QVD файлы — что внутри
QlikView и его младший брат QlikSense — замечательные BI инструменты, достаточно популярные у нас в стране и «за рубежом». Очень часто эти системы сохраняют «промежуточные» результаты своей работы — данные, которые визуализируют их «дашборды» — в так называемые «QVD файлы». Часто QVD файлы используются в качестве основного хранилища в многоэтапных ETL процессах, построенных на базе Qlik. И тогда у некоторых (у меня, например, — я занимаюсь в компании вопросами инженерии данных) возникает вопрос — можно ли и как воспользоваться этими данными без QlikView/QlikSense? Или другой —, а что там и правильно ли «оно» посчиталось?
QVD — это формат файла, оптимизированный для работы QlikView/QlikSense (чтение из запись информации этими приложениями в файлы такого формата происходит существенно быстрее, чем в файлы любого другого формата). Структура этого файла недокументирована и покрыта «мраком проприетарности», практически не существует приложений, которые способны работать такими файлами (читать и тем более писать). В этой серии статей я поделюсь своим опытом и полученными практическими познаниями: я знаю, как устроен QVD, умею напрямую и быстро его читать и в него писать.
Кому будет интересна данная информация: в первую очередь тем, кто работает с QlikView/QlikSense, а также тем, кто (как и я) хотел бы воспользоваться данными, хранящимися в QVD файлах. Ну и, конечно, всем любознательным.
Все, что написано в этой серии, базируется на моем личном опыте, что, разумеется, не является «документацией» или «гарантией» (того, что ваши файлы будут в точности такими, как я описал. Или того, что так это будет вечно). Также не могу гарантировать, что разобрал все случаи — наверняка могут найтись файлы, которые будут содержать что-то, не описанное мной (хотя бы просто потому, что мне такие варианты не попадались). Однако должен заметить, что информация проверена на большом (несколько сотен) наборе файлов, созданных разными людьми из разных систем при помощи разных версий QlikView/QlikSense.
И немного о том, как я это делал: начинал я с простого — небольшой inline пример, сохраняющийся в QVD. Далее — анализ бинарного файла, мозговые усилия, пробы и ошибки. Забегая вперед (я об этом более подробно скажу в заключении серии) у меня получилось достаточно эффективно читать и писать QVD файлы среднего размера (сотни гигабайт). Отправной точкой моего путешествия в мир QVD был вот этот GitHub, большое спасибо автору (пытался с ним связаться — не отвечает).
Какую я преследовал цель (кроме любопытства и желания проверить корректность данных, с которыми работает QlikView/QlikSense) — мне необходимо было прочитать содержимое QVD файла, т.е. воссоздать на его основе реляционную таблицу. И наоборот — выгрузить данные реляционной таблицы в QVD так, чтобы QlikView смог ее корректно загрузить.
Как я вижу эту серию статей
- введение, структура файла, метаданные (эта статья)
- хранение информации о колонках
- хранение информации о строках, достижения, планы
Структура файла
QVD файл создается скриптом QlikView/QlikSense в процессе загрузки данных в память приложения (результат работы команды STORE) и соответствует одной (реляционной) таблице QlikView/QlikSense. Он состоит из двух частей
- текстовой (метаданные) и
- бинарной (колонки и строки)
Метаданные представлены в виде XML (пример будет приведен ниже), бинарная часть начинается непосредственно после текстовой и состоит из двух блоков
- уникальные значения всех колонок (исходной таблицы)
- строки (исходной таблицы), ссылающиеся на уникальные значения колонок
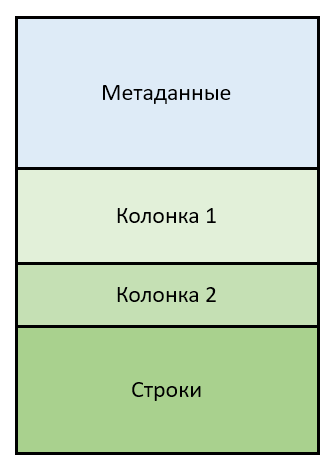
Таким образом для таблицы из N колонок файл будет содержать N + 1 бинарный блок. Все части файла «плотно склеены» и идут друг за другом без каких-бы то ни было заполнителей и «хвостовиков».
QVD файл содержит достаточно много метаданных — «данных о данных». Он практически самодостаточен, судите сами, вот краткий перечень того, что есть в метаданных (более подробно я опишу их ниже):
- версия ПО, породившего файл
- дата и время создания файла
- файл QlikView/QlikSense, работа скрипта которого привела к созданию файла
- исходный код скрипта, породивший QVD файл
- имя таблицы
- информация о колонках (имена, типы, количества уникальных значений)
- количество строк
Метаданные хранятся в файле в текстовом виде и их можно увидеть в любой программе, которая может показать файл в текстовом виде (ну, почти в любой… в такой, которая не боится файлов больших размеров). Лично я смотрю метаинформацию при помощи more — достаточно удобно.
В дальнейшем изложении я буду использовать тестовую таблицу (использую синтаксис QlikView, но думаю, несложно будет домыслить):
SET NULLINTERPRET =;
tab1:
LOAD * INLINE [
ID, NAME
123.12,"Pete"
124,12/31/2018
-2,"Vasya"
1,"John"
,"None"
]; Приведу в качестве примера метаданные для этой таблички
7314
2019-04-03 06:24:33
-1
tab1
ID
0
3
-2
0
0
0
5
0
42
NAME
3
5
0
0
0
0
5
42
37
1
5
79
5
Мой опыт работы с QVD показывает, что структура XML не меняется от файла к файлу.
Прокомментирую наиболее важные элементы метаданных.
Общая информация
QvBuildNo
Номер билда того приложения QlikView/QlikSense, которое породило QVD файл.
CreatorDoc
Как правило содержит имя того QVW файла, скрипт которого породил QVD файл. В данном примере не заполнено, возможно, потому что использовался Personal Edition.
CreateUtcTime
Время создания QVD файла.
SourceCreateUtcTime, SourceFileUtcTime, SourceFileSize, StaleUtcTime
Не видел файлов, в которых эти поля были бы заполнены — пытливому уму: может быть, каких-то настроек не хватает?
TableName
Имя таблицы в QlikView (см. пример выше).
Информация о полях (колонках)
Кстати, слова «поле» и «колонка» для меня являются синонимами, не пугайтесь, если я их буду употреблять оба (постараюсь этого не делать, но все же…).
Про каждое поле в QVD хранится информация о
FieldName
Имя поля (опять же в терминах QlikView, т.е. с учетом «AS»)
BitOffset, BitWidth, Bias
Пока пропустим — это информация для «расшифровки строк», рассмотрим в третьей части, когда будет разбираться со строками.
Type, nDec, UseThou, Fmt, Dec, Thou
Хорошо задуманная (судя по названиям), но абсолютно бесполезная с точки зрения достижения моей цели информация (подробнее — во второй части, где будем говорить о колонках). Почему бесполезная? — тэг «Type» не коррелирует с типом данных, которые хранятся в бинарной части. По нему нельзя восстановить тип колонки (казалось бы — что может быть проще, есть же тэг Type!). В 90% случаев значением этого тэга будет строка UNKNOWN…
В метаданных о колонках бывают еще такие данные (в метаданных примера его нет, видимо, по причине малого размера)
$numeric
$integer
Комментарий в комментариях не нуждается (кстати, в тех файлах, с которыми я работал, 100% пуст…).
Тэги — тоже бесполезная (с точки зрения восстановления структуры таблицы) информация. Но по ней можно примерно догадаться, какого типа информация хранится в колонке. Я более подробно коснусь типизации во второй части — когда буду говорить о колонках: это важно. Но чуть более сложно, чем мне бы хотелось.
NoOfSymbols
Количество записей в бинарной части, относящейся к данной колонке. Как мы видим — в нашем примере это 5. Очень важная для расшифровки информация.
Offset
Смещение блока данных данной колонки в байтах относительно начала бинарной части файла. Также очень важно.
Length
Длина всего блока данных данной колонки в байтах. Отметим, что бинарное представление элемента колонки (ячейки таблицы) в общем случае имеет переменную длину (строка, например), поэтому длину нельзя вычислить, можно только взять из этого тэга (smile).
Информация о строках
Compression
Никогда не заполнено (в тех данных, с которыми я работал). Возможно, мы не используем эту опцию…
RecordByteSize
Размер записи о строке в байтах. Все строки представлены в бинарном блоке строк в виде битового индекса (об этом подробнее в третьей части), битовый индекс состоит из строк одинаковой длины.
NoOfRecords
Количество строк (в битовом индексе и в исходной таблице).
Offset
Смещение битового индекса (блока с информацией о строках) в байтах относительно начала бинарной части файла.
Length
Длина битового индекса в байтах.
В метаданных о строках бывают еще такие данные (опять же — короткий пример не позволяет увидеть все, но зато позволяет разобраться в сложном)
Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""
LinkTable:
LOAD
SOURCE_NAME & '_' & SOURCE_ID as SYSKEY,
HID_PARTY;SQL
SELECT *
FROM
UNITED_VIEW
Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""
SQL
SELECT *
FROM
UNITED_VIEW
STORE - \\xxx.ru\mfs\SPECIAL\Qlikview\QVData\LinkTable.qvd (qvd)
Не буду здесь слишком вдаваться в суть, она примерно понятна (исходные SELECT-ы, которые породили таблицу в QlikView), до конца я в этом еще не разобрался (иногда они двоятся)… (кроме одного — комментариев 100% нет (smile)).
Подытожим
- QVD файл является самодостаточным (т.е. его можно анализировать в отрыве от других данных)
- QVD файл состоит из текстовой (метаданные) и бинарной (колонки и битовый индекс) частей
- метаданные — это XML с вполне понятной семантикой
Любознательный читатель вправе тут спросить: «Пока не прозвучало ничего нового, все вышесказанное можно взять и посмотреть в XML заголовке QVD файла… Об этом уже неоднократно писали в разных интернетах, в чем новизна?». Все верно — первая часть практически полностью посвящена метаданным. Но это — не конец.
Что дальше — в следующей части мы подробно рассмотрим структуру бинарной части QVD файла, содержащего информацию о колонках (уникальные значения всех колонок таблицы).
