Псс, парень… индекс нужен?
 Индексы PostgreSQL оптом и в розницу
Индексы PostgreSQL оптом и в розницу
Самый больной вопрос для любого разработчика, которому приходится вычитывать данные из базы: «Как сделать мой запрос быстрее?». Классический ответ — необходимо создать подходящий индекс. Но куда именно его стоит «накатывать», да и как вообще он должен выглядеть?…
Мы научили наш сервис визуализации планов PostgreSQL отвечать на эти вопросы, и под катом расскажем, чем именно он руководствуется в своих рекомендациях.
Вообще, разного рода рекомендации мы умеем раздавать уже давно — о некоторых из них можно прочитать в статье «Рецепты для хворающих SQL-запросов». Сегодня мы подробно рассмотрим некоторые из них, когда правильный индекс действительно может помочь улучшить производительность запроса.
И «правильный» — тут ключевое слово, потому что насоздавать неправильных индексов, которые нормально работать все равно не будут — наука невелика. А вот чтобы их потом вычислить и зачистить, уже придется использовать методы из статьи «DBA: находим бесполезные индексы».
Чтобы не начинать с самых азов, договоримся, что пользоваться EXPLAIN все умеют, и что такое Seq Scan, Index Scan и Bitmap Index Scan знают. А если нет — стоит почитать переводы хороших постов Hubert 'depesz' Lubaczewski.
Проблема #1: Seq Scan
Давайте создадим модельную табличку из знакомой всем таблицы pg_class, и будем проводить эксперименты над ее копией:
CREATE TABLE pg_class_copy AS TABLE pg_class;Посмотрим, как реагирует база на попытку найти идентификаторы всех последовательностей (sequence), которые есть у нас в базе:
explain (analyze, buffers, costs off, verbose)
SELECT oid FROM pg_class_copy WHERE relkind = 'S';Поскольку ни одного индекса на нашей таблице нет, то получим самый простой вариант, который может встретиться в плане Seq Scan:
Seq Scan on pg_class_copy (actual time=0.017..0.105 rows=2 loops=1)
Output: oid
Filter: (pg_class_copy.relkind = 'S'::"char")
Rows Removed by Filter: 427
Buffers: shared hit=11Filter — это как раз то самое условие, которое заставило PostgreSQL из 429 прочитанных записей отбросить 427 и оставить для нас только 2. И это плохо — мы прочитали в 200 раз больше необходимого количества записей!
Способы индексации
Индекс по полю/выражению
Очевидно, что сразу напрашивается индекс по значению поля pg_class_copy(relkind):
CREATE INDEX ON pg_class_copy USING btree(relkind);И мы видим, что вместо фильтрации наше выражение теперь ушло в условие индексного поиска Index Cond, а сам узел превратился в Index Scan:
Index Scan using pg_class_copy_relkind_idx on pg_class_copy (actual time=0.010..0.011 rows=2 loops=1)
Output: oid
Index Cond: (pg_class_copy.relkind = 'S'::"char")
Buffers: shared hit=2Индекс с условием
С другой стороны, мы можем все выражение вынести в WHERE-условие индекса, а его поля использовать под что-то более насущное — например, под тот самый oid, который мы вычитываем:
CREATE INDEX ON pg_class_copy USING btree(oid) -- индексируемое поле
WHERE relkind = 'S'; -- условие применения индексаОбратите внимание, что узел превратился в Index Only Scan, а вот вынесенное нами условие исчезло из плана вовсе:
Index Only Scan using pg_class_copy_oid_idx on pg_class_copy (actual time=0.012..0.013 rows=2 loops=1)
Output: oid
Heap Fetches: 0
Buffers: shared hit=2Такое поведение характерно только для узлов Index [Only] Scan — в Seq Scan нам и так видны все условия сразу, а в Bitmap Heap Scan мы увидим условия дополнительной проверки записей страниц в строке Recheck Cond.
Неиндексируемые выражения
Но далеко не все выражения можно проиндексировать, а только сводящиеся к IMMUTABLE в терминах категорий изменчивости функций.
Применительно к индексам это означает, что выражение должно быть вычислимо с использованием только полей записи и IMMUTABLE-функций, выдающих всегда один и тот же результат.
Если на совсем простых примерах:
Условие |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На что обратить внимание:
Из всех этих вариантов условий, только первый допускает создание индекса
(...) WHERE ts >= '2022-04-01 00:00:00'::timestamp, во всех остальных случаях правая часть не-иммутабельна.Хотя все три последних варианта математически эквивалентны, но…
первый может использовать наиболее общий индекс и не зависит от константы
второй требует специального индекса с фиксацией константы
третий не может быть проиндексирован из-за вариативности
now()и является примером одной из классических ошибок при использовании индексов
Типы индексов
Пока мы использовали только btree — самый простой и «дефолтный» из всех типов индексов, которые PostgreSQL поддерживает «из коробки», его даже можно можно опускать при описании индекса:
CREATE INDEX ON pg_class_copy(relkind);Но типов индексов в PostgreSQL гораздо больше, и каждый из них обладает своими возможностями и ограничениями, но основное отличие — поддерживаемые типы полей (на самом деле, конечно, произвольных IMMUTABLE-выражений от них) и операторы.
Некоторые из них могут быть модифицированы с использованием дополнительных расширений, поэтому я приведу только базовые возможности доступные «из коробки».
btree
Операторы линейного порядка (<, <=, =, >=, >):
числовые (
smallint, integer, bigint, numeric, real, double precision)хронологические (
date, time, time without time zone, time with time zone, timestamp, timestamp without time zone, timestamp with time zone)uuidтекстовые (
varchar, text)
Операторы префиксного поиска (~<~, ~<=~, ~, ~>=~, ~>~) с использованием дополнительных классов операторов:
[подробнее: обзор]
hash
Индекс может содержать только одно поле и поддерживает только один оператор =, поэтому в реальной работе малоприменим.
[подробнее: обзор]
gist
Операторы геометрических отношений (<<, &<, &>, >>, <@, @>, ~=, &&, <<|, &<|, |&>, |>>, ~, @):
геометрические (
box, circle, poly, point)
Операторы для сетевых адресов (<<, <<=, >>, >>=, =, <>, <, <=, >, >=, &&):
Операторы для диапазонов (=, &&, @>, <@, <<, >>, &<, &>, -|-):
диапазоны числовые (
int4range, int8range, numrange)диапазоны хронологические (
daterange, tsrange, tstzrange)
Операторы текстового поиска (<@, @>, @@) :
[подробнее: документация, обзор]
Дополнительно:
поддерживает оператор упорядочивания
<->, который позволяет осуществлять индексный kNN-поискпри использовании расширения btree_gist поддерживает операторы и типы
btree
spgist
Индекс может содержать только одно поле и поддерживает те же возможности, что и у gist, включая оператор упорядочивания <->, но с большей оптимизацией для пространственных данных.
[подробнее: документация, обзор]
gin
Операторы для массивов (&&, @>, <@, =):
Операторы jsonb-ключей (@>, @?, @@, ?, ?|, ?&):
Операторы jsonb-путей (@>, @?, @@):
Операторы текстового поиска (@@, @@@) :
[подробнее: документация, обзор]
Дополнительно:
brin
Блочный индекс с возможностями btree.
С одной стороны, позволяет эффективно индексировать большие блоки данных, с другой — неэффективен для небольших, поскольку всегда получается Bitmap Heap Scan.
[подробнее: обзор]
Условия применимости
Из приведенных выше особенностей следует достаточно простой алгоритм, когда и какой тип можно попробовать использовать, а когда не стоит:
поддержка нужного оператора;
не стоит пытаться использовать
btree-индекс, если у вас условие с<>, но если у вас~>=~, не забудьтеtext_pattern_ops.поддержка нужного типа;
хотите что-то искать в
jsonb— толькоgin, если надо сочетать<, =, >и<@— смотрим наbtree_gist/btree_gin.поддержка нескольких полей;
если необходима, то
hashиspgistсразу отпадают.количество данных;
если возвращается мало записей, то
brinвам не нужен.
Теперь, зная все это, посмотрим, что нам порекомендует explain.tensor.ru:
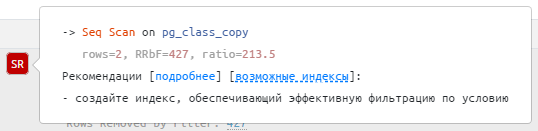 Явно стоит создать индекс
Явно стоит создать индекс
Наиболее релевантным для данного случая сервис выбрал обычный btree-индекс по полю фильтрации:
 Рекомендованный btree-индекс
Рекомендованный btree-индекс
Комментарий содержит описание вычисленных типов для всех индексируемых полей и использованные с ними в условии операторы. Итоговый SQL-запрос для создания такого индекса можно в один клик скопировать в буфер обмена.
Проблема #2: BitmapAnd
Для демонстрации второй проблемы давайте возьмем табличку из прошлой статьи про способы работы с EAV-структурой:
CREATE TABLE tst_eav AS
SELECT
(random() * 1e4)::integer e -- 10k объектов
, (random() * 1e2)::integer a -- 100 характеристик
, (random() * 1e2)::integer v -- 100 вариантов значений
FROM
generate_series(1, 1e6); -- 1M записей о значениях
CREATE INDEX ON tst_eav(a);
CREATE INDEX ON tst_eav(v);Пробуем отобрать сразу по двум ключам:
explain (analyze, buffers, costs off)
SELECT * FROM tst_eav WHERE a = 1 AND v = 1;Bitmap Heap Scan on tst_eav (actual time=1.495..1.603 rows=98 loops=1)
Recheck Cond: ((a = 1) AND (v = 1))
Heap Blocks: exact=97
Buffers: shared hit=119
-> BitmapAnd (actual time=1.466..1.466 rows=0 loops=1)
Buffers: shared hit=22
-> Bitmap Index Scan on tst_eav_a_idx (actual time=0.651..0.651 rows=10036 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=11
-> Bitmap Index Scan on tst_eav_v_idx (actual time=0.627..0.627 rows=9963 loops=1)
Index Cond: (v = 1)
Buffers: shared hit=11Очевидно, что каждый из Bitmap Index Scan «наметил» к дальнейшей проверке по 10K записей, а всего нам их оказалось нужно 98. Посмотрим внимательно на Recheck Cond — там два условия, которые мы можем комбинировать как в варианте с Seq Scan:
(a, v)
(a) WHERE v = 1
(v) WHERE a = 1
(?) WHERE a = 1 AND v = 1Попробуем первый вариант с составным индексом как наиболее типовой:
Bitmap Heap Scan on tst_eav (actual time=0.036..0.117 rows=98 loops=1)
Recheck Cond: ((a = 1) AND (v = 1))
Heap Blocks: exact=97
Buffers: shared hit=100
-> Bitmap Index Scan on tst_eav_a_v_idx (actual time=0.021..0.021 rows=98 loops=1)
Index Cond: ((a = 1) AND (v = 1))
Buffers: shared hit=3Теперь вместо 22 страниц данных мы прочитали всего 3 — и это хорошо!
Что же нам посоветуют сделать авторекомендации explain?…
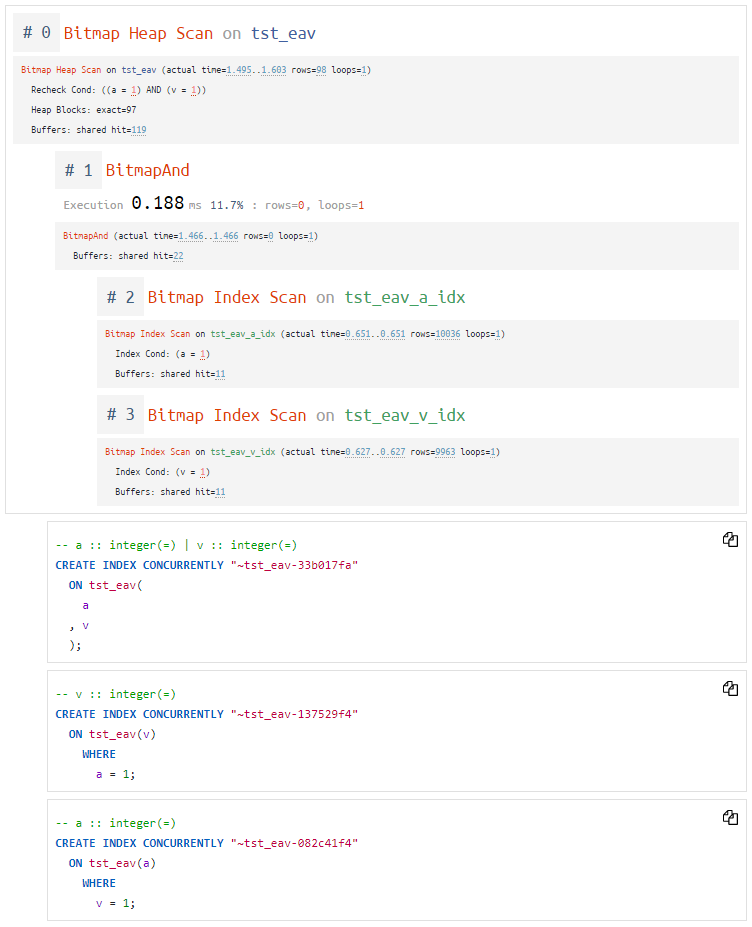 Три варианта возможных индексов — на усмотрение разработчика
Три варианта возможных индексов — на усмотрение разработчика
Тут мы видим сразу всю «цепочку» узлов, которая демонстрирует нам необходимость именно таких индексов.
Проблема #3: Limit — Sort — Scan
Давайте чуть модифицируем запрос, и найдем запись с минимальным v для конкретного заданного a:
explain (analyze, buffers, costs off)
SELECT * FROM tst_eav WHERE a = 1 ORDER BY v LIMIT 1;Limit (actual time=49.178..49.178 rows=1 loops=1)
Buffers: shared hit=3048 read=99
-> Gather Merge (actual time=49.177..55.782 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=5425 read=99
-> Sort (actual time=30.746..30.746 rows=1 loops=3)
Sort Key: v
Sort Method: top-N heapsort Memory: 25kB
Buffers: shared hit=5425 read=99
Worker 0: Sort Method: top-N heapsort Memory: 25kB
Worker 1: Sort Method: top-N heapsort Memory: 25kB
-> Parallel Seq Scan on tst_eav (actual time=0.023..30.286 rows=3345 loops=3)
Filter: (a = 1)
Rows Removed by Filter: 329988
Buffers: shared hit=5307 read=99«Параллельность» Seq Scan не должна нас смущать, и для условия a = 1 мы ровно как в первом случае можем порекомендовать варианты индексов:
(a)
(?) WHERE a = 1Но если мы поднимемся выше, то увидим, что Sort-узел хранит информацию о дополнительно используемых полях: Sort Key: v. Так почему бы нам не расширить индексы ключом сортировки?
(a, v)
(v) WHERE a = 1Попробуем первый из них (a, v) — тем более, он же попал и в рекомендации предыдущей проблемы:
Limit (actual time=0.023..0.023 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using tst_eav_a_v_idx on tst_eav (actual time=0.021..0.021 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=4Наш запрос ускорился больше чем в 2000 раз! Но при дальнейших оптимизациях надо быть много аккуратнее — в плане теперь вообще не фигурирует условие сортировки по v .
Замечу, что такое расширение индекса имеет смысл только в случае использования оператора = или IS NULL для всех остальных полей, иначе это не сможет использоваться эффективно. То есть, например, для условия a > 1 — увы, оптимизация не даст эффекта.
Посмотрим, что нам присоветует сервис:
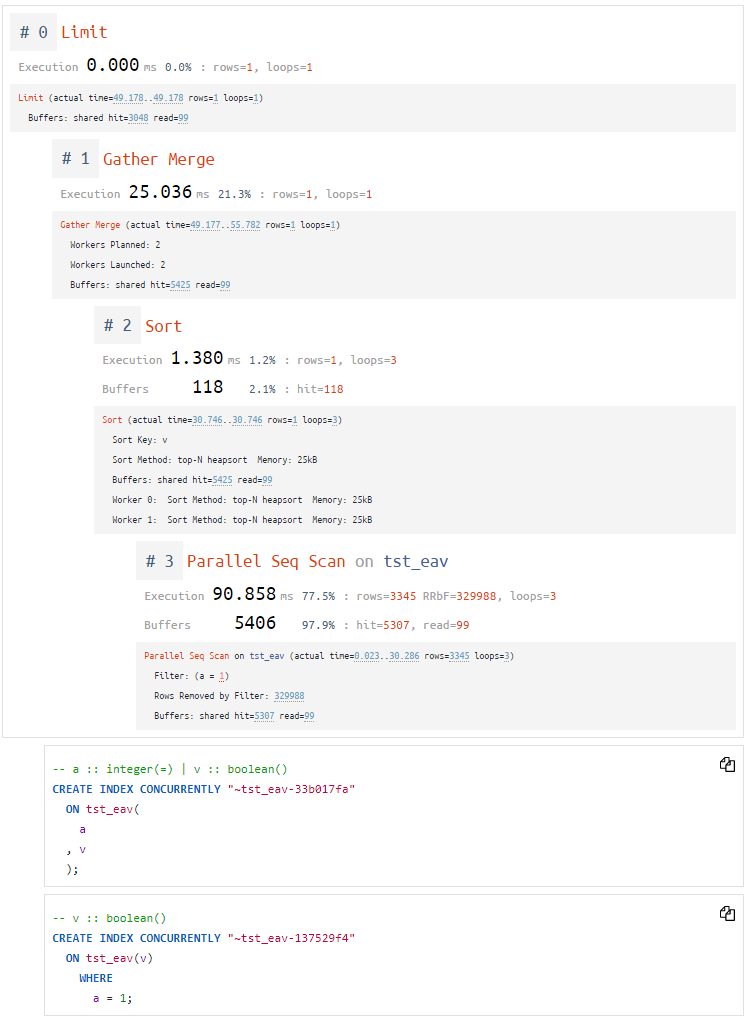 Пара вариантов ускоряющих индексов для Limit — Sort — Scan
Пара вариантов ускоряющих индексов для Limit — Sort — Scan
И прямо-таки ровно то, что мы и ожидали!
А еще explain.tensor.ru научился замечать, когда…
