Процессор Forth J1 в FPGA плате M02mini

Впервые я познакомился с языком программирования Forth еще в студенческие годы. Было это правда ну очень давно. Уже тогда язык поразил меня тем, что он «не такой как все». При этом, код получался хоть и малопонятный, но компактный и быстрый.
Недавно я занимался запуском процессора Forth j1 в FPGA плате и пришлось вспоминать фортовские азы программирования. Да уж… чертовски трудно, но получил громадное эстетическое удовольствие. Как будто впервые взял кубик Рубика, и сам собрал его, и пазл сложился и программа работает…
Что же такого особенного в языке Forth?
Мне показалось, что главное правило языка Forth — никаких правил. Программист полностью определяет поведение всей системы, структуру памяти, структуру программы и данных и определяет набор слов, которые живут и работают в системе. Я бы сказал, что язык Forth чуть-чуть более высокоуровневый, чем ассемблер. Есть только базовый набор слов, которые могут выполнять какие-то основные вещи вроде арифметических или логических операций и переходов. Новые слова программист определяет сам на основе уже существующих слов. Операнды лежат на стеке и результат выполнения операции так же кладется на стек.
Например, можно в консоли интерпретатора языка Forth ввести: > 1 2 + .
Здесь интерпретатор из последовательности символов возьмет строку »1», преобразует в число 1, положит на стек данных, потом возьмет строку »2», преобразует в число 2, положит на стек данных. Далее возьмет строку »+» и, поскольку она не преобразуется в число, то попробует найти ее в словаре известных слов. Найдет в словаре слово »+» и выполнит связанное с этим словом действие, суммирование двух чисел на стеке. При этом, два числа со стека будут сняты, но взамен будет положен результат число 3. И снова интерпретатор ищет слова во входном потоке, найдет следующее слово ».», а это слово снимает число со стека и печатает его в консоль.
Теперь программист может определить для себя совершенно новое слово вот так: > : 2+ 2 + ;
Новое определенное слово будет »2+», а делать оно будет «прибавление 2».
После этого повсеместно можно применять новое определенное слово »2+»: > 1 2+ .
Напечатает результат число 3.
Расскажу немного о FPGA проекте. Каждый разработчик FPGA однажды сталкивается с необходимостью выполнять часть логики с помощью обычных последовательных программ. Существует огромное количество софт процессоров. Да и сами производители ПЛИС активно продвигают свои собственные ядра. Intel, например, рекомендует NIOS. Xilinx дает своим пользователям MicroBlaze Soft Processor Core. Каждое ядро занимает драгоценное место в FPGA. Я тогда подумал, а может нужен Forth процессор, он же довольно простой должен быть?
Тогда я обнаружил для себя, что Forth процессоры люди уже вполне делали!
Мне нужно только портировать на свою плату и посмотреть, как он работает. Тогда можно будет оценить и быстродействие и необходимые ресурсы для его реализации в ПЛИС.
Исходный проект форта для ПЛИС обнаружился на github.com.
Я портировал этот проект для платы Марсоход3 и платы M02mini. Плата M02mini — самая маленькая из известных мне FPGA плат. На ней стоит крошечная, буквально 3 миллиметра FPGA Intel MAX10 с двумя тысячами логических элементов. Тем более было интересно, получится ли в такой крохе запустить хоть какой-то софт процессор. Вот так выглядит плата: 
Тут же на плате есть двухпортовая микросхема FTDI, которая используется и как JTAG программатор и как последовательных порт к ПЛИС. Микросхема FTDI гораздо больше самой ПЛИС.
Структура процессора J1 очень простая: 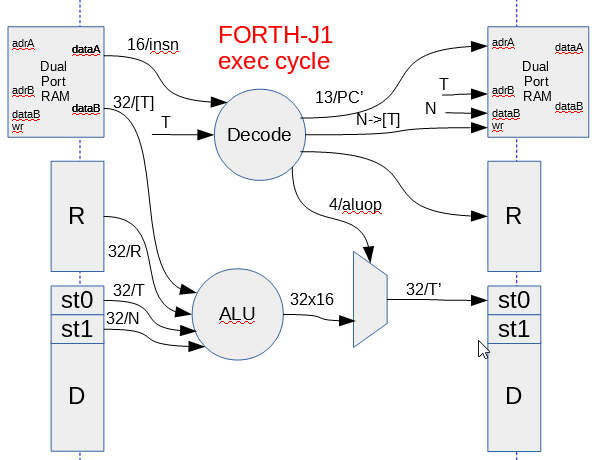
Имеется два не очень глубоких стека: стек данных и стек возвратов, по 16 слов. При желании, конечно можно стек сделать глубже. Программа, как и данные находятся в двухпортовом RAM с тем намерением, чтобы можно было одновременно за такт процессора выбирать следующую инструкцию на исполнение и тут же читать или писать в ОЗУ данные. Подразумевается исполнение одной инструкции за один такт. При этом различные поля инструкции одновременно отвечают за исполнение команд в АЛУ и приращение или уменьшение указателей стека данных и стеков возврата: 
Я бы сказал, что кодирование команд не очень плотное, но дело в том, что последующие слова определяются через предыдущие, вот тут и происходит магия. Итоговый «шитый код» получается очень компактным.
Несмотря на то, что инструкции 16ти разрядные, сам процессор 32х разрядный. Интересно, что числовые константы в инструкцию кодируются если её старший бит находится в единице. Понятно, что диапазон возможных значений не очень широкий. Если потребуется большее значение числа, то его придется вычислять с помощью сдвигов и логических операций. Кодирование команд процессора выглядит так: 
Очень хочется поделиться своей программой на Forth, это мой простейший интерпретатор. В Форте все пишется на Форте, в том числе и интерпретатор и компилятор и кросс-компилятор. Используется gforth, в котором запускается фортовская программа кросс-компилятор cross.fs, которая принимает определения новых базовых слов, тех которые по сути ассемблерные команды basewords.fs, для целевой системы. Дальше программа cross.fs включает в себя собственно реальную программу target.fs, которую мы хотим запустить в FPGA на Forth процессоре: > gforth cross.fs basewords.fs target.fs
В результате исполнения этих Форт программ получится листинг, бинарный файл образа программы, и MIF файл для инициализации памяти в ПЛИС.
Моя программа интерпретатора выглядит вот так:
: main
2drop
begin \ начало вечного цикла
tib d# 80 accept cr \ строка из консоли записывается в tib
\ (text input buffer) длиной 80 байт
tib# ! \ длина принятой из консоли строки
\ записывается в переменную tib#
d# 0 >in ! \ изначально разбор строки начинается с
\ нулевого символа, запишем 0 в переменную >in
begin \ начнем поиск всех слов в принятой строке
parse-name \ возьмем из tib слова по очереди, на стеке
\ останется адрес строки и длина строки, "name" -- c-addr u
dup \ возьмем на стек длину слова еще раз, на стеке c-addr u u
while \ зайдем в обработку слова, если его длина не ноль
2dup d# 0. 2swap >number \ попробуем преобразовать строку в число
0= \ если в строке не осталось символов,
\ значит была строка-число
if
2drop \ удалим лишнее со стека
rot rot 2drop \ оставим на стеке только полученное
\ число и сверху адрес строки с длиной
else
drop 2drop \ было не число, так что удалим
\ лишние данные со стека
sfind \ попробуем найти слово в словаре
if
execute \ исполним найденное слово
else
drop \ слово не найдено в словаре, удалим лишний элемент со стека
space msg-unkn print-str \ напечатаем сообщение об ошибке
then
then
repeat
2drop \ удалим адрес последней строки и ее длину (нулевую) со стека
again \ к началу вечного цикла
;
Я постарался в комментариях объяснить происходящее.
Некоторые простые слова легко объяснить:
dup — повторно кладет на стек верхнее число, w — w w
2dup — повторно кладет два верхних числа, w1 w2 — w1 w2 w1 w2
аналогично
drop — сбрасывает со стека верхнее число, w —
2drop — сбрасывает 2 верхних числа, w1 w2 —
2swap — меняет местами две пары верхних чисел на стеке, w1 w2 w3 w4 — w3 4 w1 w2
rot — достает третье сверху число, w1 w2 w3 — w2 w3 w1
d# — кладет на стек десятичное число, которое написано сразу после d#
Более сложные слова и комбинации begin — again, if — else — then определяют переходы и условные переходы.
Некоторые из других сложных слов:
sfine — ищет слово в словаре,
execute — исполняет найденное слово.
space — печатает пробел,
print-str — печатает строку…
Еще раз повторю, что этот мой интерпретатор очень примитивный в том смысле, что с его помощью нельзя определять новые слова из консоли. Но и это, конечно, при желании возможно. В своей работе мне хотелось получить консольный Форт — и я его в принципе получил:
На видео демонстрации выше показано исполнение простых слов языка Forth в FPGA плате M02mini (Intel MAX10, 2K LE). Команды печатаются к консоли Putty через последовательный порт к плате.
Остается добавить, что в моей крохотной плате FPGA M02mini проект занимает всего 1232 логических элемента, а получившаяся тактовая частота проекта Fmax=72МГц, что мне кажется совсем не плохо: 
Таким образом, считаю ядро процессора Forth J1 вполне работоспособным и его вполне можно применять в реальных проектах. Сам язык Форт, хоть и кажется мудреным, дает высокую плотность кода и не плохую производительность.
Весь проект можно взять на github.
Описание других проектов для платы M02mini можно посмотреть здесь.
