Проклятье TOAST и с каким маслом его ест JSONB
О роли формата JSON в эволюции реляционных баз данных я недавно рассказал на двух конференциях — HighLoad++ и Saint HighLoad++ 2021. А также о том, что мешает эффективно использовать JSONB (бинарный JSON) и как с этим можно бороться.
Сегодня посмотрим на особенности работы с TOAST — отдельным хранилищем для длинных записей. Начну с проклятия TOAST для JSON, а в следующей части расскажу, как это можно использовать в PostgreSQL, и за счет чего получится повысить производительность JSONB.

Почему важно начать именно с TOAST? Если вы хотите хранить в JSON больше 2 килобайтов данных, то должны понимать к чему это может привести, иначе PostgreSQL принесет вам небольшой сюрприз в виде непредсказуемой производительности.
Чтобы лучше понять существующую ситуацию, необходимо немного углубиться в историю.
Эволюция Postgres и JSONB в роли главного драйвера
На основе материалов сайта DBEngine, мы построили график, с помощью которого можно проанализировать динамику относительной популярности четырех мировых СУБД и увидеть, что PostgreSQL пошел в рост с 2014 года — как раз с момента появления JSONB.
Кроме того, график показывает, что единственной СУБД, которая ощутимо растет с 2014 года, также является PostgreSQL. Остальные — MySQL, Oracle, MS SQL, находятся в константе или чуть проседают.
 NoSQL users attracted by the NoSQL Postgres features
NoSQL users attracted by the NoSQL Postgres features
Такой рост объясняется тем, что PostgreSQL стала первой реляционной базой данных, поддерживающей слабоструктурированные данные. Причем, работу над этой задачей мы начали довольно давно — в 2003 году у нас появился прообраз хранилища для слабоструктурированных данных Hstore — бинарный тип данных для хранения произвольных данных «ключ-значение», а с 2006 года Hstore стал частью PostgreSQL и дал возможность уже тогда удобно работать с данными с переменчивой структурой.
Официально JSON появился в PostgreSQL только в 2014 году, он представлял собой текстовую строку с валидацией и без возможности индексирования. Я считал, что этого недостаточно и мы начали работу над расширением функциональности Hstore в сторону поддержки вложенных объектов и массивов, и их индексирования, который впоследствии получил название JSONB, и в 2014 году стал частью PostgreSQL. Тогда к нам пришло много NoSQL пользователей, которым нуждались в гибкости NoSQL, надёжности и богатства функциональности реляционных СУБД. PostgreSQL с JSONB дал им эту возможность и теперь JSONB используется практически во всем мире. Поэтому мы продолжали работу над его развитием.
Успех JSONB привёл к тому, что все основные реляционные СУБД, коммерческие и опенсорсные, обзавелись поддержкой JSON, и в конце-концов, JSON стал частью стандарта SQL-2016. Сейчас готовится новое издание стандарта, в котором уже будет описан формат типа данных JSON.
SQL/JSON в PostgreSQL
Мы взяли JSONB как подмножество SQL/JSON модели данных, но подмножество упорядоченных и уникальных ключей. Опыт показал, что этого хватает практически для всех задач. Чтобы можно было гибко описать ту часть дерева или поддерева JSON, с которыми вы работаете, мы реализовали JSONPath. Это наиболее важная часть стандарта. И этим уже можно пользоваться, это закоммичено в 12–13 версиях СУБД PostgreSQL, где поддерживаются все 15 фич.
Поддержку JSONPath мы также добавили в индексы — теперь их можно использовать для того, чтобы специфицировать и искать по JSONPath. Но самое интересное, что все предыдущие существующие индексы, уже лежащие на диске, которые вы делали для JSONB, поддерживают JSONPath без изменений.
То есть, чтобы сделать JSONB стандартным SQL-типом, мы создали SQL/JSON функции и обобщенный API, и теперь с помощью специальной переменной можно объявить JSONB как JSON. Благодаря этому теперь можно писать приложения для любой базы данных.
Также мы улучшили индексирование JSON: создали селективные индексы и расширили синтаксис JSONPath, вплоть до поддержки лямбда-функций. Это всё это уже можно попробовать и начать использовать в работе. Над SQL/JSON функциями мы честно работали 4 года: 55-я версий патча для SQL/JSON и 48-я для JSON_TABLE ждут своего ревью.
В настоящее время мы решили немного придержать основные проекты и заняться тем, чтобы сделать JSONB «гражданином первого класса» в Postgres. Мы хотим, чтобы у него было действительно эффективное хранение, быстрые выборки, апдейты и хороший API. Cейчас эти задачи заявлены как высший приоритет.
Тем более, что в JSONB есть что улучшать. Несмотря на то, что формат является «зрелым» типом данных с большой функциональностью и поддержкой, его очевидная проблема заключается в непредсказуемой производительности. Давайте разберемся, в чем причина этих затруднений.
Пример 1. Классика жанра
Есть простейшая таблица, состоящая из ID и JSON в виде длинного массива. Вы делаете запрос, получаете 6 мс и у вас всё хорошо. Потом вы делаете маленький апдейт, всего лишь добавляя ключ «bar» со значением «baz» и… получаете 66 мс. То есть производительность просела в 10 раз, что, конечно, уже не так хорошо.

Связано это с тем, что после апдейта JSON стал чуть больше, чем 2 Кб. Но кто сейчас имеет строки не больше 2 Кб? У всех нас JSONы достаточно ветвистые, а таблицы — широкие.
Всё, что больше 2 Кб, даже после компрессии, уходит в отдельное хранение, в TOAST. Сам JSONB разбивается на две части: pointer, показывающий на скрытую от нас табличку, куда на самом деле перемещаются эти данные, и чанк из TOAST-реляции, где они и хранятся.

Для доступа к такому JSONB нам нужно прочитать три дополнительных буфера. Два тянутся из индекса, который тоже строится автоматически (в данном случае B-tree имеет высоту 2), и один — из TOAST heap, в котором содержится сам JSONB.
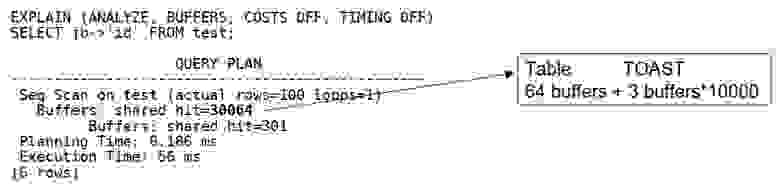 То есть, нам надо прочитать 30064 страницы, из которых реально полезных — только 64
То есть, нам надо прочитать 30064 страницы, из которых реально полезных — только 64
В этом и заключается проблема: как только вы начинаете доставать какое-то значение из TOAST, вам приходится делать внутренний джойн — читать все чанки, потом джойнить их и deTOAST«ить в память. И только потом с ним можно что-то сделать.
Это приличный оверхед и одно из проклятий TOAST. Это хорошо работающая система, в которой содержится скрытая бомба. Чтобы TOAST произошел, нужно сделать целых 4 шага, а это довольно сложно.Посмотрим поближе, что такое TOAST и как он работает.
TOAST
TOAST (The Oversized-Attribute Storage Technique) — это отдельное хранилище для длинных записей. В самой таблице хранятся строки не больше 2 Кб, все, что больше, как я уже говорил, уходит в TOAST. Его значения сжимаются в формате pglz, а затем разбиваются на фрагменты TOAST фиксированного размера, 1996 B для страницы 8 KB.
TOAST-чанки, вместе со сгенерированным Oid chunk_id и sequnce номером chunk_seq, хранятся в специальном TOAST-отношении pg_toast.pg_toast_XXX, автоматически создаваемом для каждой таблицы, содержащей TOASTable атрибуты. Атрибут в исходном heap tuple заменяется на TOAST-указатель (18 байт), содержащий chunk_id, toast_relid, raw_size и compressed_size:
 TOAST (The Oversized-Attribute Storage Technique)
TOAST (The Oversized-Attribute Storage Technique)
TOAST access
Указатели TOAST не ссылаются непосредственно на heap tuples с чанками. Вместо этого они содержат Oid chunk_id, и нам нужно спускаться по индексу (chunk_id, chunk_seq). Накладные расходы на чтение всего нескольких байт из первого чанка в итоге составят 3, 4 или даже 5 дополнительных индексных блоков, потому что в этой таблице существует свой B-tree индекс. И сначала вы по индексу прочитаете 3–4–5 блоков, а потом уже пойдете в таблицу собирать чанки:
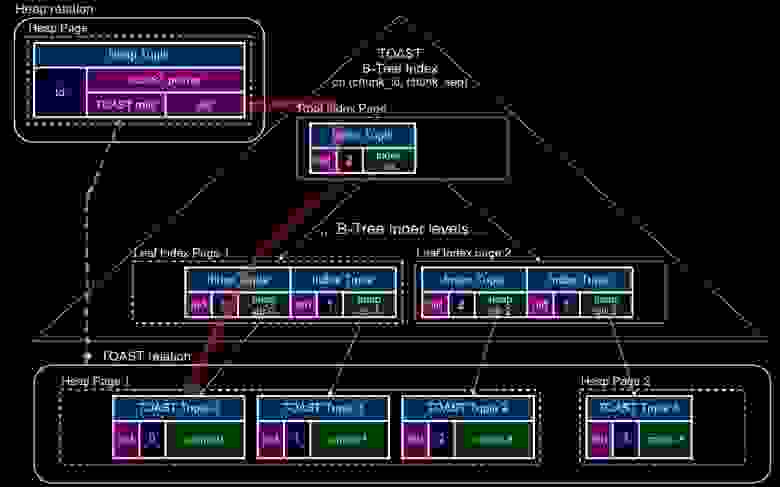 TOAST access
TOAST access
TOAST passes
Есть несколько разных алгоритмов для TOAST: например, мы можем указать, что какие-то колонки не TOAST«им никогда. Стандартно TOAST проходится за 4 шага, при каждом проходе рассматриваются только атрибуты определенного типа хранения (extended/external или main), начиная с самого большого. Plain атрибуты не TOAST«ятся и не сжимаются вообще.
Процесс может останавливаться на каждом шаге, если размер результирующего тупла становится меньше 2 КБ. Если атрибуты были скопированы из другой таблицы, они уже могут быть сжатыми или заTOASTеными, и тогда тоже заменяются указателями TOAST.
При первом проходе TOAST учитываются только extended и external атрибуты. Если размер extended атрибутов превышает 2 КБ, они сжимаются и перемещаются в TOAST, а вместо них остается pointer на чанки:

При втором проходе TOAST ситуация повторяется, пока размер результирующего тупла не станет < 2 КБ. Рассматриваются только те extended и external атрибуты, которые не были заTOASTены в предыдущем проходе:

При третьем проходе TOAST рассматриваются только main атрибуты и происходит их сжатие:

В последнем проходе TOAST каждый не-plain атрибут TOAST«ится, пока размер результирующего кортежа не станет < 2 КБ:

А теперь посмотрим на примере, как действует TOAST.
Апдейт таблицы
Возьмем 10 000 JSONB, у которых имеется 1000 простых ключей { »1»: 1,»2»: 2, … }:
CREATE TABLE t AS
SELECT i AS id, (SELECT jsonb_object_agg(j, j) FROM generate_series(1, 1000) j) js
FROM generate_series(1, 10000) i;
SELECT oid::regclass AS heap_rel,
pg_size_pretty(pg_relation_size(oid)) AS heap_rel_size,
reltoastrelid::regclass AS toast_rel,
pg_size_pretty(pg_relation_size(reltoastrelid)) AS toast_rel_size
FROM pg_class WHERE relname = 't';Сама таблица будет занимать 512 Кб, а хранилище TOAST — 78 Мб. JSON будет 19 Кб, и он сжимается в 6 Кб, которые займут 4 чанка в TOAST (чанки размером по 2 Кб). Дальше давайте проапдейтим колонку id — она маленькая, находится отдельно и никогда не попадет в TOAST:
SELECT pg_current_wal_lsn(); --> 0/157717F0
UPDATE t SET id = id + 1; -- 42 ms
SELECT pg_current_wal_lsn(); --> 0/158E5B48
SELECT pg_size_pretty(pg_wal_lsn_diff('0/158E5B48','0/157717F0')) AS wal_size;Апдейт займет всего 42 мс, и WAL будет всего 1,5 Мб, то есть 150 байт на запись. При этом размер TOAST не изменится — как был 78 Мб, так и останется. И теперь давайте проапдейтим JSON:
SELECT pg_current_wal_lsn(); --> 0/158E5B48
UPDATE t SET js = js — '1'; -- 12316 ms (was 42 ms, ~300x slower)
SELECT pg_current_wal_lsn(); --> 0/1DB10000
SELECT pg_size_pretty(pg_wal_lsn_diff('0/1DB10000','0/158E5B48')) AS wal_size;Это займет 12 секунд, то есть станет в 300 раз медленней, а размер WAL увеличится до 130 Мб вместо 1,5 Мб. Хранилище TOAST соответственно увеличилось в 2 раза. То есть, мы сделали маленький апдейт и у нас сразу же возникли проблемы.
Это объясняется тем, что TOAST, который реализован в Postgres, ничего не знает о структуре JSON. Потому что когда-то реляционные базы работали только с атомарными типами данных, а что там внутри, особо никого не интересовало. Сейчас появились JSON, массивы и прочее, но механизм, который реализован, ничего об этом не знает. Поэтому апдейт JSON происходит очень туго.
Из этих простых примеров становится ясно, что декомпрессия является большой проблемой. Во второй части я расскажу, какие улучшения мы провели, чтобы с этим справиться.
Видео моего выступления на HighLoad ++ 2021:
Следующее повышение цен на HighLoad++ Foundation — 1 февраля. Вы можете забронировать билеты и выкупить их позже по той же цене. Также действует акция: при покупке офлайн-билета на HighLoad++ Foundation до 31 декабря вы сможете получить крутой подарок на выбор: эксклюзивный рюкзак HighLoad++ или участие в pre-party.
