Оператор в Kubernetes для управления кластерами БД. Владислав Клименко (Altinity, 2019)

Доклад посвящен практическим вопросам разработки оператора в Kubernetes, проектированию его архитектуры и основных принципов функционирования.
В первой части доклада рассмотрим:
- что такое оператор в Kubernetes и зачем он нужен;
- как именно оператор упрощает управление сложными системами;
- что оператор может, а что оператор не может.
Далее, перейдём к обсуждению внутреннего устройства оператора. Рассмотрим архитектуру и функционирование оператора по шагам. Подробно разберём:
- взаимодействие между оператором и Kubernetes;
- какие функции оператор берет на себя, а что делегирует в Kubernetes.
Рассмотрим управление шардами и репликами БД в Kubernetes.
Далее, обсудим вопросы хранения данных:
- как работать с Persistent Storage с точки зрения оператора;
- подводные камни использования Local Storage.
В заключительной части доклада рассмотрим практические примеры применения clickhouse-operator с Amazon или Google Cloud Service. Доклад строится на примере разработки и опыта эксплуатации оператора для ClickHouse.
Видео:
Меня зовут Владислав Клименко. Я хотел сегодня рассказать о нашем опыте разработки и эксплуатации оператора, причем это специализированный оператор для управления кластерами баз данных. На примере ClickHouse-operator для управления кластером ClickHouse.

Почему мы имеем возможность рассказывать об операторе и ClickHouse?
- Мы занимаемся поддержкой и развитием ClickHouse.
- На текущий момент мы стараемся потихоньку вносить свой посильный вклад в разработку ClickHouse. И являемся вторыми после Яндекса по объему сделанных изменений в ClickHouse.
- Стараемся делать дополнительные проекты для экосистемы ClickHouse.
Об одном из таких проектов я хотел бы рассказать. Это про ClickHouse-operator для Kubernetes.
В своем докладе я хотел бы затронуть две темы:
- Первая тема — это как работает наш оператор по управлению базами данных ClickHouse в Kubernetes.
- Вторая тема — это как работает любой оператор, т. е. как он взаимодействует с Kubernetes.
При этом эти два вопроса будут пересекаться на протяжении всего моего доклада.

Кому будет интересно послушать то, что я пытаюсь рассказать?
- Наиболее будет интересно тем, кто эксплуатирует операторы.
- Или тем, кто хочет сделать свой, чтобы понимать, как оно работает внутри, как взаимодействует оператор с Kubernetes и какие подводные камни могут появиться.

Для того чтобы лучше всего понимать то, что мы сегодня будем обсуждать, было бы неплохо знать, как работает Kubernetes и иметь базовую подготовку по облачным технологиям.

Что такое ClickHouse? Это колоночная база данных со спецификой в онлайн-обработку аналитических запросов. И она полностью open source.
И нам важно знать только две вещи. Надо знать, что это база данных, поэтому то, что я буду рассказывать, будет применимо практически к любой базе данных. И то, что СУБД ClickHouse очень хорошо масштабируется, практически линейную дает масштабируемость. И поэтому состояние кластера — это для ClickHouse состояние естественное. И нам наиболее интересно обсудить то, как кластер ClickHouse обслуживать в Kubernetes.

Зачем он там нужен? Почему мы не можем продолжать его эксплуатировать самостоятельно? И ответы частично технические, а частично организационные.
- На практике мы все чаще и чаще встречаем такую ситуацию, когда в крупных компаниях уже практически все компоненты и так уже в Kubernetes. Остаются базы данных за пределами.
- И все чаще задается вопрос: «Можно ли это внутрь поместить?». Поэтому крупные компании стараются производить максимальную унификацию управления для того, чтобы быстро иметь возможность управлять своими хранилищами данных.
- И особенно это помогает, если нужна максимальная возможность повторить тоже самое на новом месте, т. е. максимальная переносимость.

Насколько это просто или сложно? Это, конечно, можно делать руками. Но это не так, чтобы просто, потому что у нас складываются по сумме сложность управления самим Kubernetes, но при этом накладывается специфика ClickHouse. И получается такая агрегация.
И все вместе это дает достаточно большой набор технологий, которым управлять становиться уже достаточно сложно, потому что Kubernetes приносит свои каждодневные вопросы к эксплуатации, а ClickHouse приносит свои вопросы к каждодневной эксплуатации. Особенно, если у нас ClickHouse-ов несколько, и нам надо постоянно с ними что-то делать.

У ClickHouse при динамической конфигурации есть достаточно большое количество вопросов, которые создают постоянную нагрузку на DevOps:
- Когда мы хотим поменять что-то в ClickHouse, например, добавить реплику, шард, то нам надо провести управление конфигурацией.
- Потом поменять схему данных, потому что у ClickHouse специфичный способ шардирования. Там надо раскладывать схему данных, раскладывать конфигурации.
- Надо настроить мониторинг.
- Сбор логов для новых шардов, для новых реплик.
- Озаботиться восстановлением.
- И перезапуском.
Это такие рутинные работы, которые очень бы хотелось облегчить в эксплуатации.

Сам Kubernetes хорошо помогает в эксплуатации, но на базовых системных вещах.
Kubernetes хорошо облегчает и производит автоматизацию таких вещей, как:
- Восстановление.
- Перезапуск.
- Управление системой хранения.
Это хорошо, это правильное направление, но он полностью не имеет представления о том, как эксплуатировать кластер базы данных.
Хочется большего, хочется, чтобы у нас работала вся база данных в Kubernetes.

Хочется получить что-то типа большой одной магической красной кнопки, на которую ты нажимаешь и у тебя разворачивается и поддерживается на протяжении всего жизненного цикла кластер с каждодневными задачами, которые надо решать. Кластер ClickHouse в Kubernetes.
И мы постарались сделать такое решение, которое помогло бы облегчить работу. Это ClickHouse-operator для Kubernetes от компании Altinity.

Оператор — это программа, основная задача которой управлять другими программами, т. е. это управленец.
И он содержит шаблоны поведения. Можно это назвать кодифицированными знаниями о предметной области.
И основная его задача — это облегчить жизнь DevOps и уменьшить микроменеджмент, чтобы он (DevOps) уже мыслил терминами высокого уровня, т. е. чтобы он (DevOps) не занимался микроменеджментом, чтобы не производил настройку всех деталей вручную.
И как раз оператор — это робот помощник, который борется с микрозадачами и помогает DevOps.

Зачем нужен оператор? Он особенно хорошо себя показывает в двух вопросах:
- Когда у специалиста, который занимается ClickHouse, недостаточно опыта, но эксплуатировать ClickHouse уже надо, оператор облегчает эксплуатацию и позволяет эксплуатировать кластер ClickHouse с достаточно сложной конфигурацией, при этом не очень вдаваясь в подробности о том, как это все работает внутри. Просто ему даешь высокоуровневые задачи, и это работает.
- И вторая задача, в которой он себя наиболее хорошо проявляет, это когда надо автоматизировать большое количество типовых задач. Снимает микрозадачи с сисадминов.

Это больше всего надо либо тем, кто только начинает свой путь, либо тем, кому надо много заниматься автоматизацией.

В чем же отличие подхода, основанного на операторах, от других систем? Есть же Helm. Он же тоже помогает поставить ClickHouse, можно нарисовать helm charts, которые даже поставят целый кластер ClickHouse. В чем тогда отличие между оператором и от того же, например, Helm?
Основное фундаментальное отличие в том, что Helm — это управление пакетами, а оператор шагает дальше. Это сопровождение всего жизненного цикла. Это не только установка, это каждодневные задачи, которые включают себя масштабирование, шардирование, т. е. все то, что надо выполнять в процессе жизненного цикла (если надо, то и удаление тоже) — это все решает оператор. Он пытается автоматизировать и обслуживать весь жизненный цикл программного обеспечения. В этом его фундаментальное отличие от других решений, которые представлены.

Это была вступительная часть, давайте пойдем дальше.
Как мы строим свой оператор? Мы пытаемся подойти к вопросу, чтобы управлять кластером ClickHouse как одним ресурсом.
Вот у нас в левой части картины есть входные данные. Это YAML со спецификацией кластера, который классическим образом через kubectl передается в Kubernetes. Там у нас оператор это подхватывает, делает свою магию. И на выходе у нас получается вот такая схема. Это имплементация ClickHouse в Kubernetes.
И дальше мы будем потихоньку смотреть, как именно работает оператор, какие типовые задачи можно решать. Мы рассмотрим только типовые задачи, потому что у нас ограниченное время. И будет рассказано не обо всем, что может решать оператор.

Давайте исходить из практики. Наш проект — это полностью open source, поэтому можно посмотреть на GitHub, как он работает. И можно исходить из соображений, если хочется просто запустить, то с Quick Start Guide можно начинать.
Если хочется детально разбираться, то мы стараемся поддерживать документацию в более-менее приличном виде.

Давайте начнем с практической задачи. Первая задача, с чего мы все хотим начать, это запустить первый пример хоть как-нибудь. Как при помощи оператора запустить ClickHouse, даже не очень зная, как он работает? Пишем манифест, т.к. все общение с k8s — это общение через манифесты.

Вот такой сложный манифест. То, что у нас выделено красным, это то, на чем надо акцентироваться. Мы оператора просим создать кластер по имени demo.
Пока что это базовые примеры. Storage еще не описывается, но мы к storage вернемся чуть позже. Пока что в динамике будем наблюдать за развитием кластера.
Создали мы этот манифест. Скармливаем его нашему оператору. Он поработал, сделал магию.

Смотрим в консоль. Интерес вызывают три компонента — это Pod, два Service-a, StatefulSet.
Оператор отработал, и мы можем посмотреть, что именно он создал.
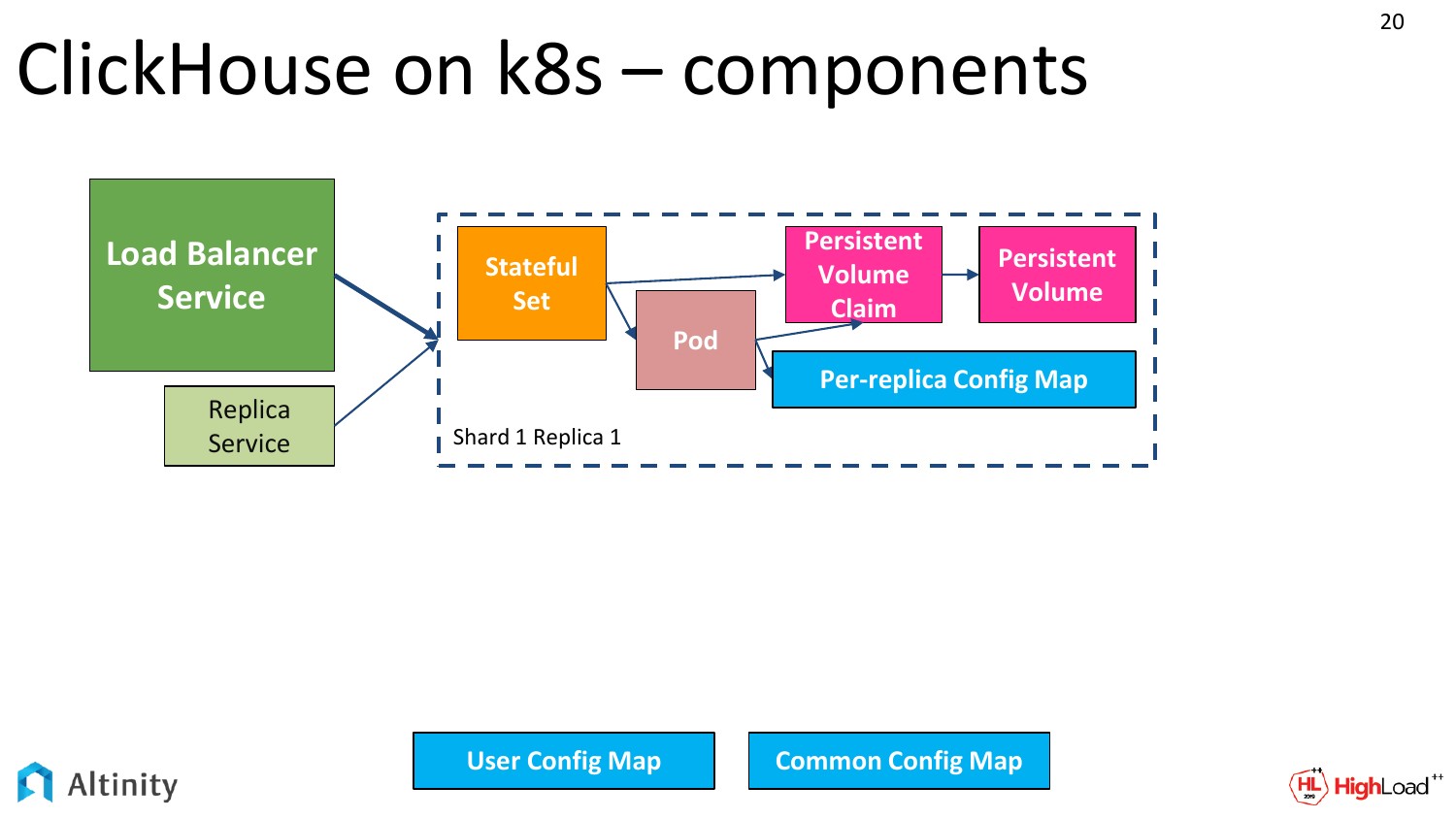
Создает он примерно такую схему. У нас есть StatefulSet, Pod, ConfigMap для каждой реплики, ConfigMap для всего кластера. Обязательно сервисы как точки входа в кластер.
Сервисы — это центральный Load Balancer Service и можно еще для каждой реплики, для каждого шарда.
Вот у нас базовый кластер выглядит примерно таким образом. Он из одной единственной ноды.

Пойдем дальше, будем усложнять. Надо кластер шардировать.
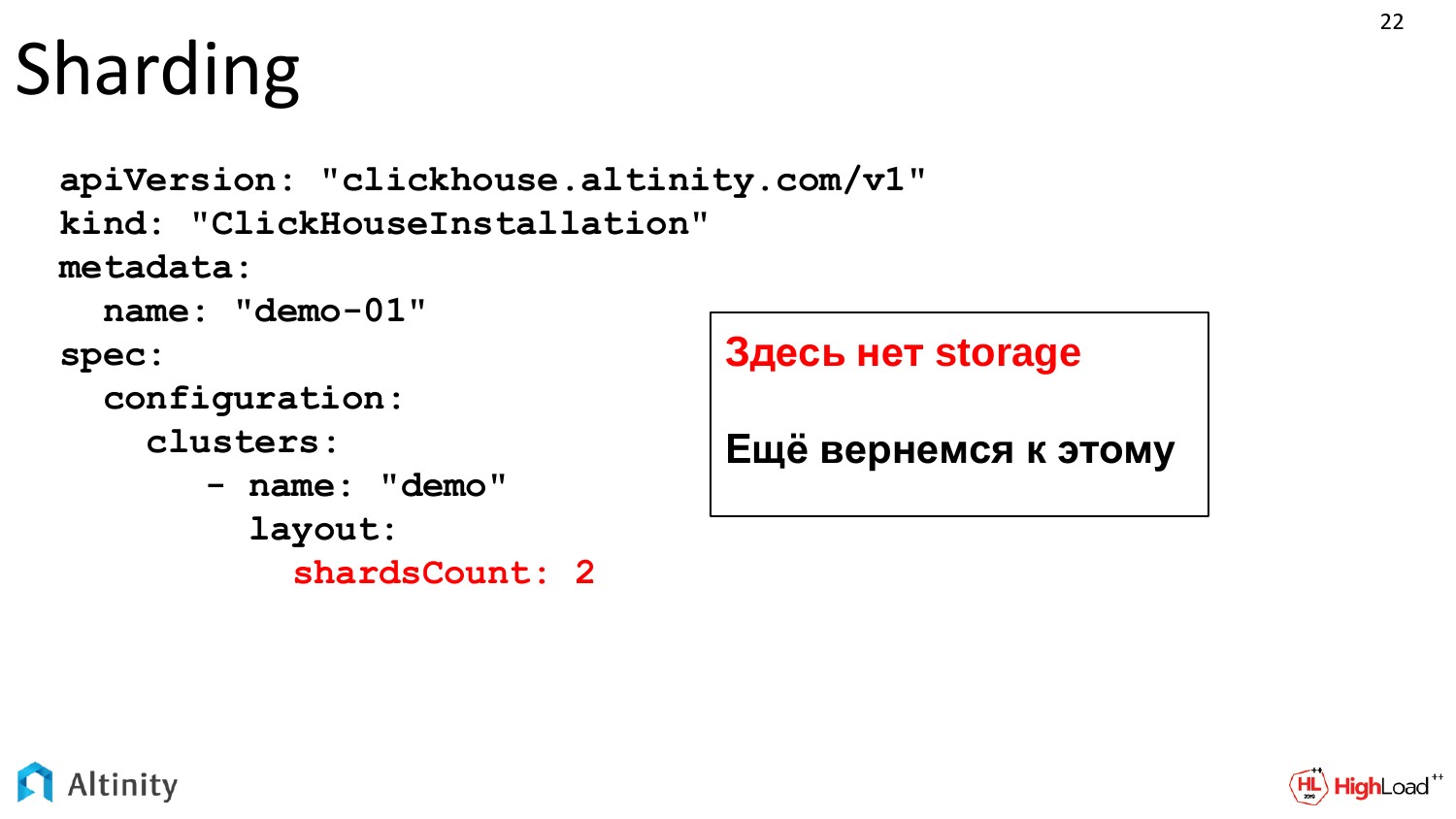
У нас задачи растут, начинается динамика. Мы хотим добавить шард. Следим за развитием. Меняем нашу спецификацию. Указываем, что мы хотим два шарда.
Это тот же самый файл, который у нас динамически развивается с ростом системы. Storage нет, storage будет дальше рассмотрен, это отдельная тема.
Скармливаем YAML-оператор и смотрим, что получается.

Оператор подумал и сделал следующие сущности. У нас уже два Pod, три Service-a и, внезапно, 2 StatefulSet-а. Почему 2 StatefulSet-а?

На схеме было вот так — это у нас первоначальное состояние, когда один у нас был pod.

Стало вот так. Пока что все просто, оно продублировалось.

И почему же StatefulSet стало два? Тут надо отвлечься и обсудить вопрос, как в Kubernetes происходит управление Pod«ами.
Есть такой объект под названием StatefulSet, который позволяет делать набор Pod«ов из шаблона. Тут ключевой фактор — это Template. И можно в одном StatefulSet запускать по одному шаблону много Pod«ов. И ключевой фразой тут является «по одному шаблону много Pod«ов».
И был большой соблазн сделать весь кластер, упаковав в один StatefulSet. Это будет работать, в этом нет никаких проблем. Но есть один нюанс. Если мы хотим собрать гетерогенный кластер, т. е. из нескольких версий ClickHouse, то тут у нас начинаются вопросы. Да, StatefulSet может сделать rolling update, да там можно накатывать новую версию, объяснять, что нужно попробовать не больше столько-то нодов одновременно.
Но если экстраполировать задачу и сказать, что мы хотим сделать полностью гетерогенный кластер и хотим не со старой версии поменять на новую при помощи rolling update, а просто хотим создать кластер гетерогенный как в части разных версий ClickHouse, так в части разного storage. Мы хотим, например, какие-то реплики сделать на отдельных дисках, на медленных, в общем, полностью построить гетерогенный кластер. И из-за того, что StatefulSet делает из одного шаблона стандартизованное решение, поэтому нет возможности это сделать.
После некоторого раздумья было принято решение, что мы делаем вот так. У нас каждая реплика в своем StatefulSet. Есть некоторые недостатки у этого решения, но на практике это все полностью в себе инкапсулирует оператор. И есть куча достоинств. Мы можем строить полностью такой кластер, какой хотим, например абсолютно гетерогенный. Поэтому в кластере, в котором у нас два шарда по одной реплике, у нас будет 2 StatefulSet«а и 2 Pod«а именно потому, что мы избрали такой подход из-за вышеозвученным причинам для возможности построить гетерогенный кластер.

Вернемся к практическим задачам. В нашем кластере надо настраивать пользователей, т.е. надо производить какое-то конфигурирование ClickHouse в Kubernetes. Оператор для этого предоставляет все возможности.

Можно прямо в YAML писать то, что мы хотим. Все конфигурационные опции прямиком мапятся из этого YAML в конфиги ClickHouse, которые потом раскладываются по всему кластеру.
Можно и вот так писать. Это для примера. Пароль можно шифрованный сделать. Поддерживаются абсолютно все конфигурационные опции ClickHouse. Здесь только пример.
Конфигурация по кластеру распространяется как ConfigMap. На практике апдейт ConfigMap происходит не мгновенно, поэтому если большой кластер, то процесс пропихивания конфигурации занимает некоторое время. Но все это очень удобно в эксплуатации.

Усложняем задачу. Кластер развивается. Мы хотим реплицировать данные. Т. е. у нас есть уже два шарда, по одной реплике, настроены пользователи. Мы растем и хотим заниматься репликацией.

Что нам нужно для репликации?
Нам нужен ZooKeeper. В ClickHouse репликация построена с использованием ZooKeeper. ZooKeeper нужен для того, чтобы у различных реплик ClickHouse был консенсус относительно того, какие блоки данных на каком ClickHouse есть.
ZooKeeper можно любой использовать. Если есть внешний ZooKeeper у предприятия, то его можно использовать. Если нет, то можно поставить из нашего репозитория. Есть установщик, который все это дело облегчает.
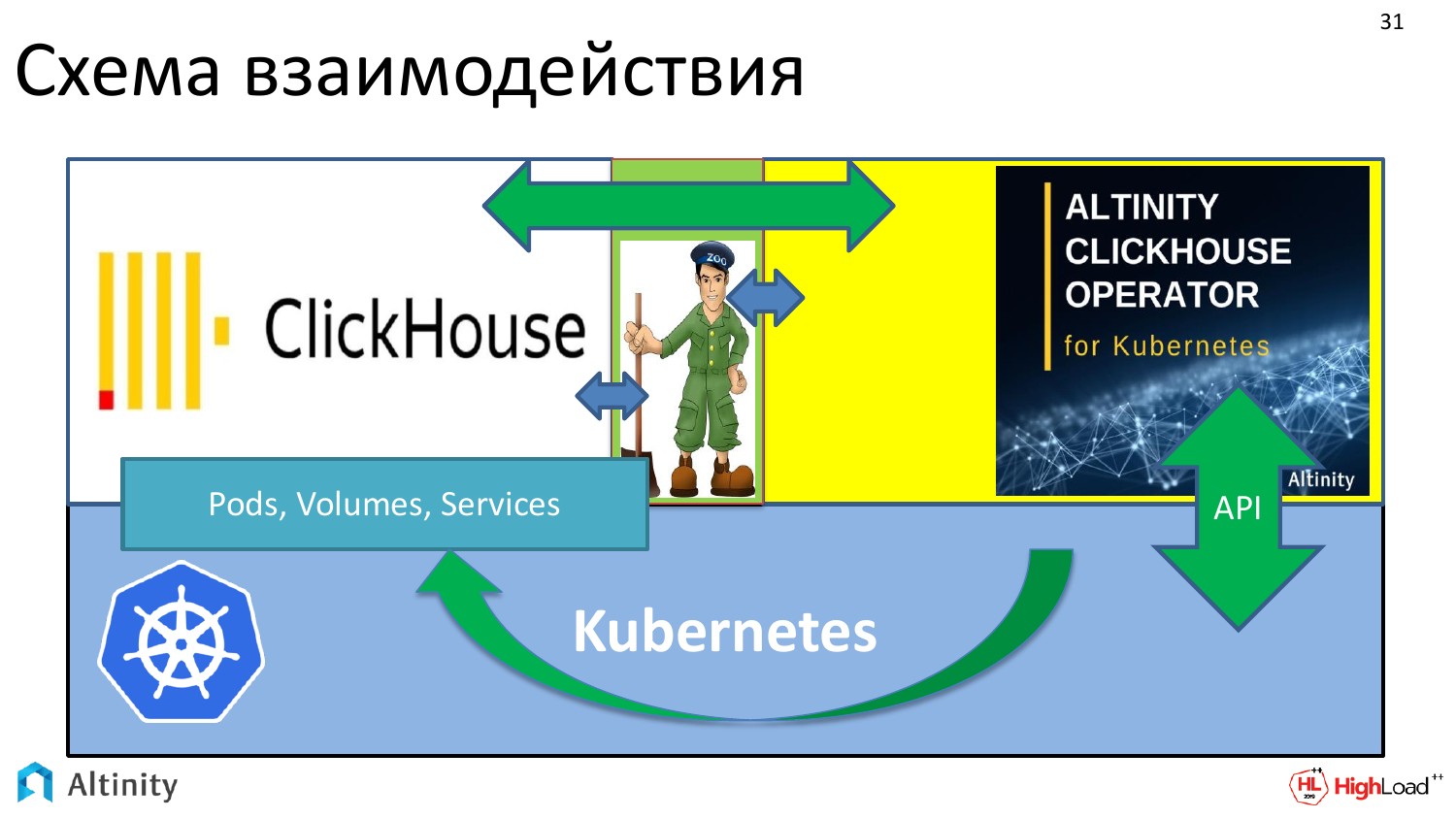
И схема взаимодействия всей системы получается вот такая. У нас есть Kubernetes как платформа. На нем исполняется оператор ClickHouse. ZooKeeper я изобразил вот здесь. И оператор взаимодействует как с ClickHouse, так и с ZooKeeper. Т. е. получается взаимодействие.
И все это надо для того, чтобы ClickHouse удачно реплицировал данные в k8s.

Давайте теперь посмотрим на саму задачу, на то, как будет выглядеть манифест для репликации.
Мы к нашему манифесту добавляем две секции. Первая — это где брать ZooKeeper, который может быть как внутри Kubernetes, так и внешний. Это просто описание. И заказываем реплики. Т.е. мы хотим две реплики. Итого на выходе у нас должно быть 4 pod«а. Про storage мы помним, он вернется чуть дальше. Storage — это отдельная песня.
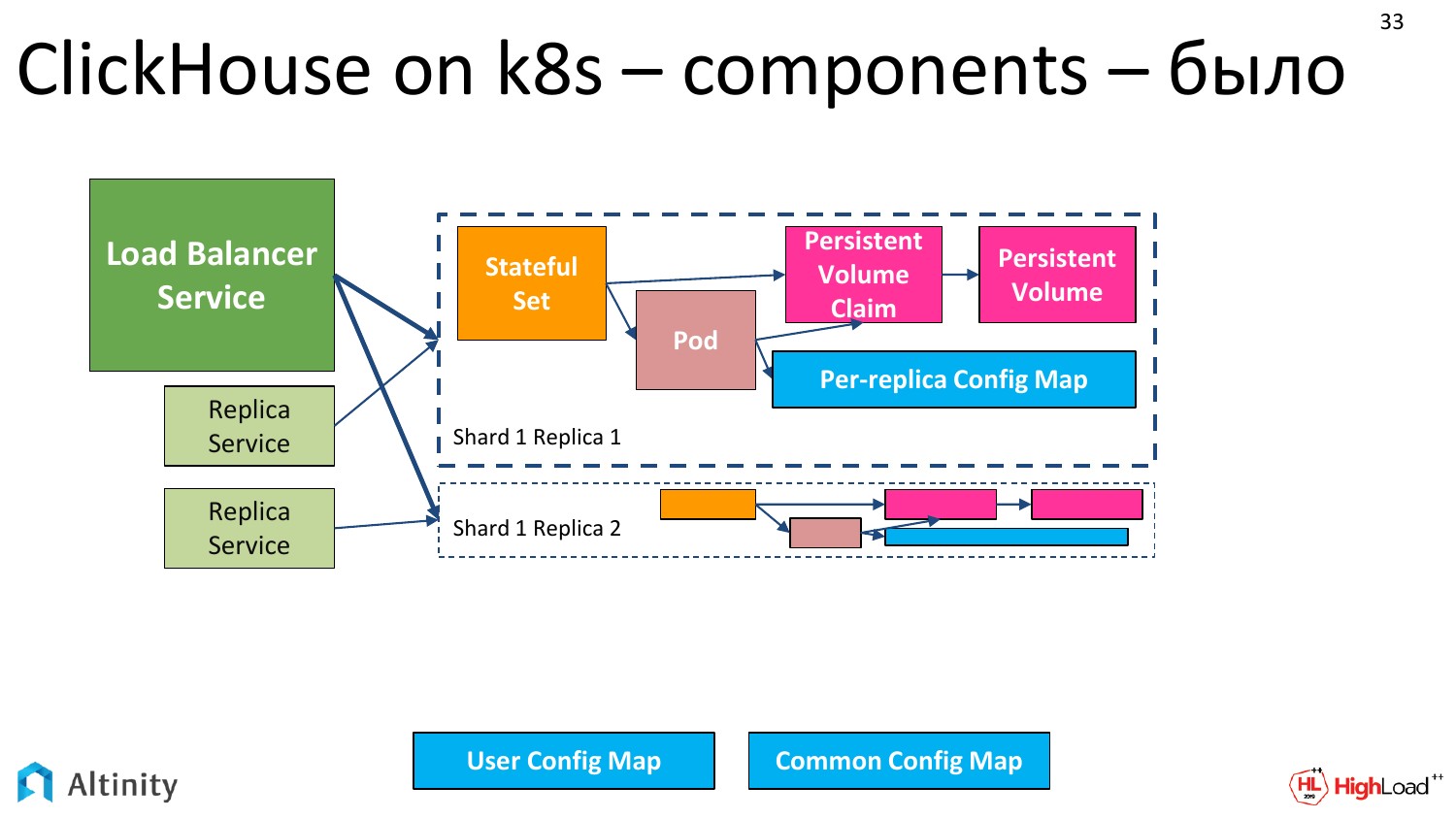
Было вот так.

Становится вот так. Добавляются реплики. 4-я не помещалась, мы верим, что их там может быть много. И сбоку добавляется ZooKeeper. Схемы усложняются.

И настало время добавлять следующую задачу. Будем добавлять Persistent Storage.
 По Persistent Storage у нас есть различные варианты исполнения.
По Persistent Storage у нас есть различные варианты исполнения.
В случае, если мы исполняемся в cloud-провайдере, например, используя Amazon, Google, то есть большой соблазн воспользоваться облачным storage. Это очень удобно, это хорошо.
И есть второй вариант. Это для local storage, когда у нас диски локальные на каждой ноде. Этот вариант намного сложнее в исполнении, но при этом он более производительный.

Давайте посмотрим, что у нас относительно cloud storage.
Есть достоинства. Это очень просто конфигурировать. Мы просто заказываем у облачного провайдера, что дай нам, пожалуйста, storage такой-то емкости, такого-то класса. Классы расписаны провайдерами самостоятельно.
И есть недостаток. Для кого-то это некритичный недостаток. Конечно, там будут какие-то накладки по производительности. Это очень удобно в работе, надежно, но есть некие потенциальные просадки по производительности.

А т.к. ClickHouse акцентируется именно на производительности, можно даже сказать, что выжимает все, что можно, поэтому очень многие клиенты стараются выжать максимум производительности.
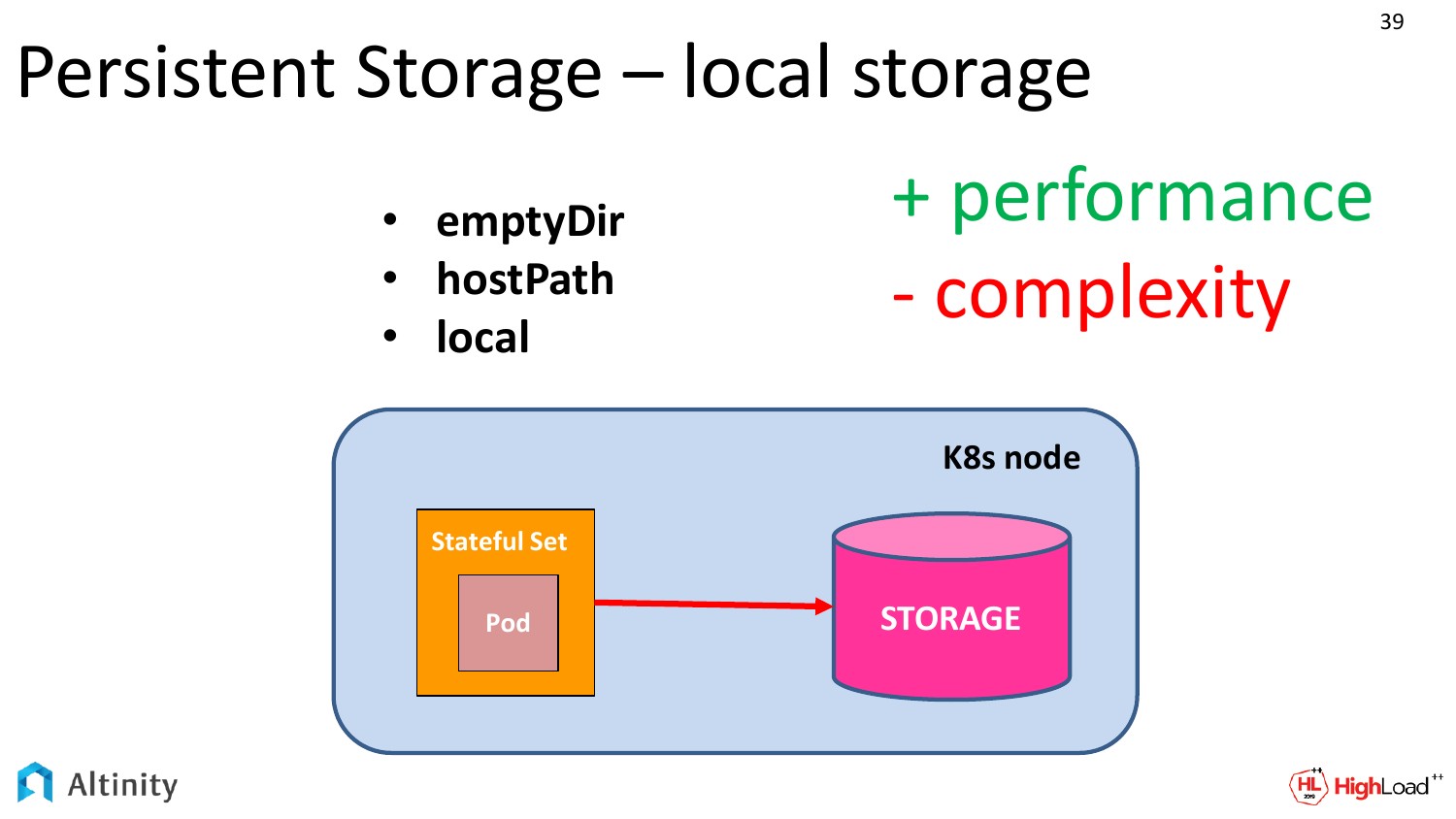
А чтобы выжать максимум, нам нужен local storage.
Kubernetes предоставляет три абстракции для использования local storage в Kubernetes. Это:
- EmptyDir
- HostPath.
- Local
Рассмотрим, чем они различаются, чем они похожи.
Во-первых, во всех трех подходах у нас storage — это локальные диски, которые находятся на том же самой физической k8s ноде. Но у них есть некоторые различия.

Начнем с самого простого, т. е. с emptyDir. Что это на практике такое? Это мы у своей спецификации просим систему контейнеризации (чаще всего — это докер) предоставить нам доступ в папку к локальному диску.
На практике докер где-то там у себя по своим собственным путям создает временную папку, называет ее длинным хэшем. И предоставляет интерфейс доступа к ней.
Как это будет работать по производительности? Это будет работать со скоростью локального диска, т.е. это полностью доступ к своему винту.
Но у этого дела есть свой недостаток. Persistent в этом деле достаточно сомнительный. При первом же движении докера с контейнерами Persistent теряется. Если Kubernetes захочется по какой-то причине перенести этот Pod на другой диск, то данные потеряются.
Такой подход хорошо для тестов, потому что скорость он показывает уже нормальную, но при этом для чего-то серьезного этот вариант не подходит.

Поэтому есть второй подход. Это hostPath. Если посмотреть предыдущий слайд и этот, то можно увидеть одно только различие. У нас папка выехала из докера прямо на Kubernetes ноду. Тут немного попроще. Мы прямо прописываем путь по локальной файловой системе, где мы бы хотели хранить свои данные.
Достоинства у этого способа есть. Это уже настоящий Persistent, причем классический. У нас на диске будут записаны данные по какому-то адресу.
Есть и недостатки. Это сложность управления. Наш Kubernetes может захотеть Pod передвинуть на другую физическую ноду. И тут уже вступает в дело DevOps. Он должен правильно объяснить всей системе, что передвигать эти pod«ы можно только лишь на такие ноды, на которых у тебя по этим путям что-то смонтировано, и не больше одной ноды за раз. Это достаточно сложно.
Специально для этих целей, мы у себя в операторе сделали шаблоны для того, чтобы всю эту сложность спрятать. И можно было бы просто сказать: «Я хочу, чтобы был у меня один instance ClickHouse на каждую физическую ноду и по такому-то пути».
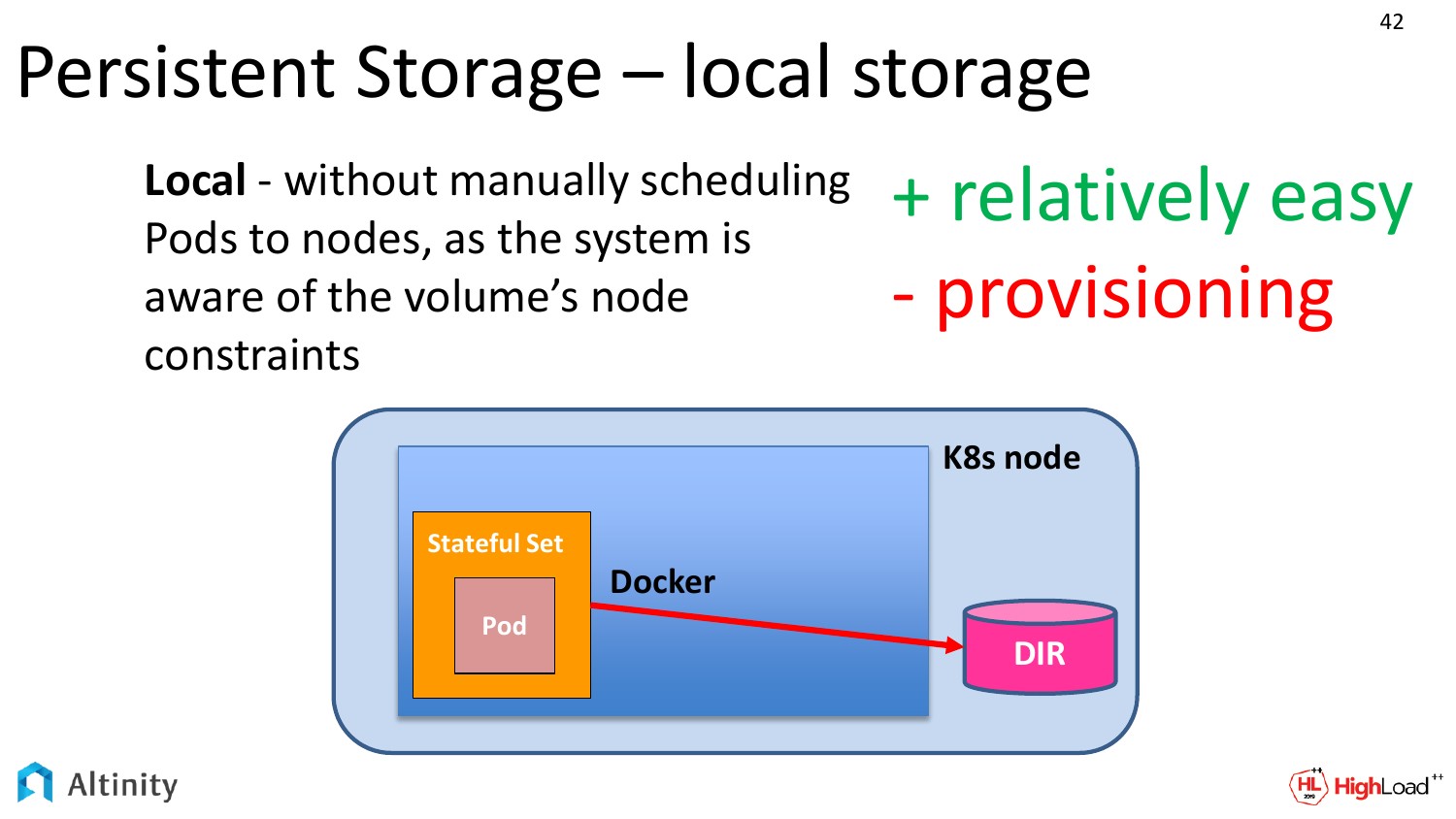
Но эта необходимость нужна не только нам, поэтому джентльмены из самого Kubernetes тоже понимают, что людям хочется иметь доступ к физическим дискам, поэтому они предоставляют третий уровень.
Он называется local. Разницы от предыдущего слайда практически никакой. Только раньше надо было руками проводить, что у нас нельзя эти pod«ы переносить с ноды на ноду, потому что они должны быть прицеплены по такому-то пути к локальному физическому диску, а теперь все эти знания инкапсулируется в сам Kubernetes. И получается намного проще конфигурировать.

Вернемся к нашей практической задаче. Вернемся к YAML template. Тут у нас появился настоящий storage. Мы вернулись к этому. Мы задаем классический VolumeClaim template как в k8s. И описываем, какой storage мы хотим.
После этого k8s запросит storage. Выделит нам его в StatefulSet. И в итоге это получится в распоряжении ClickHouse.

Была у нас вот такая схема. Наш Persistent Storage был красным, что как бы намекало на то, что его надо бы сделать.

И он становится зеленым. Теперь схема кластера ClickHouse on k8s полностью финализирована. У нас есть шарды, реплики, ZooKeeper, есть настоящий Persistent, который реализован тем или иным способом. Схема уже полностью работоспособная.

Мы продолжаем жить дальше. У нас кластер развивается. И Алексей старается, и выпускает новую версию ClickHouse.
Возникает практическая задача — протестировать новую версию ClickHouse на нашем кластере. Причем, естественно, не хочется его накатывать весь, хочется где-то в дальнем углу в одну реплику поставить новую версию, а, может быть, не одну новую версию, а сразу две, потому что они выходят частенько.
Что мы можем сказать по этому поводу?

Тут у нас есть как раз и такая возможность. Это шаблоны pod«ов. Можно расписать, наш оператор полностью позволяет построить кластер гетерогенный. Т.е. конфигурировать, начиная от всех реплик кучей, заканчивая каждой персональной репликой тем, какой версии мы хотим ClickHouse, какой версии мы хотим storage. Мы можем полностью сконфигурировать кластер такой конфигурации, как нам надо.

Немножко будем уже углубляться внутрь. До этого мы говорили, как работает ClickHouse-operator применительно к специфике ClickHouse.
Теперь я хотел бы сказать пару слов о том, как работает вообще любой оператор, а также о том, как взаимодействует с K8s.

Рассмотрим взаимодействие с K8s для начала. Что происходит, когда мы делаем kubectl apply? У нас через API в etcd появляются наши объекты.

К примеру базовые объекты Kubernetes: pod, StatefulSet, service и так далее по списку.
При этом ничего физического еще не происходит. Эти объекты надо материализовать в кластере.
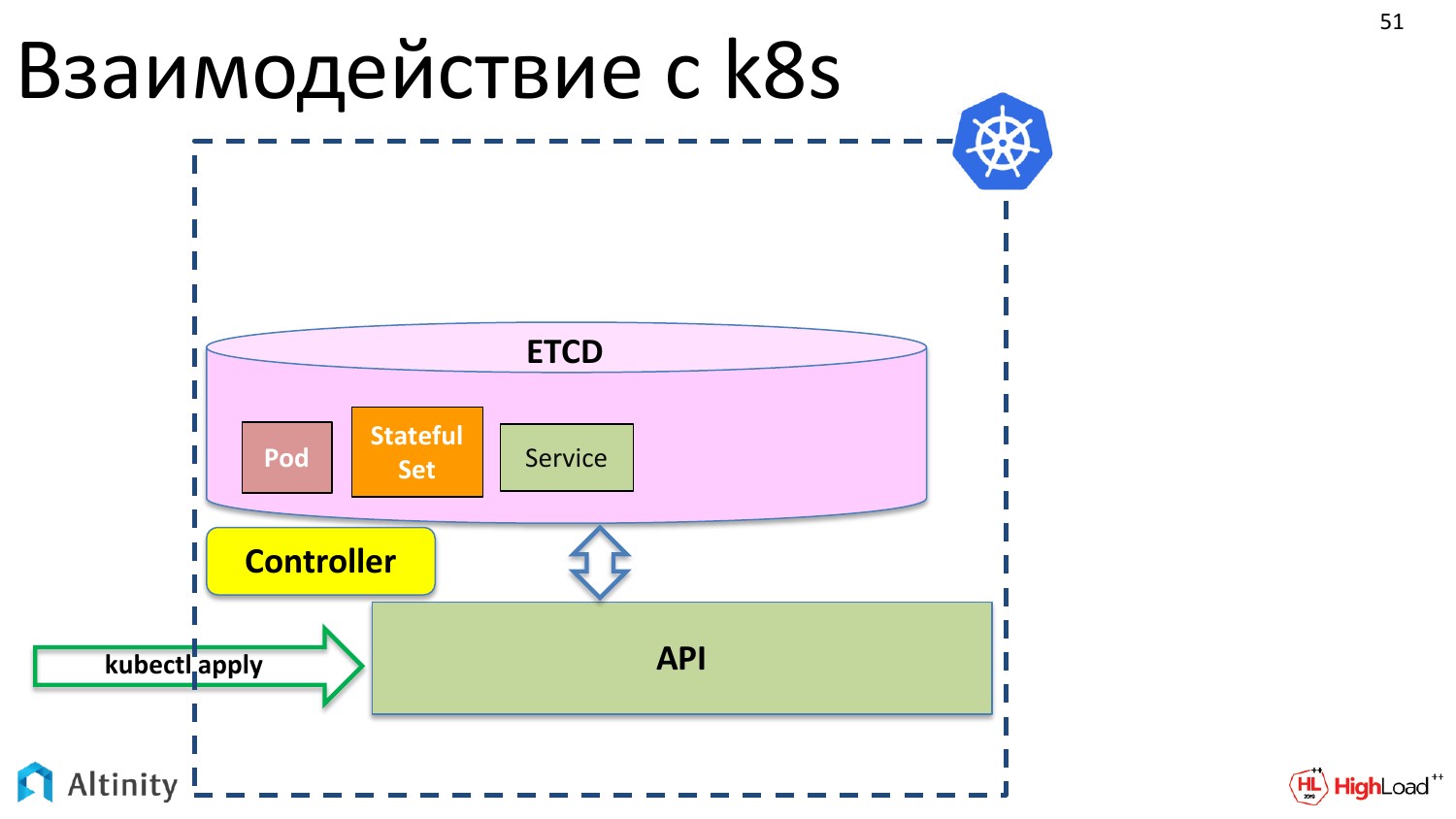
Для этого появляется контроллер. Контроллер — это специальный компонент k8s, который умеет материализовывать эти описания. Он знает, как и что надо делать физически. Он знает, как запускать контейнеры, что там надо настроить для того, чтобы заработал сервер.

И он материализует наши объекты в K8s.
Но мы хотим оперировать не только pod-ами, StatefulSet-ами, мы хотим создать ClickHouseInstallation, т. е. объект типа ClickHouse, чтобы оперировать им как единым целом. Пока что такой возможности нет.

Но у K8s есть следующая приятная вещь. Мы хотим, чтобы у нас появилась где-то там вот такая сложная сущность, в которой был бы собран из pod«ов и StatefulSet наш кластер.

И что для этого надо сделать? Во-первых, на сцену выходит Custom Resource Definition. Что это такое? Это описание для K8s, что у тебя будет еще один тип данных, что мы к pod, StatefulSet хотим добавить кастомный ресурс, который будет сложным внутри. Это описание структуры данных.

Мы его тоже через kubectl apply туда отправляем. Kubernetes его радостно забрал.
И теперь у нас в хранилище, у объекта в etcd появляется возможность записать кастомный ресурс под названием ClickHouseInstallation.
Но пока что ничего дальше не произойдет. Т. е. если мы сейчас создадим YAML-файл, который мы рассматривали с описанием шард, реплик и скажем «kubectl apply», то Kubernetes его примет, положит в etcd и скажет: «Отлично, но что с ним делать, не знаю. Как обслуживать ClickHouseInstallation я не знаю».

Соответственно, нам нужен кто-то, кто поможет Kubernetes обслуживать новый тип данных. Слева у нас есть штатный контроллер Kubernetes, который работает со штатными типами данных. А справа у нас должен появиться кастомный контроллер, который умеет работать с кастомными типами данных.
И по-другому он называется оператор. Я его здесь специально вынес за Kubernetes, потому что он может исполняться и снаружи K8s. Чаще всего, конечно, все операторы исполняются в Kubernetes, но ничего не мешает ему стоять снаружи, поэтому тут он специально вынесен наружу.
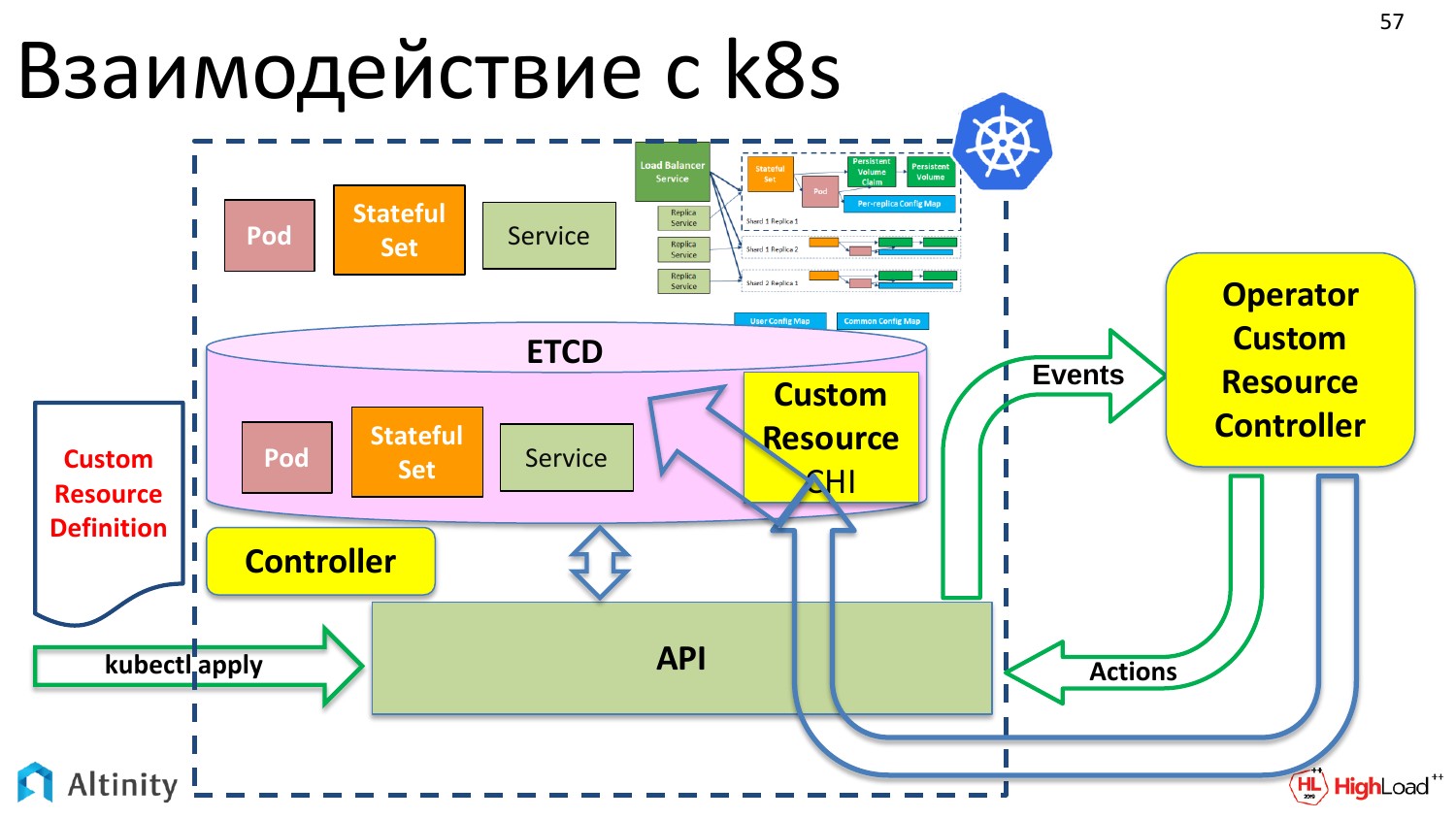
И уже в свою очередь кастомный контроллер, он же оператор, взаимодействует с Kubernetes через API. Он уже умеет взаимодействовать с API. И он уже знает, как из кастомного ресурса материализовать сложную схему, которую мы хотим сделать. Именно этим и занимается оператор.
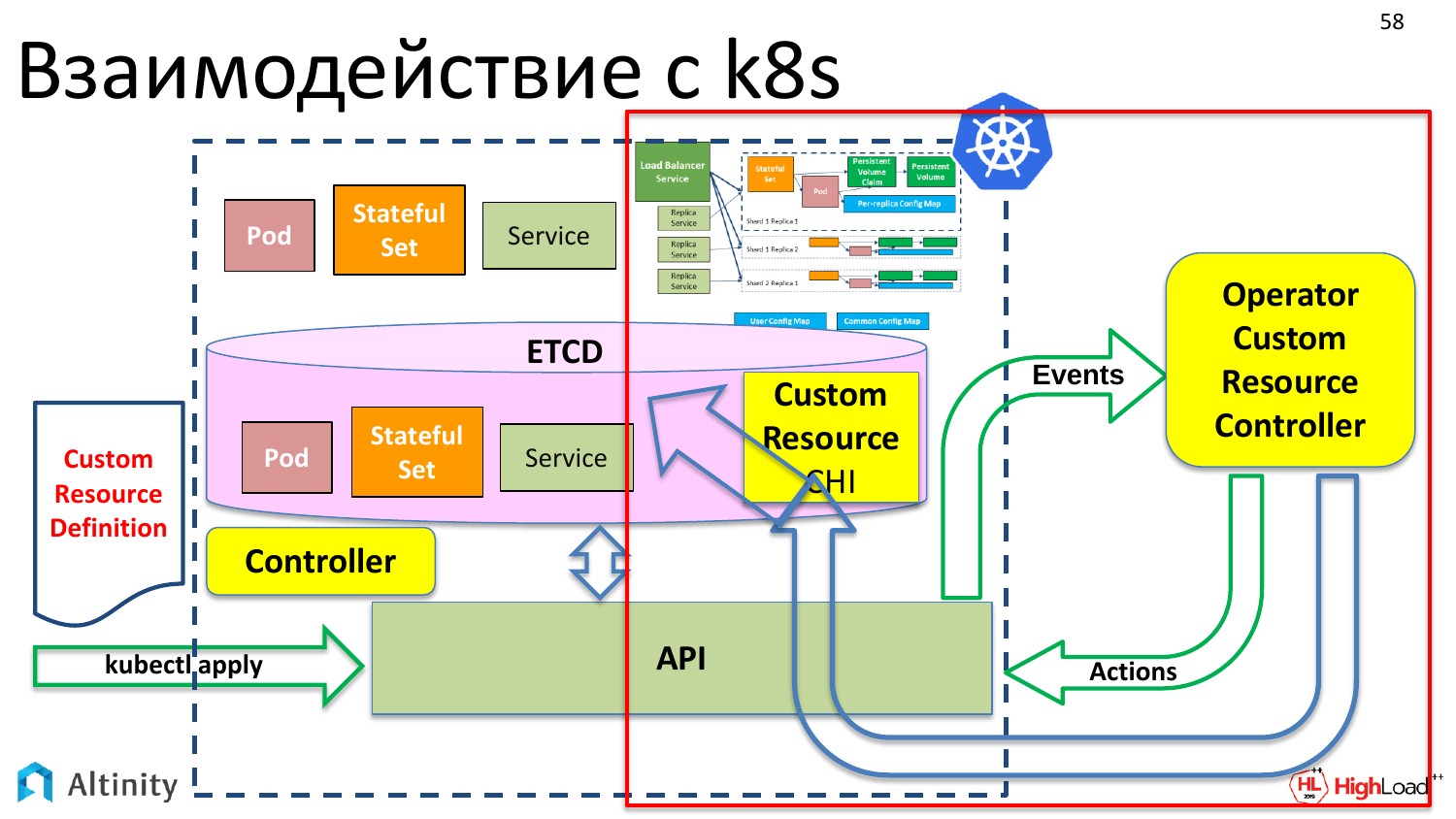
Как работает оператор? Давайте заглянем в правую часть, чтобы узнать, как он это делает. Узнаем, как оператор все это материализует и как дальше происходит взаимодействие с K8s.
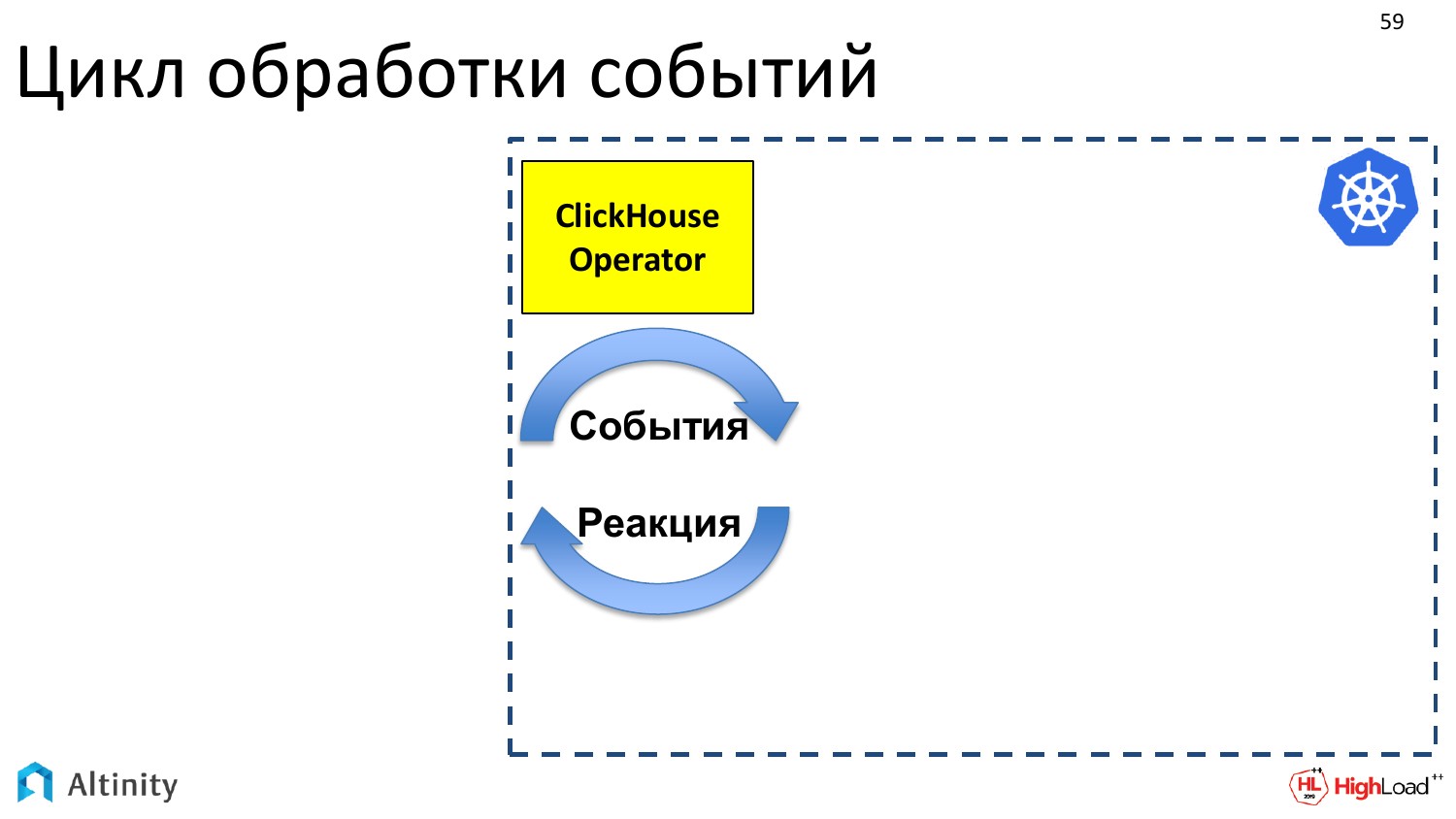
Оператор — это программа. Она событийно ориентированная. Оператор при помощи Kubernetes API подписывается на события. В Kubernetes API есть точки входа, в которых можно подписаться на события. И если что-то в K8s меняется, то Kubernetes посылает события всем желающим, т.е. кто на эту точку API подписался, тот и будет получать уведомления.
Оператор подписывается на события, и должен делать какую-то реакцию. Его задача — это реагировать на появляющиеся события.
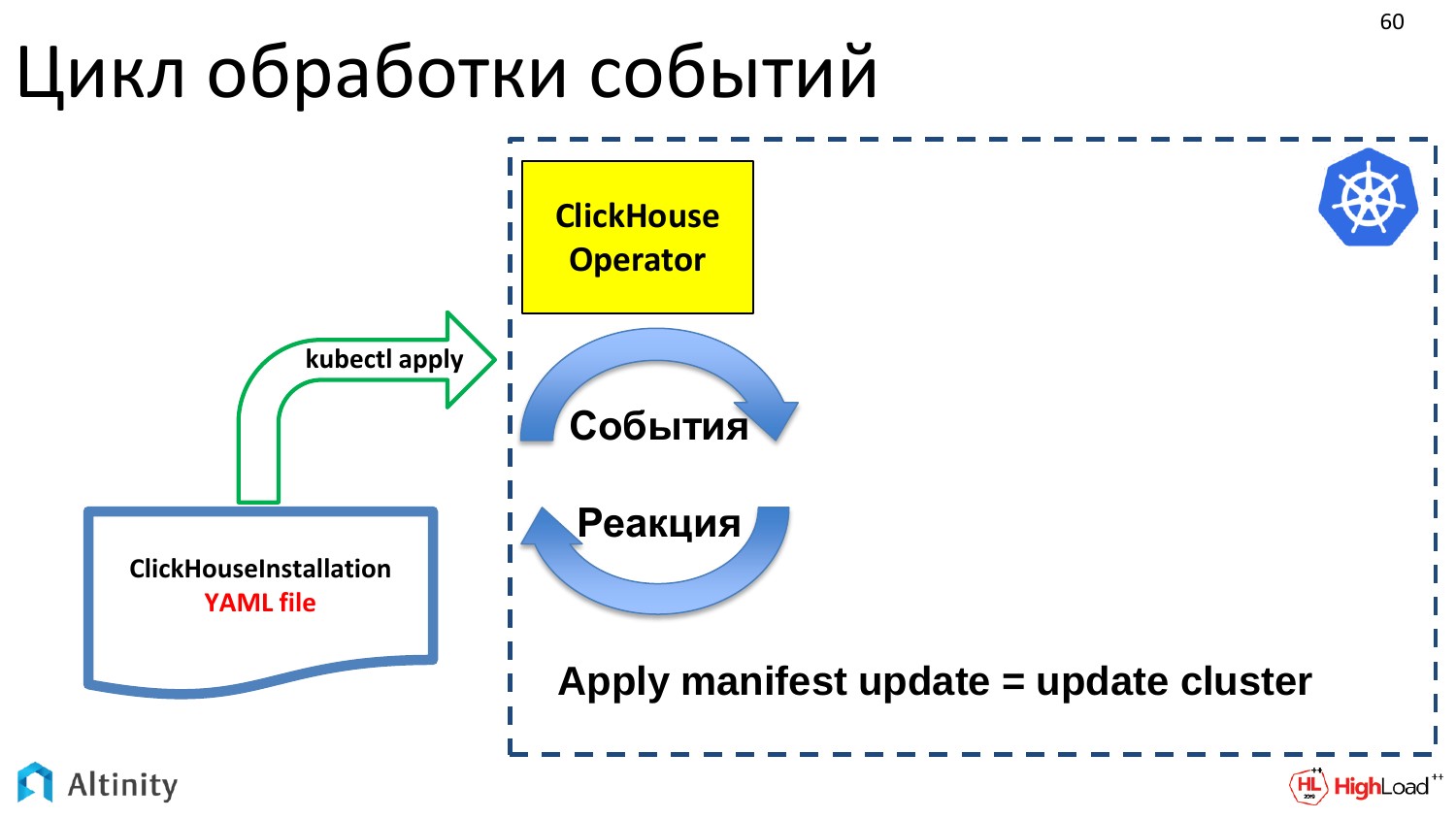
События генерируются некими апдейтами. Приходит наш YAML-файл с описанием ClickHouseInstallation. Он через kubectl apply пошел в etcd. Там сработал event, в итоге этот event пришел в ClickHouse-operator. Оператор получил это описание. И он что-то должен делать. Если пришел апдейт на объект ClickHouseInstallation, то надо апдейтить кластер. И задача оператора — это апдейтить кластер.
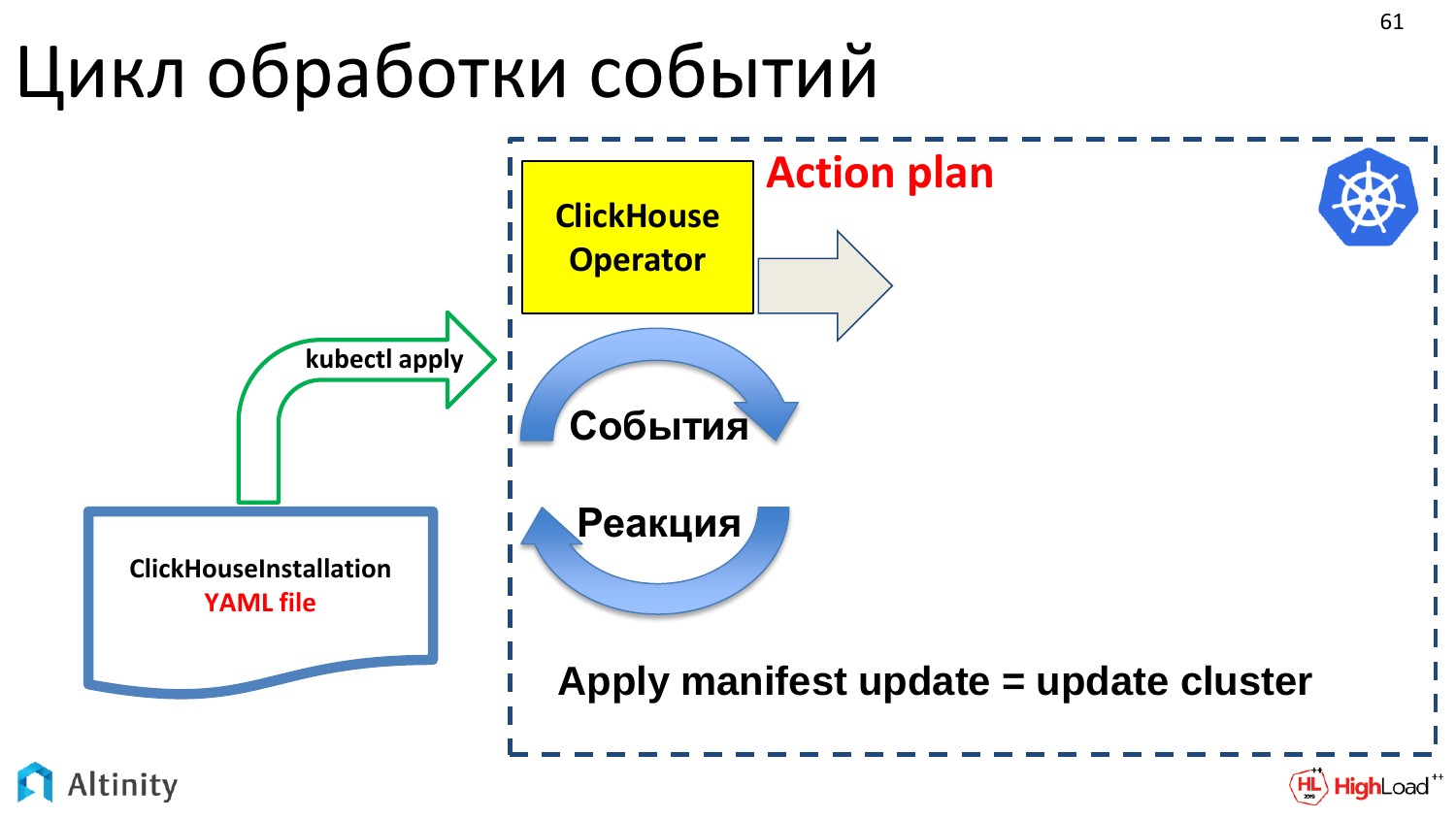
Что он делает? Во-первых, надо составить план действий, что мы будем делать с этим апдейтом. Апдейты могут быть очень маленькими, т.е. маленькие в YAML-исполнении, но могут влечь за собой очень большие изменения на кластере. Поэтому оператор создает план, и дальше он его придерживается.
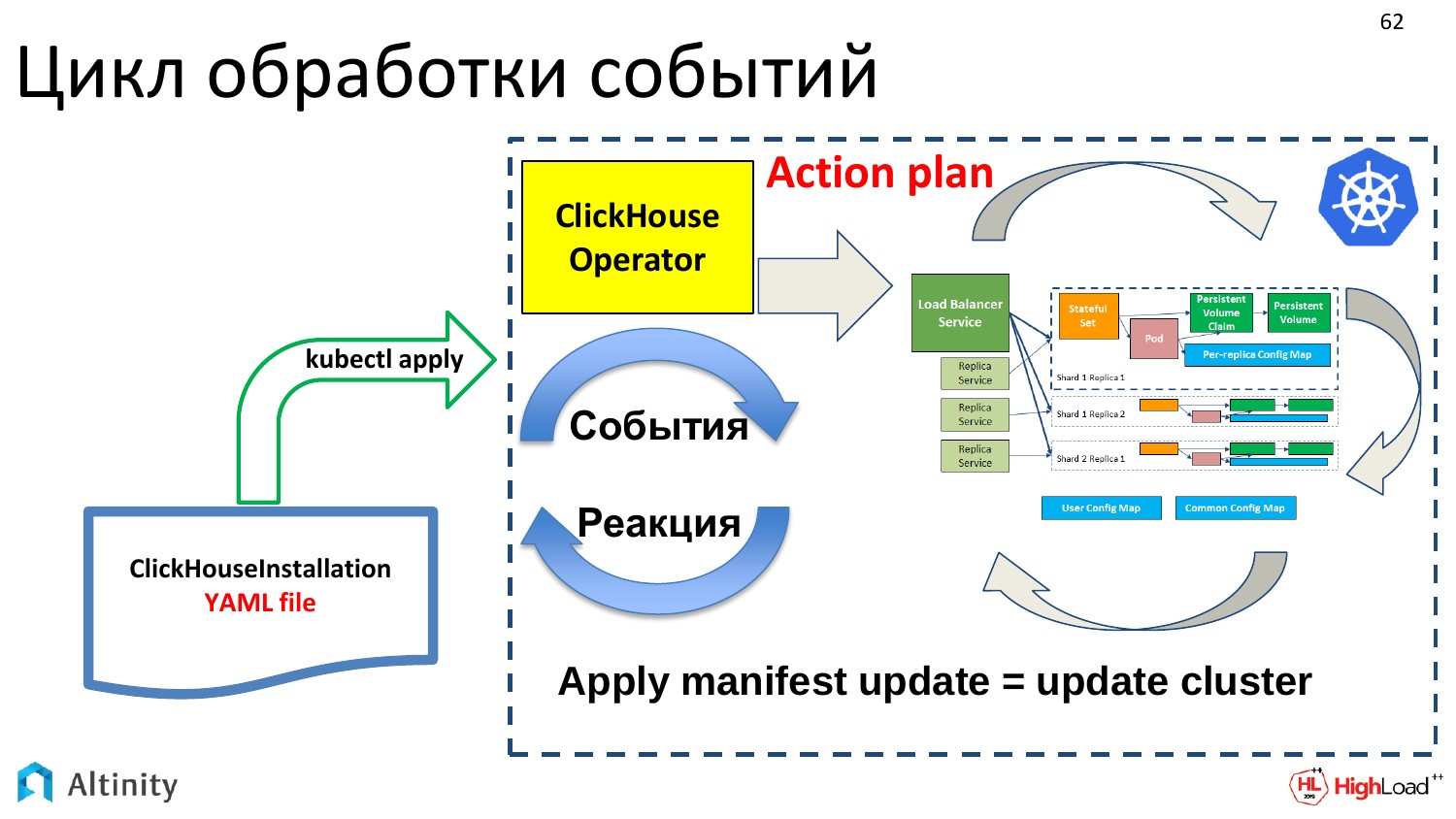
Он начинает согласно этому плану варить эту структуру внутри, чтобы материализовать pod«ы, сервисы, т.е. делать то, что его основной задачей и является. Это как строить кластер ClickHouse в Kubernetes.
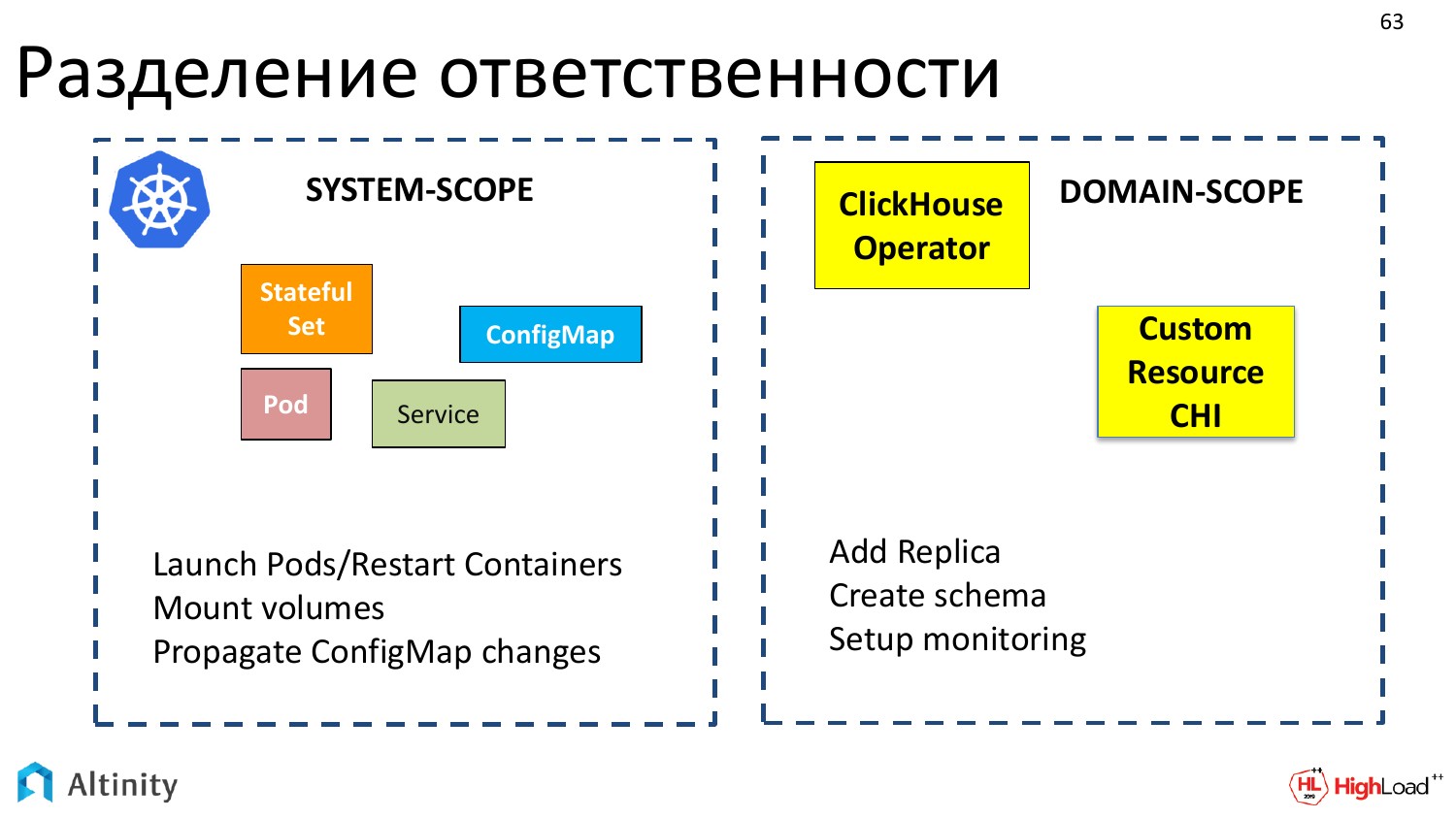
Теперь давайте коснемся такой интересной вещи. Это разделение ответственности между Kubernetes и оператором, т.е. что делает Kubernetes, что делает оператор и как они взаимодействуют между собой.
Kubernetes отвечает за системные вещи, т.е. за базовый набор объектов, который можно интерпретировать как system-scope. Kubernetes знает, как запускать pod«ы, как рестартить контейнеры, как делать mount volumes, как работать с ConfigMap, т.е. все, что можно назвать системой.
Операторы оперируют в предметных областях. Каждый оператор делается для своей предметной области. Мы сделали для ClickHouse.
И оператор взаимодействует именно в терминах предметной области таких, как добавить реплику, сделать схему, настроить мониторинг. Получается такое разделение.

Давайте рассмотрим на практическом примере, как это разделение ответственности происходит, когда мы делаем действие добавить реплику.
В оператор приходит задача — добавить реплику. Что оператор делает? Оператор рассчитает, что надо новый сделать StatefulSet, в котором надо описать такие-то шаблоны, volume claim.

Он это все подготовил и передает дальше в K8s. Говорит, что ему надо ConfigMap, StatefulSet, Volume. Kubernetes отрабатывает. Он материализует базовые единицы, которыми он оперирует.
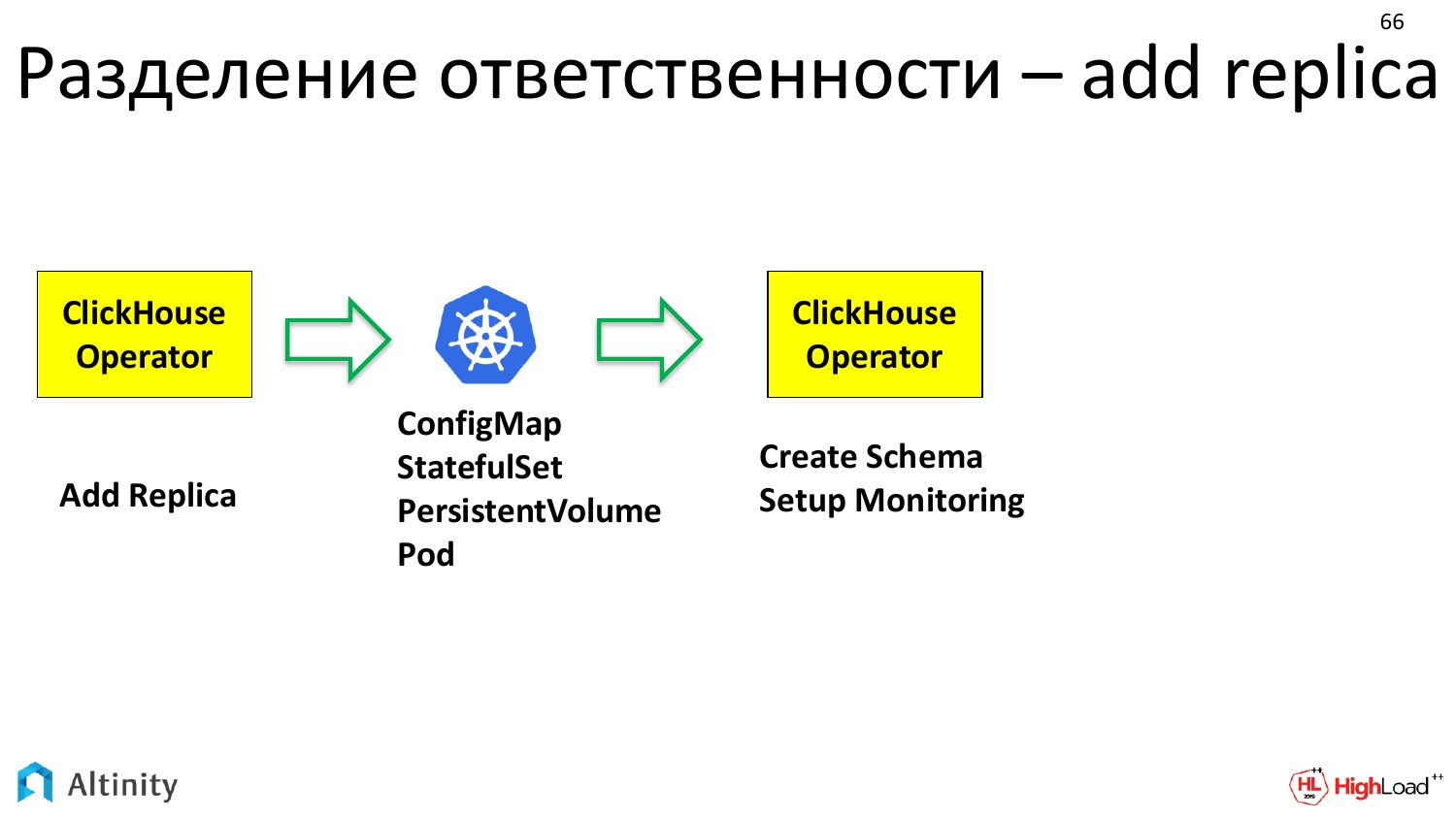
И дальше в дело вступает снова ClickHouse-operator. У него уже есть физический pod, на котором можно уже что-то делать. И ClickHouse-operator снова работает в терминах предметной области. Т.е. конкретно ClickHouse для того, чтобы включить реплику в кластер надо, во-первых, настроить схему данных, которая в этом кластере есть. А, во-вторых, эту реплику надо включить в мониторинг, чтобы она хорошо прослеживалась. Уже оператор это настраивает.

И только после этого уже в дело вступает сам ClickHouse, т.е. еще одна более высокоуровневая сущность. Это уже база данных. Она имеет свой instance, очередную реплику сконфигурированную, которая готова вступить в кластер.
Получается цепочка выполнения и разделения ответственности при добавлении реплики достаточно длинной.

Продолжаем наши практические задачи. Если кластер уже есть, то можно осуществить миграцию конфигурации.

Мы сделали так, что в существующий xml, которую ClickHouse понимает, можно прокидывать насквозь.

Можно сделать тонкую настройку ClickHouse. Как раз zoned deployment — это то, о чем я рассказывал при объяснении hostPath, local storage. Это как правильно сделать zoned deployment.

Следующая практическая задача — это мониторинг.
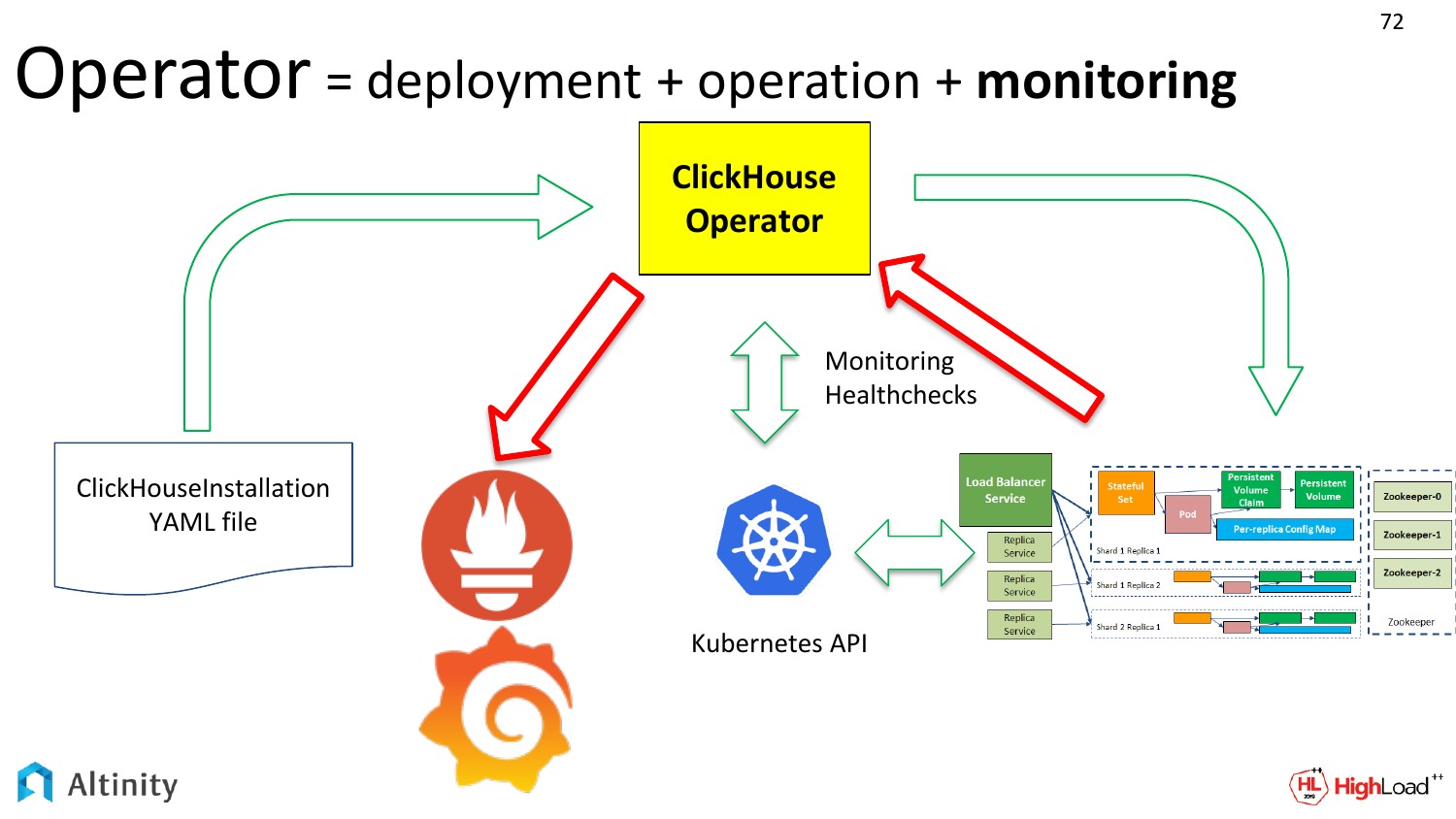
Если у нас кластер меняется, то надо периодически настраивать мониторинг.
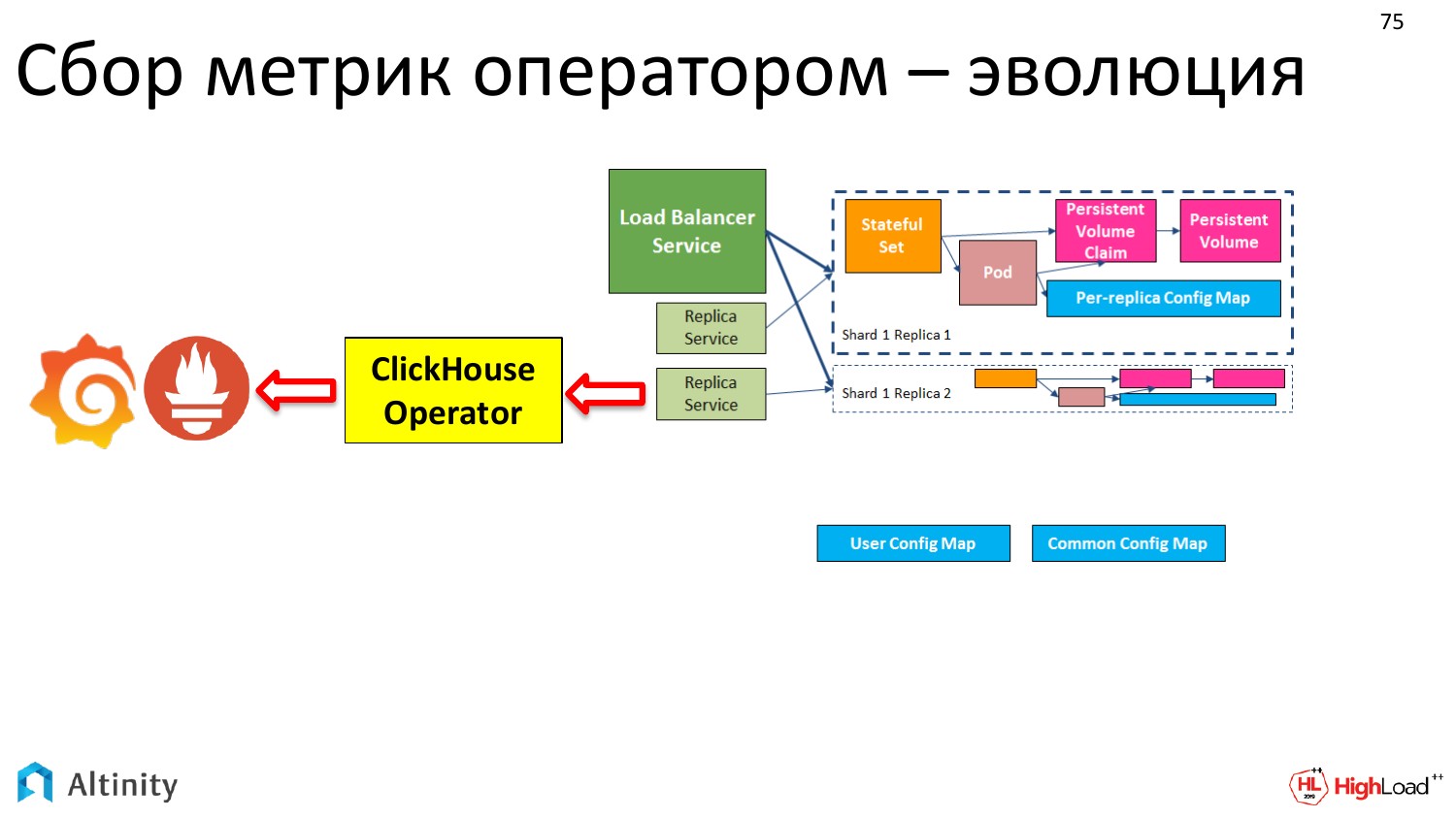
Давайте рассмотрим схему. Мы зеленые стрелки тут уже рассмотрели. Теперь давайте рассмотрим красные стрелки. Это то, как мы хотим мониторить наш кластер. Как метрики из кластера ClickHouse попадают в Prometheus, а потом в Grafana.

А в чем сложность с мониторингом? Почему это выносится как какое-то достижение? Сложность именно в динамике. Когда у нас кластер один и он статический, то можно единожды настроить мониторинг и больше не заморачиваться.
Но если у нас кластеров много, или постоянно что-то меняется, то процесс динамический. И постоянно заниматься перенастройкой мониторинга — это трата ресурсов и времени, т.е. даже просто лень. Это надо автоматизировать. Сложность именно в динамике процесса. И оператор это очень хорошо автоматизирует.

Как у нас развивался кластер? В начале он был такой.
Потом он был такой.
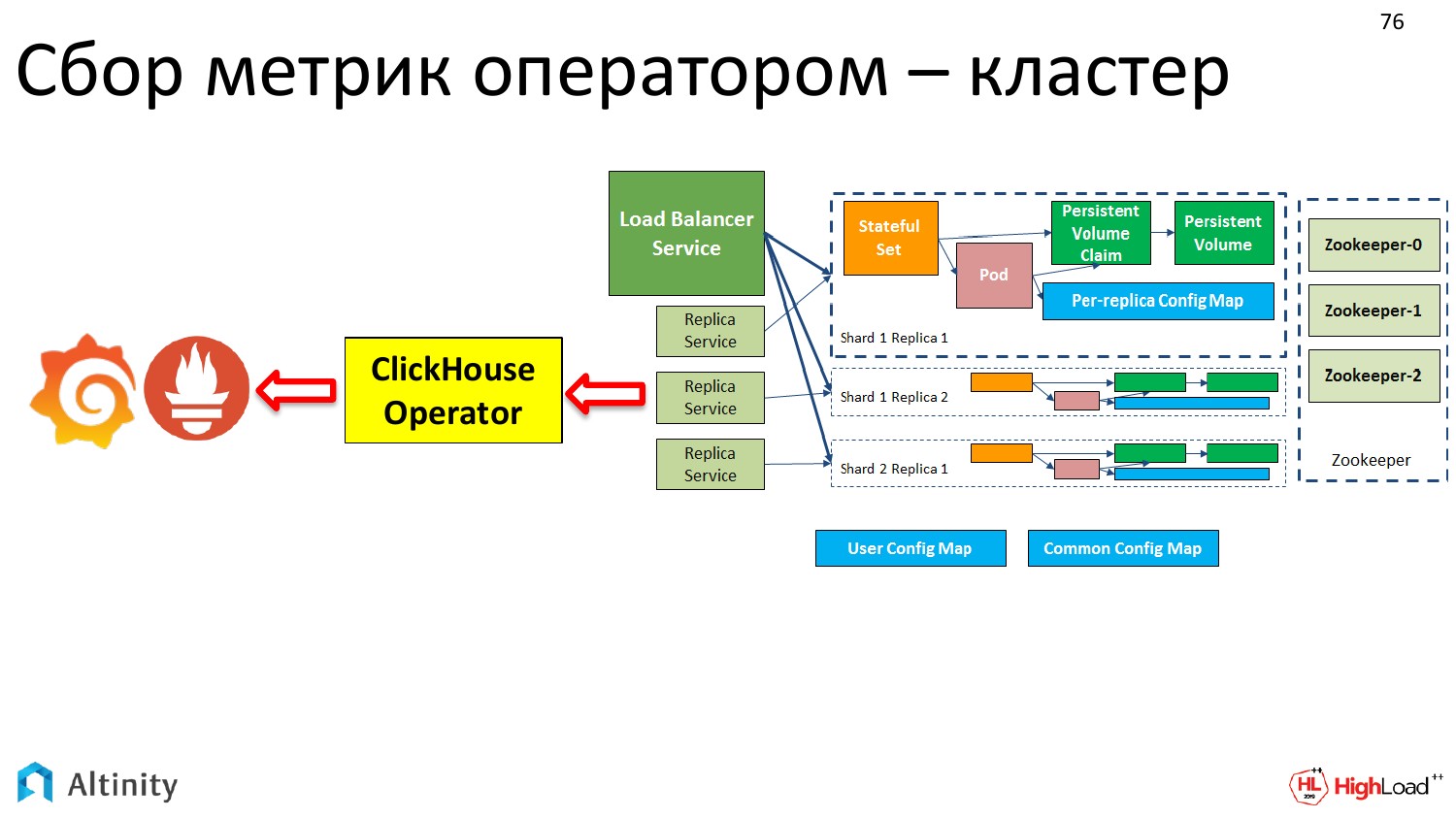
В итоге он стал вот таким.
А мониторинг автоматически д
