[Перевод] Обработка 40 ТБ кода из 10 млн проектов на выделенном сервере с Go за $100
Написанной мной инструмент командной строки Sloc Cloc and Code (scc), который теперь доработан и поддерживается многими отличными людьми, подсчитывает строки кода, комментарии и оценивает сложность файлов внутри каталога. Здесь нужна хорошая выборка. Инструмент подсчитывает в коде операторы ветвления. Но что такое сложность? Например, заявление «У этого файла сложность 10» не очень полезно без контекста. Чтобы решить эту проблему, я запустил scc на всех исходниках в интернете. Это также позволит найти какие-то крайние случаи, которые я не рассматривал в самом инструменте. Мощное испытание методом грубой силы.
Но если я собираюсь запустить тест на всех исходниках в мире, это потребует много вычислительных ресурсов, что тоже интересный опыт. Поэтому я решил всё записать — так и появилась эта статья.
Короче говоря, я загрузил и обработал много исходников.
Голые цифры:
- 9 985 051 репозиториев всего
- 9 100 083 репозитория хотя бы с одним файлом
- 884 968 пустых репозиториев (без файлов)
- 3 500 000 000 файлов во всех репозиториях
- Обработано 40 736 530 379 778 байт (40 ТБ)
- Идентифицировано 1 086 723 618 560 строк
- Распознано 816 822 273 469 строк с кодом
- 124 382 152 510 пустых строк
- 145 519 192 581 строк комментариев
- Общая сложность по правилам scc: 71 884 867 919
- 2 новые ошибки, найденные в scc
Давайте сразу отметим одну деталь. Здесь не 10 миллионов проектов, как указано в громком заголовке. Мне не хватило 15 000, так что я округлил. Прошу прощения за это.
Потребовалось около пяти недель, чтобы всё скачать, пройтись scc и сохранить все данные. Потом ещё чуть более 49 часов, чтобы обработать 1 ТБ JSON и получить результаты ниже.
Также обратите внимание, что я мог ошибиться в некоторых расчётах. Я оперативно сообщу, если обнаружится какая-то ошибка, и предоставлю датасет.
С момента запуска searchcode.com я уже накопил коллекцию из более 7 000 000 проектов на git, mercurial, subversion и так далее. Так почему бы не обработать их? Работа с git обычно является самым простым решением, поэтому на этот раз я проигнорировал mercurial и subversion и экспортировал полный список проектов git. Оказывается, у меня в реальности отслеживалось 12 миллионов репозиториев git, и наверное, нужно обновить главную страницу, чтобы отразить это.
Итак, теперь у меня 12 миллионов репозиториев git, которые нужно загрузить и обработать.
При запуске scc вы можете выбрать выдачу в JSON с сохранением файла на диск: scc --format json --output myfile.json main.go. Результаты выглядят следующим образом (для одного файла):
[
{
"Blank": 115,
"Bytes": 0,
"Code": 423,
"Comment": 30,
"Complexity": 40,
"Count": 1,
"Files": [
{
"Binary": false,
"Blank": 115,
"Bytes": 20396,
"Callback": null,
"Code": 423,
"Comment": 30,
"Complexity": 40,
"Content": null,
"Extension": "go",
"Filename": "main.go",
"Hash": null,
"Language": "Go",
"Lines": 568,
"Location": "main.go",
"PossibleLanguages": [
"Go"
],
"WeightedComplexity": 0
}
],
"Lines": 568,
"Name": "Go",
"WeightedComplexity": 0
}
]
В качестве более крупного примера см. результаты для проекта redis: redis.json. Все приведённые ниже результаты получены из такой выдачи без каких-либо дополнительных данных.
Следует иметь в виду, что scc обычно классифицирует языки на основе расширения (за исключением тех случаев, когда расширение является общим, например, Verilog и Coq). Таким образом, если сохранить HTML-файл с расширением java, он будет считаться файлом java. Обычно это не проблема, потому что зачем такое делать? Но, конечно, в большом масштабе проблема становится заметной. Это я обнаружил позже, когда некоторые файлы маскировались под другое расширение.
Какое-то время назад я написал код для генерации меток github на основе scc. Поскольку в процессе нужно было кэшировать результаты, я немного изменил его, чтобы кэшировать их в формате JSON на AWS S3.
С кодом для меток в AWS на lambda, я взял экспортированный список проектов, написал около 15 строк python, чтобы очистить формат для соответствия моей lambda, и сделал запрос к нему. С помощью мультипроцессинга python я распараллелил запросы на 32 процесса, чтобы конечная точка отзывалась достаточно быстро.
Всё сработало блестяще. Однако проблема заключалась, во-первых, в стоимости, а во-вторых, у lambda за API-Gateway/ALB есть 30-секундный таймаут, поэтому она не может достаточно быстро обрабатывать большие репозитории. Я знал, что это не самое экономичное решение, но думал, что цена составит около $100, с чем я бы смирился. После обработки миллиона репозиториев я проверил — и стоимость оказалась около $60. Поскольку меня не радовала перспектива итогового счёта AWS на $700, я решил пересмотреть своё решение. Имейте в виду, что это было в основном хранилище и CPU, которые использовались для сбора всей этой информации. Любая обработка и экспорт данных значительно увеличивала цену.
Поскольку я уже был на AWS, быстрым решением было бы сбросить URL-адреса как сообщения в SQS и вытащить оттуда, используя инстансы EC2 или Fargate для обработки. Затем масштабировать как сумасшедший. Но несмотря на повседневный опыт работы с AWS, я всегда верил в принципы программирования Taco Bell. Кроме того, там было всего 12 миллионов репозиториев, поэтому я решил реализовать более простое (дешёвое) решение.
Запуск вычисления локально был невозможен из-за ужасного интернета в Австралии. Однако мой searchcode.com работает, достаточно бережливо используя выделенные серверы от Hetzner. Это довольно мощные машины i7 Quad Core 32 GB RAM, часто с 2 ТБ дискового пространства (обычно не используется). У них обычно есть хороший запас вычислительной мощности. Например, фронтенд-сервер большую часть времени вычисляет квадратный корень из нуля. Так почему бы не запустить обработку там?
Это не совсем программирование Taco Bell, поскольку я применил инструменты bash и gnu. Я написал простую программу на Go, чтобы запустить 32 go-рутины, которые считывают данные с канала, порождают подпроцессы git и scc перед записью выдачи на JSON в S3. Я на самом деле сначала написал решение на Python, но необходимость устанавливать зависимости pip на моём чистом сервере казалась плохой идеей, и система ломалась странными способами, которые мне не хотелось отлаживать.
Запуск всего этого на сервере выдал следующие метрики в htop, а несколько запущенных процессов git/scc (scc не отображается на этом скриншоте) предполагали, что всё работает как положено, что и подтвердилось результатами в S3.

Недавно я прочитал этистатьи, поэтому у меня родилась идея позаимствовать формат этих постов в отношении подачи информации. Правда, я ещё хотел добавить jQuery DataTables к большим таблицам, чтобы сортировать и искать/фильтровать результаты. Таким образом, в оригинальной статье вы можете щёлкнуть по заголовкам для сортировки и использовать поле поиска для фильтрации.
Размер данных, которые нужно было обработать, поднял ещё один вопрос. Как обработать 10 миллионов файлов JSON, занимающих чуть более 1 ТБ дискового пространства в бакете S3?
Первой мыслью была AWS Athena. Но поскольку это будет стоить что-то вроде $2,50 за запрос к такому набору данных, я быстро начал искать альтернативу. Тем не менее, если вы сохраните данные там и редко их обрабатываете, это может оказаться самым дешёвым решением.
Я опубликовал вопрос в корпоративном чате (зачем решать проблемы в одиночку).
Одна из идей заключалась в том, чтобы сбросить данные в большую базу данных SQL. Однако это означает обработку данных в БД, а затем выполнение запросов по ней несколько раз. Плюс структура данных означает несколько таблиц, что означает внешние ключи и индексы для обеспечения определённого уровня производительности. Это кажется расточительным, потому что мы могли бы просто обрабатывать данные, как мы читаем их с диска — в один проход. Я также беспокоился о создании такой большой БД. Только с данными это будет более 1 ТБ в размере перед добавлением индексов.
Видя, как я создавал JSON простым способом, я подумал, почему бы не обработать результаты таким же образом? Конечно, есть одна проблема. Вытягивание 1 ТБ данных из S3 будет много стоить. В случае сбоя программы это будет раздражать. Чтобы снизить затраты, я хотел вытащить все файлы локально и сохранить их для дальнейшей обработки. Полезный совет: лучше не хранить много маленьких файлов в одном каталоге. Это отстой для производительности во время выполнения, и файловым системам такое не нравится.
Моим ответом на это была ещё одна простая программа на Go, чтобы вытащить файлы из S3, а затем сохранить их в файле tar. Затем я мог бы обрабатывать этот файл снова и снова. Сам процесс выполняет очень уродливая программа на Go для обработки файла tar, чтобы я мог повторно запускать запросы без необходимости вытягивать данные из S3 снова и снова. Я здесь не возился с go-рутинами по двум причинам. Во-первых, я не хотел максимально загружать сервер, поэтому ограничился одним ядром для тяжёлой работы CPU (другое для чтения файла tar было в основном заблокировано на процессоре). Во-вторых, я хотел гарантировать потокобезопасность.
Когда это было сделано, нужен был набор вопросов для ответа. Я снова использовал коллективный разум и подключил коллег, пока придумывал собственные идеи. Результат этого слияния разумов представлен ниже.
Вы можете найти весь код, который я использовал для обработки JSON, включая код для локальной обработки, и уродливый скрипт Python, который я использовал, чтобы подготовить что-то полезное для этой статьи: пожалуйста, не комментируйте его, я знаю, что код уродлив, и он написан для одноразовой задачи, поскольку я вряд ли когда-нибудь посмотрю на него снова.
Если хотите просмотреть код, который я написал для всеобщего использования, посмотрите на исходники scc.
Я потратил около $60 на вычисления при попытке работать с lambda. Я еще не смотрел на стоимость хранения S3, но она должна быть близка к $25, в зависимости от размера данных. Однако это не включает в себя расходы на передачу, которые я тоже не смотрел. Пожалуйста, обратите внимание, что я очистил бакет, когда закончил с ним, так что это не постоянные расходы.
Но через некоторое время я всё-таки отказался от AWS. Итак, какова реальная стоимость, если бы я захотел сделать это снова?
Всё программное обеспечение у нас свободное и бесплатное. Так что беспокоиться не о чем.
В моём случае стоимость была бы нулевой, поскольку я использовал «бесплатные» вычислительные мощности, оставшийся от searchcode.com. Однако не у каждого есть такие свободные ресурсы. Поэтому давайте предположим, что другой человек хочет повторить это и должен поднять сервер.
Это можно сделать за €73, используя самый дешёвый новый выделенный сервер от Hetzner, включая плату за установку нового сервера. Если подождать и покопаться в разделе с аукционами, вы можете найти гораздо более дешёвые серверы без платы за установку. На момент написания статьи я нашёл машину, которая идеально подходит для этого проекта, за €25,21 в месяц без платы за установку.
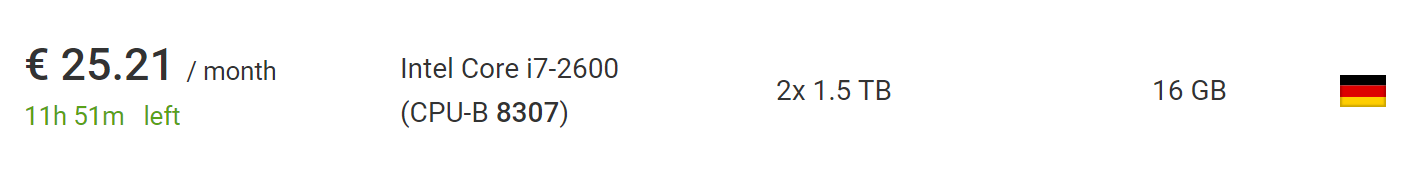
Что ещё лучше, за пределами Евросоюза с этой цены уберут НДС (VAT), так что смело отнимайте ещё 10%.
Поэтому если поднимать такой сервис с нуля на моём софте, это в итоге будет стоить до $100, а скорее до $50, если вы немного терпеливы или удачливы. Это предполагает, что вы используете сервер менее двух месяцев, чего вполне достаточно для загрузки и обработки. Тут также достаточно времени для получения списка из 10 миллионов репозиториев.
Если бы я использовал зазипованный tar (что на самом деле не так уж сложно), то мог бы обработать в 10 раз больше репозиториев на той же машине, а результирующий файл всё равно останется достаточно маленьким, чтобы поместиться на том же HDD. Хотя процесс может занять несколько месяцев, потому что загрузка займёт больше времени.
Чтобы выйти далеко за пределы 100 миллионов репозиториев, однако, потребуется какой-то шардинг. Тем не менее, можно с уверенностью сказать, что вы повторите процесс в моём масштабе или гораздо более крупном, на том же оборудовании без особых усилий или изменений кода.
Вот сколько проектов поступило от каждого из трёх источников: github, bitbucket и gitlab. Обратите внимание, что это до исключения пустых репозиториев, следовательно, сумма превышает количество репозиториев, которые фактически обработаны и учтены в последующих таблицах.
Приношу прощения сотрудникам GitHub/Bitbucket/GitLab, если вы это читаете. Если мой скрипт вызвало какие-то проблемы (хотя сомневаюсь), с меня при встрече напиток на ваш выбор.
Перейдём к реальным вопросам. Начнём с простого. Сколько файлов находится в среднем репозитории? У большинства проектов всего пару файлов или побольше? После циклического перебора репозиториев получаем такой график:

Здесь по оси X отложены бакеты с количеством файлов, а по Y — количество проектов с таким количеством файлов. Ограничим горизонтальную ось тысячей файлов, потому что дальше график слишком близко к оси.
Кажется, будто в большинстве репозиториев меньше 200 файлов.
Но что насчёт визуализации до 95-го процентиля, которая покажет реальную картину? Оказывается, в подавляющем большинстве (95%) проектов — меньше 1000 файлов. В то время как 90% проектов имеют менее 300 файлов и 85% — менее 200.

Если хотите построить график самостоятельно и сделать это получше меня, вот ссылка на необработанные данные в JSON.
Например, если идентифицируется файл Java, то увеличиваем количество Java в проектах на один, а для второго файла ничего не делаем. Это даёт быстрое представление о том, какие языки наиболее часто используются. Неудивительно, что наиболее распространённые языки включают markdown, .gitignore и plaintext.
Markdown — наиболее часто используемый язык в замечен более чем в 6 миллионах проектов, что составляет около 2⁄3 от общего количества. Это имеет смысл, так как почти все проекты включают README.md который отображается в HTML для страниц репозитория.
Дополнение к предыдущей таблице, но усреднённое по количеству файлов на каждый язык в репозитории. То есть сколько файлов Java существует в среднем для всех проектов, где есть Java?
Полагаю, ещё интересно посмотреть, на каких языках в среднем самые большие файлы? Использование среднего арифметического порождает аномально высокие числа из-за проектов вроде sqlite.c, который включён во многие репозитории, объединяя много файлов в один, но никто никогда не работает над этим одним большим файлом (я надеюсь!)
Поэтому я считал среднее по медиане. Тем не менее, всё равно остались языки с абсурдно высокими значениями, такие как Bosque и JavaScript.
Так что я подумал, почему бы не сделать ход конём? По предложению Даррела (резидент Kablamo и превосходный учёный по данным) я сделал одно небольшое изменение и изменил среднее арифметическое, отбросив файлы более 5000 строк, чтобы удалить аномалии.
Какова средняя сложность файла для каждого языка?
На самом деле оценку сложности нельзя сопоставлять напрямую между языками. Выдержка из readme самого scc:
Оценка сложности — это лишь число, которое можно сопоставлять только между файлами на одном языке. Её не следует использовать для сравнения языков напрямую. Причина в том, что она вычисляется поиском операторов ветвления и цикла для каждого файла.
Таким образом, здесь нельзя сравнивать языки друг с другом, хотя это можно сделать между аналогичными языками, такими как Java и C, например.
Это более ценная метрика для отдельных файлов на том же языке. Таким образом, вы можете ответить на вопрос «Этот файл, с которым я работаю, проще или сложнее среднего?»
Должен упомянуть, что я буду рад предложениям по улучшению этой метрики в scc. Для коммита обычно достаточно добавить всего несколько ключевых слов в файл languages.json, так что помощь может оказать программист любой квалификации.
Каково среднее количество комментариев в файлах на каждом языке?
Вероятно, вопрос можно перефразировать: разработчики на каком языке пишут больше всего комментариев, предполагая непонимание читателя.
Какие имена файлов наиболее распространены во всех кодовых базах, игнорируя расширение и регистр?
Если бы вы спросили меня раньше, я бы сказал: README, main, index, license. Результаты довольно хорошо отражают мои предположения. Хотя там есть много интересного. Понятия не имею, почему так много проектов содержат файл под названием 15 или s15.
Самый распространённый файл makefile немного удивил меня, но потом я вспомнил, что он используется во многих новых проектах JavaScript. Ещё одна интересная вещь, которую следует отметить: похоже, jQuery по-прежнему на коне, и сообщения о его смерти сильно преувеличены, причём он на четвёртом месте в списке.
Обратите внимание, что из-за ограничений памяти я сделал этот процесс чуть менее точным. Через каждые 100 проектов я проверял карту и удалял из списка имена файлов, которые встречались менее 10 раз. Они могли вернуться к следующей проверке, и если встречались более 10 раз, то оставались в списке. Возможно, некоторые результаты имеют некоторую погрешность, если какое-то общее имя редко появлялось в первой партии репозиториев, прежде чем стать общим. Короче говоря, это не абсолютные числа, но должны быть достаточно близки к ним.
Я мог бы использовать префиксное дерево, чтобы «сжать» пространство и получить абсолютные числа, но мне не хотелось его писать, так что я слегка злоупотребил map, чтобы сэкономить достаточно памяти и получить результат. Однако довольно любопытно будет позже попробовать префиксное дерево.
Это очень интересно. У какого количества репозиториев есть хоть какой-нибудь явный файл лицензии? Обратите внимание, что отсутствие файла лицензии здесь не означает, что у проекта его нет, поскольку он может существовать в файле README или указываться через теги комментариев SPDX в строках. Это просто означает, что scc не смог найти явный файл лицензии, используя свои собственные критерии. На данный момент такими файлами считаются файлы «license», «licence», «copying», «copying3», «unlicense», «unlicence», «license-mit», «licence-mit» или «copyright».
К сожалению, у подавляющего большинства репозиториев нет лицензии. Я бы сказал, что есть много причин, почему любому ПО нужна лицензия, но вот кто-то другой сказал это за меня.

Некоторые могут не знать этого, но в проекте git может быть несколько файлов .gitignore. С учётом этого сколько проектов используют несколько файлов .gitignore? А заодно, у скольких нет ни одного?
Я нашёл довольно интересный проект с 25 794 файлами .gitignore в репозитории. Следующим результатом было 2547. Понятия не имею, что там происходит. Я мельком взглянул: похоже, что они используются для проверки каталогов, но не могу это подтвердить.
Возвращая к данным, вот график репозиториев с числом файлов .gitignore до 20 штук, который покрывает 99% всех проектов.

Как и ожидалось, у большинства проектов 0 или 1 файлов .gitignore. Это подтверждается массивным десятикратным падением числа проектов, у которых количество файлов 2. Что меня удивило, так это то, как много проектов имеют больше, чем один файл .gitignore. Длинный хвост в этом случае особенно длинный.
Мне стало любопытно, почему у некоторых проектов тысячи таких файлов. Один из главных нарушителей спокойствия — форки https://github.com/PhantomX/slackbuilds: у каждого из них около 2547 файла .gitignore. Ниже перечислены другие репозитории с числом файлов .gitignore более тысячи.
Этот раздел — не точная наука, а относится к классу проблем обработки естественного языка. Поиск в именах файлов ругательств или оскорбительных терминов по определённому списку никогда не будет эффективным. Если искать простым поиском, то вы найдёте много обычных файлов вроде assemble.sh и так далее. Поэтому я взял список ругательств, а затем проверил, начинаются ли какие-либо файлы в каждом проекте с одним из этих значений, за которым следует точка. Это означает, что файл под названием gangbang.java будет учтён, а assemble.sh — нет. Однако он пропустит много разнообразных вариантов, таких как pu55syg4rgle.java и другие такие же грубые названия.
Мой список содержит некоторые слова на leetspeak, такие как b00bs и b1tch, чтобы поймать некоторые из интересных случаев. Полный список здесь.
Хотя это не совсем точно, как уже упоминалось, но невероятно интересно посмотреть на результат. Давайте начнём со списка языков, в которых больше всего ругательств. Вероятно, следует соотнести результат с общим количеством кода на каждом языке. Итак, вот лидеры.
Интересно! Моя первая мысль была: «Ох уж эти озорные разработчики на С!» Но несмотря на большое количество таких файлов, они пишут так много кода, что процент ругательств теряется в общем количестве. Однако довольно ясно, что у разработчиков Dart есть в арсенале пару словечек! Если знаете кого-то из программистов на Dart, можете пожать ему руку.
Также хочется узнать, какие наиболее часто используемые ругательства. Давайте посмотрим на общий грязный коллективный ум. Некоторые из лучших, которые я нашёл, были нормальными именами (если прищуриться), но большинство остальных, безусловно, вызовет удивление у коллег и несколько комментариев в пул-реквестах.
Обратите внимание, что некоторые из более оскорбительных слов в списке действительно имели соответствующие имена файлов, что я нахожу довольно шокирующим. К счастью, они не очень распространены и не вошли в список выше, который ограничен файлами с количеством более 100. Надеюсь, что эти файлы существуют только для тестирования списков разрешить/запретить и тому подобное.
Как и ожидалось, верхние позиции занимают plaintext, SQL, XML, JSON и CSV: они обычно содержат метаданные, дампы БД и тому подобное.
Примечание. Некоторые из приведённых ниже ссылок могут не сработать из-за некоторой лишней информации при создании файлов. Большинство должно работать, но для некоторых может потребоваться чуть подредактировать URL-адрес.
Ещё раз, эти значения не сопоставимы напрямую друг с другом, но интересно посмотреть, что считается самым сложным в каждом языке.
Некоторые из этих файлов — абсолютные монстры. Например, рассмотрим самый сложный файл на C++, который я нашел: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp: это 28,3 мегабайт компиляторского ада (и, к счастью, кажется, он сгенерирован автоматически).
Примечание. Некоторые из приведённых ниже ссылок могут не сработать из-за некоторой лишней информации при создании файлов. Большинство должно работать, но для некоторых может потребоваться чуть подредактировать URL-адрес.
Звучит хорошо в теории, но на деле… что-то минифицированное или без разбиения на строки искажает результаты, делая их бессмысленными. Поэтому не публикую результаты вычислений. Однако я создал тикет в scc для поддержки детекта минификации, чтобы удалять его из результатов вычислений.
Вероятно, можно сделать какие-то выводы на основе имеющихся данных, но хочется, чтобы выгоду от этой функции получили все пользователи scc.
Понятия не имею, какую ценную информацию вы можете извлечь из этого, но интересно посмотреть.
Примечание. Некоторые из приведённых ниже ссылок могут не сработать из-за некоторой лишней информации при создании файлов. Большинство должно работать, но для некоторых может потребоваться чуть подредактировать URL-адрес.
Под «чистыми» имеются в виды проекты чисто на одном языке. Конечно, это не очень интересно само по себе, поэтому посмотрим на них в контексте. Как оказалось, у подавляющего большинства проектов менее 25 языков, а у большинства менее десяти.
Пик на графике внизу приходится на четыре языка.
Разумеется, в чистых проектах может быть только один язык программирования, но есть поддержка других форматов, таких как markdown, json, yml, css, .gitignore, которые учитывает scc. Наверное, разумно предположить, что любой проект с менее чем пятью языками, является «чистым» (для некоторого уровня чистоты), и это чуть более половины общего датасета. Конечно, ваше определение чистоты может отличаться от моего, поэтому можете ориентироваться на любое число, которое вам нравится.
Что меня удивляет, так это странный всплеск вокруг 34–35 языков. У меня нет разумного объяснения, откуда он взялся, и это, вероятно, достойно отдельного расследования.

Ах, современный мир TypeScript. Но для проектов TypeScript, сколько из них чисто на этом языке?
Должен признаться, я немного удивлён этим числом. Хотя я понимаю, что смешивание JavaScript с TypeScript довольно распространено, я бы подумал, что будет больше проектов на новомодном языке. Но вполне возможно, что более свежий набор репозиториев резко увеличит их число.
У меня такое чувство, что некоторых разработчиков TypeScript тошнит при одной мысли об этом. Если это им поможет, то могу предположить, что большинство этих проектов — программы вроде scc с примерами всех языков для целей тестирования.
Учитывая, что вы можете либо выгрузить все нужные файлы в один каталог, либо составить систему каталогов, какова типичная длина пути и количество каталогов?
Для этого подсчитываем количество слэшей в пути для каждого файла и усредняем. Я не знал, чего ожидать здесь, кроме того, что Java может быть вверху списка, поскольку там обычно длинные пути к файлам.
Когда-то в компании Slack была «дискуссия» — использовать .yaml or .yml. Многие там полегли с обеих сторон.
Дебаты могут наконец (?) закончиться. Хотя я подозреваю, что некоторые всё равно предпочтут умереть в споре.
Какой регистр используется для имён файлов? Поскольку есть ещё расширение, то можно ожидать, в основном, смешанный случай.
Что, конечно, не очень интересно, потому что обычно расширения файлов находятся в нижнем регистре. Что если проигнорировать расширения?
Не то, что я ожидал. Опять, в основном, смешанный, но я бы подумал, что нижний будет более популярным.
Ещё одна идея, которая появилась у коллег при просмотре какого-то старого кода Java. Я подумал, почему бы не добавить проверку для любого Java-кода, где в названии встречается Factory, FactoryFactory или FactoryFactoryFactory. Идея в том, чтобы оценить количество таких фабрик.
Итак, чуть более 2% кода Java оказалось factory или factoryfactory. К счастью, factoryfactoryfactory не нашлось. Возможно, эта шутка наконец умрёт, хотя я уверен, что по крайней мере одна нешуточная рекурсивная мультифабрика третьего уровня до сих пор работает где-то в каком-то монолите Java 5, и каждый день зарабатывает больше денег, чем я увижу за всю свою карьеру.
Идею файлов .ignore разработали burntsushi и ggreer в обсуждении на Hacker News. Возможно, это один из лучших примеров «конкурирующих» опенсорс-инструментов, работающих вместе с хорошим результатом и выполненных в рекордные сроки. Он стал стандартом де-факто для добавления кода, который инструменты будут игнорировать. scc тоже выполняет правило .ignore, однако также умеет их считать. Давайте посмотрим, насколько хорошо распространилась идея.
Люблю делать некоторый анализ на будущее. Было бы неплохо ещё просканировать такие вещи как ключи AWS AKIA и тому подобное. Я бы также хотел расширить покрытие проектов Bitbucket и Gitlab с анализом по каждому, чтобы посмотреть, может, там зависают группы разработчиков из разных областей.
Если я когда-то повторю проект, то хотел бы преодолеть следующие недостатки и учесть следующие идеи.
- Правильно сохранять URL где-то в метаданных. Использовать для его хранения имя файла было плохой идеей, поскольку теряется информация и может быть трудно определить источник и расположение файла.
- Не заморачиваться с S3. Мало смысла платить за трафик, если я использую его только для хранения. Лучше было с самого начала забить всё в файл tar.
- Потратить время на изучение некоторых инструментов, которые помогут с построением графиков и диаграмм.
- Использовать префиксное дерево или какой-nо другой тип данных, чтобы точно посчитать количество названий файлов, а не с небольшой погрешностью, как сейчас.
- Добавить опцию в scc, чтобы проверять тип файла по ключевым словам в качестве примеров, потому что иначе возможны ошибки. Например, этот файл CIDE.C был определён как файл C, хотя по содержимому очевидно, что это HTML. Для справедливости все счётчики работали одинаково.
- Кажется, есть ошибка в scc, когда название файла считается его расширением, если у него нет расширения, а название совпадает с расширением в списке. Для этого зарегистрирован тикет.
- Я хотел бы добавить в scc обнаружение шебангов.
- Было бы неплохо как-то учитывать количество звёзд на Github и количество коммитов.
- Хочу как-нибудь добавить расчёт индекса ремонтопригодности. Было бы очень здорово посмотреть, какие проекты считаются наиболее ремонтопригодными в зависимости от их размера.
Ну, я могу взять часть этой информации и использовать её в своём поисковике searchcode.com и программе scc. Хотя бы некоторые полезные точки данных. Изначально проект затевался во многом ради этого. К тому же очень полезно сравнить свой проект с другими. Кроме того, это был интересный способ провести несколько дней, решая некоторые интересные проблемы. И хорошая проверка на надёжность для scc.
Кроме того, я сейчас работаю над инструментом, который помогает ведущим разработчикам или менеджерам анализировать код, искать определённые языки, большие файлы, недостатки и т. д… с предположением, что нужно проанализировать несколько репозиториев. Вы вводите какой-то код, а инструмент говорит, насколько он ремонтопригоден и какие навыки нужны для его обслуживания. Это полезно при решении вопроса, покупать ли какую-то базу кода, обслуживать ли её, или получить понятие о своём собственном продукте, который выдаёт команда разработчиков. Теоретически это должно помочь командам масштабироваться за счёт общих ресурсов. Что-то вроде AWS Macie, но для кода — примерно над этим я работаю. Это мне и самому нужно для повседневной работы, и я подозреваю, что другие могут найти применение такому инструменту, по крайней мере, такова теория.
Наверное, стоило бы поставить тут какую-то форму регистрации для заинтересованных…
Если кто-то хочет сделать собственный анализ и внести исправления, вот ссылка на обработанные файлы (20 МБ). Если кто-то хочет разместить raw-файлы в открытом доступе, дайте знать. Это 83 ГБ tar.gz, а внутри чуть более 1 ТБ. Содержимое состоит из чуть более 9 миллионов файлов JSON различных размеров.
UPD. Несколько добрых душ предложили разместить файл, места указаны ниже:
По хостингу этого файла tar.gz спасибо CNCF за сервер для xet7 из проекта Wekan.
