Offset Explorer: разбираемся в базе
Всем привет! Меня зовут Макс. Я Lead Backend в компании ИдаПроджект и автор YouTube-канала PyLounge.
Любой крупный проект так или иначе используют брокеры сообщений — и чаще всего это Apache Kafka. Так что уметь взаимодействовать с Kafka (хотя бы на базовом уровне) будет полезно как разработчику, так и тестировщику или аналитику.
Я в своей работе практически ежедневно взаимодействую с кафкой, поэтому решил поделиться опытом. В команде мы используем графический интерфейс Offset Explorer (далее OE), о котором сегодня и пойдет речь.
Погнали!
Что же тут будет (и не будет)
В этом материале мы:
узнаем, что такое Offset Explorer, зачем он нужен и как его установить
научимся подключаться как Kafka-кластеру через OE
познакомимся с интерфейсом OE
узнаем, как создавать и просматривать топики
увидим, как просматривать и отправлять сообщение в топики
научимся перечитывать топики кафки (редкий навык по моим наблюдениям)
познакомимся с инструментами импорта и экспорта
а также посмотрим на альтернативные варианты OE — AHKQ и Kafka-UI
А вот чего здесь НЕ будет:
информации про то, что такое Kafka, зачем нужна и как она работает
информации о том, что такое топики, партишены, zookeeper, кластеры и т.д.
Этот материал посвящен преимущественно Offset Explorer и его применению при работе с Kafka. Поэтому подразумевается, что читатель имеет хотя бы минимальное базовое понимание концепций Kafka:)
Я продемонстрирую на практике все, что сам использую в повседневной работе. Материалов в Интернете про это немного (особенно на русском языке), поэтому начинающим специалистам пригодится в работе. Есть, конечно, официальная документация на английском, которую я тоже использовал для подготовки этого материала. Ссылки на все источники я обязательно предоставлю.
P.S. Материал рассчитан на новичков и тех, кто хочет научиться базовой работе с Kafka со стороны НЕ ее администратора. Поэтому помните — не всегда то, что очевидно мне или вам, понятно кому-то другому :)
P.S. S. Offset Explorer, как и любой инструмент, можно разбирать довольно долго. В этом материале рассмотрены базовые вещи, которые, тем не менее, покрывают 90% пользовательских кейсов, которые я вижу по своему опыту. Но держите в голове, что «темные пятна» все равно останутся и, возможно, в чем-то придется разбираться самому :)
Установка
Для начала необходимо установить Offset Explorer. Переходим на официальный сайт и скачиваем подходящий под вашу ОС вариант установщика (OE доступен для Windows, Linux и MacOS).

Windows
В случае с Windows скачивается обычный .exe-файл. Запускаем установщик и последовательно проходимся по формам установочного виззарда.
MacOS
В случае с MacOS скачивается .dmg-файл. После загрузки открываем Finder и переходим в раздел «Загрузки». Дважды щелкаем на загруженный файл *.dmg, перетаскиваем значок приложения в папку «Приложения», чтобы установить приложение. Закрываем окно и нажимаем кнопку извлечения в Finder.
Linux
В случае с Linux открывается .sh-файл (скрипт для установки), который необходимо сохранить — например, комбинацией клавиш Ctrl + S. После этого переходим в каталог, куда сохранили файл, и запускаем его командой sh offsetexplorer.sh
Если файл не удалось запустить из-за нехватки прав — выставляем права на выполнение и запускаем снова.
sudo chmod +x offsetexplorer.sh
sh offsetexplorer.shЗапуск Kafka (опционально)
Если у нас нет уже существующего сервера Kafka, к которому можно подключиться, то развернем его локально с помощью Docker. Для этого воспользуемся готовым образом kafka-kraft из DockerHub.
Загрузим образ и запустим экземпляр контейнера на порту 9092 с помощью этой команды:
docker run -p 9092:9092 -d bashj79/kafka-kraft
Для управления Kafka из коробки доступен Kafka CLI. Мы можем использовать его, подключившись к контейнеру.
Сначала узнаем имя (NAMES) или Container id контейнера с помощью команды docker ps

Теперь подключимся к контейнеру по его id:
docker exec -it d9bcb5ec2669 shМожно, например, создать топик, посмотреть уже существующие и отправить в только что созданный сообщение:
$ cd /opt/kafka/bin
# создаём топик pylounge.videos
$ sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic pylounge.videos --partitions 1 --replication-factor 1
Created topic pylounge.videos.
# список топиков
$ sh kafka-topics.sh --bootstrap-server localhost:9092 --list
pylounge.videos
# отправить сообщение в топик
$ sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic pylounge.videos
>django
>fastapi
>litestar
Что такое и зачем нужен Offset Explorer
Offset Explorer (ранее Kafka Tool) — это приложение с графическим интерфейсом для работы с Kafka.
ОЕ позволяет быстро просматривать объекты в кластере Kafka, а также работать с сообщениями в топиках кластера.
Что позволяет делать OE:
просматривать содержимое кластеров Kafka, включая брокеров, топики и consumer«ов
просматривать и добавлять сообщения в партиции
просматривать и выставлять offset у consumer
выводить сообщения в JSON, XML и Avro формате с возможностью их локального сохранения
управлять топиками, их конфигурациями
обеспечить поддержку протоколов и механизмов аутентификации и шифрования для Apache Kafka
писать свои собственные плагины для вывода кастомных форматов данных и т.д.
Итак, мы установили OE и локально подняли Kafka. Переходим к подключению.
Подключение к Kafka через Offset Explorer
Чтобы работать с данными в кластере Kafka, необходимо создать подключение. Это можно сделать с помощью пункта 'Add New Connection' в меню File или через контекстное меню каталога Cluster. В диалоговом окне при создании нового подключения необходимо указать следующие значения в разделе General:
Cluster Name — имя, которое мы хотим дать кластеру (чисто для вашего удобства)
Bootstrap Servers — серверы (с портами), настроенные в кластере
Версия — версия кластера
Zookeeper Host — имя хоста или IP-адрес хоста zookeeper в кластере
Порт Zookeeper — порт хоста zookeeper
chroot path — путь, по которому данные кластера Kafka отображаются в Zookeeper.
Создадим новое подключение к запущенной в Docker Kafk«e.

Вводим данные для подключения:
Cluster Name — pylounge (самопиар)
Bootstrap Servers — localhost:9092 (поскольку Kafka у нас запущена локально в Docker, и мы пробросили порты на 9092)
Версия — 3.7 (просто оставляем по умолчанию)
Enable Zookeeper access — в нашем случае галочку можно не ставить (у нас очень простой «кластер», zookeeper для управления настраивать нет смысла).

Если кластер использует механизм безопасности PlaineText (такое, как правило, бывает в локальных или тестовых средах — как в нашем случае), то настраивать дополнительные атрибуты безопасности не нужно. Мы остановимся именно на этом варианте.

Если же кластер настроен на SASL, то следует либо указать специальную конфигурацию JAAS в пользовательском интерфейсе, либо передать файл конфигурации JAAS в Offset Explorer при его запуске.
В Windows нужно запустить Offset Explorer:
offsetexplorer.exe -J-Djava.security.auth.login.config=c:/мой_jaas_файл.confДля Linux запуск другой:
offsetexplorer -J-Djava.security.auth.login.config=/мой_jaas_файл.conf
На MacOS потребуется помощь файла offsetexplorer.sh, расположенного в следующей папке:
/Applications/Offset Explorer.app/Contents/java/app
Перед этим необходимо настроить предоставленный файл мой_jaas_файл.conf в соответствии с конфигурацией кластера Kafka.
Если вы не передаете файл конфигурации JAAS при запуске Offset Explorer, то его можно указать на вкладке JAAS Config для каждого соединения. Пример из документации:

При использовании SASL Plaintext необходимо изменить свойство клиента sasl.mechanism на PLAIN. Это можно сделать в текстовом поле 'SASL Mechanism' в разделе 'Advanced'.

Если кластер Kafka настроен на использование SSL, то необходимо задать параметры конфигурации SSL. В случае, когда брокеры Kafka не используют сертификат сервера, выпущенный публичным центром сертификации (СА), потребуется указать локальный сертификат с собственной подписью, которым подписан сертификат брокеров.
Если SAN (ы) в сертификате вашего сервера не совпадают с реальным именем хоста брокеров, к которым мы подключаемся, при попытке подключения получим SSL-ошибку (No subject alternative DNS name matching xxx found). Можно избежать этого, сняв флажок 'Validate SSL endpoint hostname' в разделе 'Broker security'. При этом свойство клиента ssl.endpoint.identification.algorithm будет установлено в null.

Если кластер требует наличия клиентского сертификата (двусторонняя аутентификация), то необходимо настроить атрибуты хранилища ключей. В keystore содержится закрытый ключ, который мы используем для аутентификации в брокерах Kafka. Также нужно настроить пароль для хранилища ключей и пароль для закрытого ключа в этом хранилище.

Также можно подключиться к кластерам из облачных сервисов (например, Amazon), но об этом рекомендую почитать в документации OE (в разделе с подключениями).
Чтобы убедится, что мы все верно сконфигурировали, нажмем кнопку Test для проверки подключения. Если соединение проходит — клацаем кнопку Add для добавления свежесозданного подключения.
У нас добавился кластер pylounge. Чтобы подключиться к нему, вызовем контекстное меню и выберем пункт Connect. В этом же контекстном меню можно: отключиться, переподключиться, удалить подключение, клонировать его или экспортировать.

Как только индикатор рядом с именем кластера загорелся зелёным, значит, мы успешно подключились и можем приступать к работе.

Основные элементы
В левой панели есть три основных раздела: Брокеры (Brokers), Топики (Topics) и Потребители (Consumers).
Кластер Kafka состоит из брокеров. По сути это набор узлов с запущенной Kafka и сконфигурированных определенным образом. Все брокеры соединены друг с другом сетью и действуют сообща, образуя единый кластер.
Кликнув на каталог Brokers, можно посмотреть список брокеров. Видим, что в нашем кластере всего один брокер с id=1 с хостом localhost и работающий на порту 9092.

Также можно выбрать брокер отдельно и посмотреть информацию о нем (увидим примерно то же самое).

Выбрав каталог Topics, увидим список топиков нашего кластера (доступен поиск). Здесь можно создавать и удалять топики.

Можно выбрать конкретный топик и посмотреть более детальную информацию о нем. Так, во вкладке Properties видно имя топика (Topic Name) и есть выбор формата отображения сообщений (для привычного вида выбираем тип String для свойств Key и Value). Также мы видим количество сообщений в топике Total number of messages — в нашем случае в pylounge.videos есть четыре сообщения.

На вкладке Config можно редактировать настройки (свойства) топика: политику хранения сообщений, максимальный размер сообщений и т.д.

На вкладке Data видно содержимое топика. Чтобы получить список сообщений, необходимо нажать на кнопку в виде проигрывателя с зелёной стрелочкой ().
После извлечения записей можно просмотреть следующую информацию о каждом сообщении:
Смещение (offset) — информация о смещении
Ключ (Key) — ключ сообщения
Значение (Value) — значение сообщения
Временная метка — когда сообщение было добавлено
Заголовки — данные заголовка

Кроме того, данные ключей и значений можно просматривать в формате JSON и XML. Эти данные можно увидеть, получив сообщения и щелкнув по одному из них. За выбор формата отвечает параметр View Data AS — Text, Hex, JSON, XML.

Мы можем отфильтровать сообщения (поле Filter), которые отображаются в данный момент (на уровне топика или партиции), что позволяет найти конкретное сообщение с помощью следующих параметров фильтрации:
Оффсет (Смещение) — если щелкнуть этот параметр, то фильтр покажет все сообщения, у которых в смещении указан фильтр
Key (Ключ) — если щелкнуть этот параметр, фильтр покажет все сообщения, в которых фильтр введен в ключевые данные
Value (Значение) — при щелчке на этой опции фильтр покажет все сообщения, в которых фильтр введен в данные значения
Header Key (Ключ заголовка) — если щелкнуть эту опцию, фильтр покажет все сообщения, в которых фильтр введен в данные ключа заголовка
Header Value (Значение заголовка) — при нажатии на эту опцию фильтр покажет все сообщения, в которых фильтр введен в данные значения заголовка
Regex — поиск с использованием регулярных выражений

Также можно задать порядок сортировки сообщений — сначала новые (Newest) или сначала старые (Oldest).

Кроме того, сортировку (по возрастанию или убыванию значения) можно задать по любому из столбцов — необходимо лишь кликнуть на заголовок столбца

Также мы можем указать, сколько сообщений хотим отобразить — поле Max Messages в правом нижнем углу. По умолчанию отображаем 100 сообщений.

Вкладка Partitions отвечает за информацию о партициях топика. Партиции задаются при создании топика. У нашего топика всего одна партиция на localhost:9092.

В самой партиции можно узнать ее номер, на каком брокере расположен лидер, а также посмотреть оффсеты — начальный (Start), конечный (End) и сколько сообщений в этой партиции (Size). Там мы видим, что начальный оффсет 0, конечный 4, и у нас в этой партиции всего 4 сообщения.

Вкладка Replicas показывает реплики каждой партиции. У нас она всего одна на localhost:9092 в режиме In-Sync.

Во вкладке Data можно просматривать сообщения из этой партиции и добавлять конкретно в нее новые (по аналогии со вкладкой Data у топика).

Вкладка потребители (Consumers) отображает группы потребителей — приложений, которые читают сообщения из топиков Kafka.
На данный момент список потребителей пуст, из OE такую группу потребителей создать нельзя. Consumer group создастся автоматически, когда приложение начнет читать данные из Kafka. Поэтому, чтобы добавить новую группу, нужно создать небольшое приложение (consumer) для чтения топика и настроить consumer так, чтобы он использовал некоторый group.id
Для этого установим библиотеку kafka-python
python pip install kafka-pythonЗатем создадим файл consumer.py и добавим туда следующий код:
from kafka import KafkaConsumer
# Настройка консумера
consumer = KafkaConsumer(
'pylounge.videos', # Имя топика
bootstrap_servers=['localhost:9092'], # Адрес Kafka-брокера
auto_offset_reset='earliest', # Считывать сообщения с самого начала, если оффсет не найден
enable_auto_commit=True, # Автоматически коммитить оффсет
group_id='consumer-from-python-app', # Идентификатор группы консумеров
value_deserializer=lambda x: x.decode('utf-8') # Десериализация значений сообщений
)
print("Starting the consumer...")
# Чтение сообщений из топика
try:
for message in consumer:
print(f"Received message: {message.value}")
except KeyboardInterrupt:
print("Stopping the consumer...")
finally:
consumer.close()Теперь запустим своего consumer с заданным group.id, и он появится в списке consumer groups в Offset Explorer
python manage.py consume.pyПосле запуска увидим следующие сообщения:
Starting the consumer...
Received message: django
Received message: fastapi
Received message: litestarЕсли переключиться на каталог с потребителями, то увидим список всех consumer group с указанием их активности

Если выбрать определённого консумера, то на вкладке Properties увидим общую информацию — id, активность, тип консумера и где хранится его offset

На вкладке Offsets видно, какой топик читает этот консумер и докуда он его прочитал. Сейчас стоит Offset 5 — значит, консумер прочитал все сообщения (потому что End = 4).
Lag — это разница между офсетом, до которого дочитал консумер и последним офсетом в топике. То есть это дает нам понять, сколько сообщений потребитель НЕ дочитал до конца топика. В нашем случаем lag = 0, значит, консумер прочитал все сообщения из топика.

Создание нового топика
Чтобы создать новый топик, можно либо перейти в папку Topics и воспользоваться кнопкой Add New Topic (иконка зеленый плюс на панели инструментов), либо воспользоваться пунктом меню Create topic (щелкните правой кнопкой мыши по каталогу Topics). В диалоговом окне Add topic необходимо указать следующие значения в разделе General:
Имя — имя, которое вы хотите дать топику
Partition Count — количество партиций в топике
Replica Count — количество реплик для каждой партиции в топике.
Давайте создадим топик flats, в который будут приходить сообщения о квартирах. Сразу укажем свойства cleanup.policy (политику хранения старых сообщений, delete — будет удалять старые сегменты, когда будет достигнуто их время хранения или предельный размер) и retention.ms (максимальное время хранения, прежде чем мы будем удалять старые сегменты, чтобы освободить место). Свойства добавляются в раздел Configs с помощью кнопки Add.
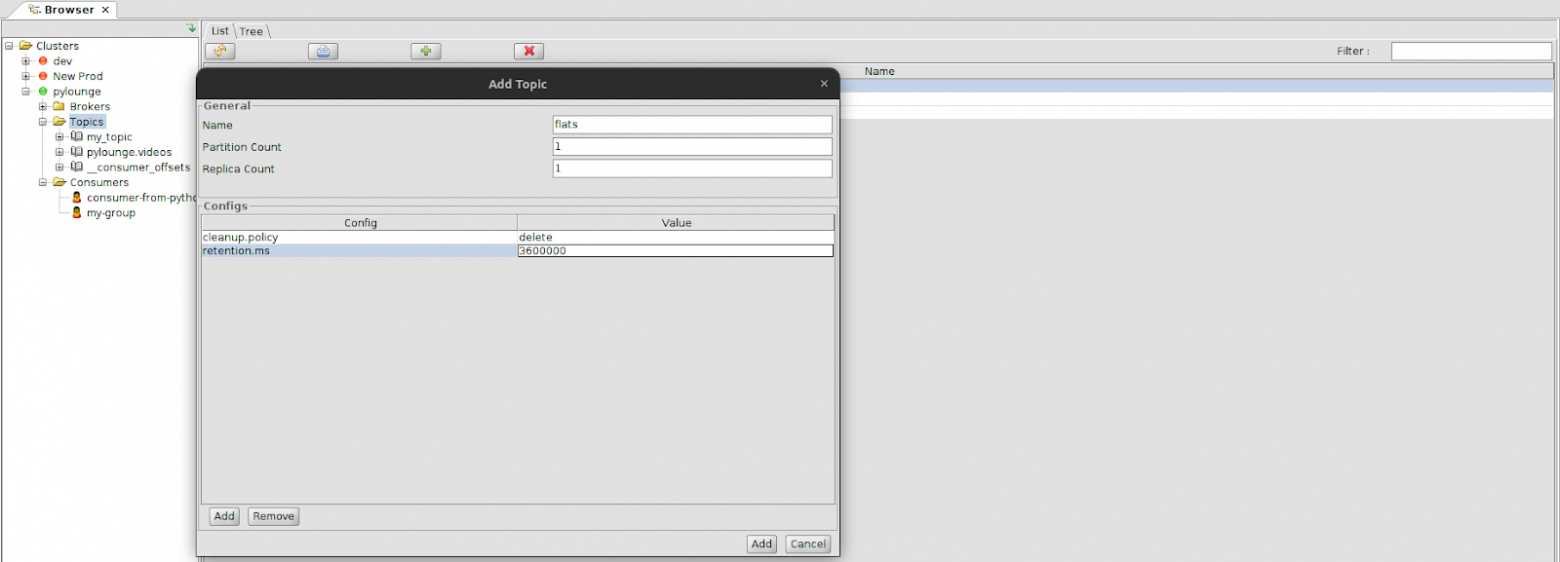
После создания топика она добавится в каталог Topics.
Давайте сразу перейдем в этот топик и заменим key и value на тип строки String, чтобы мы могли отправлять и смотреть сообщения в формате обычных строк (в конце не забываем нажимать кнопку Update).

Добавление сообщения в топик через OE
Мы будем добавлять несколько сообщений похожего вида в формате JSON. Каждое сообщение описывает одну квартиру:
{
"id": "d4e4a1f0-fd3e-4e3c-bd0a-f6d0f97c7e01",
"description": "Уютная двухкомнатная квартира в центре города. Просторная гостиная, полностью оборудованная кухня, балкон с видом на парк.",
"location": "Москва, ул. Арбат, д. 12",
"price": 75000,
"rooms": 2,
"area": 65,
"floor": 5,
"amenities": ["Wi-Fi", "Кондиционер", "Стиральная машина"]
}
{
"id": "f3e7117b-7b5b-4c7b-9398-73f03f9a6d4c",
"description": "Однокомнатная квартира с современным ремонтом в новостройке. Панорамные окна, хорошая инфраструктура, близость к метро.",
"location": "Санкт-Петербург, пр. Энгельса, д. 45",
"price": 55000,
"rooms": 1,
"area": 40,
"floor": 10,
"amenities": ["Парковка", "Домофон", "Холодильник"]
}
{
"id": "a9b8e8b2-3d56-4b3c-bf8b-8e4c8b6f9cfa",
"description": "Трехкомнатная квартира с отличным ремонтом в тихом районе. Две спальни, просторная гостиная, две ванные комнаты.",
"location": "Новосибирск, ул. Достоевского, д. 18",
"price": 85000,
"rooms": 3,
"area": 90,
"floor": 3,
"amenities": ["Лифт", "Балкон", "Подогрев пола"]
}Чтобы добавить сообщение в топик, необходимо выбрать нужную партицию (в нашем случае Partition 0) и перейти на вкладку Data. Там через элемент управление с иконкой «зеленого знака плюс» мы можем добавить одно или несколько сообщений. Выберем одно сообщение — Add Single Message

В окне добавления для Key и Value выставляем загрузку сообщения в ручном режиме (не из файла) — Enter Manually [Text].
Само тело сообщения копируем в блок Value, в качестве ключа сообщения будем использовать id квартиры — его и добавим в поле Key. Теперь нажмем Add. По аналогии добавим еще два сообщения.

Просмотр сообщений в топике и фильтрация
Чтобы увидеть переданные сообщения, кликаем на сам топик (чтобы мы видели сообщения из всех партиций, а не только из нулевой), переходим на вкладку Data, выставляем Max Messages (можно оставить по умолчанию 100) и нажимаем на иконку «зеленого проигрывателя» — Retrieve Messages. После того, как сообщения отобразились, можно дополнительно кликнуть на заголовок Timestamp, чтобы отсортировать сообщения по времени отправки.

Кликнем на любую ячейку в столбце Value, чтобы посмотреть само сообщение. Не забудем в выпадающем списке View Data As выбрать формат отображения JSON.

Мы можем сохранить это сообщение в файл, нажав на иконку с сохранения (дискета).

Также можно отфильтровать сообщения по ключу. Например, я хочу увидеть все сообщения у которых id = d4e4a1f0-fd3e-4e3c-bd0a-f6d0f97c7e01. Тогда нужно в поле Filter вставить этот id:

Если мне нужны квартиры в описании которых есть слово «Новосибирск», то я тоже укажу это в фильтрах.

Как перечитывать топики Kafka
Допустим, производитель (producer) отправил нам в топик тысячу сообщений. Наше приложение их прочитало, но не смогло сохранить в базу данных поскольку в коде приложение была ошибка. Через какое-то время мы фиксим баг, и нам снова нужно прочитать эту тысячу сообщений из топика, чтобы записать их в БД.
У нас есть два варианта, как это сделать:
Заставить производителя ещё раз отправить эти же сообщения (что не всегда возможно).
Перечитать сообщения из топика.
Когда консумер читает топик, у него выставляется определенный оффсет, который указывает, до какого сообщения в топике он дочитал. Чтобы перечитать сообщения из топика, можно искусственно (ручками) сдвинуть этот офсет назад. Тогда консумер решит, что он дочитал только до офсета, который выставили мы, и будет заново пытаться прочитать все сообщения, которые идут после установленного нами офсета.
Чтобы обновить офсеты через offset explorer, нужно выбрать раздел consumers, найти нашего консумера consumer-from-pylounge-app (или другой нужный). Затем выбрать нужные топики и задать офсеты (нажать Edit Consumer Offset, установить поле Offset), нажать Update.
Перед тем как делать перечитку, надо отключить все сервисы-консумеры. А после того как офсет сдвинут, включить их обратно.
Сейчас в топике flats всего три сообщения. Офсет начала 0, последний офсет 3:

Наш консумер прочитал все эти сообщения — офсет 3, лаг — 0

Допустим, мы хотим, чтобы консумер заново прочитал сообщения из топика flats, но не все, а пропустил первое сообщение.
Для этого нам нужно:
Выключить на этом время консумера.
Для нужного топика нужного консумера нажимаем Edit consumer offset.

3. Выставляем офсет на 1 (так как самое первое сообщение имеет офсет 0, его пропускаем). Затем нажимаем Update.
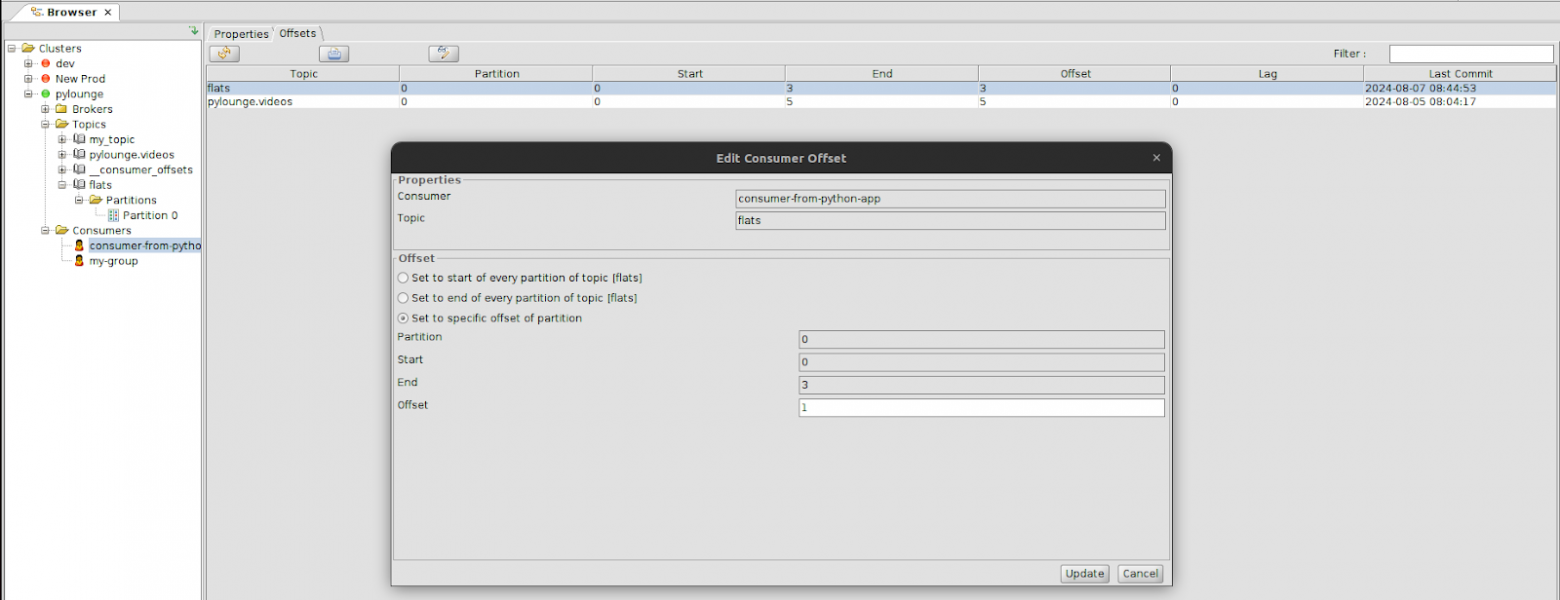
4. Проверяем, что текущий офсет для этого топика стал 1. Заметим, что lag стал равен 2.
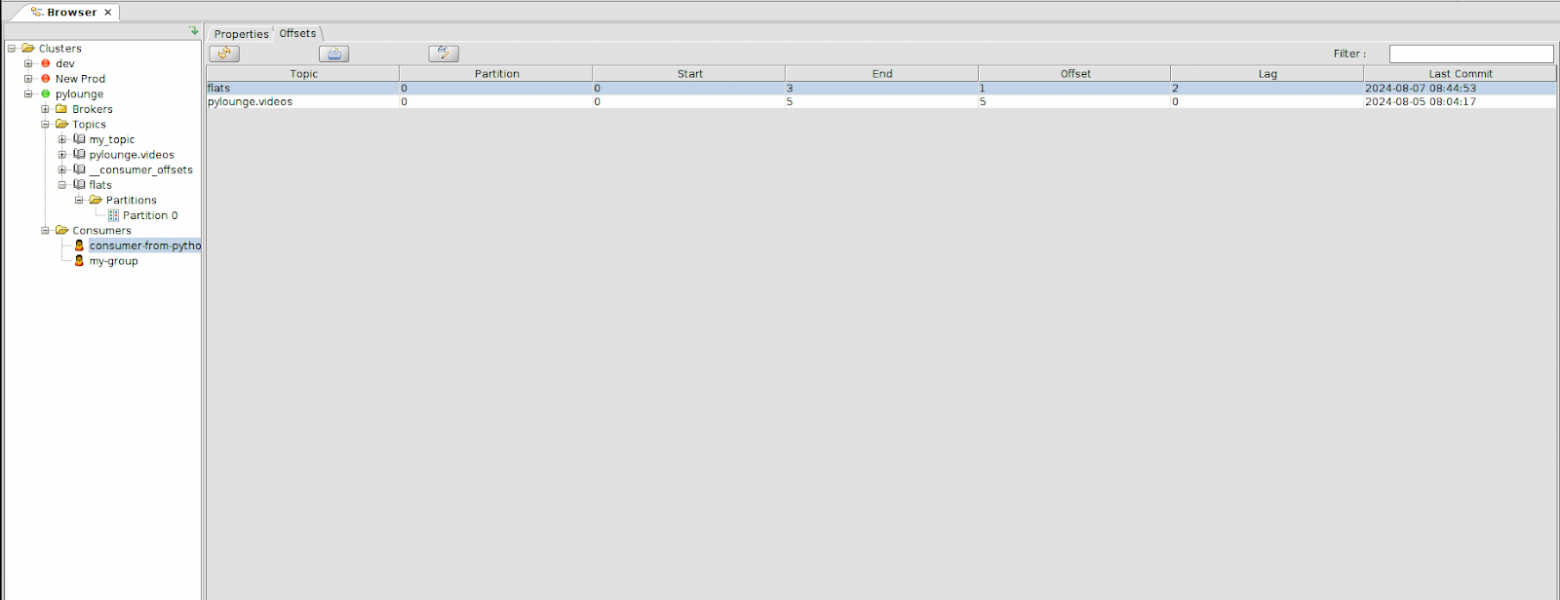
5. Запускаем консумера python consumer.py
Видим, что наше приложение ещё раз прочитало второе и третье сообщение. Значит, мы успешно перечитали топик кафки с офсета 1!

Импорт экспорт
Инструмент экспорта позволяет экспортировать данные из топиков в различные файлы. Когда мы открыли инструмент экспорта и выбрали топик для экспорта, необходимо выполнить несколько действий, чтобы экспорт прошел успешно:
Выбрать директории, куда сохраним файлы
Поставить формат шаблона имен ключевых файлов
Затем — формат имени файла значений
Не забудем о количестве сообщений в каждом разделе, которые мы хотим экспортировать
Партиции — выбираем, какие партиции в топике мы хотим включить в экспорт

Сначала нам предложат выбрать топик, из которого мы хотим экспортировать данные:

Затем укажем директорию для экспорта, что конкретно экспортировать из топика (в данном случае мне нужны и ключи, и значения сообщений), сколько сообщений и из каких партиций. Нажмем Next.

За 102 мс экспорт завершился.

Инструмент импорта позволяет импортировать данные в топик. После выбора топика для импорта данных необходимо выполнить несколько действий, чтобы импорт прошел успешно.
Исходный каталог — выбираем папку с импортируемыми данными
Формат шаблона имени ключевого файла
Формат имени файла значений
Топики — выбираем, в какую партицию (партиции) топика необходимо импортировать данные
Порядок действий аналогичен экспорту:

Также можно экспортировать конфиг для подключения к кластеру. Для этого кликнем по название кластера и в контекстном меню выбираем Export Connection.

Выбираем файл, куда сохранить конфигурацию (не забудем вписать название файла, а не только выбрать каталог).

В итоге получим xml-файл с конфигом для подключения.

Импортировать подключение из конфига можно с помощью пункта Import Connection директории с кластерами:

Плагины
Offset Explorer поддерживает пользовательские плагины на языке Java. Они позволяют просматривать сообщения, которые не понимает Offset Explorer, в формате, который мы сочтем нужным.
Пример написания плагина находится в папке plugins/example в каталоге установки Offset Explorer.
За подробностями — в официальную документацию.
Альтернативы OE
В качестве альтернативы Offset Explorer выступают и пользуются популярностью еще два инструмента:
Kafka-UI — https://github.com/provectus/kafka-ui
AKHQ — https://akhq.io/
Kafka-UI выглядит стильно, модно, молодежно, но лично я ей не пользовался, поэтому ничего не могу особо сказать. Но, возможно, вам она понравится больше.

Чуть чаще в компании мы используем AKHQ.

В качестве бонуса поделюсь инструкцией по запуску:
Создаем директорию akhq
В этой директории создаем файл docker-compose.yml со следующим содержимым:
version: '3.6'
services:
akhq:
image: tchiotludo/akhq
restart: always
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "localhost:9092"
ports:
- 9000:8080(bootstrap.servers — адрес и порт на котором живет кластер Kafka)
3. Запускаем с помощью команды docker compose up
4. Переходим в строке браузера по адресу localhost:9000
5. Наслаждаемся результатом.
Заключение
Offest Explorer — удобный графический инструмент для работы с Kafka, у которого все же есть альтернативы. Выбирайте то, что вам удобнее, я же показал то, чем сам пользуюсь в 99% случаев на работе. Надеюсь, вам было полезно и интересно.
Если есть что добавить или я где-то ошибся, милости прошу в комментарии :) Давайте сделаем этот материал лучше, чтобы он точно стал хорошим подспорьем для всех начинающих.
А каким инструментом для работы с Kafka пользуетесь вы? Может Kafka CLI? :)
Источники
https://habr.com/ru/companies/piter/articles/352978/
https://offsetexplorer.com/documentation/docindex.html
https://www.baeldung.com/apache-kafka
https://habr.com/ru/companies/nsd/articles/661007/
https://www.baeldung.com/java-kafka-consumer-lag
