Простая реализация небольших CAM на ПЛИС
Введение
Как-то раз мне потребовалось по работе реализовать небольшой блок ассоциативной памяти. Почитав, как это делается у Xilinx на BlockRAM (BRAM) или на SRL16, я несколько опечалился, так как их реализации занимали довольно много места. Решил попробовать сделать его самостоятельно. Первым вариантом стала реализация в лоб. Забегая вперед, она практически сходу мне и подошла, благо, целевая частота для дизайна была всего 125 МГц.
Архитектура
Для начала рассмотрим постановку задачи. Итак, нам требуется небольшой CAM с шириной слова 8–64 бит и глубиной 16–1024 слов. Поиск в CAM мне требовался бинарный, но позже оказалось, что сделать из него TCAM довольно дёшево по ресурсам и таймингу. Нижняя граница частоты — 125 МГц на семействе Kintex7. Начнем! Наш CAM будет набран из вот таких линеек, каждая из которых будет соответствовать одному адресу и хранить одно слово:
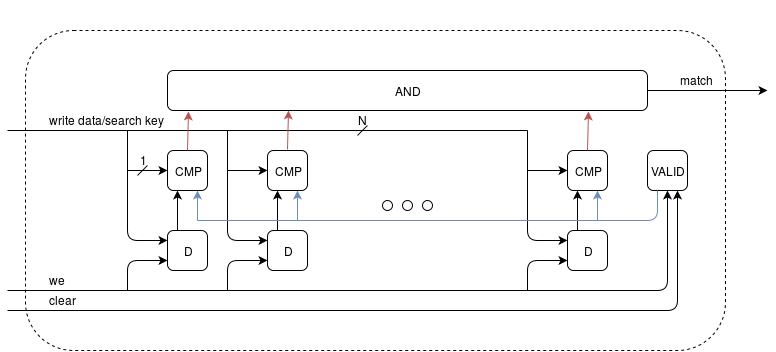
Рисунок 1. Структура одной линейки CAM
На рис. 1 D — обычный D-триггер для хранения данных, число этих триггеров в линейке соответствует ширине входного слова данных в CAM. VALID — D-триггер, в котором хранится '1' если данные в линейке актуальны. CMP — компаратор, который сравнивает значение соответствующего бита шины ключа поиска search key, если VALID = '1'. write data — шина данных на запись, побитово подключенная к соответствующим D (N — ширина слова CAM), we — флаг записи, clear — сброс VALID (инвалидация данных линейки). AND — логический AND от N выходов компараторов, match — флаг, переходящий в '1', если поиск в данной линейке успешен.
Итак, у нас есть одна линейка, в которой мы можем осуществлять поиск. Теперь объединим их:
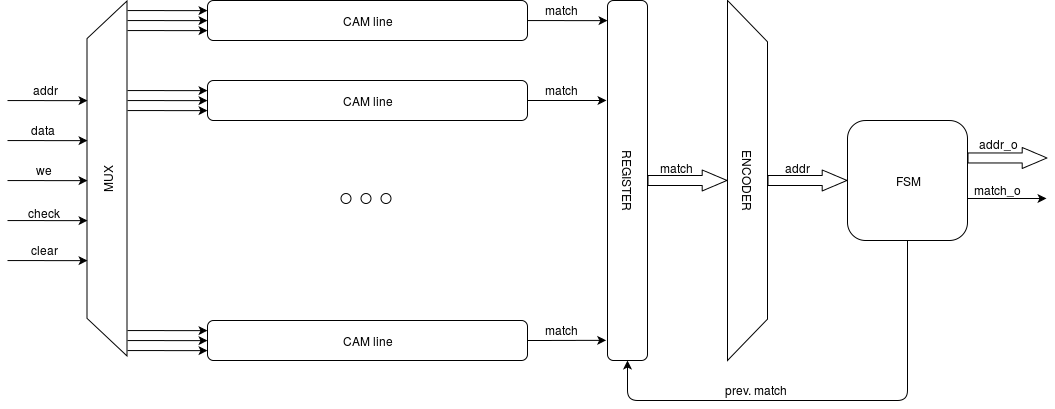
Рисунок 2. Структура CAM
На рис. 2 CAM_line — собственно линейки CAM с рис. 1, MUX — входной адресный мультиплексор, MATCH REGISTER — регистр, сохраняющий значения флагов совпадения match, ENCODER — дешифратор, преобразующий шину совпадений в младший из найденных адрес совпадений. FSM — управляющий конечный автомат, который по линии prev. match удаляет из MATCH REGISTER бит, соответствующий отправленному адресу, чтобы ENCODER переключился на следующий найденный адрес. Интерфейс нашего CAM будет следующим:
Таблица 1. Интерфейс CAM
Ниже на рис. 3 представлена временная диаграмма работы данного интерфейса, где показана сначала запись трёх слов в CAM, затем успешный поиск, стирание и снова поиск:

Рисунок 3. Временная диаграмма работы интерфейса к CAM
Итак, у нас есть описание CAM, давайте перейдём к синтезу.
Синтез
Синтезировать будем в Xilinx ISE, чтобы сравнить результаты с полученными в XAPP1151.
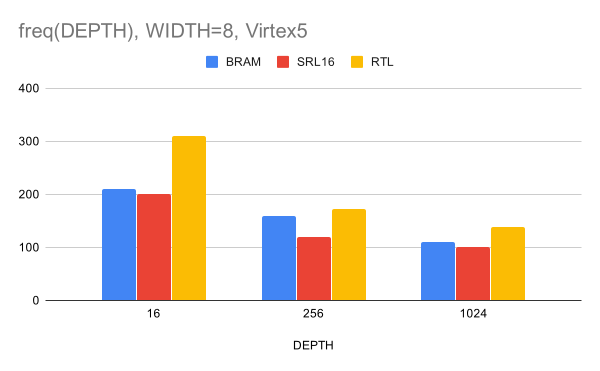
Рисунок 4. Зависимость частоты после XST от глубины CAM для ширины шины данных 8 бит
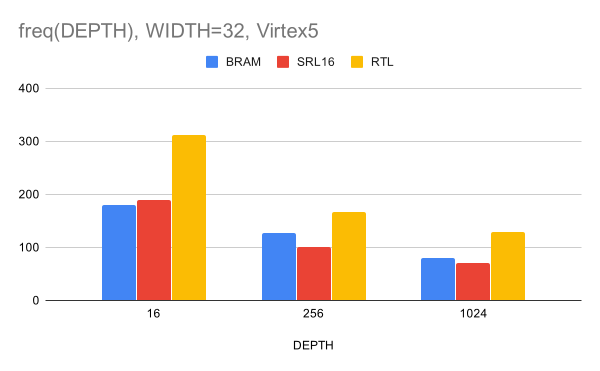
Рисунок 5. Зависимость частоты после XST от глубины CAM для ширины шины данных 32 бита
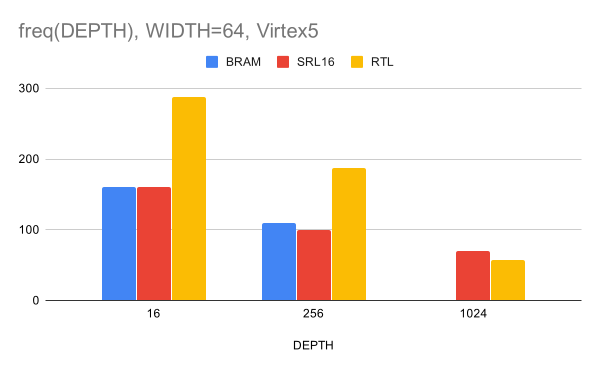
Рисунок 6. Зависимость частоты после XST от глубины CAM для ширины шины данных 64 бита
На на рис. 6 отсутствуют данные для Virtex5, так как CAM такого размера не влез в имеющиеся BRAM. Отметим также, что для ширины 64 бита и глубины 1024 наш результат оказался чуть хуже, чем у реализации на SRL16. Перейдём теперь к синтезу на Vivado для XC7K325T. Результаты получились следующие:
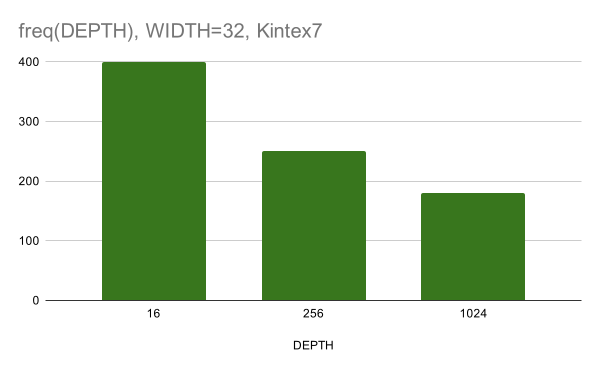
Рисунок 7. Зависимость частоты после PnR от глубины CAM для ширины шины данных 32 бита
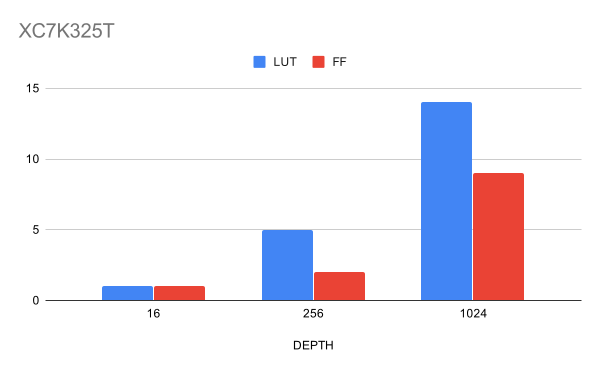
Рисунок 8. Утилизация ресурсов для различных глубин CAM для ширины данных 32 бита в %
Важно отметить, что результаты на Vivado были получены уже после PnR, а значит в дизайне нет сложностей с трассировкой.
TCAM
Как говорилось выше, получить при данном подходе из CAM TCAM особой проблемы не составило. Достаточно добавить шину маскирования битов data и раздать её побитно в компараторы, чтобы при сравнении данных с ключом они учитывали её значение. Такое изменение не привело к падению частоты или серьёзному росту потребляемых ресурсов, так что TCAM мы получили бесплатно.
Выводы
Итак, нам удалось выполнить поставленную задачу. Полученный дизайн позволяет на 7-м семействе ПЛИС Xilinx получать достаточно большие CAM с частотой выше целевых 125 МГц. Результат сравнения с XAPP1151 оказался для меня неожиданным, я предполагал, что реализация на BRAM, хоть и является очень дорогой с точки зрения ресурсов, обгонит лобовую реализацию по частоте. Однако не стоит праздновать победу так рано, в этом документе дано описание IP-ядра CAM от Xilinx, которое позволяет, например, получать CAM глубиной 32К ячеек и частотой 155 МГц, базируясь на BRAM. Такого результата наверное можно добиться и в предложенном в статье варианте, за счет добавления стадий конвейера, или набирая большой CAM из маленьких, но предсказать сходу, влезет ли это в чип я не могу. В дальнейшем попробую реализовать на BRAM нечто похожее, а пока спасибо за внимание.
