Путь разработчика в SRE: зачем идти в инфраструктуру и что из этого выйдет
Около года назад я переквалифицировался из .NET-разработчика в SRE. В этой статье делюсь историей о том, как группа опытных разработчиков отложила в сторону C# и пошла изучать Linux, Terraform, Packer, рисовать NALSD и строить IaC, как мы применяли практики экстремального программирования для управления инфраструктурой компании, и что из этого вышло.

В Додо Пицце больше 600 пиццерий в 13 странах мира, а большая часть процессов в пиццериях управляется с помощью информационной системы Dodo IS, которую мы сами пишем и поддерживаем. Поэтому надёжность и стабильность системы важны для выживания.
Сейчас стабильность и надёжность информационной системы в компании поддерживает команда SRE (Site Reliability Engineering), но так было не всегда.
Предыстория: параллельные миры разработчиков и инфраструктуры
Много лет я развивался как типичный fullstack-разработчик (и немного scrum-мастер), учился писать хороший код, применял практики из Extreme Programming и старательно уменьшал количество WTF в проектах, к которым прикасался. Но чем больше появлялось опыта в разработке ПО, тем больше я осознавал важность надёжных систем мониторинга и трейсинга приложений, качественных логов, тотального автоматического тестирования и механизмов, обеспечивающих высокую надёжность сервисов. И всё чаще стал заглядывать «через забор» к команде инфраструктуры.
Чем лучше я понимал, в какой среде работает мой код, тем сильнее удивлялся: автоматические тесты на всё и вся, CI, частые релизы, безопасный рефакторинг и коллективное владение кодом в мире «софта» уже давно обыденны и привычны. При этом в мире «инфраструктуры» до сих пор нормально отсутствие автоматических тестов, внесение изменений в продакшн системы в полуручном режиме, а документация часто есть только в головах отдельных людей, но не в коде.
Этот культурный и технологический разрыв вызывает не только недоумение, но и проблемы: на стыке разработки, инфраструктуры и бизнеса. С частью проблем в инфраструктуре сложно бороться из-за близости к «железу» и относительно слабо развитых инструментов. Но остальное вполне можно победить, если начать смотреть на все свои Ansible-плейбуки и Bash-скрипты как на полноценный программный продукт и применять к ним те же требования.
Бермудский треугольник проблем
Однако я начну издалека — с проблем, ради которых все эти пляски нужны.
Проблемы разработчиков
Два года назад мы поняли, что большая сеть пиццерий не может жить без собственного мобильного приложения и решили его написать:
- собрали классную команду;
- за полгода написали удобное и красивое приложение;
- подкрепили торжественный запуск «вкусными» промоакциями;
- и в первый же день благополучно упали под нагрузкой.
Косяков на старте было, конечно, много, но больше всего мне запомнился один. На время разработки на продакшене был развёрнут один слабый сервер, почти калькулятор, который обрабатывал запросы с приложения. Перед публичным анонсом приложения его нужно было увеличить — мы живем в Azure, и это решалось нажатием одной кнопки.
Но эту кнопку никто не нажал: команда инфраструктуры даже не знала, что сегодня релизится какое-то приложение. Они решили, что следить за продакшеном «некритичного» сервиса — обязанность команды приложения. А разработчик бэкенда (это был его первый проект в Додо) решил, что в крупных компаниях этим занимаются ребята из инфраструктуры.
Тем разработчиком был я. Тогда я вывел для себя очевидное, но важное правило:
Если хочешь, чтобы твоё приложение жило долго и счастливо, внимательно следи за тем, где и как оно выполняется на проде. Даже если для этого есть специально обученные люди.
Сейчас это не сложно. В последние годы появилось огромное количество инструментов, которые позволяют программистам заглянуть в мир эксплуатации и ничего не сломать: Prometheus, Zipkin, Jaeger, ELK стек, Kusto.
Тем не менее у многих разработчиков до сих пор есть серьёзные проблемы с теми, кого называют инфраструктурой/DevOps«ами/SRE. В итоге программисты:
Зависят от команды инфраструктуры. Это вызывает боль, недопонимание, иногда взаимную ненависть.
Проектируют свои системы в отрыве от реальности и не учитывают, где и как будет выполняться их код. Например, архитектура и дизайн системы, которая разрабатывается для жизни в облаке, будет отличаться от дизайна системы, которая хостится on-premise.
Не понимают природу багов и проблем, связанных с их кодом. Особенно это заметно, когда проблемы связаны с нагрузкой, балансировкой запросов, сетью или производительностью жёстких дисков. Разработчики не всегда располагают этими знаниями.
Не могут оптимизировать деньги и другие ресурсы компании, которые используются для поддержания их кода. По нашему опыту бывает так, что команда инфраструктуры просто заливает проблему деньгами, например, увеличивая размер сервера БД на продакшене. Поэтому часто проблемы кода даже не доходят до программистов. Просто почему-то инфраструктура начинает стоить дороже.
Проблемы инфраструктуры
Сложности есть и «на другой стороне».
Сложно управлять десятками сервисов и окружений без качественного кода. У нас в GitHub сейчас больше 450 репозиториев. Часть из них не требует операционной поддержки, часть мертва и сохраняется для истории, но значительная часть содержит сервисы, которые нужно поддерживать. Им нужно где-то хоститься, нужен мониторинг, сбор логов, единообразные CI/CD-пайплайны.
Чтобы всем этим управлять, мы ещё недавно активно использовали Ansible. В нашем Ansible-репозитории было:
- 60 ролей;
- 102 плейбука;
- обвязка на Python и Bash;
- тесты в Vagrant, запускаемые вручную.
Всё это было написано умным человеком и написано хорошо. Но, как только с этим кодом стали активно работать другие разработчики из инфраструктуры и программисты, выяснилось, что плейбуки ломаются, а роли дублируются и «обрастают мхом».
Причина крылась в том, что этот код не использовал многие стандартные практики в мире разработки ПО. В нём не было CI/CD-пайплайна, а тесты были сложными и медленными, поэтому всем было лень или «некогда» запускать их вручную, а уж тем более писать новые. Такой код обречён, если над ним работает более одного человека.
Без знания кода сложно эффективно реагировать на инциденты. Когда в 3 часа ночи в PagerDuty приходит алерт, приходится искать программиста, который объяснит что и как. Например, что вот эти ошибки 500 аффектят пользователя, а другие связаны со вторичным сервисом, конечные клиенты его не видят и можно оставить всё так до утра. Но в три часа ночи программистов разбудить сложно, поэтому желательно самому понимать, как работает код, который ты поддерживаешь.
Многие инструменты требуют встраивания в код приложения. Ребята из инфраструктуры знают, что нужно мониторить, как логировать и на какие вещи обращать внимание для трейсинга. Но встроить это всё в код приложения часто не могут. А те, кто могут, не знают что и как встраивать.
«Сломанный телефон». В сотый раз объяснять, что и как мониторить, неприятно. Проще написать общую библиотеку, чтобы передать её программистам для переиспользования в своих приложениях. Но для этого нужно уметь писать код на том же языке, в том же стиле и с теми же подходами, которые используют разработчики ваших приложений.
Проблемы бизнеса
У бизнеса тоже есть две большие проблемы, которые нужно решать.
Прямые потери от нестабильности системы, связанной с надёжностью и доступностью.
В 2018 году у нас произошёл 51 критический инцидент, а критичные элементы системы не работали в сумме больше 20 часов. В деньгах это 25 млн. рублей прямых потерь из-за несозданных и недоставленных заказов. А сколько мы потеряли на доверии сотрудников, клиентов и франчайзи, — подсчитать невозможно, в деньгах это не оценивается.
Расходы на поддержку текущей инфраструктуры. При этом компания поставила перед нами цель на 2018 год: в 3 раза уменьшить стоимость инфраструктуры в пересчёте на одну пиццерию. Но ни программисты, ни DevOps-инженеры в рамках своих команд не могли даже приблизиться к решению этой задачи. Этому есть причины:
- с одной стороны, для решения таких задач нужны программисты с глубокими знаниями инфраструктуры;
- с другой стороны, нужны operations (назовём их баззвордом DevOps), которые умеют программировать на хорошем промышленном уровне;
- с третьей стороны, бизнесу нужен баланс между надёжностью и доступностью этих систем и их стоимостью.
И что с этим делать?
Как решить все эти проблемы? Решение мы нашли в книге «Site Reliability Engineering» от Google. Когда прочли, поняли — это то, что нам нужно.
Но есть нюанс — чтобы всё это внедрить нужны годы, и с чего-то надо начинать. Рассмотрим исходные данные, которые у нас были изначально.
Вся наша инфраструктура почти полностью живет в Microsoft Azure. Есть несколько независимых кластеров для прода, которые разнесены по разным континентам: Европа, Америка и Китай. Есть нагрузочные стенды, которые повторяют продакшн, но живут в изолированной среде, а также десятки DEV-окружений для команд разработчиков.
Из хороших практик SRE у нас уже были:
- механизмы мониторинга приложений и инфраструктуры (спойлер: это мы в 2018 думали, что они хорошие, а сейчас уже всё переписали);
- процессы для дежурств 24/7 on-call;
- практика ведения постмортемов по инцидентам и их анализ;
- нагрузочное тестирование;
- CI/CD-пайплайны для прикладного софта;
- хорошие программисты, которые пишут хороший код;
- евангелист SRE в команде инфраструктуры.
Но были и проблемы, которые хотелось решить в первую очередь:
Команда инфраструктуры перегружена. На глобальные улучшения не хватало времени и сил из-за текущей операционки. Например, мы очень долго хотели, но не могли избавиться от Elasticsearch в своём стеке, или продублировать инфраструктуру у другого облачного провайдера, чтобы избежать рисков (тут могут посмеяться те, кто уже пробовал в мультиклауд).
Хаос в коде. Инфраструктурный код был хаотичен, разбросан по разным репозиториям и нигде не задокументирован. Всё держалось на знаниях отдельных людей и больше ни на чём. Это была гигантская проблема управления знаниями.
«Есть программисты, а есть инженеры инфраструктуры». Несмотря на то, что у нас достаточно хорошо была развита культура DevOps, всё ещё было это разделение. Два класса людей с абсолютно разным опытом, которые говорят на разных языках и пользуются разными инструментами. Они, конечно, дружат и общаются, но часто не понимают друг друга из-за совершенно разного опыта.
Онбординг SRE-команды
Чтобы решить эти проблемы и как-то начать двигаться в сторону SRE, мы запустили проект онбординга. Только это был не классический онбординг — обучение новых сотрудников (новичков), чтобы добавить людей в текущую команду. Это было создание новой команды из инженеров инфраструктуры и программистов — первый шаг к полноценной структуре SRE.
На проект мы выделили 4 месяца и поставили три цели:
- Обучить программистов тем знаниям и навыкам, которые необходимы для дежурств и операционной деятельности в команде инфраструктуры.
- Написать IaC — описание всей инфраструктуры в коде. Причём это должен быть полноценный программный продукт с CI/CD, тестами.
- Пересоздать всю нашу инфраструктуру из этого кода и забыть про ручное накликивание виртуалок мышкой в Azure.
Состав участников: 9 человек, 6 из них из команды разработки, 3 из инфраструктуры. На 4 месяца они должны были уйти из обычной работы и погрузиться в обозначенные задачи. Чтобы поддерживать «жизнь» в бизнесе, ещё 3 человека из инфраструктуры остались дежурить, заниматься операционкой и прикрывать тылы. В итоге проект заметно растянулся и занял больше пяти месяцев (с мая по октябрь 2019-го года).
Две составляющие онбординга: обучение и практика
Онбординг состоял из двух частей: обучения и работы над инфраструктурой в коде.
Обучение. На обучение выделялось минимум 3 часа в день:
- на чтение статей и книг из списка литературы: Linux, сети, SRE;
- на лекции по конкретным инструментам и технологиям;
- на клубы по технологиям, например, по Linux, где мы разбирали сложные случаи и кейсы.
Ещё один инструмент обучения — внутреннее демо. Это еженедельная встреча, на которой каждый (кому есть, что сказать) за 10 минут рассказывал о технологии или концепции, которую он внедрил в нашем коде за неделю. Например, Вася поменял пайплайн работы с Terraform-модулями, а Петя переписал сборку образов на Packer.
После демо мы заводили обсуждения под каждой темой в Slack, где заинтересованные участники могли асинхронно обсуждать всё детальнее. Так мы избегали длинных встреч на 10 человек, но при этом все в команде хорошо понимали, что происходит с нашей инфраструктурой и куда мы катимся.

Практика. Вторая часть онбординга — создание/описание инфраструктуры в коде. Эту часть разделили на несколько этапов.
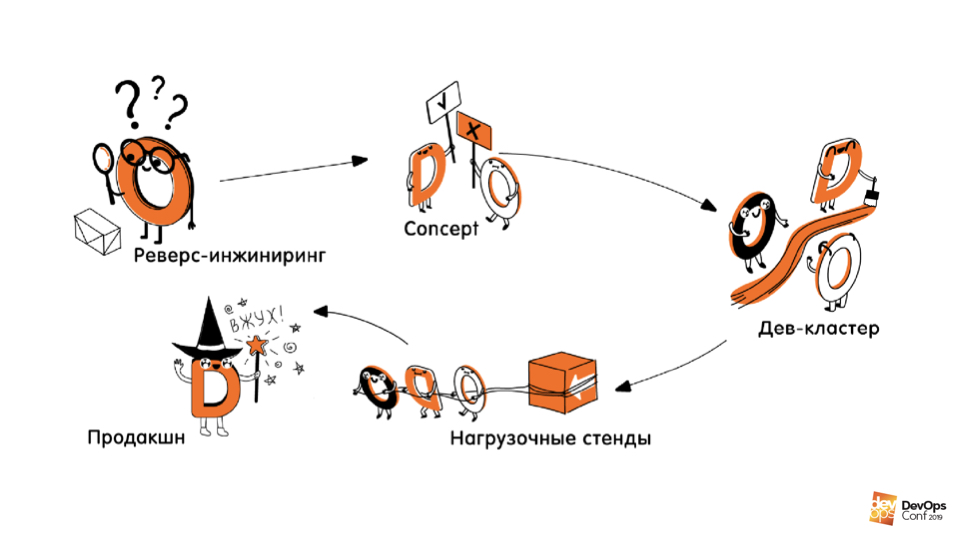
Реверс–инжиниринг инфраструктуры. Это первый этап, на котором разобрали, что где задеплоено, как что работает, где какие сервисы работают, где какие машины и их размеры. Всё полностью задокументировали.
Концепты. Мы экспериментировали с разными технологиями, языками, подходами, выясняли, как можем описать нашу инфраструктуру, какие инструменты стоит для этого использовать.
Написание кода. Сюда входило само написание кода, создание CI/CD-пайплайнов, тестов и построение процессов вокруг всего этого. Мы написали код, который описывал и умел создавать с нуля нашу дев-инфраструктуру.
Пересоздание стендов для нагрузочного тестирования и продакшена. Это четвёртый этап, который должен был идти после онбординга, но его пока отложили, так как профита от него, как ни странно, гораздо меньше, чем от дев-окружений, которые создаются/пересоздаются очень часто.
Вместо этого мы переключились на проектную деятельность: разбились на небольшие подкоманды и занялись теми глобальными инфраструктурными проектами, до которых раньше не доходили руки. Ну и конечно включились в дежурства.
- Terraform для описания текущей инфраструктуры.
- Packer и Ansible для создания образов виртуальных машин.
- Jsonnet и Python как основные языки разработки.
- Облако Azure, потому что у нас там хостинг.
- VS Code — IDE, для которой создали единые настройки, расширенный набор плагинов, линтеров и прочего, чтобы писать унифицированный код и расшарили их между всеми разработчиками.
- Практики разработки — одна из основных вещей, ради которой затевался весь этот карнавал.
Практики Extreme Programming в инфраструктуре
Главное, что мы, как программисты, принесли с собой — это практики Extreme Programming, которые используем в работе. XP — гибкая методология разработки ПО, соединяющая в себе выжимку из лучших подходов, практик и ценностей разработки.
Нет ни одного программиста, который бы не использовал хотя бы несколько из практик Extreme Programming, даже если он об этом не знает. При этом в мире инфраструктуры данные практики обходят стороной, несмотря на то, что они в очень большой степени пересекаются с практиками из Google SRE.
О том, как мы адаптировали XP для инфраструктуры, есть отдельная статья. Но если вкратце: практики XP работают и для кода инфраструктуры, пусть с ограничениями, адаптациями, но работают. Если хотите их применять у себя, зовите людей с опытом применения этих практик. Большинство из этих практик так или иначе описаны в той самой книге о SRE.
Всё могло бы сложиться хорошо, но так не бывает.
Технические и антропогенные проблемы на пути
В рамках проекта было два вида проблем:
- Технические: ограничения «железного» мира, недостаток знаний и сырые инструменты, которыми приходилось пользоваться, потому что других нет. Это привычные любому программисту проблемы.
- Человеческие: взаимодействие людей в команде. Общение, принятие решений, обучение. С этим было хуже, поэтому нужно остановиться подробнее.
Мы начали развивать команду онбординга так, как стали бы делать это с любой другой командой программистов. Мы ожидали, что будут обычные стадии формирования команды по Такману: шторминг, норминг, а в конце мы выйдем на производительность и продуктивную работу. Поэтому не переживали, что вначале возникали какие-то сложности в общении, принятии решений, сложности с тем, чтобы договориться.
Прошло два месяца, но фаза шторминга продолжалась. Только ближе к концу проекта мы осознали, что все проблемы, с которыми мы боролись и не воспринимали, как связанные друг с другом были следствием общей корневой проблемы — в команде сошлись две группы абсолютно разных людей:
- Опытные программисты с годами опыта, за которые они выработали свои подходы, привычки и ценности в работе.
- Другая группа из мира инфраструктуры со своим опытом. У них другие шишки, другие привычки, и они тоже считают, что знают как правильно жить.
Произошло столкновение двух взглядов на жизнь в одной команде. Мы не увидели этого сразу и не начали с этим работать, в результате чего потеряли очень много времени, сил и нервов.
Но избежать этого столкновения невозможно. Если позовёте в проект сильных программистов и слабых инженеров инфраструктуры, то у вас будет однонаправленный обмен знаний. Наоборот тоже не работает — одни проглотят других и всё. А вам нужно получить некую смесь, поэтому нужно быть готовым к тому, что «притирка» может оказаться очень долгой (в нашем случае мы смогли стабилизировать команду лишь спустя год, попрощавшись при этом с одним из самых сильных в техническом плане инженеров).
Если хотите собрать именно такую команду, не забудьте позвать сильного Agile- коуча, scrum-мастера, или психотерапевта — что больше нравится. Возможно, они помогут.
Итоги онбординга
По итогам проекта онбординга (он завершился в октябре 2019 года) мы:
- Создали полноценный программный продукт, который управляет нашей DEV-инфраструктурой, с собственным CI-пайплайном, с тестами и прочими атрибутами качественного программного продукта.
- Удвоили количество людей, которые готовы дежурить и сняли нагрузку с текущей команды. Спустя ещё полгода эти люди стали полноценными SRE. Теперь они могут потушить пожар на проде, проконсультировать команду программистов по НФТ, или написать свою библиотеку для разработчиков.
- Сместили майндсет в сторону идей SRE. Не только у участников проекта онбординга, но и у тех программистов из продуктовых команд, которые теперь могут разговаривать с нами на одном языке.
- Сильно устали: и те, кто участвовал в онбординге, и те, кто участвовал в дежурствах.
Вместо выводов: инсайты, не наступайте на наши грабли
Несколько инсайтов от разработчика. Не наступайте на наши грабли, сэкономьте себе и окружающим нервы и время.
Инфраструктура пока в прошлом. Когда я учился на первом курсе (15 лет назад) и начинал изучать JavaScript, у меня из инструментов были NotePad ++ и Firebug для отладки. C этими инструментами уже тогда нужно было делать какие-то сложные и красивые вещи.
Примерно так же я ощущаю себя сейчас, когда работаю с инфраструктурой. Текущие инструменты только формируются, многие из них ещё не вышли в релиз и имеют версию 0.12 (привет, Terraform), а у многих регулярно ломается обратная совместимость с предыдущими версиями.
Для меня, как энтерпрайз-разработчика, использовать на проде такие вещи — абсурд. Но других просто нет.
Читайте документацию. Как программист, я относительно редко обращался к докам. Я достаточно глубоко знал свои инструменты: любимый язык программирования, любимый фреймворк и БД. Все дополнительные инструменты, например, библиотеки, обычно написаны на том же языке, а значит всегда можно посмотреть в исходники. IDE всегда подскажет, какие и где нужны параметры. Даже если я ошибусь, то быстро это пойму, запустив быстрые тесты.
В инфраструктуре так не получится, там огромное количество различных технологий, которые необходимо знать. Но глубоко всё знать невозможно, а многое написано на неведомых языках. Поэтому внимательно читайте (и пишите) документацию — без этой привычки здесь долго не живут.
Комментарии в коде инфраструктуры неизбежны. В мире разработки комментарии — признак плохого кода. Они быстро устаревают и начинают врать. Это признак того, что разработчик не смог иначе выразить свои мысли. При работе с инфраструктурой комментарии так же признак плохого кода, но без них уже не обойтись. Для разрозненных инструментов, которые слабо связаны друг с другом и ничего не знают друг о друге, без комментариев не обойтись.
Часто под кодом скрываются обычные конфиги и DSL. При этом вся логика происходит где-то глубже, куда нет доступа. Это сильно меняет подход к коду, тестированию и работе с ним.
Не бойтесь пускать разработчиков в инфраструктуру. Они могут привнести полезные (и свежие) практики и подходы из мира разработки ПО. Пользуйтесь практиками и подходами от Google, описанными в книге про SRE, получайте пользу и будьте счастливы.
PS: Я специально не стал затрагивать в этой статье темы микросервисов, Кубернетеса и прочие хайповые вещи, с которыми приходится учиться жить, так как это большая тема для отдельной статьи.PPS: Эта статья написана по моему выступлению на DevOpsConf осенью 2019 года. С тех пор прошло довольно много времени, и теперь уже точно понятно, что всё было не зря: тойл теперь не съедает бОльшую часть времени инженеров, наша команда теперь может реализовывать крупные долгосрочные проекты по улучшению инфраструктуры в широком смысле, а программисты почти не жалуются на безумных DevOps-инженеров, которые только мешают жить.
PPPS: В этом году конференция, посвящённая DevOps-практикам, будет называться DevOps Live 2020. Изменения коснутся не только названия: в программе будет меньше докладов и больше интерактивных обсуждений, мастер-классов и воркшопов. Рецепты о том, как расти и перестраивать процессы с помощью DevOps-практик. Формат также изменится — два блока по два дня и «домашние задания» между ними.
Чтобы узнать подробнее о том, что будет происходить на DevOps Live и что полезного вынесут инженеры, безопасники, тимлиды и CTO, подписывайтесь на рассылку и следите за публикациями в блоге.
