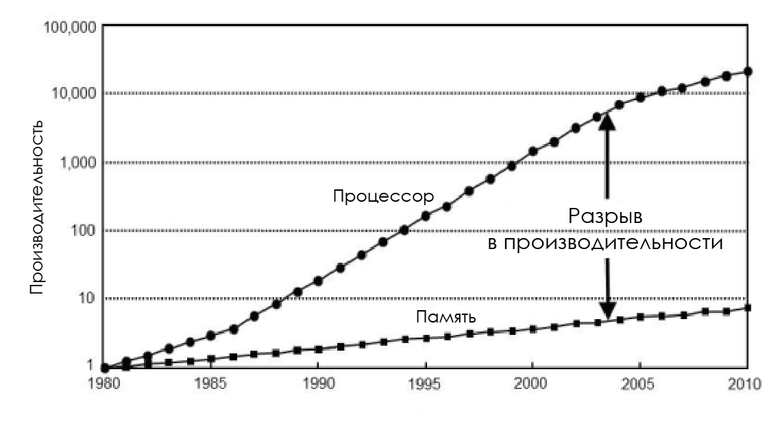
Изменение скорости процессоров и памяти
Чтобы снизить влияние производительности памяти, разработчики CPU добавили крохотное количество этой очень дорогой памяти между процессором и основной памятью — так появился кеш процессора.
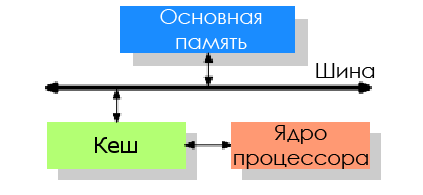
Идея такова: есть неплохая вероятность, что в течение короткого промежутка времени снова может потребоваться тот же код или данные.
- Пространственная локальность: циклы в коде, так что один и тот же код исполняется раз за разом.
- Временная локальность: даже если участки памяти, использовавшиеся в течение коротких промежутков времени, не находятся рядом друг с другом, то всё равно высока вероятность, что те же данные вскоре будут использованы вновь.
Кеш CPU — это сложная методика повышения производительности, но без помощи программиста она не будет работать корректно. К сожалению, многие разработчики не представляют себе стоимости использования памяти и структуры кеша CPU.
Архитектура, ориентированная на обработку данных
Нас интересуют игровые движки. Они обрабатывают всё увеличивающиеся объёмы данных, преобразуют их и выводят на экран в реальном времени. Учитывая это, а также необходимость решения проблем с эффективностью, программист обязан понимать, какие данные он обрабатывает, и знать оборудование, с которым будет работать его код. Следовательно, он должен осознавать необходимость внедрения архитектуры, ориентированной на данные (data oriented design, DoD).
А может, за меня это сделает компилятор?

Простое добавление. Слева — C++, справа — получившийся код на ассемблере
Давайте рассмотрим вышеприведённый пример применительно к процессору AMD Jaguar (похожему на те, что используются в игровых приставках) (полезные ссылки: AMD«s Jaguar Microarchitecture: Memory Hierarchy, AMD Athlon 5350 APU and AM1 Platform Review — Performance — System Memory):
- Операция загрузки (около 200 циклов без кеширования)
- Фактическая работа: inc eax (1 цикл)
- Операция хранения (~3 цикла, та же кеш-строка)
Даже в таком простом примере большая часть времени процессора тратится на ожидание данных, и в более сложных программах ситуация не становится лучше, пока программист не уделит внимание базовой архитектуре.
Если кратко, компиляторы:
- Не видят всю картину, им очень трудно спрогнозировать, как будут организованы данные и как к ним будут обращаться.
- Могут хорошо оптимизировать арифметические операции, но иногда эти операции — лишь вершина айсберга.
У компилятора довольно мало пространства для манёвра, когда речь идёт об оптимизации доступа к памяти. Контекст известен только программисту, и только он знает, какой код хочет написать. Поэтому вам необходимо понимать течение информационных потоков и в первую очередь исходить из обработки данных, чтобы выжать всё возможное из современных CPU.
Жестокая правда: ООП против DoD
Влияние схемы доступа к памяти на производительность (Mike Acton GDC15)
Объектно ориентированное программирование (ООП) сегодня — доминирующая парадигма, именно её в первую очередь изучают будущие программисты. Она заставляет мыслить в терминах объектов реального мира и их взаимоотношений.
В классе обычно инкапсулирован код и данные, поэтому объект содержит всю свою информацию. Заставляя применять массивы структур (array of structures) и массивы *указателей на* структуры/объекты, ООП нарушает принцип пространственной локальности, на котором базируется ускорение доступа к памяти с помощью кеша. Помните о разрыве между производительностью процессоров и памяти?
Чрезмерное инкапсулирование идёт во вред при работе на современном железе.
Я хочу сказать вам, что при разработке ПО нужно сместить акцент с самого кода на понимание преобразований данных, а также отреагировать на сложившуюся культуру программирования и положение вещей, навязанное сторонниками ООП.
В заключение хочу процитировать три больших лжи, сказанных Майком Эктоном (Mike Acton) (CppCon 2014: Mike Acton, «Data-Oriented Design and C++»)
- Программное обеспечение — это платформа
- Нужно понимать железо, с которым вы работаете
- Архитектура кода формируется по модели мира
- Архитектура кода должна соответствовать модели данных
- Код важнее данных
- Память — узкое место, данные — однозначно самая важная вещь
Изучить железо
Кеш микропроцессора
Процессор физически не подключён напрямую к основной памяти. Все операции с оперативной памятью (загрузка и хранение) на современных процессорах выполняются через кеш.
Когда процессор занят командой вызова (загрузки), контроллер памяти сначала ищет в кеше запись с тегом, соответствующим адресу памяти, по которому ему нужно выполнить чтение. Если такая запись обнаруживается — то есть случается попадание в кеш, — то данные могут быть загружены напрямую из кеша. Если нет — промах кеша, — то контроллер попытается извлечь данные из более низких уровней кеша (например, сначала L1D, затем L2, затем L3) и, наконец, из оперативной памяти. Затем данные будут сохранены в L1, L2 и L3 (инклюзивный кеш).
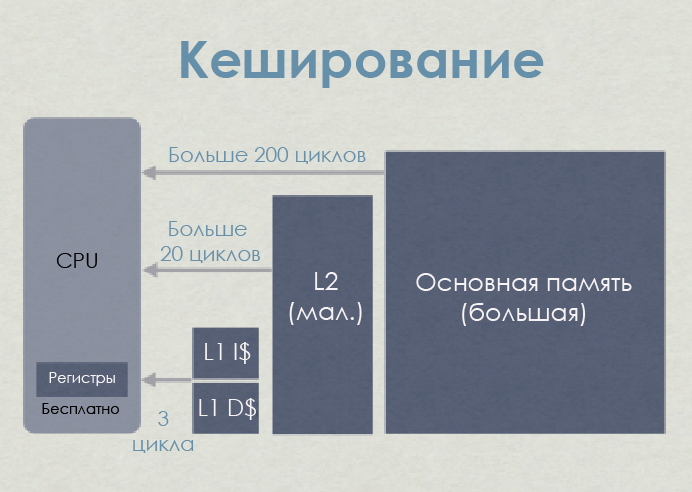
Задержка памяти на приставках — Jason Gregory
На этой упрощённой иллюстрации процессор (AMD Jaguar, используемый в PS4 и XB1) имеет два уровня кеша — L1 и L2. Как видите, кешируются не просто данные, L1 разделён на кеш кодовых инструкций (code instruction) (L1I) и кеш данных (L1D). Области памяти, необходимые для кода и данных, независимы друг от друга. В целом L1I создаёт куда меньше проблем, чем L1D.
С точки зрения задержки L1 на порядки быстрее, чем L2, который в 10 раз быстрее основной памяти. В числах выглядит грустно, но не за каждый промах кеша приходится платить полную цену. Можно снизить расходы с помощью сокрытия задержки (hiding latency), диспетчеризации и так далее, но это уже выходит за рамки поста.

Задержка обращения к памяти — Andreas Fredriksson
Каждая запись в кеше — кеш-строка — содержит несколько смежных слов (64 байта для AMD Jaguar или Core i7). Когда CPU исполняет инструкцию, извлекающую или сохраняющую значение, вся кеш-строка передаётся в L1D. В случае с сохранением та кеш-строка, в которую делается запись, помечается как грязная (dirty), пока не будет сделана запись обратно в оперативную память.
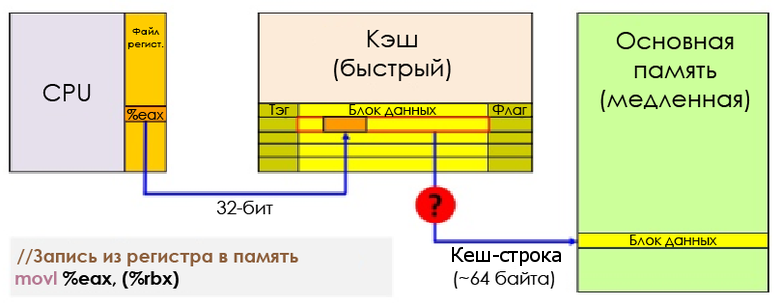
Запись из регистра в память
Чтобы иметь возможность загрузить в кеш новые данные, почти всегда необходимо сначала освободить место, выселив (evict) кеш-строку.
- Эксклюзивный кеш (Exclusive cache): при извлечении кеш-строка перемещается из L1D в L2. Это значит, что в L2 должно быть выделено место, что может привести к переносу данных снова в основную память. Перенос извлекаемой строки из L1D в L2 влияет на задержку при промахе кеша.
- Инклюзивный кеш (Inclusive cache): каждая кеш-строка в L1D представлена также и в L2. Извлечение из L1D происходит гораздо быстрее и не требует никаких дальнейших действий.
Свежие процессоры Intel и AMD используют инклюзивный кеш. Поначалу это может выглядеть ошибочным решением, но у него есть два преимущества:
- Он снижает задержку при промахе кеша, поскольку нет необходимости переносить кеш-строку на другой уровень при извлечении.
- Если одному ядру нужны данные, с которыми работает другое ядро, то оно может извлечь самую свежую версию из верхних уровней кеша, без прерывания работы другого ядра. Поэтому инклюзивный кеш стал очень популярен с развитием многоядерных архитектур.
Коллизии кеш-строки: хотя несколько ядер могут эффективно считывать кеш-строки, операции записи могут приводить к снижению производительности. Понятие »ложное разделение» (False sharing) означает, что разные ядра могут изменять независимые данные, находящиеся в одной кеш-строке. Согласно протоколам согласованности кеша (cache coherence protocols), если ядро пишет в кеш-строку, то строка в другом ядре, ссылающаяся на ту же память, признаётся недействительной (пробуксовка кеша, cache trashing). В результате при каждой операции записи возникают блокировки памяти. Ложного разделения можно избежать, сделав так, чтобы разные ядра работали с разными строками (использовав дополнительное пространство — extra padding, выровняв структуры по 64 байта и так далее).

Избегаем ложного разделения, в каждом треде записывая данные в разные кеш-строки
Как видите, понимание аппаратной архитектуры — это ключ к обнаружению и исправлению проблем, которые в противном случае могут остаться незамеченными.
Coreinfo — утилита, работающая из командной строки. Она предоставляет подробную информацию обо всех наборах инструкций, находящихся в процессоре, а также сообщает, какие кеши приписаны к каждому логическому процессору. Вот пример для Core i5–3570K:
*--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*--- Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64
**** Unified Cache 1, Level 3, 6 MB, Assoc 12, LineSize 64
-*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64
--*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
--*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
--*- Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64
---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
---* Unified Cache 4, Level 2, 256 KB, Assoc 8, LineSize 64Здесь кеш L1 на 32 Кб, кеш инструкций L1 на 32 Кб, кеш L2 на 256 Кб, и кеш L3 на 6 Мб. В этой архитектуре L1 и L2 приписаны к каждому ядру, а L3 используется совместно всеми ядрами.
В случае с AMD Jaguar CPU каждое ядро имеет выделенный кеш L1, а L2 используется совместно группами по 4 ядра — кластерами (в Jaguar нет L3).
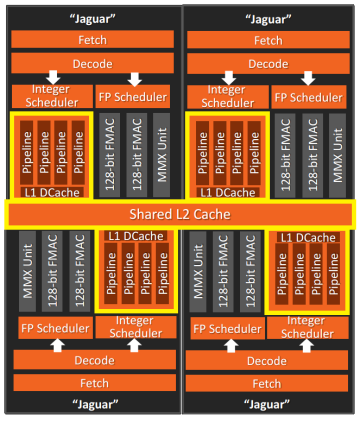
4-ядерный кластер (AMD Jaguar)
Работая с такими кластерами, следует проявлять особую осторожность. Когда ядро делает запись в кеш-строку, она может стать недействительной в других ядрах, что снижает производительность. Причём при такой архитектуре всё может стать ещё хуже: извлечение ядром данных из ближайшего L2, расположенного в том же кластере, занимает около 26 циклов, а извлечение из L2 другого кластера может занять до 190 циклов. Сопоставимо с извлечением данных из оперативной памяти!
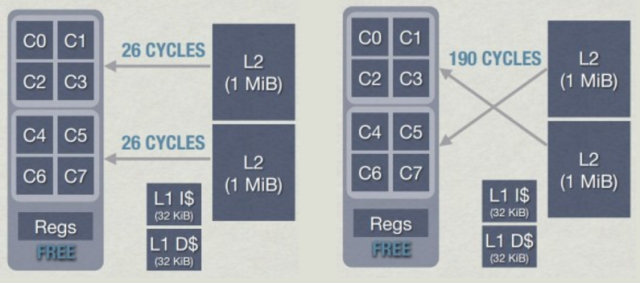
Задержка L2 в кластерах в AMD Jaguar — Jason Gregory
За дополнительной информацией о согласованности кеша обратитесь к статье Cache Coherency Primer.
Основы ассемблераx86–64 бит, x64, IA-64, AMD64… или рождение архитектуры x64
Intel и AMD разработали свои собственные 64-битные архитектуры: AMD64 и IA-64. IA-64 разительно отличается от процессоров x86–32 бит в том смысле, что ничего не унаследовала от архитектуры x86. Приложения под x86 должны работать на IA-64 через уровень эмуляции, следовательно, у них на этой архитектуре низкая производительность. Из-за нехватки совместимости с x86 IA-64 так и не взлетела, если не считать коммерческой сферы. С другой стороны, AMD создала более консервативную архитектуру, расширив имевшуюся свою x86 новым набором 64-битных инструкций. Intel, проигравшая 64-битную войну, была вынуждена внедрить те же расширения в свои x86-процессоры. В этой части мы рассмотрим x86–64 бит, также известную как архитектура x64, или AMD64.
В течение многих лет PC-программисты использовали x86-ассемблер для написания высокопроизводительного кода: mode«X', CPU-Skinning, коллизии, программные растеризаторы (software rasterizers)… Но 32-битные компьютеры медленно заменялись 64-битными, и ассемблерный код тоже изменился.
Знать ассемблер необходимо, если вы хотите понимать, почему одни вещи работают медленно, а другие быстро. Также это поможет понять, как использовать intrinsic-функции для оптимизирования критических частей кода, и как отлаживать оптимизированный (например, -О3) код, когда отладка на уровне исходного кода уже не имеет смысла.
Регистры
Регистры — это маленькие фрагменты очень быстрой памяти с почти нулевой задержкой (обычно один процессорный цикл). Они используются в качестве внутренней памяти процессора. В них хранятся данные, напрямую обрабатываемые процессорными инструкциями.
x64-процессор имеет 16 регистров общего назначения (general-purpose register, GPR). Они не используются для хранения конкретных типов данных, во время исполнения в них находятся операнды и адреса.
В x64 восемь x86-регистров расширены до 64 бит, а также добавлено 8 новых 64-битных регистра. Имена 64-битных регистров начинаются с r. Например, 64-битное расширение eax (32-битного) называется rax. Новые регистры проименованы с r8 по r15.

Общая архитектура (software.intel.com)
В число регистров x64 входят:
- 16 64-битных регистров общего назначения (GPR), из них первые восемь называются rax, rbx, rcx, rdx, rbp, rsi, rdi и rsp. Вторые восемь: r8—r15.
- 8 64-битных MMX-регистров (набор MMX-инструкций), покрывающий регистры с плавающей запятой fpr (x87 FPU).
- 16 128-битных векторных XMM-регистров (набор SSE-инструкций).
В более новых процессорах:
- 256-битные YMM-регистры (набор AVX-инструкций), расширяющие XMM-регистры.
- 512-битные ZMM-регистры (набор AVX-512 инструкций), расширяющие XMM-регистры и увеличивающие их количество до 32.

Взаимосвязи между ZMM-, YMM- и XMM-регистрами
По историческим причинам несколько GPR называются иначе. Например, ax был регистром Accumulator, cx — Counter, dx — Data. Сегодня большинство из них потеряли своё специфическое предназначение, за исключением rsp (Stack Pointer) и rbp (Base Pointer), которые зарезервированы для управления аппаратным стеком (hardware stack) (хотя rbp часто может быть «оптимизирован» и использоваться как GRP — omit frame pointer в Clang).
К младшим битам x86-регистров можно обращаться с помощью субрегистров. В случае с первыми восемью x86-регистрами используются легаси-названия. Более новые регистры (r8—r15) используют такой же, только упрощённый подход:
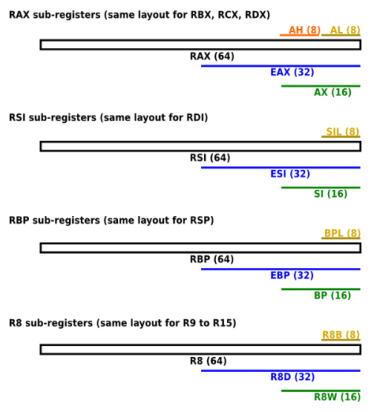
Поименованные скалярные регистры
Адресация
Когда ассемблерным инструкциям требуется два операнда, то обычно первый — пункт назначения (destination), а второй — источник. Каждый из них содержит данные, которые надо обработать, или адрес данных. Есть три основных режима адресации:
- Немедленная
- mov eax, 4; перемещает 4 в eax
- Из регистра в регистр
- mov eax, ecx; перемещает содержимое ecx в eax
- Косвенная:
- mov eax, [ebx]; перемещает 4 байта (размер eax) по адресу ebx в eax
- mov byte ptr [rcx], 5; перемещает 5 в byte по адресу rcx
- mov rdx, dword ptr [rcx+4*rax]; перемещает dword по адресу rcx+4*rax в rdx
dword ptr называется директивой размера (size directive). Она говорит ассемблеру, какой размер следует брать, если существует неопределённость по размеру области памяти, на которую ссылаются (например: mov [rcx], 5: должен записать байт? dword?).
Это может означать: байт (8-бит), word (16-бит), dword (32-бит), qword (64-бит), xmmword (128-бит), ymmword (256-бит), zmmword (512-бит).
Наборы SIMD-инструкций
Скалярная реализация обозначает операции с одной парой операндов за раз. Векторизация — это процесс преобразования алгоритма, когда вместо работы с одиночными порциями данных за раз он начинает обрабатывать по несколько порций за раз (ниже мы посмотрим, как он это делает).
Современные процессоры могут использовать преимущества набора SIMD-инструкций (векторные инструкции) для параллельной обработки данных.
SIMD-обработка
Наборы SIMD-инструкций, которые доступны в x86-процессорах:
- Multimedia eXtension (MMX)
- Легаси. Поддерживает арифметические операции над целочисленными значениями, упакованными в 64-битные векторные регистры.
- Streaming SIMD Extensions (SSE)
- Арифметические операции над числами с плавающей запятой, упакованными в 128-битные векторные регистры. В SSE2 была добавлена поддержка целочисленных и значений с двойной точностью.
- Advanced Vector Extensions (AVX) — только x64
- Добавлена поддержка 256-битных векторных регистров.
- AVX-512 — только x64
- Добавлена поддержка 512-битных векторных регистров.
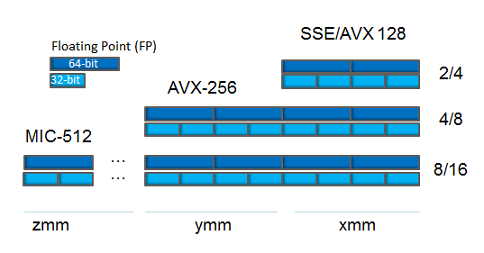
Векторные регистры в x64-процессорах
Игровые движки обычно тратят 90% времени исполнения на запуск маленьких порций кодовой базы, в основном итерируя и обрабатывая данные. В подобных сценариях SIMD может иметь большое значение. SSE-инструкции обычно применяют для параллельной обработки наборов из четырёх значений с плавающей запятой, упакованных в 128-битные векторные регистры.
SSE в основном ориентировано на вертикальное представление (структура массивов — Structure of Arrays, SoA) данных и их обработку. Но вообще-то производительность SoA по сравнению с Array of Structures (AoS) зависит от шаблонов доступа к памяти.
- AoS, вероятно, самый естественный вариант, простой в написании. Удовлетворяет парадигме ООП.
- У AoS лучше локальность данных, если выполняется доступ ко всем членам вместе.
- SoA предлагает больше возможностей по векторизации (вертикальная обработка).
- SoA зачастую использует меньше памяти благодаря применению паддинга только между массивами.
// Array Of Structures
struct Sphere
{
float x;
float y;
float z;
double r;
};
Sphere* AoS;
Размещение в памяти (структура выравнена по 8 байтов):
------------------------------------------------------------------
| x | y | z | r | pad | x | y | z | r | pad | x | y | z | r | pad
------------------------------------------------------------------
// Structure Of Arrays
struct SoA
{
float* x;
float* y;
float* z;
double* r;
size_t size;
};
Размещение в памяти:
------------------------------------------------------------------
| x | x | x ..| pad | y | y | y ..| pad | z | z | z ..| pad | r..
------------------------------------------------------------------
AVX — это естественное расширение SSE. Размер векторных регистров увеличивается до 256 битов, это означает, что до 8 чисел с плавающей запятой могут быть упакованы и параллельно обработаны. Процессоры Intel изначально поддерживают 256-битные регистры, а с AMD могут быть проблемы. Ранние AVX-процессоры AMD, такие как Bulldozer и Jaguar, раскладывают 256-битные операции на пары 128-битных, что увеличивает задержку по сравнению с SSE.
В заключение скажу, что не так-то просто ориентироваться исключительно на AVX (может быть, для внутренних инструментов, если ваши компьютеры работают на Intel), а AMD-процессоры по большей части не поддерживают их нативно. С другой стороны, на любых x64-процессорах можно априори рассчитывать на SSE2 (это часть спецификации).
Внеочередное исполнение
Если конвейер (pipeline) процессора работает в режиме внеочередного исполнения (Out-of-Order, OoO), то исполнение инструкций может задерживаться из-за неготовности необходимых входных данных. В этом случае процессор пытается найти более поздние инструкции, чьи входные данные уже готовы, чтобы выполнить сначала вне очереди.
Цикл выполнения команды (instruction cycle) (или цикл «получение — декодирование — исполнение») — это процесс, в ходе которого процессор получает инструкцию из памяти, определяет, что с ней нужно делать, и исполняет её. Цикл выполнения команды в режиме внеочередного исполнения выглядит так:
- Получение/декодирование: инструкция извлекается из L1I (кеш инструкций). Затем она преобразуется в более мелкие операции, называющиеся микрооперациями, или µops.
- Переименование: из-за существующих зависимостей между регистром и данными может возникнуть блокировка исполнения. Для решения этой проблемы и устранения ложных зависимостей процессор предоставляет набор безымянных внутренних регистров, использующихся для актуальных вычислений. Переименование регистра — это процесс преобразования ссылок на архитектурные регистры (логические) в ссылки на безымянные регистры (физические).
- Буфер переупорядочивания (Reorder Buffer): он содержит ожидающие исполнения микрооперации, хранящиеся в порядке поступления, а также уже выполненные, но ещё не выбывшие (retired).
- Диспетчеризация: микрооперации, хранящиеся в буфере переупорядочивания, могут быть в любом порядке переданы в модули параллельного исполнения, с учётом зависимостей и доступности данных. Результат микрооперации записывается обратно в буфер переупорядочивания вместе с самой микрооперацией.
- Увольнение: модуль выбывания (retirement unit) постоянно проверяет статус микроопераций в буфере, записывает результаты исполненных микроопераций обратно в архитектурные регистры (доступные пользователю), а затем убирает микрооперации из буфера.
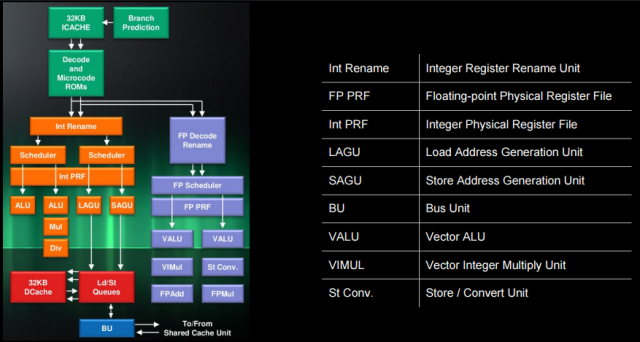
Архитектура процессора AMD Jaguar
В архитектуре процессора AMD Jaguar мы можем обнаружить все вышеупомянутые блоки. Для целочисленного конвейера:
- «Decode and Microcode ROMs»
- = модуль получения/декодирования
- «Int Rename» and «Int PRF» (физический регистровый файл)
- = модуль переименования
- Модуль управления выбыванием (Retire Control Unit, RCU), здесь не показанный, управляет переименованием регистров и выбыванием микроопераций.
- Диспетчеры
- Внутренний диспетчер (Int Scheduler, ALU)
- Может передавать по одной микрооперации на конвейер (два ALU-модуля исполнения I0 и I1) во внеочередном порядке.
- AGU-диспетчер (загрузка/хранение)
- Может передавать по одной микрооперации на конвейер (два AGU-модуля исполнения LAGU b SAGU) во внеочередном порядке.
- Внутренний диспетчер (Int Scheduler, ALU)
Примеры микроопераций:
Инструкция µops
add reg, reg 1: add
add reg, [mem] 2: load, add
addpd xmm, xmm 1: addpd
addpd xmm, [mem] 2: load, addpdГлядя на раздел про AMD Jaguar в замечательной таблице инструкций на сайте Agner, мы можем понять, как выглядит конвейер исполнения для этого кода:
Пример кода
mov eax, [mem1] ; 1 - load
imul eax, 5 ; 2 - mul
add eax, [mem2] ; 3 - load, add
mov [mem3], eax ; 4 - store
Конвейер исполнения (Jaguar)
I0 | I1 | LAGU | SAGU | FP0 | FP1
| | 1-load | | |
2-mul | | 3-load | | |
| 3-add | | | |
| | | 4-store | |Здесь инструкции прерывания (breaking instructions) в микрооперациях позволяют процессору использовать преимущества модулей параллельного исполнения, частично или целиком «пряча» задержку при выполнении инструкции (
3-load и 2-mul выполняются параллельно, в двух разных модулях). Но такое не всегда возможно. Цепочка зависимостей между 2-mul, 3-add и 4-store не даёт процессору переорганизовать эти микрооперации (4-store нужен результат 3-add, а 3-add нужен результат 2-mul). Так что для эффективного использования модулей параллельного исполнения избегайте длинных цепочек зависимостей.
Опции Visual Studio
Чтобы проиллюстрировать генерируемый компилятором ассемблер, я воспользуюсь msvc++ 14.0 (VS2015) и Clang. Сильно рекомендую вам делать то же самое и привыкать сравнивать разные компиляторы. Это поможет лучше понимать, как взаимодействуют друг с другом все компоненты системы, и составлять своё мнение о качестве генерируемого кода.
Несколько полезностей:
- Опция Show Symbol Names может показать имена локальных переменных и функций в дизассемблированном виде, вместо адресов инструкций или стековых адресов.
- Сделайте ассемблер более читабельным:
- Project settings > C/C++ > Code Generation > Basic Runtime Checks, измените значение на Default.
- Записывайте результат в .asm-файл:
- Project settings > C/C++ > Output Files > Assembler Output, сделайте значение Assembly With Source Code.
- Опускание указателя фрейма (Frame-Pointer omission) говорит компилятору о том, что не надо использовать ebp для управления стеком:
- /Oy (только x86, в Clang: -fomit-frame-pointer, работает в x64)
Базовые примеры дизассемблирования
Здесь мы рассмотрим очень простые примеры кода на C++ и их дизассемблирование. Весь код на ассемблере переорганизован и полностью задокументирован, чтобы новичкам было легче, но я рекомендую проверить, нет ли у вас сомнений относительно того, что делают инструкции.
Для простоты восприятия прологи и эпилоги функций удалены, здесь мы не будем их обсуждать.
Примечание: локальные переменные объявлены в стеке. Например, mov dword ptr [rbp + 4], 0Ah; int b = 10 означает, что локальная переменная «b» помещена в стек (на неё ссылается rbp) по относительному адресу (offset) 4 и инициализирована как 0Ah, или 10 в десятичном выражении.
Арифметические операции с плавающей запятой с простой точностью
Арифметические операции с плавающей запятой можно выполнять с помощью x87 FPU (80-битная точность, скалярная) или SSE (32- или 64-битная точность, векторизованная). В x64 всегда поддерживается набор SSE2-инструкций, и по умолчанию это используется для арифметических операций с плавающей запятой.
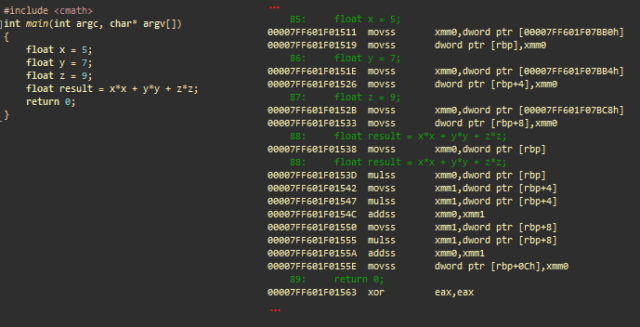
Простая арифметическая операция с плавающей запятой с использованием SSE. msvc++
Инициализации
- movss xmm0, dword ptr [adr]; загружает значение с плавающей запятой, расположенной по адресу adr в xmm0
- movss dword ptr [rbp], xmm0; сохраняет его в стек (float x)
- …; то же самое с y и z
Вычисляет x*x
- movss xmm0, dword ptr [rbp]; загружает скалярное x в xmm0
- mulss xmm0, dword ptr [rbp]; умножает xmm0 (=x) на x
Вычисляет y*y и складывает с x*x
- movss xmm1, dword ptr [rbp+4]; загружает скалярное y в xmm1
- mulss xmm1, dword ptr [rbp+4]; умножает xmm1 (=y) на y
- addss xmm0, xmm1; складывает xmm1 (y*y) с xmm0 (x*x)
Вычисляет z*z и складывает с x*x + y*y
- movss xmm1, dword ptr [rbp+8]; загружает скалярное z в xmm1
- mulss xmm1, dword ptr [rbp+8]; умножает xmm1 (=z) на z
- addss xmm0, xmm1; складывает xmm1 (z*z) с xmm0 (x*x + y*y)
Сохраняет финальный результат
- movss dword ptr [rbp+0Ch], xmm0; сохраняет xmm0 в результат
- xor eax, eax; eax = 0. eax содержит возвращаемое значение main ()
В этом примере XMM-регистры использованы для хранения одиночного значения с плавающей запятой. SSE позволяет работать как с одиночными, так и с множественными значениями, с разными типами данных. Посмотрите на SSE-инструкцию сложения:
- addss xmm0, xmm1; каждый регистр как 1 скалярное значение с плавающей запятой с одиночной точностью (scalar single precision floating-point value)
- addps xmm0, xmm1; каждый регистр как 4 упакованных значения с плавающей запятой с одиночной точностью (packed single precision floating-point values)
- addsd xmm0, xmm1; каждый регистр как 1 скалярное значение с плавающей запятой с двойной точностью (scalar double precision floating-point value)
- addpd xmm0, xmm1; каждый регистр как 2 упакованных значения с плавающей запятой с двойной точностью (packed double precision floating-point values)
- paddd xmm0, xmm1; каждый регистр как 4 упакованных dword-значения (packed double word (32-битных целочисленных) values)
Ветвление
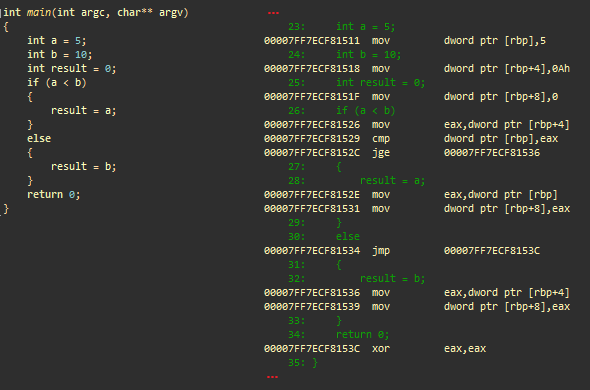
Пример ветвления. msvc++
Инициализации
- mov dword ptr [rbp], 5; сохраняет 5 в стек (целочисленное a)
- mov dword ptr [rbp+4], 0Ah; сохраняет 10 в стек (целочисленное b)
- mov dword ptr [rbp+8], 0; сохраняет 0 в стек (целочисленный результат)
Условие
- mov eax, dword ptr [rbp+4]; загружает b в eax
- cmp dword ptr [rbp], eax; сравнивает a с eax (b)
- jge @ECF81536; делает переход, если a больше или равно b
«then» result = a
- mov eax, dword ptr [rbp]; загружает a в eax
- mov dword ptr [rbp+8], eax; сохраняет eax в стек (результат)
- jmp @ECF8153C; переходит к ECF8153C
«else» result = b
- (ECF81536) mov eax, dword ptr [rbp+4]; загружает b в eax
- mov dword ptr [rbp+8], eax; сохраняет eax в стек (результат)
- (ECF8153C) xor eax, eax; eax = 0. eax содержит возвращаемое значение main ()
Инструкция cmp сравнивает операнд первого источника со вторым, в соответствии с результатом устанавливает флаги статусов в регистре RFLAGS. Регистр ®FLAGS — это регистр статуса x86-процессоров, содержащий текущее состояние процессора. Инструкция cmp обычно используется в сочетании с условным переходом (например, jge). Используемые переходами коды условий зависят от результата инструкции cmp (коды условий RFLAGS).
Арифметические операции с целочисленными и цикл «for»
В ассемблере циклы представлены в основном как серия условных переходов (=if… goto).
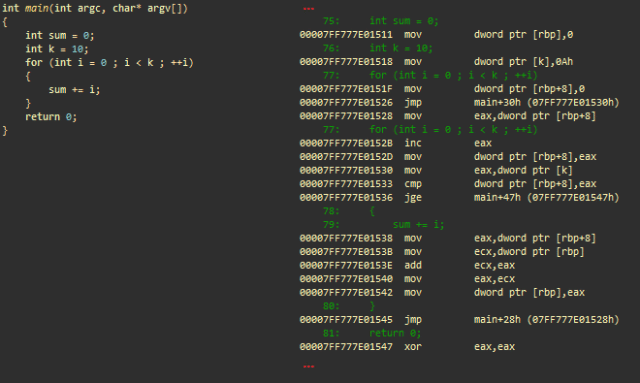
Арифметические операции с целочисленными и цикл «for». msvc++
Инициализации
- mov dword ptr [rbp], 0; сохраняет 0 в стек (целочисленная сумма)
- mov dword ptr [k], 0Ah; сохраняет 10 в стек (целочисленное k)
- mov dword ptr [rbp+8], 0; сохраняет 0 в стек (целочисленное i) для итерирования в цикле
- jmp main+30h; переходит к main+30h
Часть кода, ответственная за инкрементирование i
- (main+28h) mov eax, dword ptr [rbp+8]; загружает i в eax
- inc eax; инкрементирует
- mov dword ptr [rbp+8], eax; сохраняет обратно в стек
Часть кода, ответственная за тестирование условия выхода (i >= k)
- (main+30h) mov eax, dword ptr [k]; загружает k из стека в eax
- cmp dword ptr [rbp+8], eax; сравнивает i с eax (= k)
- jge main+47h; совершает переход (завершает цикл), если i больше или равно k
«Реальная работа»: sum+=i
- mov eax, dword ptr [rbp+8]; загружает i в eax
- mov ecx, dword ptr [rbp]; загружает сумму в ecx
- add ecx, eax; складывает eax с ecx (ecx = сумма + i)
- mov eax, ecx; переносит ecx в eax
- mov dword ptr [rbp], eax; сохраняет eax (сумма) обратно в стек
- jmp main+28h; совершает переход и обрабатывает следующую итерацию цикла
- (main+47h) xor eax, eax; eax = 0. eax содержит возвращаемое значение main ()
Встроенные функции (intrinsics) SSE
Ниже приведён типичный пример вертикальной обработки, при которой SSE позволяет программисту параллельно выполнить четыре одинаковые операции (в нашем случае — скалярное произведение). Мы увидим, как встроенные функции легко сопоставляются с их ассемблерными эквивалентами:
- _mm_mul_ps соответствует mulps
- _mm_load_ps соответствует movaps
- _mm_add_ps соответствует addps
- _mm_store_ps соответствует movaps
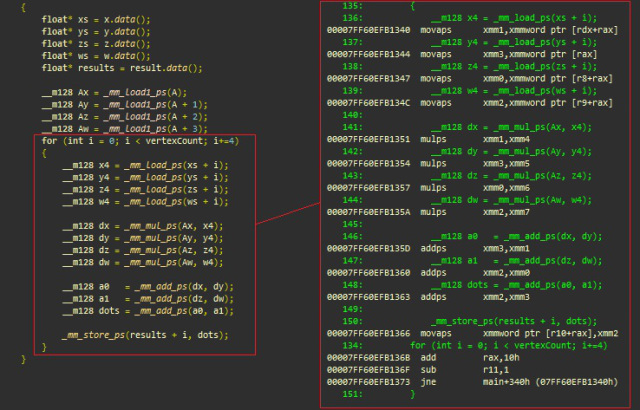
Встроенные функции SSE, msvc++
Инициализации (xmmword имеет ширину 128 бит и эквивалентен четырём dword)
- (main+340h) movaps xmm1, xmmword ptr [rdx+rax]; загружает 128-битный xmmword (четыре значения с плавающей запятой) по адресу xs+i в xmm1
- movaps xmm3, xmmword ptr [rax]; загружает 4 значения с плавающей запятой по адресу ys+i в xmm3
- movaps xmm0, xmmword ptr [r8+rax]; загружает 4 значения с плавающей запятой по адресу zs+i в xmm0
- movaps xmm2, xmmword ptr [r9+rax]; загружает 4 значения с плавающей запятой по адресу ws+i в xmm2
Вычисляет dot (v[i], A) = xi * Ax + yi * Ay + zi * Az + wi * Aw, четыре вершины (vertices) за раз:
- mulps xmm1, xmm4; xmm1 *= xmm4 xn.Ax, n [0…3]
- mulps xmm3, xmm5; xmm3 *= xmm5 yn.Ay, n [0…3]
- mulps xmm0, xmm6; xmm0 *= xmm6 zn.Az, n [0…3]
- mulps xmm2, xmm7; xmm2 *= xmm7 wn.Aw, n [0…3]
- addps xmm3, xmm1; xmm3 += xmm1 xn.Ax + yn.Ay
- addps xmm2, xmm0; xmm2 += xmm0 zn.Az + wn.Aw
- addps xmm2, xmm3; xmm2 += xmm3 xn.Ax + yn.Ay + zn.Az + wn.Aw
Сохраняет результаты по адресу памяти (результаты + сдвиг) и идёт по циклу
- movaps xmmword ptr [r10 + rax], xmm2; сохраняет 128-битный xmmword (4 значения с плавающей запятой) по адресу, на который ссылается r10+rax
- add rax, 10h; складывает 16 с rax (текущий сдвиг = размер 4 значений с плавающей запятой)
- sub r11,1; r11–, оставшиеся итерации цикла
- jne main+34h; выполняет переход и обрабатывает следующую итерацию цикла
Можно очень просто портировать этот код в AVX (256-бит, или 8 значений с плавающей запятой с одиночной точностью):
_m256 Ax = _mm256_broadcast_ss(A);
...
for (int i = 0; i < vertexCount; i+=8) // 8 значений с плавающей запятой (256-бит)
{
__m256 x4 = _mm256_load_ps(xs + i);
..
__m256 dx = _mm256_mul_ps(Ax, x4);
..
__m256 a0 = _mm256_add_ps(dx, dy);
..
_mm256_store_ps(result
