R, Asterisk и платяной шкаф
Является продолжением предыдущих публикаций. Основное назначение публикаций — демонстрация возможностей R по решению различных «рутинных» задач по обработке данных, возникающих в бизнесе. Основной акцент ставится на создание законченного решения для конечного пользователя, а не на принципиальное решение частной задачи набором команд в консоли. Схематический прототип и продукт с конвейера имеют больше различий чем сходства.
По тонкой механике R есть огромное количество специализированных блогов, книг, а также github. Но обращаются к ним обычно только после того, как видят, что решение задачи средствами R возможно и весьма элегантно.
С чего все начиналось
В целом, начальная ситуация весьма типична для компаний у которых есть хоть какое-либо подобие колл-центр, обслуживающего запросы внешних пользователей. Есть PBX (в нашем случае — несколько географически разнесенных Asterisk инстансов, версия 13LTS). Есть информационная система\системы в которые операторы вносят то, что услышали от пользователей. И есть кипа автоматизированных бизнес-процессов по обработке запросов пользователей.
Еще есть вертикаль руководства от руководителя колл-центра до топ-менеджмента, а также смежные подразделения, например, маркетинг, которые для стратегического управления требуют сводку о том «как живет народ», как себя ведут KPI и «куда движется бизнес». И вот тут желания и возможности друг друга находят себя очень слабо.
Если в части сервис деска какой-то генератор отчетов уже был, то у Asterisk изначально ничего кроме логов и cdr не было.
Шаг №1
Попробовали пойти по стандартному пути, посмотрели существующие для Asterisk инструменты. В качестве первого приближения остановились на бесплатных версиях программ:
- Asterisk Call Center Stats;
- Asterisk CDR Viewer Mod.
Стало немного лучше. Требуемую аналитическую сводку ответственные сотрудники, наконец, смогли готовить. Однако качество этой отчетности сильно хромало по нескольким причинам:
- Сценарии обработки в asterisk были весьма сложные и написаны через макросы. Штатно CDR файлы генерируются с упором на минимизацию количества записей. Поэтому в результирующих CDR при «схлопывании» внутренних трансферов и объединения плеч, терялся ряд важных данных. Как A номера (из-за макросов), так и B номера (при объединении плеч, инициированных оператором).
- Очереди тоже содержат не полную информацию. Нет записей по IVR, нет информации по трансферу наружу. И еще много чего нет.
- Сами программы может и выдают общепринятую статистику по колл-центрам, но применительно к нашим задачам больше половины выводимых результатов были не очень полезны для бизнеса, потому что отвечали не на нужные вопросы.
- Бесплатные версии урезаны по функционалу + пришлось еще руками «допиливать» php, чтобы хотя бы не падало. Неправильными подсчетами длительности пренебрегаю, за их незначительностью (~10%). Для простоты списываю это на наши специфические настройки asterisk.
- Данные из внешних справочников и систем прицепить нельзя. Все только руками в excel. Например, представить отчет не по номерам, а по ФИО оператора, учитывая график смен.
- Нет графического представления, а те, которые предлагаются в платных версиях далеки от того, что требуется.
- Разные системы почти всегда давали разные числовые результаты. Иногда разница достигала сотен процентов. Очевидно, что это было вызвано сложностью звонков, а также различиями в алгоритмах расчетов, заложенных в программах.
Шаг №2
Взялись за самостоятельный анализ cdr и log файлов. В качестве инструмента анализа использовали R. По самой сути данных не очень много. Несколько тысяч звонков в ЧНН дают в результате 1–2 Гб записей в пакованном виде на год работы. Для современных ноутбуков — это полная ерунда, не говоря уж о серверном оборудовании.
И тут начались интересные вещи. Даже самый беглый взгляд различные срезы данных вызвал массу технически вопросов, приведших к тюнингу астерисков.
- Почему макросы не выдают нужную информацию при определенных типах разговорах?
- Почему иногда теряются идентификаторы, позволяющие связать трехстороннии сессии в которых оператор является посредником?
- Почему временные метрики в cdr не всегда совпадают с реальными временными событиями? Время в IVR не всегда и не в полном объеме надо считать (зависит от логики), да и IVR бывают разные.
- Почему в очередях нет ряда требуемых параметров?
Но это только техническая сторона вопроса. После внимательного изучения данных было принято решение отказаться от использования cdr (слишком уж неполные и недостоверные данные там записывались, а радикально дорабатывать логику формирования cdr на продуктиве ни у кого не вызывало оптимизма. Поэтому перешли на модель анализа call-flow по данным, получаемым из лога очередей (queue log) со следующей логикой:
- реконструируем все события в рамках call flow, используя идентификаторы первичной сессии и линкованных сессий;
- проводим прореживание событий исходя из бизнес-логики расчета kpi (многократные RING NO ANSWER; многократные ENTER QUEUE в эту же очередь или в другую; ATTENDENT TRANSFER\BLIND TRANSFER на внешние номера и пр…);
- по выстроенным очищенным call flow пересчитываем реальные длительности всех событий исходя из их временных меток;
- обогащаем call-flow данными из внешних источников, в частности, из графика дежурных смен операторов, чтобы из номера оператора получить ФИО;
- получаем «чистый» набор «сырых» данных по которым уже строим всю необходимую отчетность.
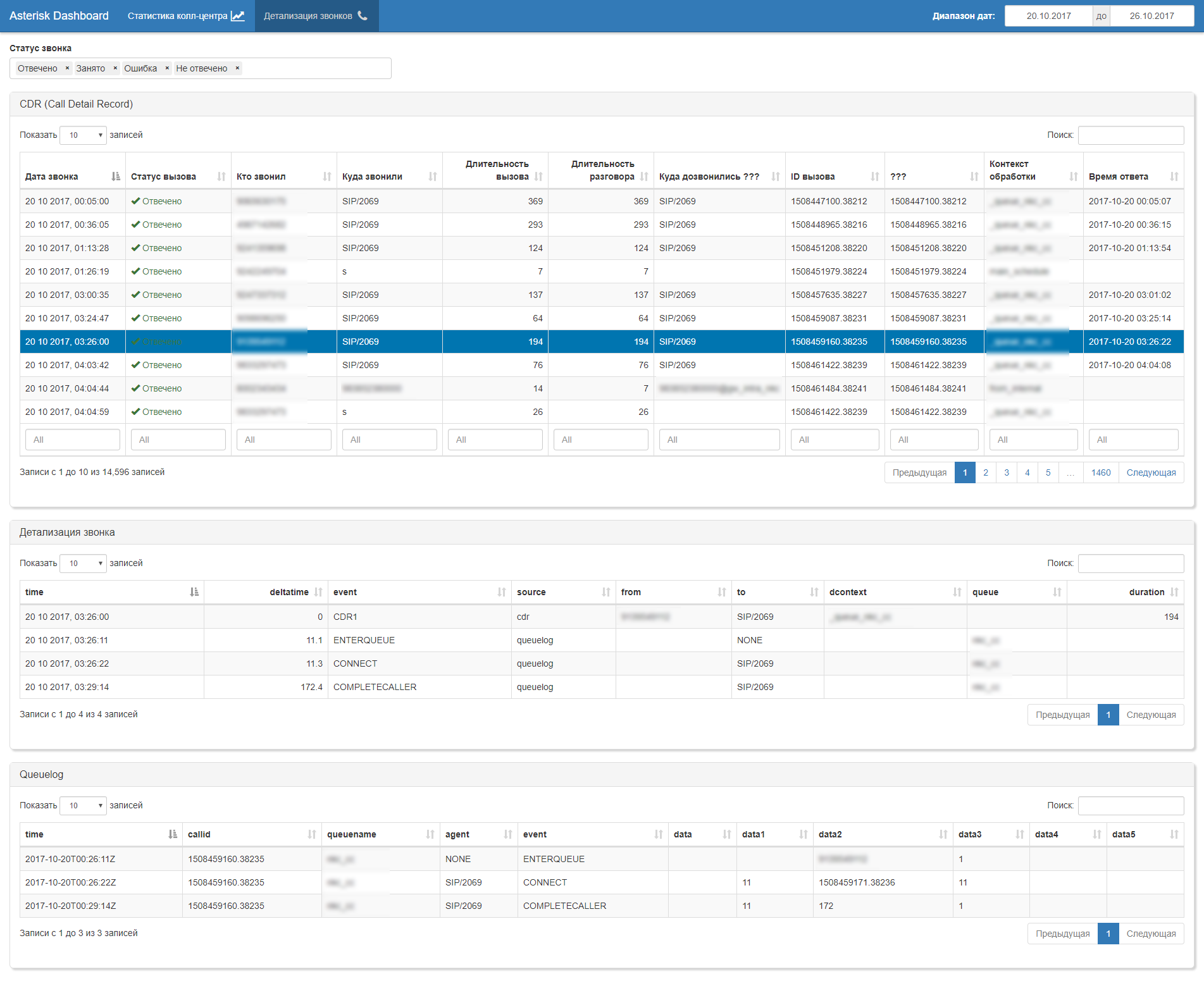
В целом, дальше следует автоматическая генерация штатного набор бизнес-артефактов: дашборды, отчеты, выгрузки (xls, pdf, csv, doc, ppt, …)
Сам АРМ для начальника колл-центра построен на Shiny.

Важно, что после такой «чистки» данных можно было сесть за стол с бизнесом и обсудить метрики (KPI) и методику их расчета. Считать ли время пребывания абонентом во внутреннем IVR в длительность звонка или нет? Считать ли CONNECT последующий мгновенный возврат в очередь ответом оператора или нет? Как декомпозировать по KPI операторов и очереденй пребывание абонента в нескольких очередях? Как соотносить среднее время ожидания в очереди со временем суток и количеством операторов в смене? Какие типовые сценарии «оптимизации» у операторов? И масса других вопросов. Самое приятное, что на все вопросы можно дать четкий и однозначный ответ.
Дополнительным плюсом к переходу на событийный анализ call-flow является возможность изучения сценариев работы колл-центра (process mining). По сути, реверс-инжиниринг бизнес-процессов по их следам в логах колл-центра. Любопытные вещи обнаруживаются!
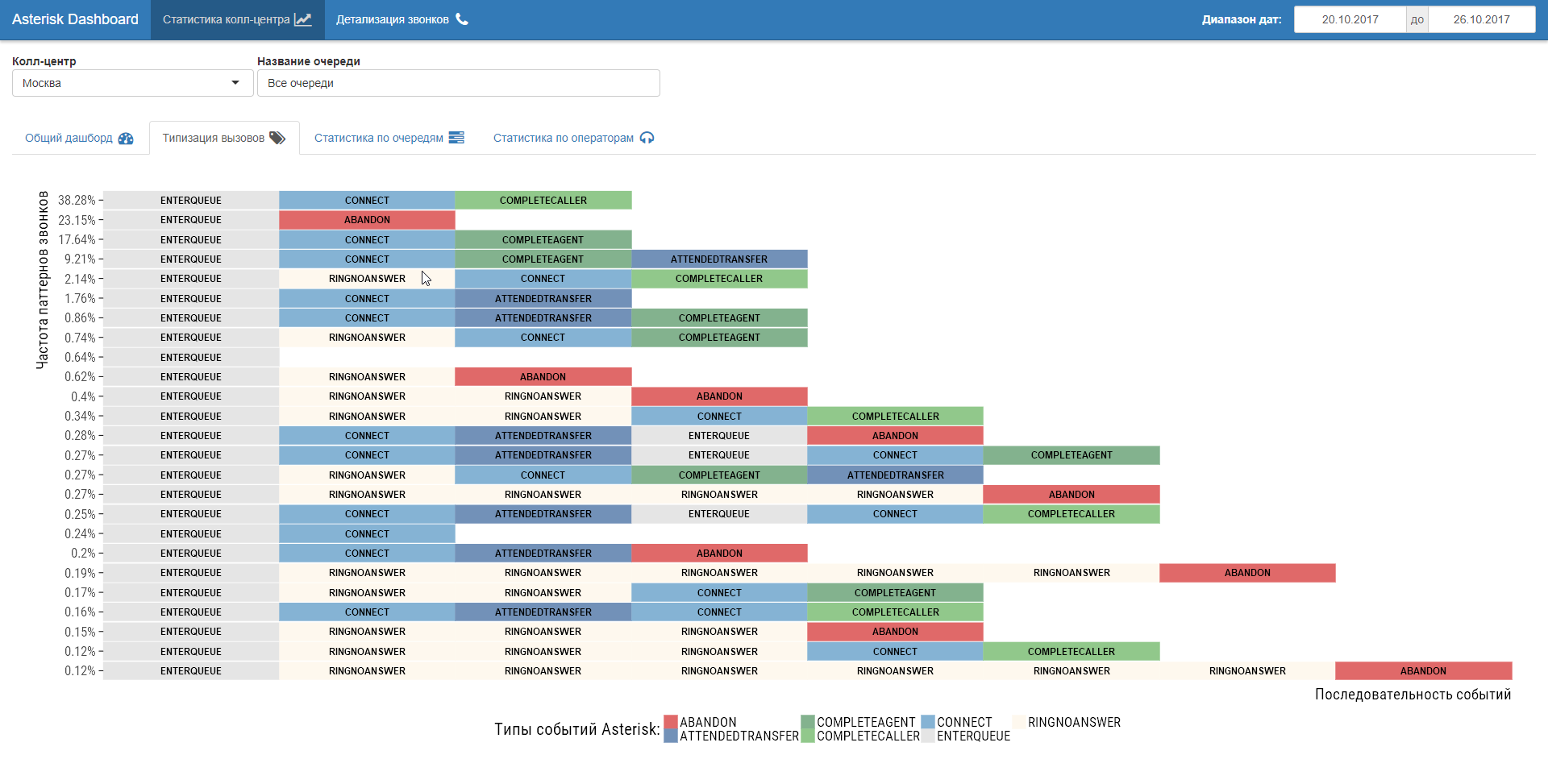
Шаг №3
Переход на анализ AMI событий. В целом, это самый универсальный способ, однако требующий чуть больше вычислительных мощностей. После незначительной юстировки логов очередей, для отдельно взятого астериска острота в анализе AMI пропала, но хранение их в контексте исторической работы астериска (траблшутинг) остается полезным. Также работа с AMI обеспечивает независимость от частных настроек отдельного астериска что будет актуально при подключении следующих. Для обеспечения скорости работы с AMI мы «сваливаем» все 151 тип событий с 619 возможными полями в ClickHouse.
Послесловие
Как многие могут отметить, задача весьма частная, объемы данных невелики. Но от этого, значимость этой задачи для бизнеса никак не уменьшается. Применение же R позволило оперативно и элегантно ее решить, при этом создать удобные АРМ для обычных бизнес-пользователей.
И только теперь, имея надежный фундамент, можно переходить к прогнозированию и операционной аналитике.
Ответ на вопрос «причем здесь платяной шкаф», увы весьма прозаичен. Потому что из него посыпались скелеты, которые тщательно скрывались операторами колл-центра. А R+Shiny послужили ключиком для его открывания.
Предыдущий пост: А вы уже применяете R в бизнесе?
