Протекающие абстракции и код, оставшийся со времён Windows 98

В конце 1990-х команды разработчиков Windows Shell и Internet Explorer внедрили множество потрясающих и сложных структур, позволяющих использовать расширение оболочки и браузера для обработки сценариев, создаваемых третьими сторонами. Например, Internet Explorer поддерживал концепцию подключаемых протоколов (»Что если какой-то протокол, допустим, FTPS станет таким же важным, как и HTTP? »), а Windows Shell обеспечивала чрезвычайно гибкое множество абстрактного использования пространств имён, что позволяло третьим сторонам создавать просматриваемые «папки», в основе которых не лежит файловая система — от WebDAV (»ваш HTTP-сервер — это папка») до папок CAB (»ваш архив CAB — это папка»). Работая в 2004 году проект-менеджером в команде по созданию клипарта, я создал приложение .NET для просмотра клипарта прямо из веб-сервисов Office, и набросал черновик расширения Windows Shell, благодаря которому бы казалось, что огромный веб-архив клипарта Microsoft был установлен в локальной папке системы пользователя.
Вероятно, самым популярным (или печально известным) примером расширения пространства имён оболочки является расширение Compressed Folders, обрабатывающее просмотр файлов ZIP. Compressed Folders, впервые появившиеся в составе Windows 98 Plus Pack, а позже и в Windows Me+, позволяли миллиардам пользователей Windows взаимодействовать с файлами ZIP без скачивания стороннего ПО. Вероятно, это может вас удивить, но эта функция была куплена у третьих лиц — Microsoft приобрела интеграцию для Explorer, представлявшую собой побочный проект Дэйва Пламмера, а лежащий в её основе движок DynaZIP разработала компания InnerMedia.
К сожалению, этот код уже давно не обновляли. Очень давно. Судя по временной метке модуля, последний раз он обновлялся на День святого Валентина в 1998 году; я подозреваю, что с тех пор в него вносили незначительные изменения (и одну функцию — поддержку имён файлов в Unicode, работающую только для извлечения), но всё равно не секрет, что, как сказал Реймонд Чен, этот код «остался на стыке веков». Это значит, что он не поддерживает такие «современные» функции, как шифрование AES, а его производительность (время выполнения и степень сжатия) сильно отстают от современных реализаций, созданных третьими сторонами.
Тогда почему же его не обновляли? Отчасти в этом виноват принцип »не сломано — не чини»: реализация ZIP Folders выживала в Windows в течение 23 лет, и при этом вопли пользователей не становились невыносимыми, то есть их вполне всё устраивало.
К сожалению, есть вырожденные случаи, в которых поддержка ZIP оказывается по-настоящему поломанной. С одной из них я столкнулся на днях. Я увидел интересный пост в Twitter о шестнадцатеричных редакторах с возможностью аннотаций (что полезно при исследовании форматов файлов) и решил попробовать некоторые из них (я решил, что больше всего мне нравится ReHex). Но в процессе этого исследования я скачал portable-версию ImHex и попробовал переместить её в папку Tools на своём компьютере.
Я дважды щёлкнул по файлу ZIP размером 11,5 МБ, чтобы открыть его. Затем я нажал CTRL+A, чтобы выбрать все файлы, а затем (это важно) нажал CTRL+X, чтобы вырезать файлы с буфера обмена.

Затем я создал новую папку внутри
C:\Tools и нажал CTRL+V, чтобы вставить файлы. И тут всё пошло наперекосяк — Windows больше минуты отображала окно »Calculating…», но кроме создания одной подпапки с одним файлом на 5 КБ больше ничего не происходило: 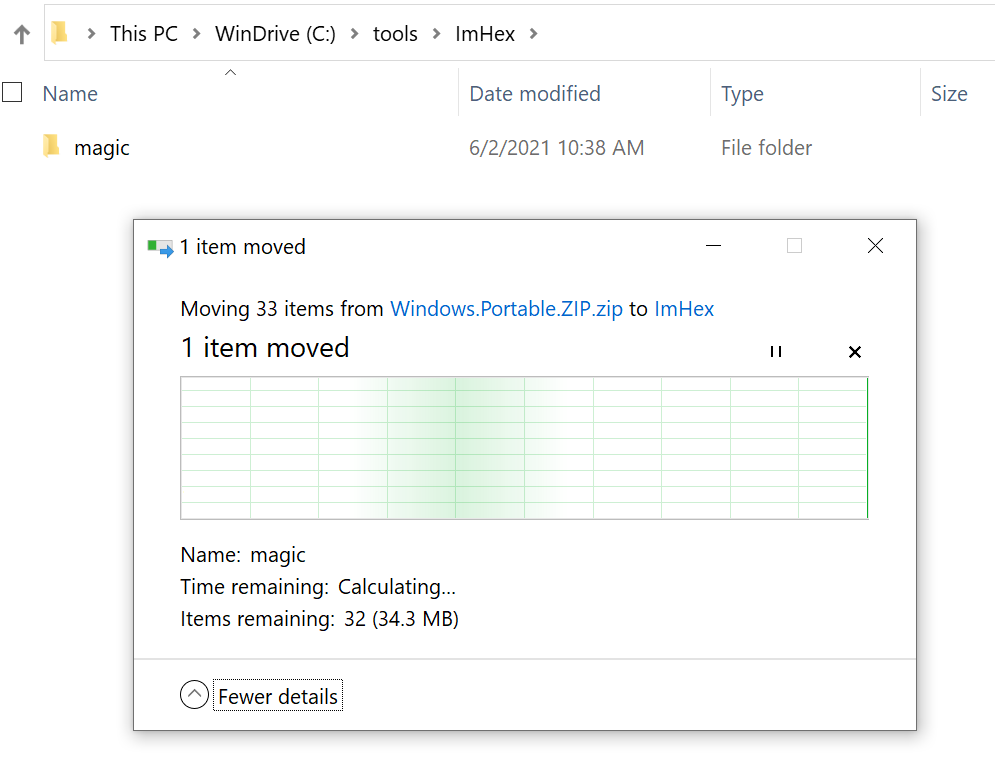
Чего? Я знал, что движок ZIP, который используется в ZIP Folders, не был оптимизирован, но раньше я никогда не видел ничего настолько плохого. Спустя ещё несколько минут распаковался ещё один файл на 6,5 МБ:
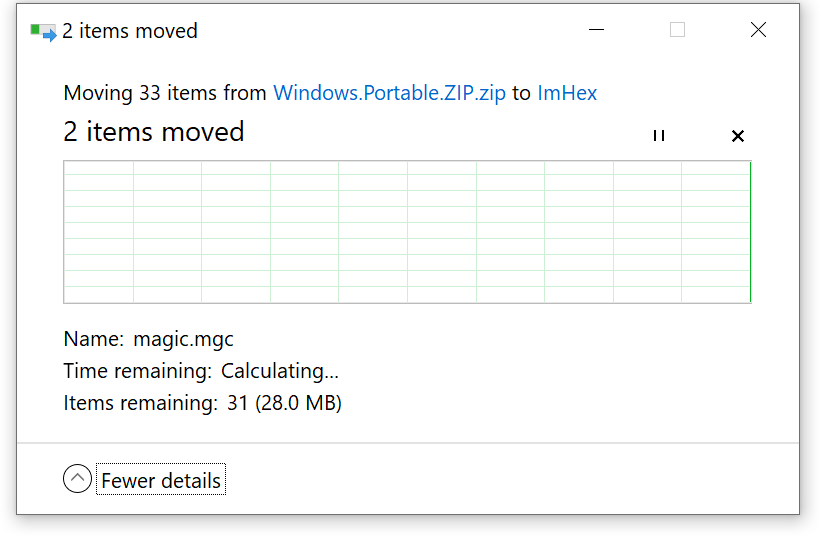
Безумие какое-то. Я открыл «Диспетчер задач», но никакие процессы не занимали мой 12-поточный процессор, 64 ГБ памяти и NVMe SSD. Наконец, я открыл SysInternals Process Monitor, чтобы разобраться, в чём дело, и вскоре увидел первоисточник происходящего.
После нескольких мелких операций считывания из конца файла (где у файла ZIP хранится индекс), весь файл размером 11 миллионов байт считывался с диска по одному байту за раз:
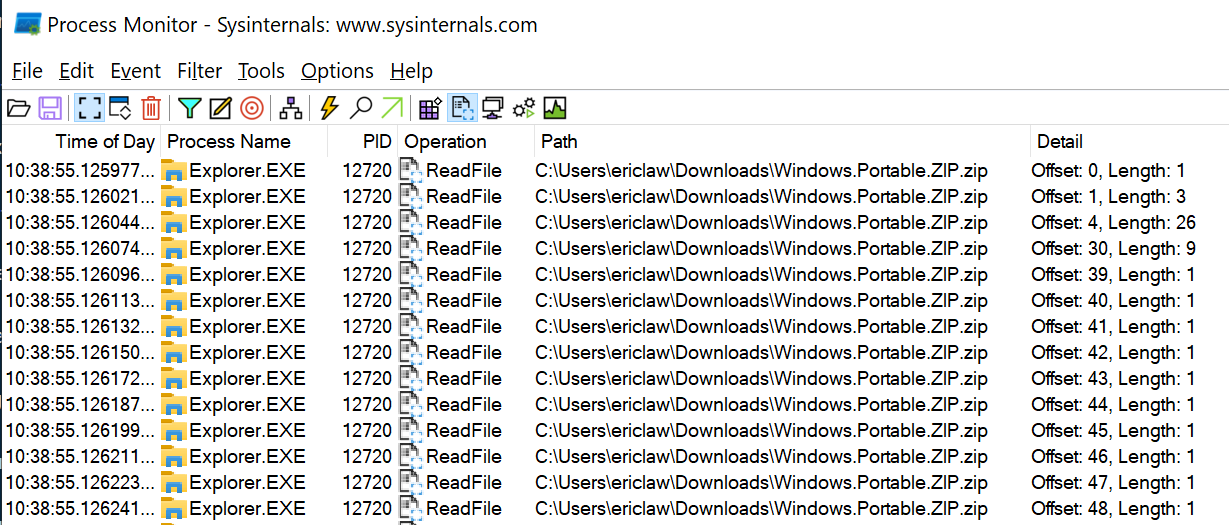
Присмотревшись повнимательнее, я понял, что почти все операции считывали по одному байту, но время от времени после считывания определённого байта выполнялось считывание 15 байт:

Что же находится в этих любопытных смещениях (
330, 337)? Байт 0x50, то есть буква P.
В прошлом мне доводилось писать тривиальный код для восстановления ZIP, поэтому я знал, в чём особенность символа
P в файлах ZIP — это первый байт маркеров блоков формата ZIP, каждый из которых начинается с 0x50 0x4B. По сути, код считывает файл от начала до конца в поисках конкретного блока размером 16 байт. Каждый раз, когда он встречает P, то просматривает следующие 15 байт, чтобы проверить, соответствуют ли они нужной сигнатуре, и если нет, то продолжает побайтовое сканирование в поисках новой P.Есть ли что-то особенное в этом конкретном файле ZIP? Да.
Формат ZIP состоит из последовательности записей файлов, за которой идёт список этих записей файлов («Central Directory»).
Каждая запись файла имеет собственный «локальный заголовок файла», содержащий информацию о файле, в том числе размер, размер в сжатом виде и CRC-32; те же данные повторяются в Central Directory.
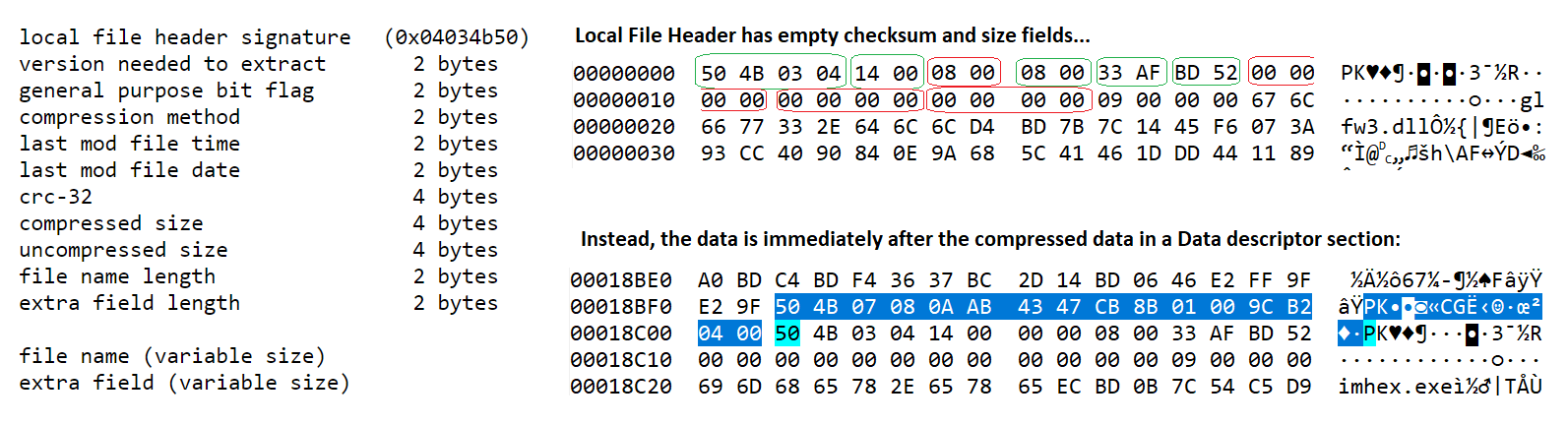
Однако формат ZIP позволяет локальным заголовкам файлов пропускать эти данные и записывать их как «хвост» после сжатых данных. Эта функция полезна при потоковом сжатии — мы не знаем окончательный размер в сжатом виде, пока не закончим сжимать данные. Вероятно, большинство файлов ZIP не используют эту функцию, однако в скачанном мной файле она использовалась. (Разработчик сообщил, что этот файл ZIP был создан GitHub CI.)
Мы видим, что в заголовке CRC и размеры равны 0, и что они появляются сразу после сигнатуры 0x08074b50 (дескриптора данных (Data Descriptor)), непосредственно перед локальным заголовком следующего файла:
Бит 0×08 во флаге
General Purpose обозначает эту опцию; пользователи 7-Zip могут увидеть её как Descriptor в столбце записи Characteristics: 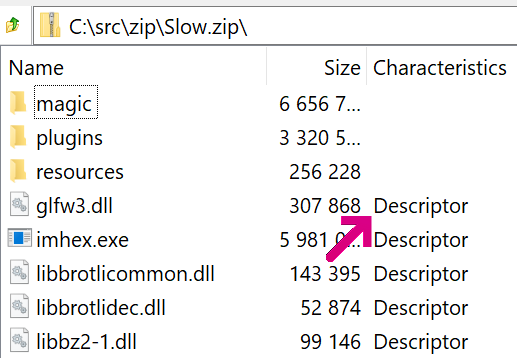
Исходя из размера операции считывания (
1+15 байт), я предполагаю, что код подстраивается под блоки Data Descriptor. Почему он это делает (вместо того, чтобы просто считать те же данные из Central Directory), я не знаю.Хуже того — этот черепаший процесс побайтового считывания всего файла происходит не только один раз — он повторяется по крайней мере по одному разу для каждого извлекаемого файла. Усугубляет ситуацию то, что эти данные считываются при помощи ReadFile, а не fread ().
В конечном итоге, после 85 миллионов однобайтных считываний монитор процессов зависает:

Перезапустив его и сконфигурировав Process Monitor с Symbols, мы можем исследовать эти однобайтные операции считывания и получить представление о том, что же происходит:
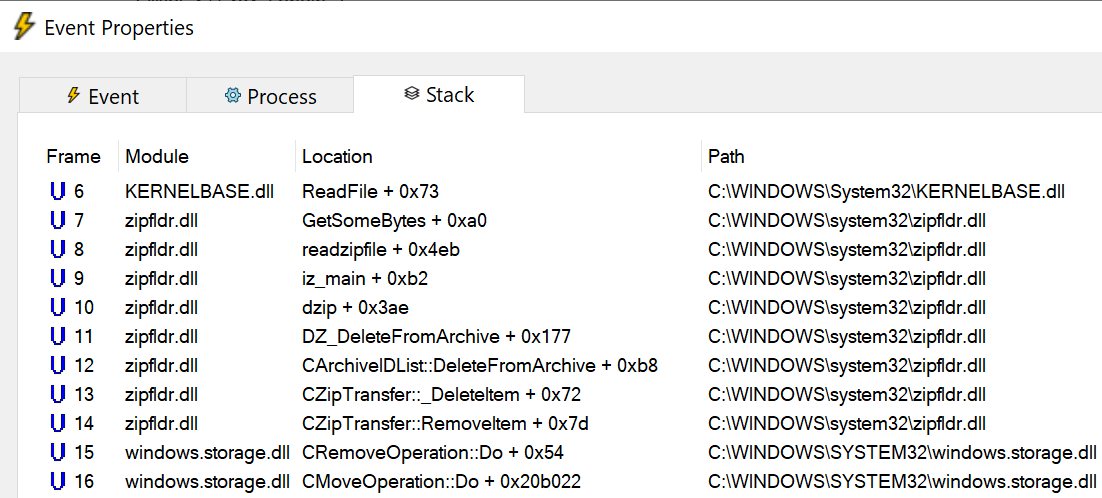
Функцию
GetSomeBytes перенагружают вызовы, передающие однобайтный буфер в коротком цикле внутри функции readzipfile. Но если посмотреть ниже по стеку, то становится очевидной первопричина этого хаоса — это происходит потому, что после перемещения каждого файла из ZIP в папку файл ZIP должен обновиться для удаления перемещённого файла. Этот процесс удаления по сути своей не быстр (поскольку он приводит к изменению всех последующих байтов и обновлению индекса), а его реализация в функции readzipfile (с этим однобайтным буфером чтения) и вовсе чудовищно медленна.Если вернуться назад, то стоит заметить, что я нажал CTRL+X, чтобы вырезать файлы, что привело к операции перемещения. Если бы вместо этого я нажал CTRL+C для копирования файлов, то ZIP не выполнял бы операцию удаления при извлечении каждого файла. Время, необходимое для распаковки файла ZIP снизилось бы с получаса до четырёх секунд. Для сравнения: 7-Zip распаковывает файл меньше чем за четверть секунды, хоть и немного жульничает.
И вот здесь и происходит протечка абстракции — с точки зрения пользователя, копирование файлов из ZIP (с последующим удалением ZIP) и перемещение файлов из ZIP не кажутся сильно различающимися операциями. К сожалению, абстракция даёт сбой — на самом деле, удаление из некоторых файлов ZIP оказывается чрезвычайно медленной операцией, а удаление файла с диска обычно происходит тривиально. Поэтому абстракция Compressed Folder хорошо работает с мелкими файлами ZIP, но даёт сбой с крупными файлами ZIP, которых в наше время становится всё больше.
Хотя довольно легко придумать способы значительного улучшения производительности в этой ситуации, подобный прецедент даёт понять, что вероятность совершенствования кода в Windows мала. Возможно, код изменят к его 25-й годовщине?
На правах рекламы
Если для работы необходим сервер на Windows, то вам однозначно к нам. Создавайте собственную конфигурацию в пару кликов, автоматическая установка винды на тарифах с 2 vCPU, 4 ГБ RAM, 20 ГБ NVMe или выше.
Присоединяйтесь к нашему чату в Telegram.

