Производные в реактивности

С этой статьи я начну цикл материалов, посвященных базовым концепциям реактивности, основанных на идеях и примерах, которые подробно изложил автор SolidJS, Райан Карниато (Ryan Carniato), в своем блоге. Наша цель — разобрать фундаментальные принципы, лежащие в основе реактивных систем, и показать их применимость в различных контекстах.
Обычно, когда вы впервые сталкиваетесь с реактивной системой, вводный пример выглядит примерно так:
let name = state("John");
effect(() => {
console.log("Hi" + name);
})
Мы будем использовать псевдокод, не ориентируясь на синтаксис конкретной библиотеки или фреймворка.
Не нужно много усилий, чтобы понять, что при обновлении этого состояния происходит событие, которое вызывает побочный эффект. Также несложно реализовать это поведение самостоятельно. Но это далеко не вся история.
Независимо от того, пытаетесь ли вы забыть React, строите представления на Vue или склоняетесь к Angular, эта тема актуальна. Она выходит за рамки виртуального DOM или сигналов. Прежде чем винить useEffect во всех бедах, давайте разберем ключевую часть реактивности: производные.
Деривация и синхронизация
Вы, наверное, уже сталкивались с производными значениями в своем любимом JS-фреймворке или реактивной системе. Возможно, они выглядели как useMemo, вычислялись автоматически или просто обозначались символом $. Но во всех этих случаях суть оставалась неизменной — они использовались для создания реактивных зависимостей. Но неизменным во всех этих случаях было то, что вам говорили в разных документациях, что они предназначены для создания реактивных зависимостей. A — это сумма B + C, даже если B или C меняются:
let a = state(1);
let b = state(1);
const c = memo(() => a + b);
effect(() => console.log(c));Возможно, вы уже знаете, что производное значение должно быть чистым, то есть не изменять никакое другое состояние. Но важно понимать, что это правило относится и к самому производному значению.
На первых порах можно использовать следующую ментальную модель для представления производного состояния:
function memo(fn) {
let internal = state();
effect(() => internal = fn());
return internal;
}Однако такой подход не сработает должным образом.
Большинство UI-фреймворков ориентированы на интерактивность: они принимают данные от пользователя, обновляют состояние и перерисовывают интерфейс. В упрощенной форме это можно выразить как UI = fn (state), но на самом деле это циклический процесс, повторяющийся снова и снова.
С точки зрения реактивности это выглядит так:

Причина в том, что конечному пользователю, взаимодействующему с пользовательским интерфейсом, необходима конситстентность. Все, что он видит (и не видит), должно быть синхронизировано. Вы не можете взаимодействовать с частью страницы, которая устарела, поскольку это создает ложные ожидания. Библиотеки пользовательского интерфейса планируют синхронное выполнение побочных эффектов, чтобы конечный пользователь мог доверять своим ощущениям.
Это означает, что существуют определенные этапы выполнения кода. Библиотеки должны гарантировать, что все зависимые вычисления будут решены до рендеринга.
Это позволяет понять, в чем именно заключается разница между подходами.
Первый пример — деривация, когда производное состояние является функцией состояния, от которого оно зависит.
let name = state("John");
const upperName = memo(() => name.toUpperCase());
updateUI(name, upperName);Второй пример — синхронизация, когда изменение состояния приводит к обновлению другого состояния. Это важное различие.
let name = state("John");
let upperName = state();
effect(() => upperName = name.toUpperCase());
updateUI(name, upperName);Во втором примере, в зависимости от вашей модели реактивности, может произойти не просто немедленное отображение всего, как ожидалось.Эффект может быть запланирован до или после рендеринга пользовательского интерфейса.
При обновлении имени вы можете ненадолго увидеть обновленное имя вместе с предыдущим значением upperName. В таких фреймворках, как React, ваш компонент может быть запущен дважды. Потому что обновление состояния в эффекте запускает цикл заново.
Консистентность без глюков
Даже если вам удается синхронизировать состояние перед рендерингом, выражения все равно могут выполняться несколько раз с разными промежуточными значениями — возможно, неожиданными — до тех пор, пока весь граф зависимостей не стабилизируется.
Производные устраняют эту неопределённость, обеспечивая предсказуемое и устойчивое поведение.
Многие реактивные системы сейчас гарантируют, что при любом обновлении состояния каждый узел запускается только один раз, и когда он запускается, то не происходит сбоев. Под безглючным понимается то, что код, который разработчик предоставляет библиотеке, никогда не сможет показывать промежуточное или устаревшее состояние.
Рассмотрим на простом примере работу кода:
let a = state(1);
const b = memo(() => a + 1);
const c = memo(() => a + 1);
const d = memo(() => c + 1);
const e = memo(() => b + d);
effect(() => console.log(e));А теперь представим его в виде графа:
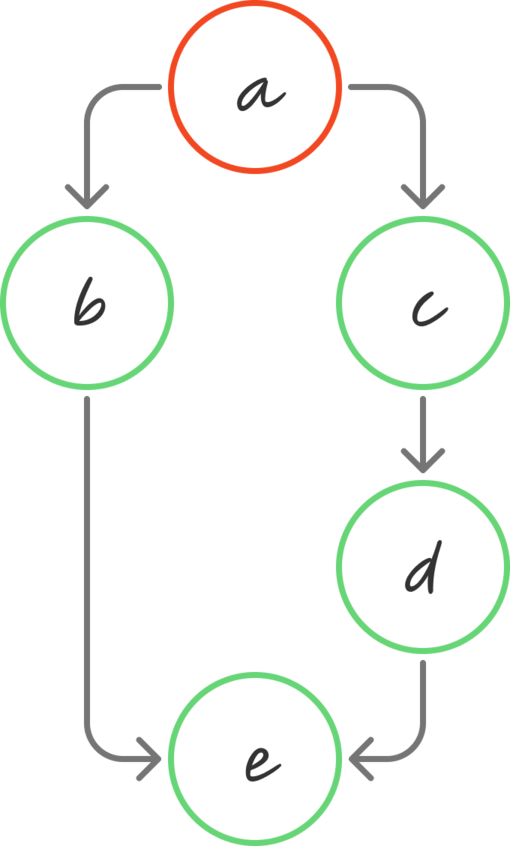
Разные системы функционируют по-своему, но в каждом случае мы ожидаем, что при первом запуске значение e окажется равным 5, хотя не факт, что это произойдет сразу.
Кроме того, очевидно, что одни состояния могут зависеть от других. Например, если мы обновляем a = 2, то, независимо от механизма, понятно, что c должно вычисляться раньше d, а d — раньше e. Это важно, если мы хотим, чтобы каждый узел при новых значениях переменной обновлялся только один раз.
Push vs Pull

Как же мы подходим к тому, чтобы узлы обновлялись только один раз? Обычно это начинается с одной из двух идей. Планирование (pull) и события (push). Давайте рассмотрим каждую из них на примере предыдущего раздела.
Pull (Планирование)
Идея состоит в том, чтобы начинать с побочного эффекта (целевого результата) и затем запрашивать значения переменных по мере их возникновения. React обычно воспринимается как система, построенная на «pull»-модели реактивности. В этой модели при обновлении состояния система запускает проверку, чтобы понять, нужно ли выполнять какую-то работу.
Но что именно она проверяет? Наивно предположить, что проверяется всё подряд, ведь система не знает, что конкретно изменилось.Однако многие UI-библиотеки, включая React, построены на компонентах. Если состояние связано с конкретным компонентом, то при обновлении этого состояния система планирует повторный рендеринг компонента.
«Pull»-системы, как правило, являются крупнозернистыми (coarse-grained). Они опираются на полное обновление сверху вниз, поскольку не обладают информацией о том, что именно изменилось. Если же представить более гранулярную «тянущую» систему, она не сможет определить, что произошло изменение, пока не проследит цепочку зависимостей до источника этого изменения — который, к слову, может и не существовать в её графе зависимостей. Такой дополнительный обход становится лишней работой, особенно если в итоге всё равно приходится выполнять обновление сверху вниз.

В нашем примере на картинке мы запускаем эффект, который сначала запрашивает значение e. Однако мы не можем определить, изменилось ли e, без предварительного выполнения узлов b или d. Использование явных зависимостей (например, массивов зависимостей в React) позволяет нам выстроить путь вверх по графу зависимостей без необходимости выполнять промежуточные узлы. Таким образом, мы можем отследить зависимости e → b → a, выполнить b, затем отследить d → c → a, выполнить c, d, e, и только после этого запустить наш эффект.
Если подумать, раз уж мы всё равно проверяем всю область (скажем, весь компонент) при изменении корневого элемента, хотя не все его части реально поменялись, получается, что многие из этих проверок просто лишние.
Мемоизация (часто в форме производных), позволяющая ранние выходы, помогает оптимизировать этот сценарий, но подход, хотя и последовательный, в корне неэффективен.
Push (События)
Идея заключается в том, что обновление распространяется наружу от исходного состояния, которое было изменено. RxJS служит популярным примером реактивности, основанной на «push»-модели. В такой системе каждый узел подписывается на события изменения своих зависимостей. Получив уведомление об изменении, узел выполняется и, если его собственное значение изменилось, уведомляет своих «наблюдателей».
При этом стоит рассмотреть распространение обновлений в глубину, поскольку это соответствует тому, как выполнение происходит при первоначальном создании системы.

Когда обновляется a, оно уведомляет b и c. Затем b выполняется и уведомляет e. После этого e запускается и видит обновленное значение b, но сталкивается с проблемой: d еще не выполнился и содержит устаревшее значение.
У подхода с обходом в ширину (Breadth-first) есть схожая проблема. Поскольку d и e находятся на одинаковом расстоянии от источника a, это снова приводит к ситуации с устаревшими значениями. Система попытается выполнить b, затем c, после чего перейдет к e и d, но обнаружит, что d не был оценен раньше e.
Системам на «push»-модели сложно гарантировать нужное поведение без лишних вычислений. Один из подходов — топологическая сортировка, которая упорядочивает зависимости и помогает распространять изменения, но даже она не спасает от ненужной работы, если эффектов для обновления в итоге нет. Система знает, что изменится, но не может заранее предугадать итоговое влияние.
Push-Pull
Третий подход заключается в объединении обеих техник — «push» и «pull». Сигналы (Signals) представляют собой де-факто гибридную реактивную систему «push-pull». Подписки и уведомления работают по принципу «push», а планирование выполнения задач осуществляется по принципу «pull». Благодаря этому планируются только те действия, которые действительно могут привести к изменениям, а всё остальное остаётся нетронутым.
Рассмотрим наш пример: при обновлении a узлы b и c получают уведомления о возможных изменениях, а затем передают эти уведомления дальше — к e и d. В итоге эффект, который зависит от e, ставится в очередь на выполнение. Когда эффект запускается, он начинает подтягивать значения по мере необходимости, как в нашей гипотетической системе «pull», описанной ранее. Однако в данном случае в очередь добавляются только те эффекты, которые действительно могут быть затронуты изменениями.
Такой подход позволяет точно знать, что именно изменилось и как эти изменения влияют на систему, гарантируя выполнение только необходимой работы.
Если вас интересует более подробная информация о том, как работают алгоритмы «push-pull» в различных реализациях сигналов (Signals), вы можете ознакомиться с дополнительными материалами.
Итог
«Что можно вывести, то и нужно выводить».
Эту фразу сказал Мишеля Вестрейта, создатель MobX, и это действительно принцип, который стоит взять на вооружение.
Само собой разумеется, что последовательность, которую мы привыкли ожидать от наших библиотек и фреймворков, была бы недостижима, если бы мы опирались исключительно на состояние и эффекты. Когда эффект записывает данные в состояние, пройтись по графу зависимостей, чтобы понять, что нужно вычислить, становится невозможно. Зависимость попросту исчезает. Это не только неэффективно — это чревато ошибками.
Тема эта невероятно глубокая, и я лишь слегка затронул её основы. Существуют и другие нюансы в противопоставлении «push» и «pull», и даже внутри одной категории систем можно найти множество тонкостей. В следующий раз мы углубимся в различия между ленивыми и нетерпеливыми вычислениями (lazy vs eager derivations), а также рассмотрим возможности работы с асинхронными операциями.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
-15% на заказ любого VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
