Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС
Итак, в первой статье цикла говорилось, что для управления нашим оборудованием, реализованным средствами ПЛИС, для комплекса Redd лучше всего использовать процессорную систему, после чего на протяжении первой и второй статей показывал, как эту систему сделать. Хорошо, она сделана, мы даже можем выбирать какие-то готовые ядра из списка, чтобы включить их в неё, но конечная цель — именно управлять нашими собственными нестандартными ядрами. Пришла пора рассмотреть, как включить в процессорную систему произвольное ядро.
Все статьи цикла:
Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти
Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код
Для понимания сегодняшней теории, следует найти и скачать документ Avalon Interface Specifications, так как базовой шиной для системы NIOS II является именно шина Avalon. Я буду ссылаться на разделы, таблицы и рисунки для редакции документа от 26 сентября 2018 года.
Открываем раздел 3, посвящённый Memory Mapped Interfaces, а точнее — 3.2. В таблице 9 приведён перечень сигналов шины. Обратите внимание, что все эти сигналы опциональные. Я не нашёл ни одного сигнала, у которого в графе Required стояло бы «Yes». Мы вполне можем не пробрасывать тот или иной сигнал в наше устройство. Поэтому в самом простом случае шина получается чрезвычайно простой в реализации. Начало таблицы выглядит так:

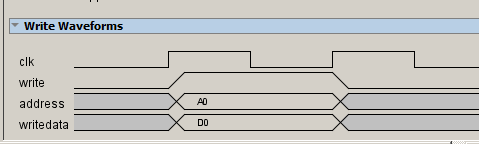
Как видим, все сигналы очень хорошо описаны (разве что, сделано это по-английски). Ниже идут временные диаграммы для различных случаев. Самый-самый-самый простой случай не вызывает никаких вопросов. Я сейчас возьму временную диаграмму из документа и прикрою некоторые линии полупрозрачной заливкой (они же все опциональны, мы имеем право исключать любую из рассмотрения).
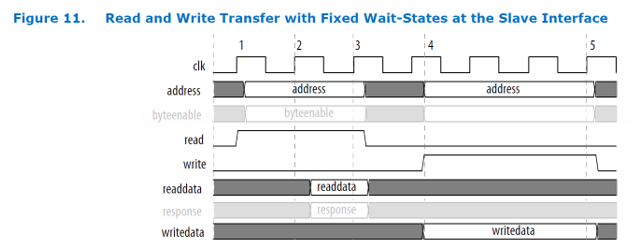
Страшно? Но всё просто: нам ставят адрес и строб read, мы должны выставить данные на шину readdata. И наоборот: нам ставят адрес, данные на шине writedata и строб write, а мы должны защёлкнуть данные. Совершенно не страшно, шина типовая синхронная.
Прикрытые линии byteenable нужны для случая, когда обращение к памяти идёт не 32-битными словами. Это чрезвычайно важно, когда мы проектируем универсальные ядра. Но когда мы проектируем ядро-однодневку, то просто пропишем в документе об этом ядре (я противник отметки в голове, но кто-то может ограничиться и этим), что обращаться нужно 32-битными словами и всё. Ну, а сигнал response, он совсем особый, и он нас не интересует в принципе.
Иногда важно, чтобы при неготовности аппаратуры, можно было задержать работу шины на несколько тактов. В этом случае, следует добавить сигнал WaitRequest. Временная диаграмма изменится следующим образом:
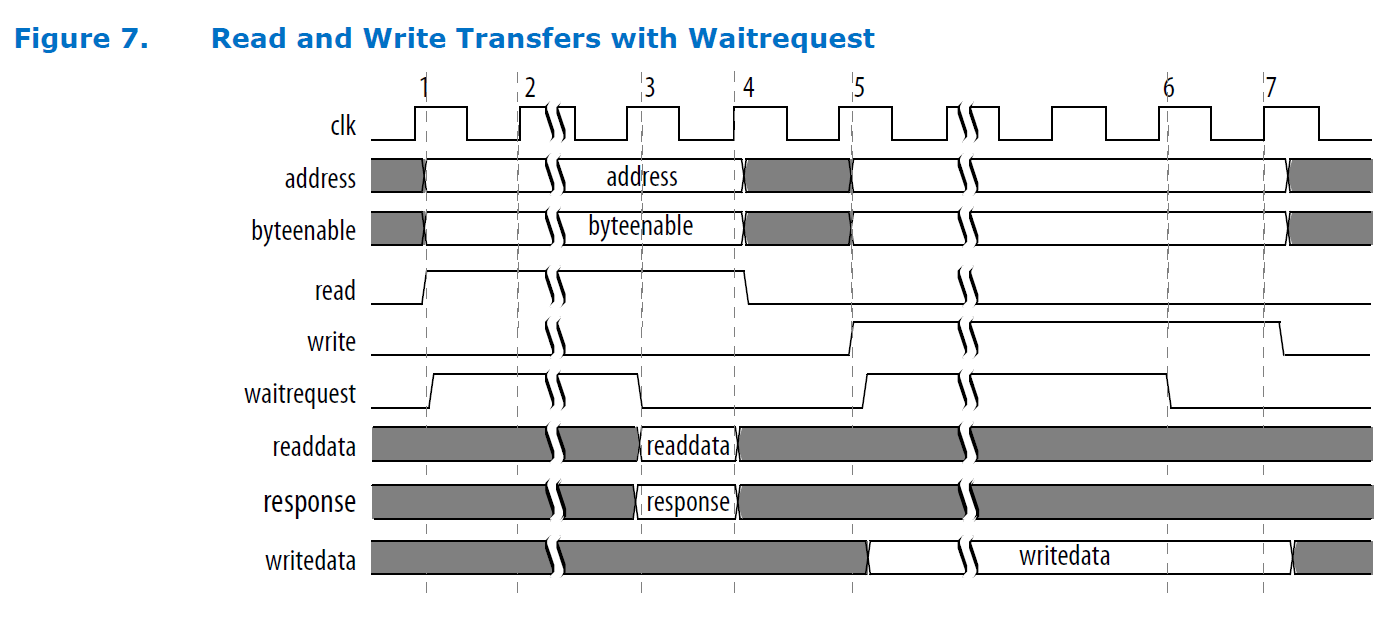
Пока WaitRequest взведён, мастер знает, что наше устройство занято. Будьте осторожны, если этот сигнал не будет сброшен, вся система «зависнет» при обращении, так что только перезагрузка ПЛИС сможет сбросить её. JTAG зависнет вместе с системой. Последний раз я наблюдал это явление при подготовке данной статьи, так что воспоминания ещё яркие.
Дальше в фирменном документе рассматриваются более производительные случаи конвейеризации данных и пакетных транзакций, но задача статьи — не рассмотреть все возможные варианты, а показать читателю путь для работы, подчеркнув, что всё это совсем не страшно, поэтому ограничимся этими двумя простыми вариантами.
Давайте спроектируем какое-то простейшее устройство, которое будет периодически становиться недоступным по шине. Первое, что приходит в голову — последовательный интерфейс. Пока идёт передача, будем заставлять систему ждать. Причём в жизни я так делать категорически не советую: процессор будет останавливаться до конца занятой транзакции, но для статьи это идеальный случай, так как реализующий код будет понятным и не очень громоздким. В общем, сделаем последовательный передатчик, который сможет посылать данные и сигналы выбора кристалла на два устройства.
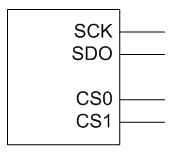
Начнём с самого простейшего варианта шины. Сделаем параллельный порт вывода, формирующий сигналы выбора кристаллов.
Для этого я возьму проект, получившийся в прошлой статье, но во избежание путаницы, положу его в каталог AVALON_DEMO. Имена прочих файлов изменять не буду. В этом каталоге создаём каталог my_cores. Имя каталога может быть любым. В нём будем складировать свои ядра. Правда, сегодня оно будет одно. Создаём там файл CrazySerial.sv со следующим содержимым:
module CrazySerial
(
input clk,
input reset,
input [1:0] address,
input write,
input [31:0] writedata,
output reg [1:0] cs
);
always @(posedge clk, posedge reset)
begin
if (reset == 1)
begin
cs <= 0;
end else
begin
if (write)
case (address)
2'h00: cs <= writedata [1:0];
default:;
endcase
end
end
endmodule
Давайте разбираться. В первую очередь, интерфейсные линии. clk и reset — это линии тактирования и сброса. Имена линий address, write и writedata взяты из таблицы с перечнем сигналов Memory Mapped Interfaces документа.

На самом деле, имена я мог дать любые. Связывание логических линий с физическими будет производиться позже. Но если дать имена, как в таблице, среда разработки свяжет их сама. Поэтому лучше брать имена именно из таблицы.
Ну, а cs — это линии выбора кристалла, которые будут выходить из микросхемы.
Сама реализация тривиальна. При сбросе выходы зануляются. А так — на каждом такте проверяем, нет ли сигнала write. Если есть и адрес равен нулю, то защёлкиваем данные. Можно, конечно, было бы здесь добавить дешифратор, который предотвратит выбор двух устройств сразу, но что хорошо в жизни, то перегрузит статью. В статье приводятся только самые необходимые шаги, однако, отмечается, что в жизни всё можно сделать и посложнее.
Прекрасно. Мы готовы внедрять этот код в процессорную систему. Идём в Platform Designer, выбираем в качестве входного файла систему, построенную нами при прошлых опытах:
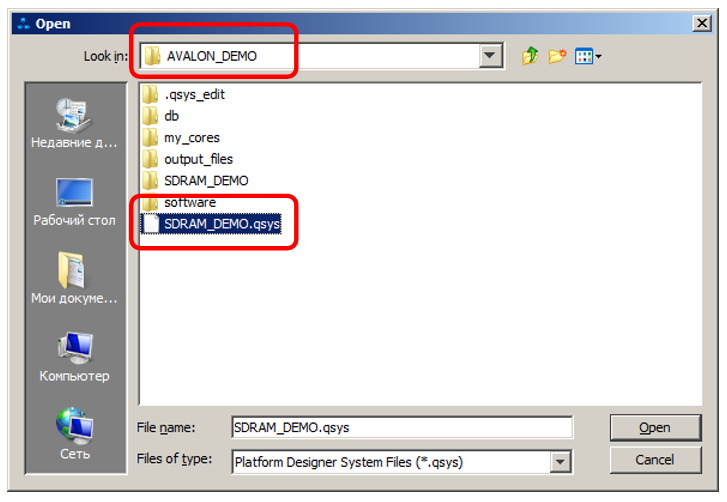
Обращаем внимание на пункт New Component в левом верхнем углу:

Чтобы добавить свой компонент, надо щёлкнуть по этому пункту. В открывшемся диалоге заполняем поля. А для статьи заполним только имя компонента:

Теперь переходим на вкладку Files и нажимаем Add File:
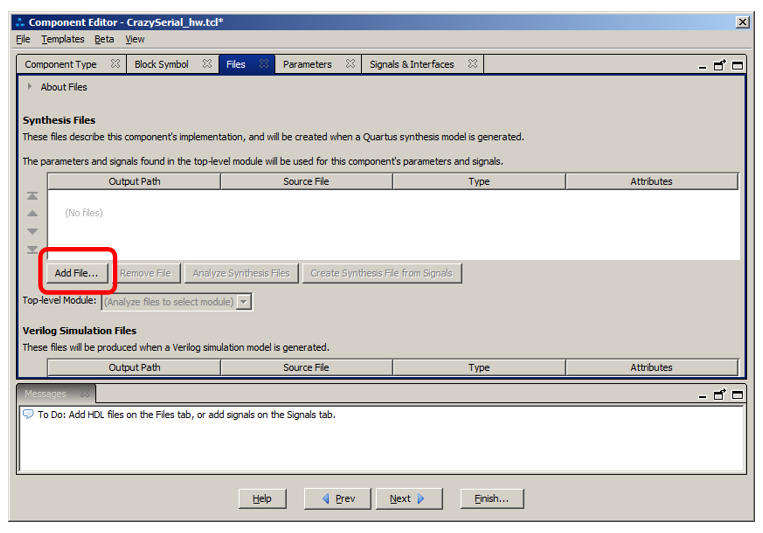
Добавляем ранее созданный файл, выбираем его в списке и нажимаем Analyze Synthesis File:
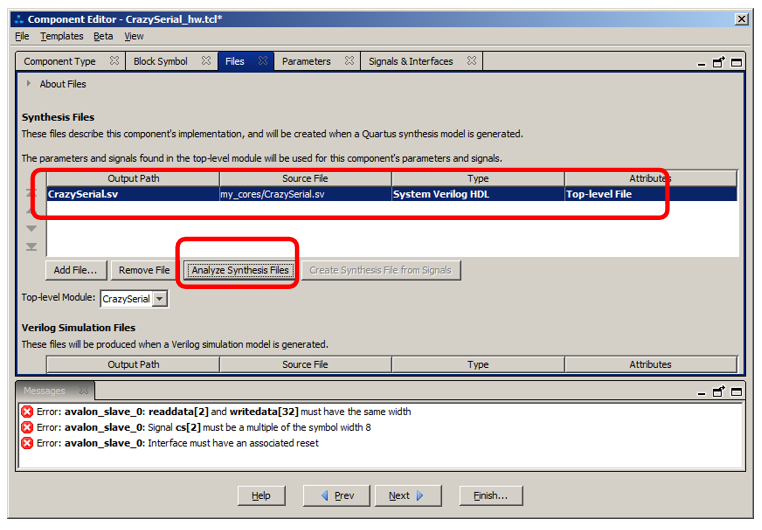
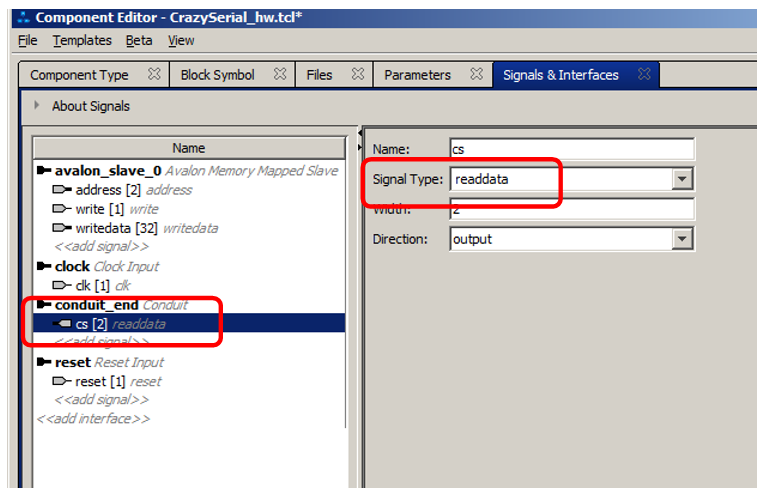
Ошибок при разборе SystemVerilog нет, но есть несколько концептуальных ошибок. Они вызваны тем, что некоторые линии были неверно связаны средой разработки. Идём на вкладку Signals & Interfaces и обращаем внимание сюда:
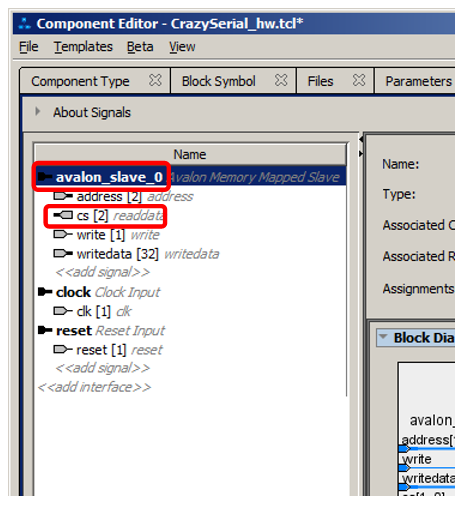
Линии cs были неверно отнесены к интерфейсу avalon_slave0, сигналу readdata. Но зато все остальные линии были распознаны верно, благодаря тому, что мы дали им имена из таблицы документа. Но что делать с проблемными линиями? Их надо отнести к интерфейсу типа conduit. Для этого щёлкаем по пункту «add interface»
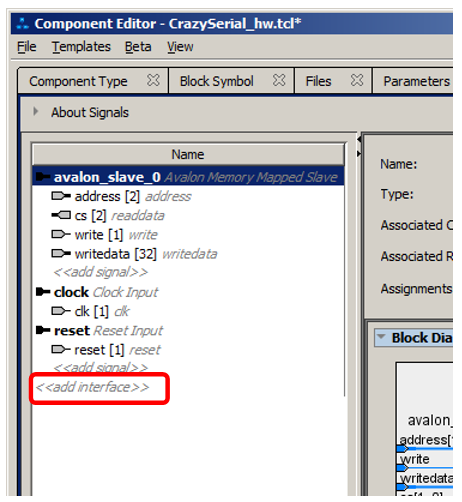
В выпавшем меню выбираем conduit:
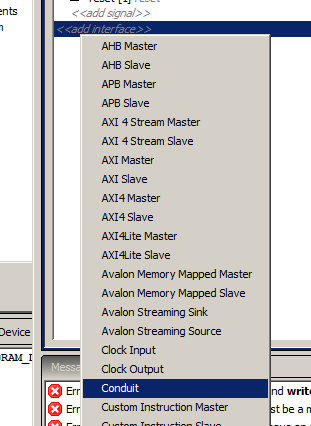
Получаем новый интерфейс:
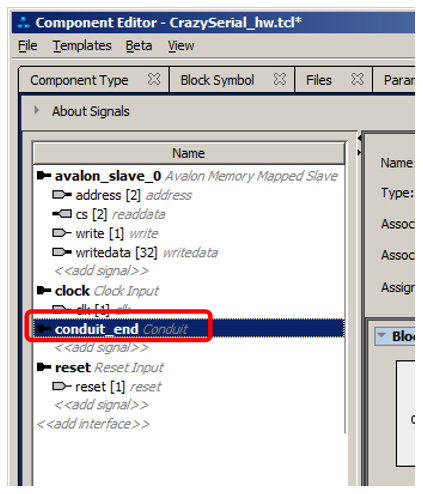
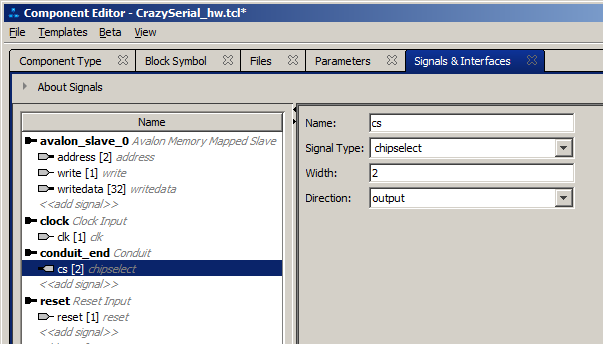
При желании, его можно переименовать. Правда, это будет непременно нужно, если мы хотим сделать несколько внешних интерфейсов. В рамках статьи оставим ему имя conduit_end. Теперь цепляем «мышкой» линию cs и тянем её в этот интерфейс. Надо умудриться бросить сигнал под строку conduit_end, тогда нам это позволят это сделать. В других местах будет отображаться курсор в виде перечёркнутого круга. В конце концов, у нас должно получиться так:
Заменим тип сигнала с readdata на, скажем, chipselect. Итоговая картинка:
Но ошибки остались. Шине avalon не назначен сигнал сброса. Выбираем в списке avalon_slave_0 и смотрим его свойства.

Заменяем none на reset. Заодно осмотрим прочие свойства интерфейса.
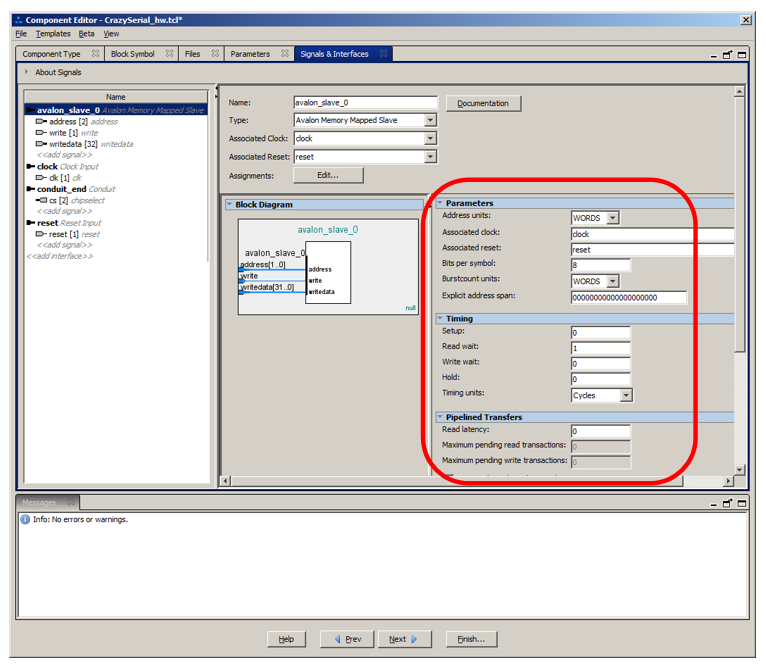
Видно, что адресация идёт словами. Ну, и ряд других вещей из документации настраивается именно здесь. Какие при этом получаются временные диаграммы, будет нарисовано в самом низу свойств:
Собственно, ошибок больше нет. Можно нажимать Finish. Наш созданный модуль появился в дереве устройств:
Добавляем его в процессорную систему, подключаем тактовые сигналы и сброс. Подключаем шину данных к Data Master процессора. Дважды щёлкаем по Conduit_end и даём внешнему сигналу имя, скажем, lines. Получается как-то так:

Здесь важно не забыть, что раз мы добавили в систему блок, то надо сделать так, чтобы он не конфликтовал ни с кем в адресном пространстве. В данном конкретном случае на рисунке конфликтов нет, но всё равно я выберу пункт меню System→Assign Base Addresses.
Всё. Блок создан, настроен, добавлен в систему. Нажимаем кнопку Generate HDL, затем — Finish.
Делаем черновую сборку проекта, после чего идём в Pin Planner и назначаем ножки. У меня получилось так:

Что соответствует контактам B22 и C22 интерфейсного разъёма.
Делаем чистовую сборку, загружаем процессорную систему в ПЛИС. Теперь нам надо доработать программный код. Запускаем Eclipse.
Напомню, я сейчас работаю с проектом, который расположен в другом каталоге относительно моей прошлой работы с Redd. Чтобы не путаться, я удалю старые проекты из дерева (но только из дерева, не стирая сами файлы).

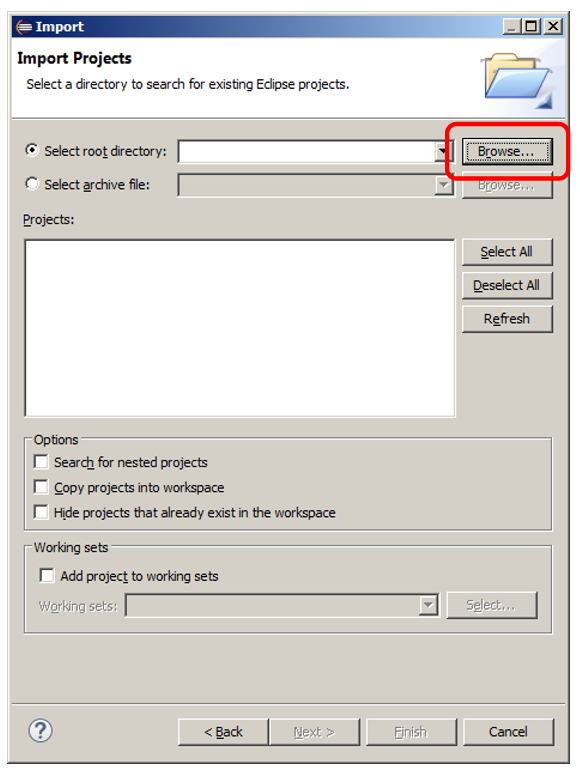
Далее нажму на пустом дереве правую кнопку «мыши» и выберу в меню Import:
Далее — General→Existing Project into Workspace:
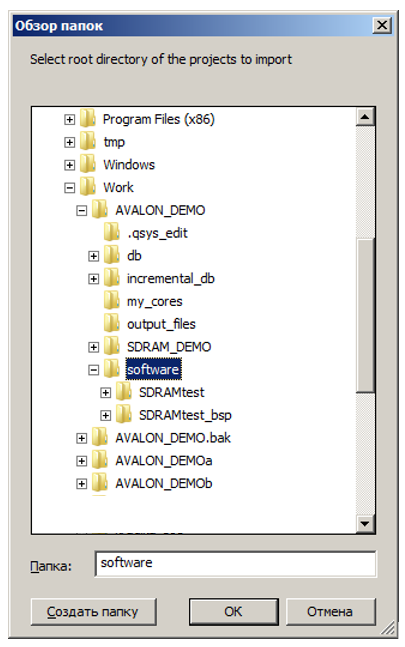
И просто выберу каталог, в котором хранятся файлы проектов:
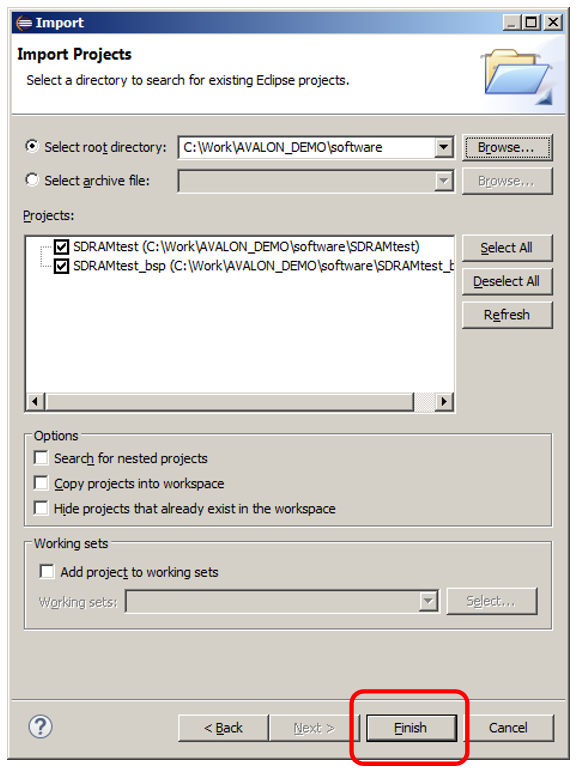
Оба проекта, унаследованные от прошлых экспериментов, подключатся к среде разработки.
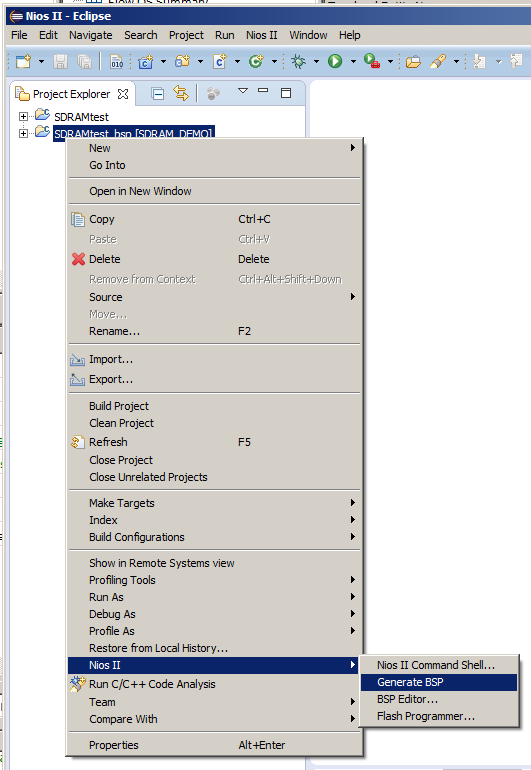
Следующий пункт я выделю в рамку:
Каждый раз после изменения аппаратной конфигурации следует заново выбирать пункт меню Nios II →Generate BSP для проекта BSP.
Собственно, после этой операции, в файле \AVALON_DEMO\software\SDRAMtest_bsp\system.h появился новый блок:
/*
* CrazySerial_0 configuration
*
*/
#define ALT_MODULE_CLASS_CrazySerial_0 CrazySerial
#define CRAZYSERIAL_0_BASE 0x4011020
#define CRAZYSERIAL_0_IRQ -1
#define CRAZYSERIAL_0_IRQ_INTERRUPT_CONTROLLER_ID -1
#define CRAZYSERIAL_0_NAME "/dev/CrazySerial_0"
#define CRAZYSERIAL_0_SPAN 16
#define CRAZYSERIAL_0_TYPE "CrazySerial"
Нас, в первую очередь, интересует константа CRAZYSERIAL_0_BASE.
Добавим в функцию main () код следующего вида:
while (true)
{
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x00);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x01);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x02);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x03);
}
Запускаем отладку и смотрим содержимое линий осциллографом. Должен быть инкрементирующийся двоичный код. Он там имеется.
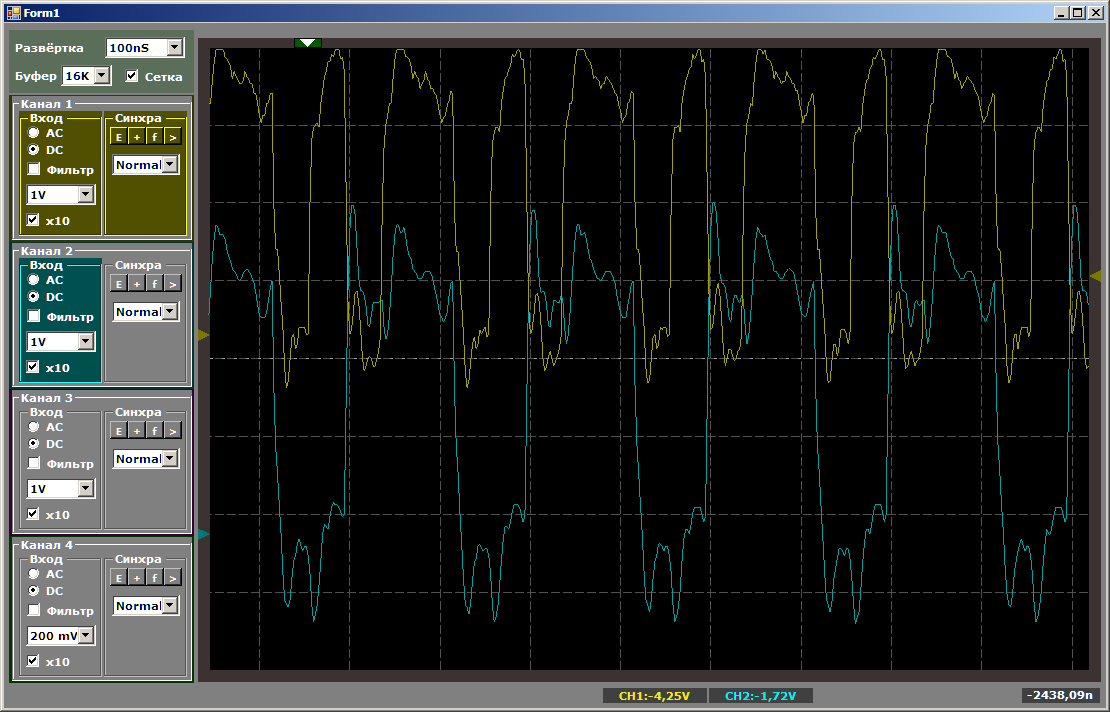
Причём частота доступа к портам просто замечательная:
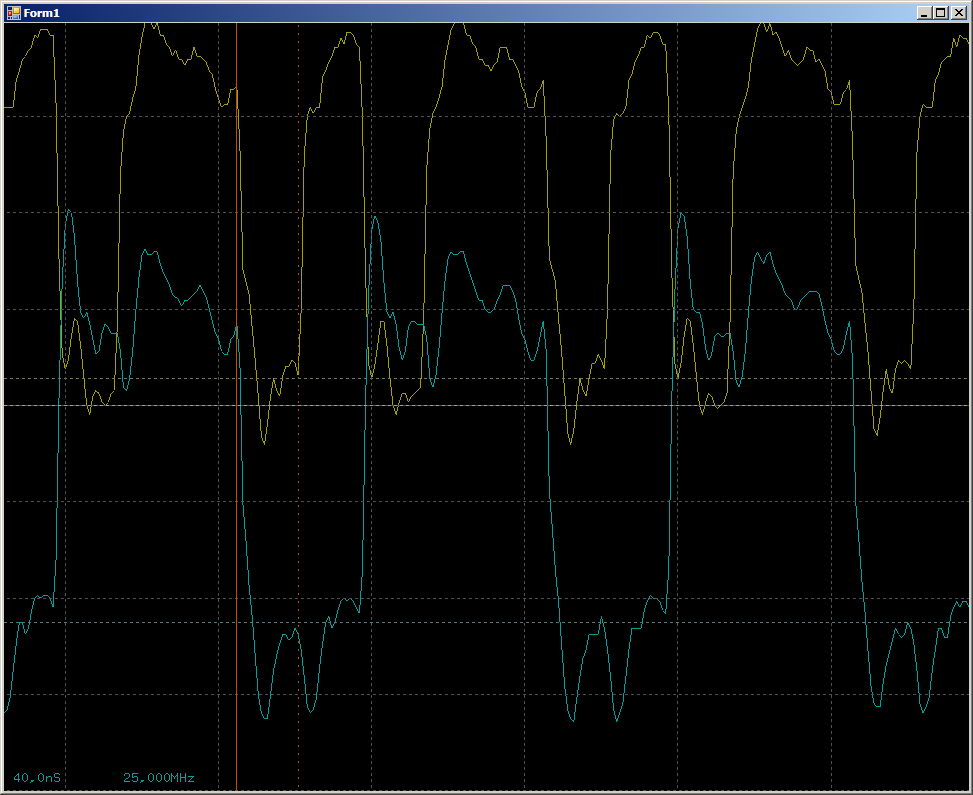
Примерно 25 МГц — половина частоты шины (2 такта на цикл). Иногда время доступа не 2 такта, а больше. Это связано с исполнением операций ветвления в программе. В общем, простейшее обращение к шине работает.
Пришла пора добавить к примеру функциональность последовательного порта. Для этого добавим интерфейсный сигнал waitrequest, относящийся к шине и пару сигналов последовательного порта — sck и sdo. Итого, получаем следующий фрагмент кода на systemverilog:

module CrazySerial
(
input clk,
input reset,
input [1:0] address,
input write,
input [31:0] writedata,
output waitrequest,
output reg [1:0] cs,
output reg sck,
output sdo
);
По правилам хорошего тона надо сделать несложный автомат, который будет осуществлять передачу данных. К сожалению, самый несложный автомат в рамках статьи будет выглядеть очень сложно. Но на самом деле, если я не буду наращивать функционал автомата (а в рамках статьи я не собираюсь этого делать), то состояний у него будет всего два: идёт передача и не идёт передача. Поэтому я могу состояние закодировать одним сигналом:
reg sending = 0;
Во время передачи мне понадобится счётчик битов, делитель тактовой частоты (я же делаю заведомо медленное устройство) и регистр сдвига для передаваемых данных. Добавляем соответствующие регистры:
reg [2:0] bit_cnt = 0;
reg [3:0] clk_div = 0;
reg [7:0] shifter = 0;
Частоту я буду делить на 10 (руководствуясь принципом «а почему бы и нет?»). Соответственно, на пятом такте я буду взводить SCK, а на десятом — ронять эту линию, после чего — выполнять переход к следующему биту данных. На всех остальных тактах — просто увеличивать счётчик делителя. Важно не забывать, что на четвёртом такте также надо увеличивать счётчик, а на девятом — занулять его. Если опустить процесс перехода к следующему биту, то указанная логика выглядит так:
if (sending)
begin
case (clk_div)
4: begin
sck <= 1;
clk_div <= clk_div + 1;
end
9: begin
sck <= 0;
clk_div <= 0;
// <переход к следующему биту>
end
default: clk_div <= clk_div + 1;
endcase
end else
Переход к следующему биту прост. Сдвинули регистр сдвига, затем, если текущий бит седьмой, прекратили работу, переключив состояние автомата, иначе — увеличили счётчик битов.
shifter <= {shifter[6:0],1'b0};
if (bit_cnt == 7)
begin
sending <= 0;
end else
begin
bit_cnt <= bit_cnt + 1;
end
Собственно, всё. Выходной бит всегда берём из старшего бита регистра сдвига:
assign sdo = shifter [7];
И самая главная строка для текущей доработки. Сигнал waitrequest взводим в единицу всегда, когда идёт передача последовательных данных. То есть, он является копией сигнала sending, задающего состояние автомата:
assign waitrequest = sending;
Ну, и при записи в адрес 1 (напоминаю, здесь адресация у нас в 32-битных словах), мы защёлкиваем данные в регистр сдвига, зануляем счётчики и запускаем процесс передачи:
if (write)
//...
2'h01: begin
bit_cnt <= 0;
clk_div <= 0;
sending <= 1;
shifter <= writedata [7:0];
end
default:;
endcase
end
module CrazySerial
(
input clk,
input reset,
input [1:0] address,
input write,
input [31:0] writedata,
output waitrequest,
output reg [1:0] cs,
output reg sck,
output sdo
);
reg sending = 0;
reg [2:0] bit_cnt = 0;
reg [3:0] clk_div = 0;
reg [7:0] shifter = 0;
always @(posedge clk, posedge reset)
begin
if (reset == 1)
begin
cs <= 0;
sck <= 0;
sending <= 0;
end else
begin
if (sending)
begin
case (clk_div)
4: begin
sck <= 1;
clk_div <= clk_div + 1;
end
9: begin
clk_div <= 0;
shifter <= {shifter[6:0],1'b0};
sck <= 0;
if (bit_cnt == 7)
begin
sending <= 0;
end else
begin
bit_cnt <= bit_cnt + 1;
end
end
default: clk_div <= clk_div + 1;
endcase
end else
if (write)
case (address)
2'h00: cs <= writedata [1:0];
2'h01: begin
bit_cnt <= 0;
clk_div <= 0;
sending <= 1;
shifter <= writedata [7:0];
end
default:;
endcase
end
end
assign sdo = shifter [7];
assign waitrequest = sending;
endmodule
Начинаем внедрять новый код в систему. Собственно, путь такой же, как при создании компонента, но часть шагов уже можно опустить. Сейчас мы как раз познакомимся с процессом доработки. Идём в Platform Designer. Если бы у нас поменялся только verilog код, было бы достаточно просто выполнить операцию Generate HDL для готовой системы. Но так как у модуля появились новые линии (то есть, изменился интерфейс), его надо переделать. Для этого выбираем его в дереве, нажимаем правую кнопку «мыши» и выбираем Edit.
Мы редактируем уже готовую систему. Поэтому просто идём на вкладку Files и нажимаем Analyze Sinthesis Files:
Предсказуемо возникли ошибки. Но мы уже знаем, что виной всему неверно трактованные линии. Поэтому идём на вкладку Signals & Interfaces, перетаскиваем по одной линии sck и sdo из интерфейса avalon_slave_0 в интерфейс conduit_end:

Также переименовываем для них поля Signal Type. Результат должен быть следующий:
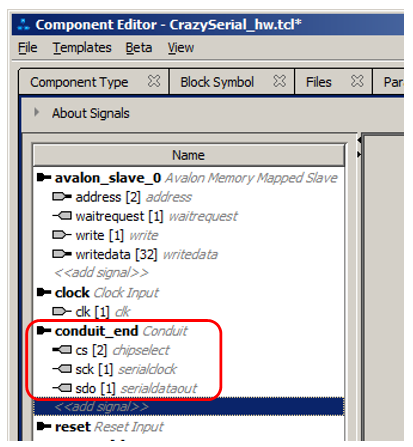
Собственно, всё. Нажимаем Finish, вызываем Generate HDL File для процессорной системы, делаем черновую сборку проекта в Quartus, делаем назначение новых ножек:

Это контакты A21 и A22 интерфейсного разъёма, делаем чистовую сборку, заливаем «прошивку» в ПЛИС.
Железо обновлено. Теперь — программа. Идём в Eclipse. Что там не забываем сделать? Правильно, не забываем выбрать Generate BSP.
Собственно, всё. Осталось добавить функциональность в программу. Сделаем передачу пары байтов в последовательный порт, но первый байт отправим в устройство, выбранное линией cs[0], а второй — cs[1].
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x01);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE+4,0x12);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x02);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE+4,0x34);
IOWR_ALTERA_AVALON_PIO_DATA (CRAZYSERIAL_0_BASE,0x00);
Обратите внимание, что никаких проверок готовности там нет. Посылки идут одна за другой. Тем не менее, на осциллографе всё получилось вполне последовательно
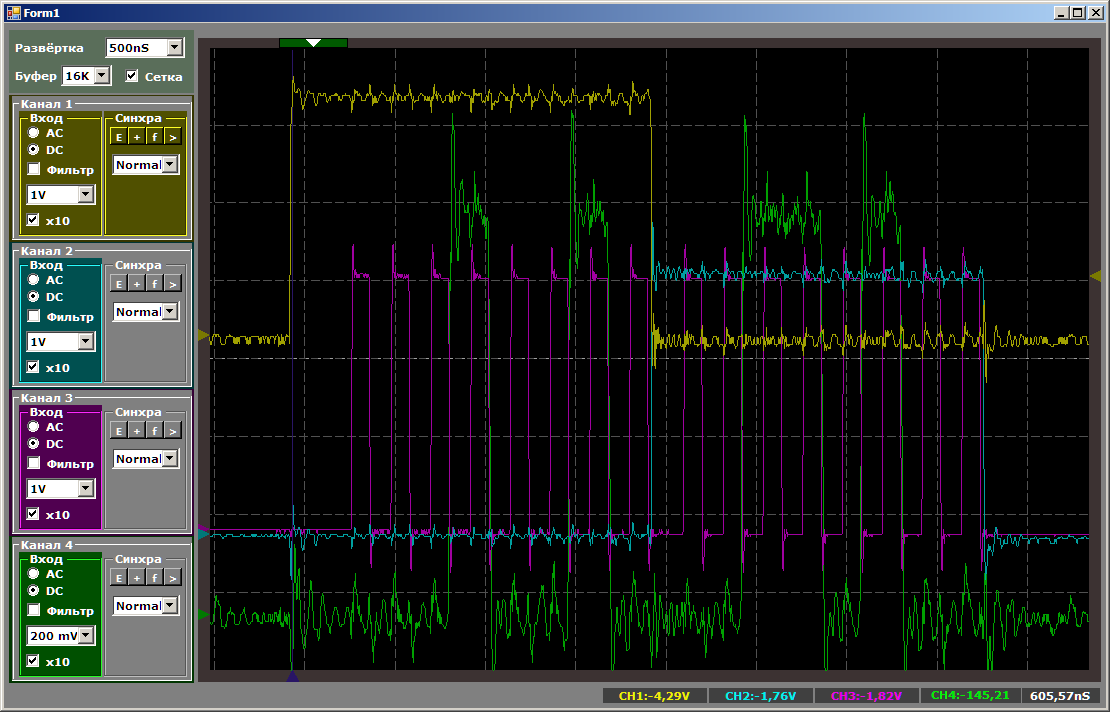
Жёлтый луч — cs[0], зелёный — sdo, фиолетовый — sck, голубой — cs[1]. Видно, что в первое устройство ушёл код 0×12, во второе — 0×34.
Чтение делается аналогично, но мне просто не придумать какого-либо красивого примера, кроме банального чтения содержимого ножки разъёма. Но тот пример настолько вырожденный, что его даже не интересно делать. Но здесь стоит отметить, что при чтении чрезвычайно важной может быть вот эта настройка шины:
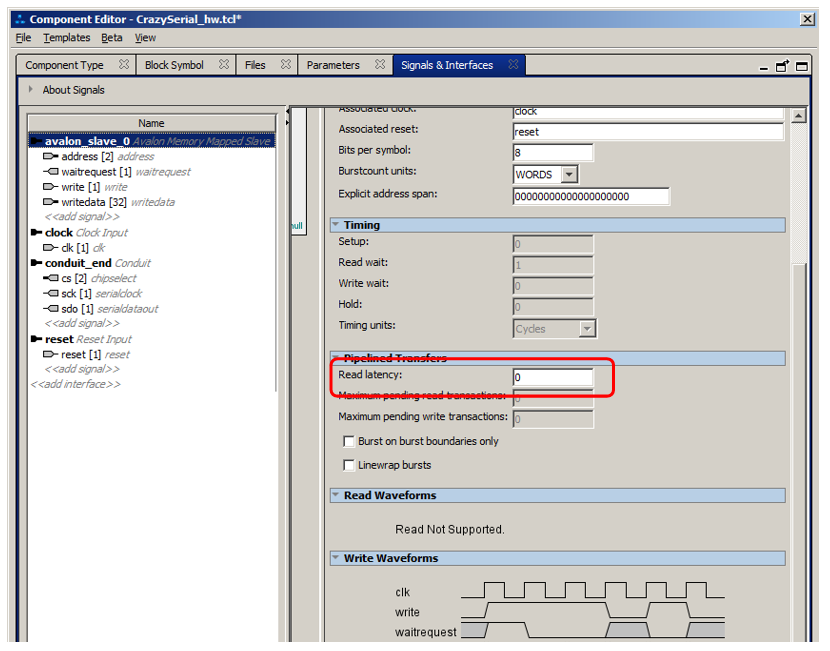
Если имеется линия Read, то на диалоге настройки появится и временная диаграмма чтения. И на ней будет видно влияние данного параметра. При чтении ножки разъёма, это всё равно будет не заметно, а вот при чтении из того же FIFO или ОЗУ — вполне. ОЗУ может быть настроено на выдачу данных сразу после подачи адреса, а может на синхронную выдачу. Во втором случае, добавляется латентность. Ведь шина выставила адрес, выставила строб… Но по ближайшему фронту тактового сигнала данных ещё нет. Они появятся уже после этого фронта… То есть, у системы имеется латентность в один такт. И её как раз надо учесть, задав именно этот параметр. Короче, если читается не то, что ожидалось, в первую очередь проверяйте, не надо ли настроить латентность. В остальном — чтение ничем не отличается от записи.
Ну, и ещё раз напомню, что готовность шины на время длительных операций лучше не снимать, иначе вполне можно резко снизить производительность системы. Сигнал готовности хорош, чтобы придержать выполнение транзакции на пару-тройку тактов, а не вплоть до 80 тактов, как у меня в примере. Но во-первых, любой другой пример был бы неудобен для статьи, а во-вторых, для ядер-однодневок, это вполне допустимо. Вы вполне будете отдавать себе отчёт в своих действиях и будете избегать ситуаций, когда шина блокируется. Правда, если ядро переживёт отпущенное ему время, такое допущение может испортить жизнь в будущем, когда о нём все забудут, а оно всё затормозит. Но это будет потом.
Тем не менее, мы научились делать так, чтобы процессорное ядро управляло нашими ядрами. С адресуемым миром всё ясно, теперь пришла пора разобраться с миром потоковым. Но это мы сделаем уже в следующей статье, а возможно — даже нескольких статьях.
Заключение
В статье показано, как произвольное ядро на языке Verilog может быть подключено на управление средствами процессорной системы Nios II. Показаны варианты простейшего подключения к шине Avalon, а также подключения, при котором шина может находиться в занятом состоянии. Даны ссылки на литературу, из которой можно узнать прочие режимы работы шины Avalon в режиме Memory Mapped.
Получившийся в результате проект можно скачать здесь.
