Промышленный мониторинг качества данных в Feature Store. Предпосылки и реализация
Привет, Хабр! Меня зовут Алексей Лямзин, я работаю аналитиком в финтех направлении Big Data МТС. Мы с коллегами разрабатываем предиктивные модели на данных крупнейшего телеком-оператора и сегодня я расскажу вам о том, как мы строили автоматизированный контроль за качеством данных в нашем Feature Store.
Что такое Feature Store, почему в нем возникла потребность и какое место занимает мониторинг качества данных в нашей работе?
С развитием нашей компании в нее приходят новые аналитики, инженеры, дата-сайентисты, создаются новые продуктовые команды. Все они хотят строить новые признаки, гонять эксперименты и ставить в продакшн новые модели. На первый взгляд кажется, что ничего не предвещает беды в таких ситуациях. Но если ничего не менять в традиционном подходе к менеджменту данных, это приведет к тому, что скейлится будет все труднее и труднее.

Думаю, что людям, работающим с данными в распределенном стеке, эта боль знакома довольно хорошо. Посмотрим, как выглядит традиционная схема работы с данными:

У нас есть дата-инженеры, которые преобразуют источники данных в широкие витрины с признаками. Есть дата-сайентисты, которые на основе этих источников строят новые признаки для экспериментов, сохраняя их в песочнице. Затем все это в каком-то виде поступает на вход ML-моделям.
У этой схемы есть очевидные минусы:
Во-первых, разные продуктовые команды могут (сами того не подозревая) строить одни и те же признаки, гонять одни и те же эксперименты. Кстати, часто эксперименты еще и неудачные. Это приводит к нерациональному использованию рабочих рук, а потом все эти одинаковые таблицы лежат на кластере мертвым грузом.
Во-вторых, доступ к данным в Hadoop медленный, это может стать критическим для процессов, чувствительных ко времени отклика. Например, для highload онлайн-процессов. И это еще больше усугубляет первую проблему, так как доступ к историческим данным и сбор датасетов занимает довольно длительное время.
В-третьих, в этом подходе отсутствует централизованный мониторинг качества данных. Даже если мониторинг в каком-то виде есть на широких витринах — он может сильно отличаться по составу и качеству. Что уж говорить о пользовательских песочницах.
Справиться с этим хаосом в разработке помогает организация отдельного слоя управления данными, который будет осуществлять их централизованный менеджмент. Он называется Feature Store. Обычно в нем есть такие компоненты:
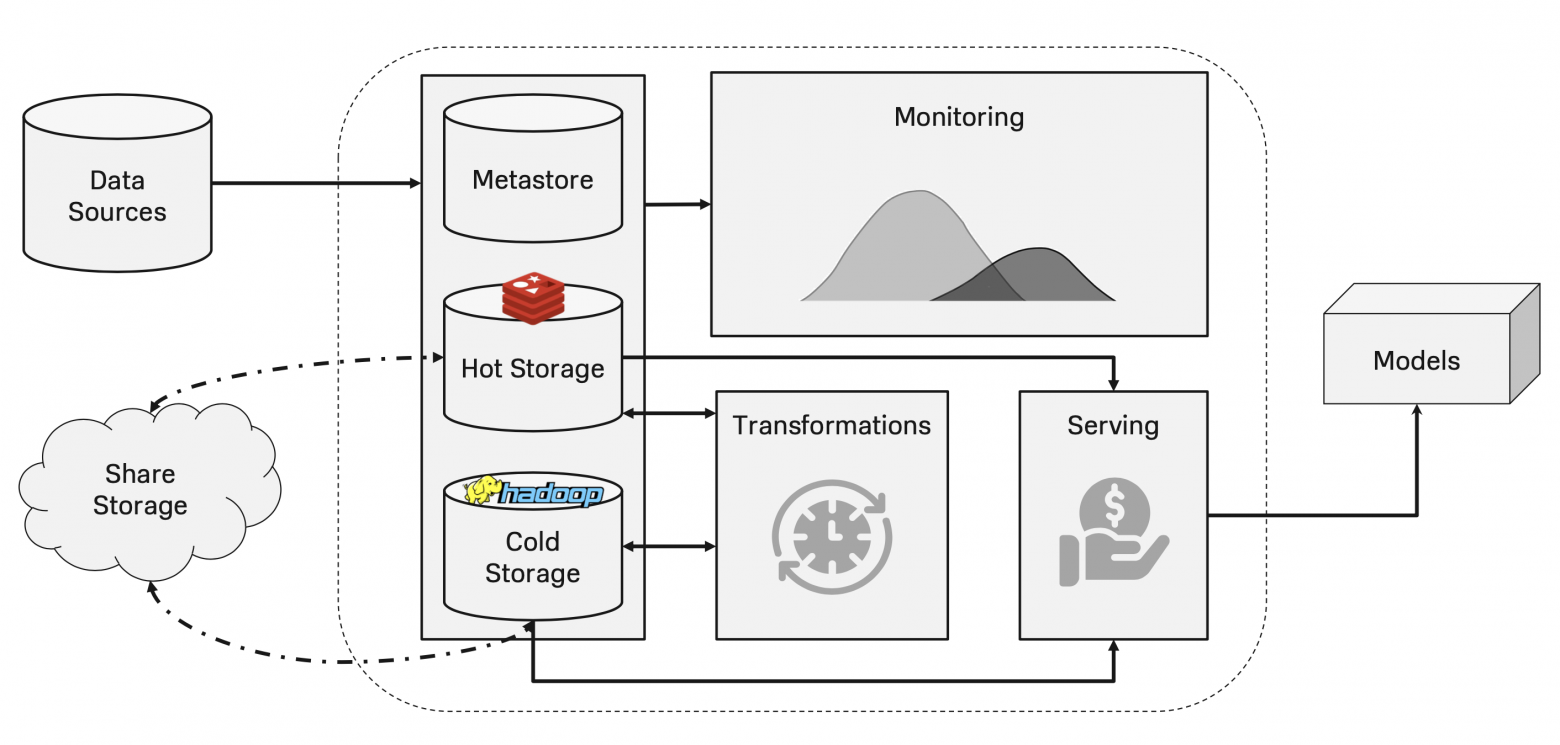 Feature Store
Feature Store
Хранилище данных, состоящее из Cold и Hot Storage:
Холодное (или оффлайн) хранилище используется, например, для доступа к историческим данным при обучении моделей или для обслуживания процессов с небольшой нагрузкой.
Горячее (или онлайн) хранилище реализовано в виде kv-базы данных и предоставляет быстрый доступ к вектору признаков для конкретного объекта. Используется для обслуживания процессов с высокой нагрузкой.
Над Cold и Hot Storage поднимается метастор, хранящий всю необходимую информацию о признаках. Например, какой у данного признака тип, в каких моделях он используется и другую метаинформацию.
С помощью трансформаций из более или менее детальных данных мы можем получать множество производных признаков, агрегируя их с помощью различных функций по заданным окнам, нормировать континуальные и маппить категориальные признаки, делать динамические преобразования с признаками, представляющими собой временные ряды и так далее.
Следующая часть Feature Store отвечает за доставку признаков ML-моделям. В случае Cold Storage это происходит через SDK, а для Hot Storage — через API.
И наконец, критическая часть Feature Store, ответственная за мониторинг данных. Она контролирует стабильность признаков, перформанс моделей и детекцию дрейфа на их признаковом пространстве. Так как описанная система подразумевает активное переиспользование признаков в разных моделях — это предъявляет дополнительные требования к их стабильности, ведь теперь мы рискуем выходом из строя сразу нескольких продовых процессов.
Что же может пойти не так с нашими данными?
Для начала стоит сказать, что объекты признакового пространства моделей — это обезличенные профили абонентской базы МТС, которая представляет собой устойчивую популяцию. Распределение признаков на этих объектах может меняться по разным обстоятельствам.
 Динамика популяции
Динамика популяции
Например, если завтра мужчин среди наших абонентов станет резко больше, чем женщин, это приведет к изменению распределения разных биометрических показателей в популяции.
Также, на распределения признаков сильно влияют естественные тренды. Первое, что приходит в голову — это ковидный локдаун, во время которого резко сократилось число международных авиарейсов, а вот заказов на доставку еды и продуктов, наоборот, стало больше. Привычный уклад жизни меняется в праздники: люди поздравляют друг друга, создают непривычно много коммуникационной активности. С развитием технологий популяция все больше использует мессенджеры и социальные сети вместо звонков и SMS.
Кроме этого, не стоит забывать про банальные ошибки на источниках и аппаратные неисправности, которые приводят к некорректно собранным метрикам.
Формально все это обобщается понятием дрейфа данных: если вы строите модель, чтобы предсказывать целевую переменную Y на объектах из X, то дрейф данных — это несовпадение совместных распределений на трейне и тесте.
 Data Drift
Data Drift
На картинке пример, когда мы обучаем и валидируем модель на данных из одного распределения, а предсказывать собираемся совсем уж непохожее.
А цель мониторинга в этом сеттинге — путем сравнения нового потока данных с тем, на котором модель обучалась, определить условия, в которых модель начинает деградировать, и предотвратить это.
Для этого нашему решению потребуются следующие модули:
Нужно научиться детектить дрейф. То есть выбрать методы его детекции на признаковом пространстве моделей и реализовать их.
Автоматизировать это в продакшене.
Научиться обрабатывать ситуации, когда данные не прошли проверку и правильно реагировать на обнаруженный дрейф: оперативно принимать решение о дальнейшей судьбе данных (например, пересчитать их). В противном случае, продуктовые процессы останутся без актуальных предсказаний.
В качестве бонуса — прогнать всю эту рутину на исторических данных, чтобы расширить диапазон стабильных признаков, которые мы можем использовать для обучения новых моделей
Существующие решения
Конечно, нам не хотелось изобретать велосипед. В идеале нужно было взять готовое обкатанное решение из индустрии, удовлетворяющее следующим требованиям:
Без проблем заводится в нашем распределенном стеке;
Помогает мониторить перформанс моделей;
Помогает детектить дрейф и собирать нужные метрики по признаковому пространству моделей. Тут важно отметить, что одним мониторингом предсказаний моделей здесь не обойтись, так как у нас в продакшене находится много моделей с длинным таргетом. Например, модель предсказания риска дефолта: мы обучили модель и поставили ее в промышленную эксплуатацию сегодня, а узнать результаты ее работы на реальных выдачах сможем только через год, в течение которого модель должна давать стабильные и надежные предсказания;
Без проблем интегрируется с нашим DQ-метастором. В этом случае не пришлось бы тратить ресурсы на внедрение нового способа хранение результатов, визуализации метрик и так далее.
А теперь посмотрим, что из этого можно закрыть с помощью готовых решений:
Первый кандидат — это амазоновский PyDeequ — фреймворк, который предоставляет удобный интерфейс для построения юнит-тестов над данными. Его очевидные плюсы в том, что он работает на спарке, причем поддерживает большую часть его версий, и предлагает широкий функционал для мониторинга признакового пространства: минимумы, максимумы, средние, стандартные отклонения и прочее. Но некоторый функционал для мониторинга целевых признаков пришлось бы реализовать самим, да и для интеграции его с нашим метастором потребовались бы ресурсы, так как базово он поддерживает только HDFS или облако.
Второй тип готовых решений — это фреймворки для ML-валидации, которых сейчас становится все больше. Они предлагают широкий функционал для мониторинга перформанса ML-моделей и, безусловно, могут быть широко использованы при их обучении. Но все-таки для DQ-мониторинга они подходят не очень хорошо. Хотя бы потому, что методы нужно будет адаптировать к распределенному стеку.
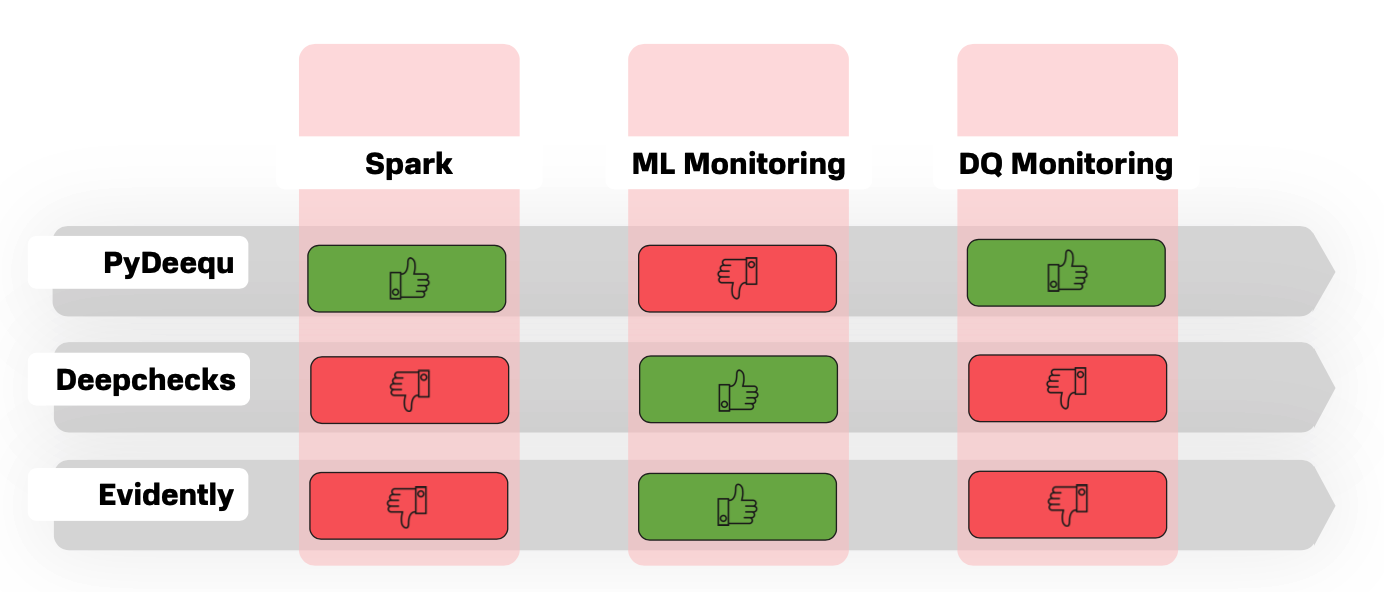 Сравнение существующих решений
Сравнение существующих решений
Поэтому мы приняли решение разработать собственный фреймворк для организации мониторинга на основании уже существующего в компании движка и метастора.
Реализация
Как определить дрейф?
За это отвечают реализованные в нашем фреймворке методы.
Как применять построенные методы в продуктовых процессах?
За это отвечают автоматизированные DQ-пайплайны.
Что делать в случае обнаружения проблем с данными?
За это отвечают алгоритмы обработки создаваемых инцидентов.
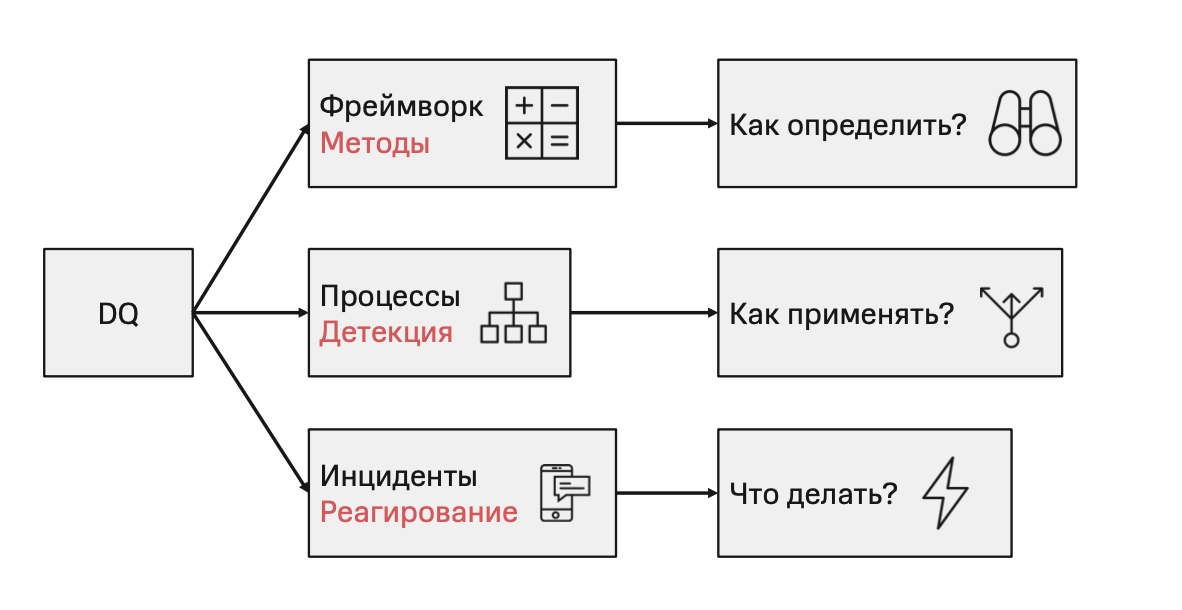 Структура решения
Структура решения
Методы
Первая часть посвящена методам: их можно поделить на те, что детектят дрейф на совокупном признаковом пространстве, и на те, что обрабатывают только маргинальные распределения признаков.
Наиболее яркий представитель многомерных методов — это adversarial-валидация
Идея простая и заключается в том, чтобы обучить классификатор, различающий тестовую и обучающую выборки.
Если классификатор, решающий эту задачу хорошо, нашелся — значит имеет место дрейф данных. Если же наоборот, никакая сильная модель не может отличить тест от трейна, значит распределения похожи.
 Adversarial Validation
Adversarial Validation
Очевидное преимущество — детекция дрейфа сразу на всем признаковом пространстве, при этом можно найти признаки, которые в большей степени различают обучение от теста или валидации, и выкинуть их на этапе обучения модели.
Но сильную модель обучать долго, тем более, что в итоге мы получим слабо интерпретируемые метрики в виде фичи импотанса и качества классификатора.
Самый простой и популярный одномерный метод — индекс стабильности популяции, идея которого заключается в сравнении двух распределений по одним и тем же бинам. Мы разбиваем по квантилям распределение на трейне, затем по полученным бинам разбиваем распределение на тесте и сравниваем доли значений, попавших в каждый бакет.
 Population Stability Index
Population Stability Index
Этот метод отлично считается распределенно. Кроме того, можно придумать сразу несколько оптимизаций: например, хранить бинаризованную тестовую выборку и ее квантили в метасторе и не пересчитывать их при каждом запуске проверок.
Также вычисление индексов для разных признаков можно производить параллельно. В конечном итоге, мы получим хорошо интерпретируемую метрику, на которую можно настроить простые катофы.
Но стоит помнить, что, ограничиваясь только PSI, мы контролируем маргинальные распределения. В то время как дрейф все равно может иметь место, например, в совместном распределении двух признаков.
Процессы
А теперь поговорим о применении этих методов в автоматизированном мониторинге. Для простоты давайте будем считать, что мы строим DQ-пайплайны вокруг признаков или вокруг предиктов моделей в Feature Store. И на этих двух примерах покажем, как устроены DQ-пайплайны.

Безусловно, самое важное, чего мы можем добиться с помощью ML-мониторинга — это предотвратить попадание некачественных данных в продуктовые процессы. Сделать это можно следующим незамысловатым образом: сразу после того, как ваша модель произвела на свет предсказания на новом срезе данных, вы считаете критические метрики, сравниваете их с заданными вами допустимыми значениями и не пускаете эти данные дальше в случае фейла какой-нибудь из проверок. И наоборот, пускаете их в продуктовые процессы только при условии прохождения всех проверок.
 ML модель в продакшене
ML модель в продакшене
Если же речь идет о признаках для какой-нибудь ML-модели, то мы можем немного усложнить предыдущую схему.
Сначала также посчитаем проверки и сверим результаты сравнения с эталонными значениями. В случае успешного прохождения просто пропустим построенные признаки дальше. А в случае фейла уведомим пользователя о том, что на новом срезе что-то не так. И попробуем оперативно починить фичи, не прошедшие DQ. Например, заменой их значений на значения из предыдущего среза.
Затем на данных после починки посчитаем все те же метрики. В случае успешного прохождения — отправим данные в Feature Store, а в случае фейла уведомим Data Governance о том, что DQ не проходит даже после замены значений.
Этот пайплайн — шаблон для реализации автоматизированного контроля, потому что тут вы вольны сами настраивать проверки и их параметры, а также выбирать действия, которые вы будете автоматически применять к данным, которые эти проверки не прошли.
 Группа признаков в Feature Store
Группа признаков в Feature Store
Инциденты
Во время работы описанных пайплайнов создавались три типа инцидентов:
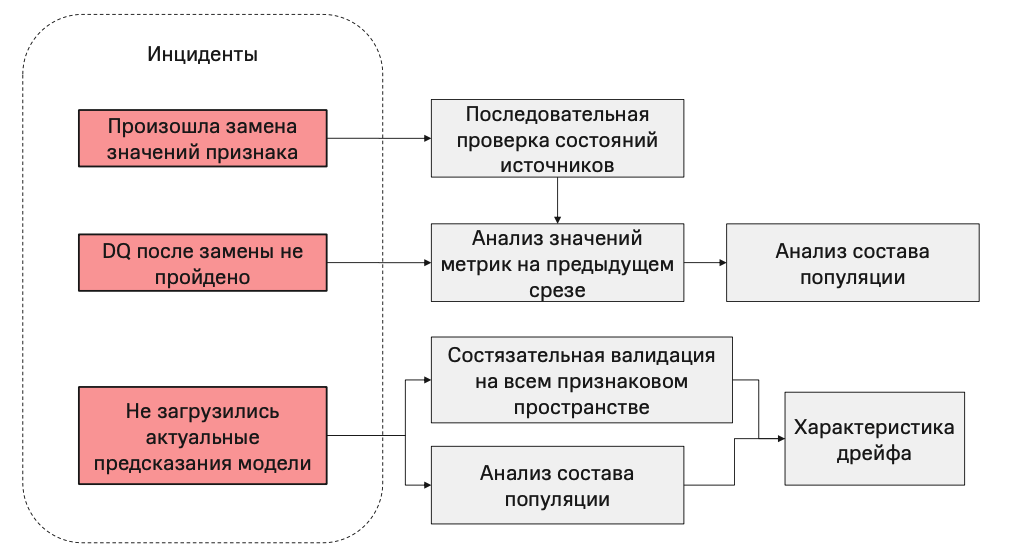
Первый возникает, когда фейлится проверка на одном из признаков.
Первое, что можно сделать — посмотреть DQ метрики на источнике, если они конечно есть, а затем посмотреть на этот признак в динамике, может быть он стал негодным в силу его трендовой природы.
Второй возникает, если DQ по признаку не проходит успешно даже после замены или других оперативных действий.
В этом случае надо посмотреть на какие данные мы делаем замену, может быть они не лучше тех, что были собраны. И посмотреть не изменилась ли у нас популяция, как было в примере с мужчинами и женщинами.
Если же на признаковом пространстве проверки не триггерятся, но при этом DQ не проходит по предсказаниям модели, то это может свидетельствовать о дрейфе данных на совокупном признаковом пространстве и в попытках найти причину его можно исследовать уже более сложными многомерными методами. Кроме того, проблема может скрываться и в изменившемся составе популяции.
Примеры на исторических данных
Пришло время посмотреть как все рассмотренные практики работают на реальных данных. Для начала небольшой дисклеймер:
Я анонимизировал рассматриваемые признаки.
По оси X находятся недели, а по оси Y — значение индекса стабильности.
Первый пример — про признак с естественным трендом. Например, возраст объектов популяции в днях. С каждым днем все объекты стареют на день и это увеличивает значение индекса, что негативно влияет на стабильность модели, использующей этот признак.
Но оказывается, что эту проблему можно устранить, например, нормировав значение этого признака на среднее значение в популяции за эту дату. Тогда, как мы видим это на графике, на протяжение 5 лет признак все еще является стабильным.
 Трендовый признак
Трендовый признак
Теперь посмотрим на признак, у которого время от времени случаются проблемы со сборкой. В эти даты индекс стабильности у нас сильно подскакивает и триггерится соответствующая проверка.
Однако посредством построенного пайплайна, мы меняем значения признаков для объекта на значения из предыдущего среза и получаем куда более приятную картину:
 Признак с проблемными срезами
Признак с проблемными срезами
Аналогичная ситуация и с проблемными периодами: на этом графике на протяжение пятнадцати недель значения признака сильно отличались от значений за эталонную дату, например, из-за какой-то серьезной неисправности части системы. И при должном контроле эта ситуация отлично сглаживается.
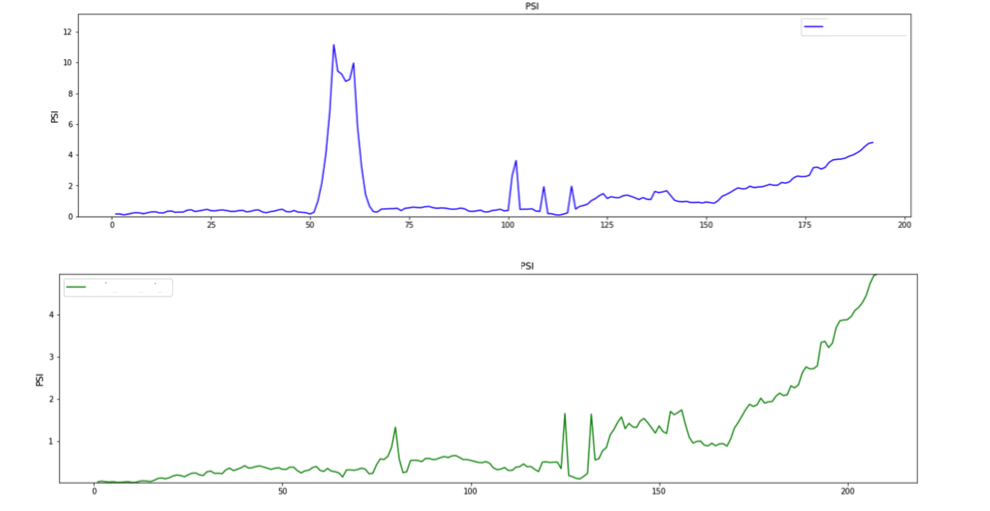 Признак с проблемным периодом
Признак с проблемным периодом
Выводы
Один из наиболее полезных уроков этого опыта заключается в том, что стабильность моделей в продакшене во многом закладывается во время их обучения, по большей части на стадиях фичи инжиниринга и фичи селекшена.
И я бы еще раз хотел подчеркнуть, что главная миссия DQ-мониторинга в том, чтобы не допустить принятия бизнес-решений на искаженных или ненадежных данных.
Что дальше
Мы наметили некоторые направления для дальнейшей разработки:
Усложнение DQ-рутины в части действий и решений, которые принимаются автоматически. Например, для некоторых видов моделей можно предусмотреть автоматическое переобучение.
Это, в свою очередь, может потребовать внедрения методов детекции дрейфа на совокупном признаковом пространстве, которые нужно сначала эффективно реализовать.
Рассмотренные процессы можно попробовать адаптировать для автоматического фича селекшена при добавлении признаков в Feature Store.

В заключение хочу вам пожелать:
Синтезировать стабильные признаки.
Строить на них стабильные модели.
Качественно мониторить все это в продакшене.
И спать спокойно.
Если после прочтения статьи у вас появились вопросы, замечания или предложения — добро пожаловать в комментарии, пообщаемся!
