Проекты школы GoTo: рекомендательная система для новостного портала

В рамках каждой школы школы GoTo происходит много активностей, школьниками реализуются десятки удачных и не очень проектов. К сожалению, нам не удается рассказать о каждом проекте или происшествии, но попытаться поделиться отдельными успехами стоит. Поэтому мы и начинаем цикл статей от учеников о своих успехах и проектах в рамках наших школ.
Этим летом один из партнёров — компания E-Contenta — предложила задачу создания рекомендательной системы новостного портала одного из телеканалов. Ребята из компании преподавали на направлении Анализ данных и машинное обучение, да и задача всем показалась довольно интересной — помимо реальной необходимости такого рода разработок, задача была еще и довольно уникальной — методы рекомендации новостей в большинстве отличаются от методов рекомендации, допустим, фильмов.
За её решение взялись 2 ученика июньской школы: 16-летний Творожков Андрей из Москвы и 14-летний Всеволод Жидков из Воткинска. Они же и подготовили краткое описание задачи и ее решения, которое мы публикуем в этой статье под катом.
Описание задачи
Рекомендательная система — это программа, позволяющая предсказать наиболее интересные объекты (например, книги, фильмы или статьи), уже имея какие-то данные о текущем состоянии. Состоянием могут быть уже понравившееся пользователю объекты или данные, которые мы знаем о клиенте (например, его музыкальные предпочтения). Такие данные можно без труда получить с помощью логирования действий пользователя на сайте, собиранием внешней информации о пользователе или об объекте.
Основная задача, которую решает рекомендательная система — это повышение удобства использования продукта конечному пользователю. Мы должны предсказать, что пользователю понравится с наибольшей вероятностью и тогда он будет избавлен от необходимости искать это самому, что позволит нам удержать пользователя на нашем ресурсе. Благодаря качественным рекомендательным системам выросли такие цифровые гиганты как Netflix, Spotify и многие другие стартапы.
Среди рекомендательных систем выделяются три основных типа: коллаборативная фильтрация, контетная и гибридная.
Коллаборативная фильтрация — наверное, наиболее популярная модель для рекомендации объектов. Её основная идея заключается в том, что если объекты смотрят почти одинаковые пользователи, то эти объекты стоит рекомендовать этим пользователям.

Например, если некой Алисе нравится сериалы «Друзья» и «Теория Большого Взрыва», а некому Бобу нравятся «Бруклин 9–9» и «Друзья», то можно порекомендовать «Бруклин 9–9» Алисе и «Теорию Большого Взрыва» Бобу.
В коллаборативной фильтрации выделяется два основных подхода:
- Корреляционные модели — основная идея таких моделий основана на хранении матрицы пользователей/объектов.
- Латентные модели — модели, которые позволяют не держать матрицу пользователей/объектов, а строятся на основе 'профилей' пользователей и объектов. Профиль — это вектор скрытых характеристик.
Следующий способ построения рекомендательной модели — контетные рекомендации. Это значит, что наша модель будет зависеть от содержимого объектов. Например, можно оценивать похожесть текстов новостей (о том, как именно этот делать — чуть позже) или к фильму «Титаник» рекомендовать другие фильмы Кэмерона. Главная идея этого метода заключается в том, что мы пытаемся достать как можно большую информацию об объекте, который мы хотим порекомендовать, и используем эту информацию для поиска таких же объектов, после чего мы просто рекомендуем похожие объекты.
RTB на ужин от CTO E-Contenta

Коллективное творчество

Испытания на прочность

Преодоление трудностей

Столкновение с реальностью на примере игры Пальчики

Выживают сильнейшие

Сжигание багов напоследок
Решение
В нашей задаче по рекомендации новостей мы решили использовать гибридную модель. Она комбинирует результаты предыдущих вариантов и возвращает взвешенный результат.
Наша гибридная модель на основе признаков, которые мы вытащили для объекта и для пользователя возвращает вероятность того, что пользователь прочитает эту статью (кликнет на неё). После нескольких тестов, в качестве алгоритма машинного обучения мы решили использовать Random Forest, но это не так принципиально.
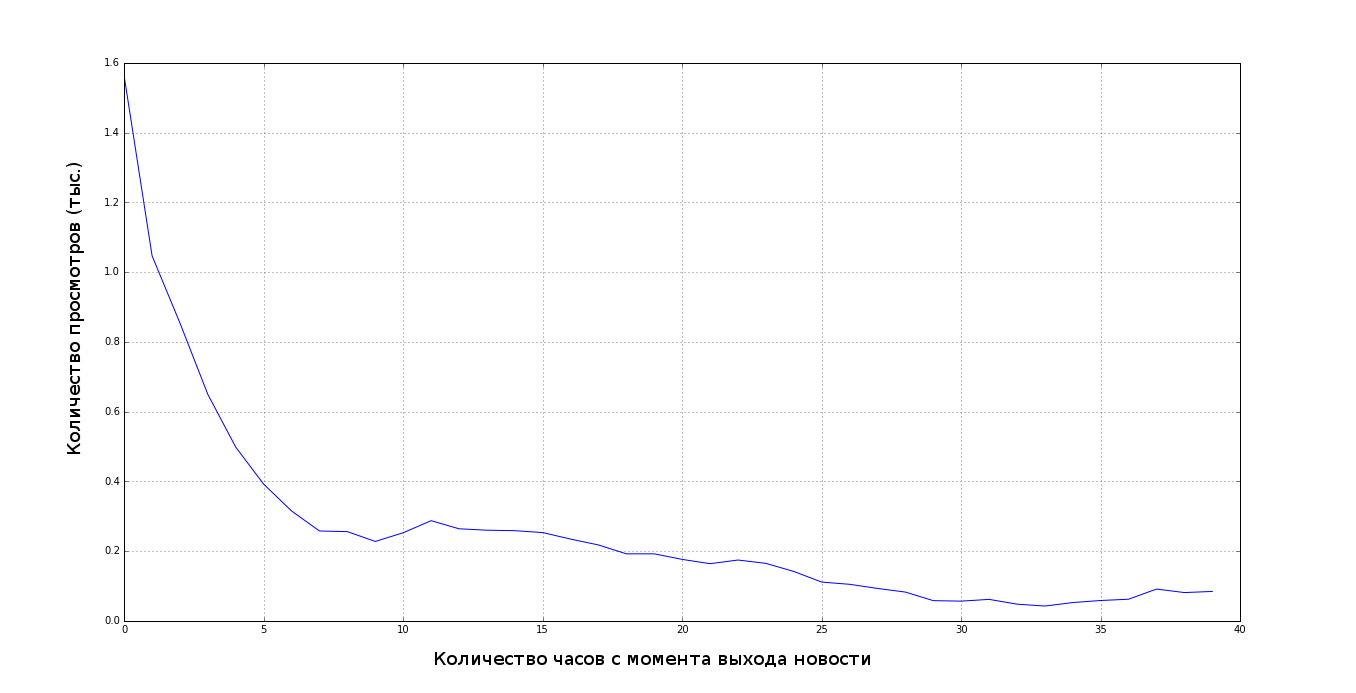
Во всех задачах машинного обучения важно посмотреть на распределение данных, построить зависимости, которые помогут тебе обучить модель, без этого хорошего результата получить вы не сможете. Например, в нашей задаче прежде чем написать модель мы построили вот такой график:
Суть гибридной модели в том, что в качестве фичей мы предоставляем ей какие-то значения, полученные с помощью коллаборативной фильтрации и какие-то значения, полученные с помощью контентной модели.
Начнем с коллаборативной фильтрации. Давайте будем вычислять похожесть новостей по пользователям, которые смотрели эту статью. Для этого часто используется косинусная мера — косинус угла между двумя векторами, в данном случае — просмотрами пользователей.

Так как мы хотим, чтобы при рекомендациях учитывалась не только одна новость, возьмем три последние статьи и одну возможную (вероятность перехода на которую мы оцениваем), после чего посчитаем косинусную похожесть от каждой из прочитанных новостей к возможной. Таким образом у нас получится 3 фичи.
Теперь есть более сложная задача — оценивать похожесть новостей по их содержимому. Мы отмели самые простые варианты вроде поиска ключевых слов и подсчета их пересечений из-за маленькой эффективности.
В области построения контентных моделей отдельно стоит тематическое моделирование — способ разбиения документов по темам без учителя. Для этого существует несколько алгоритмов, в нашей системе мы использовали NMF — разложение неотрицательных матриц, она показала себя лучше чем LDA — латентное размещение Дирихле. Перед тем, как использовать NMF, нам необходимо построить матрицу, которую мы будем раскладывать, для этого использовали TF-IDF.
TF-IDF состоит из двух частей:
TF (term frequency — частота слова) — это отношение количеству данного слова в документе к количеству слов в данном документе. С помощью term frequency можно оценить важность слова в документе. Заметим, что частота так называемых стоп слов — союзы и союзные слова, местоимения, предлоги, частицы и т.д.) будет больше чем других, поэтому мы очистили все новости от них.

IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. С помощью IDF мы можем выбросить не только стоп слова, но и понижать важность для часто употребляемых существительных.

Поскольку нам важно знать и важность слова в тексте и уникальность мы перемножаем TF-IDF и получаем:

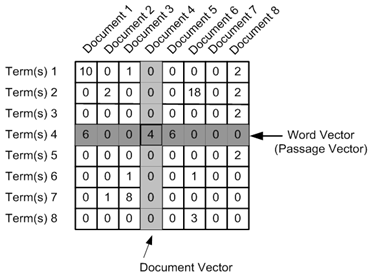
С помощью TF-IDF мы создаём матрицу документы на слова, на пересечении документа и слова мы ставим значение полученное из TF-IDF:
Получив терм-документную матрицу мы раскладываем её по сингулярным значениям с помощью NMF. После разложения матрицы мы можем представить любой документ и термин в виде вектора в пространстве, близость между любой комбинацией терминов и/или документов легко вычисляется с помощью скалярного произведения векторов. После всего этого мы получили вполне осмысленные темы, например, в один кластер попали статьи про Савченко, в другой — про законы, которые предлагает Госдума.
При помощи градиентного спуска мы нашли оптимальное значение количества кластеров для наших данных, оно равно 40. После преобразований мы можем рассматривать каждую новость как точку в 40-мерном пространстве, где каждое измерение — это степень принадлежности к какому-то кластеру.
А в качестве фичей можем использовать 40 значений для каждой из четырех новостей. Кроме того, можно заняться feature engineering и добавить разность каждой прочитанной статьи с возможной, но этого мы не сделали.
В результате у нас получилась модель, предсказания которой нас устраивали. Например, мы прочитали несколько новостей о возможном назначении кого-нибудь на должность советника Президента, сразу после этого рекомендательная система выдаёт нам статьи уже с конкретными именами кандидатов.
Метрика качества
Тем не менее, хоть мы и видели, что рекомендуются статьи вполне логично, было необходимо посчитать метрику качества рекомендаций. Самой распространённой метрикой является MAP@K, где K — количество рекомендаций. В нашей задаче пользователю за раз рекомендуется 10 статей, поэтому и K = 10. Метрика позволяет нам узнать, насколько быстро мы дали пользователю то, что он хочет, в нашем случае — как быстро мы порекомендовали статью, которую пользователь на самом деле прочитал.
В итоге MAP@10 для нашей конечной модели составил 0.75, а для самой первой модели — 0.05. Наш результат оказался вполне годным, это показала и метрика, и проверка на глаз.
После того, как мы закончили делать рекомендательную систему, мы собрали веб-приложение, с помощью которого вы можете сами оценить ее работу. Его исходники доступны на Github.
За время работы на проектом, мы заметили важную особенность подобных рекомендательных систем: они очень часто загоняют пользователей в ловушку статей на одну и ту же тему, поэтому стоит предусмотреть включения случайных статей, чтобы попробовать найти другие тему, интересные пользователю.
Что в итоге?
Результаты были высоко оценены преподавателями и использованы компанией E-Contenta для дальнейшей работы над проектом заказчика, а ребята приглашены на стажировку для решения новых задач.
Мы же, в свою очередь, очень рады, что многие компании участвуют в образовательном процессе и постановке задач участникам наших школ.
Ближайшие активности
Этой осенью состоится школа для старшеклассников и младшекурсников в бизнес-инкубаторе Ингрия при участии Jetbrains, КРОК, Intel, Института биоинформатики, BIOCAD, Parseq Lab, Одноклассники и других компаний.
Это наша первая школа в СПб. Участники займутся не только анализом данных и биоинформатикой, но и интернетом вещей с разработкой мобильных приложений, чат-ботов и веб-сервисов. У всех желающих есть возможность выиграть гранты на бесплатное обучение по направлениям Биоинформатика и Анализ данных, приняв участие в конкурсах GoTo Challenge до 20 октября — реализовав геномную сборку или тематический классификатор web-страниц.
Приглашаем экспертов к участию в роли менторов и преподавателей, особенно рады стартапам, которые готовы поделиться задачами с ребятами.
Также скоро расскажем о втором хакатоне GoToHack по анализу данных, в этот раз он посвящен сфере образования и HR. Обратите внимание, что уже стартовал онлайн-этап с заданиями на Kaggle на основе реальных данных по прохождению учениками онлайн-курсов платформы Stepik.org.
