Практическое руководство по разработке бэкенд-сервиса на Python
Привет, меня зовут Александр Васин, я бэкенд-разработчик. Идея этого материала началась с того, что я хотел разобрать вступительное задание (Я.Диск) в Школу бэкенд-разработки Яндекса. Я начал описывать все тонкости выбора тех или иных технологий, методику тестирования… Получался совсем не разбор, а очень подробный гайд по тому, как писать бэкенды на Python. От первоначальной идеи остались только требования к сервису, на примере которых удобно разбирать инструменты и технологии. В итоге я очнулся на сотне тысяч символов. Ровно столько потребовалось, чтобы рассмотреть всё в мельчайших подробностях. Итак, программа на следующие 100 килобайт: как строить бэкенд сервиса, начиная от выбора инструментов и заканчивая деплоем.

TL; DR: Вот репка на GitHub с приложением, а кто любит (настоящие) лонгриды — прошу под кат.
Мы разработаем и протестируем REST API-сервис на Python, упакуем его в легкий Docker-контейнер и развернем с помощью Ansible.
Реализовать REST API-сервис можно по-разному, с помощью разных инструментов. Описанное решение не единственно верное, реализацию и инструменты я выбирал исходя из своего личного опыта и предпочтений.
Представим, что интернет-магазин подарков планирует запустить акцию в разных регионах. Чтобы стратегия продаж была эффективной, необходим анализ рынка. У магазина есть поставщик, регулярно присылающий (например, на почту) выгрузки данных с информацией о жителях.
Давайте разработаем REST API-сервис на Python, который будет анализировать предоставленные данные и выявлять спрос на подарки у жителей разных возрастных групп в разных городах по месяцам.
В сервисе реализуем следующие обработчики:
-
POST /imports
Добавляет новую выгрузку с данными; -
GET /imports/$import_id/citizens
Возвращает жителей указанной выгрузки; -
PATCH /imports/$import_id/citizens/$citizen_id
Изменяет информацию о жителе (и его родственниках) в указанной выгрузке; -
GET /imports/$import_id/citizens/birthdays
Вычисляет число подарков, которое приобретет каждый житель выгрузки своим родственникам (первого порядка), сгруппированное по месяцам; -
GET /imports/$import_id/towns/stat/percentile/age
Вычисляет 50-й, 75-й и 99-й перцентили возрастов (полных лет) жителей по городам в указанной выборке.
Итак, пишем сервис на Python, используя знакомые фреймворки, библиотеки и СУБД.
В 4 лекции видеокурса рассказывается о различных СУБД и их особенностях. Для моей реализации я выбрал СУБД PostgreSQL, зарекомендовавшую себя как надежное решение c отличной документацией на русском языке, сильным русским сообществом (всегда можно найти ответ на вопрос на русском языке) и даже бесплатными курсами. Реляционная модель достаточно универсальна и хорошо понятна многим разработчикам. Хотя то же самое можно было сделать на любой NoSQL СУБД, в этой статье будем рассматривать именно PostgreSQL.
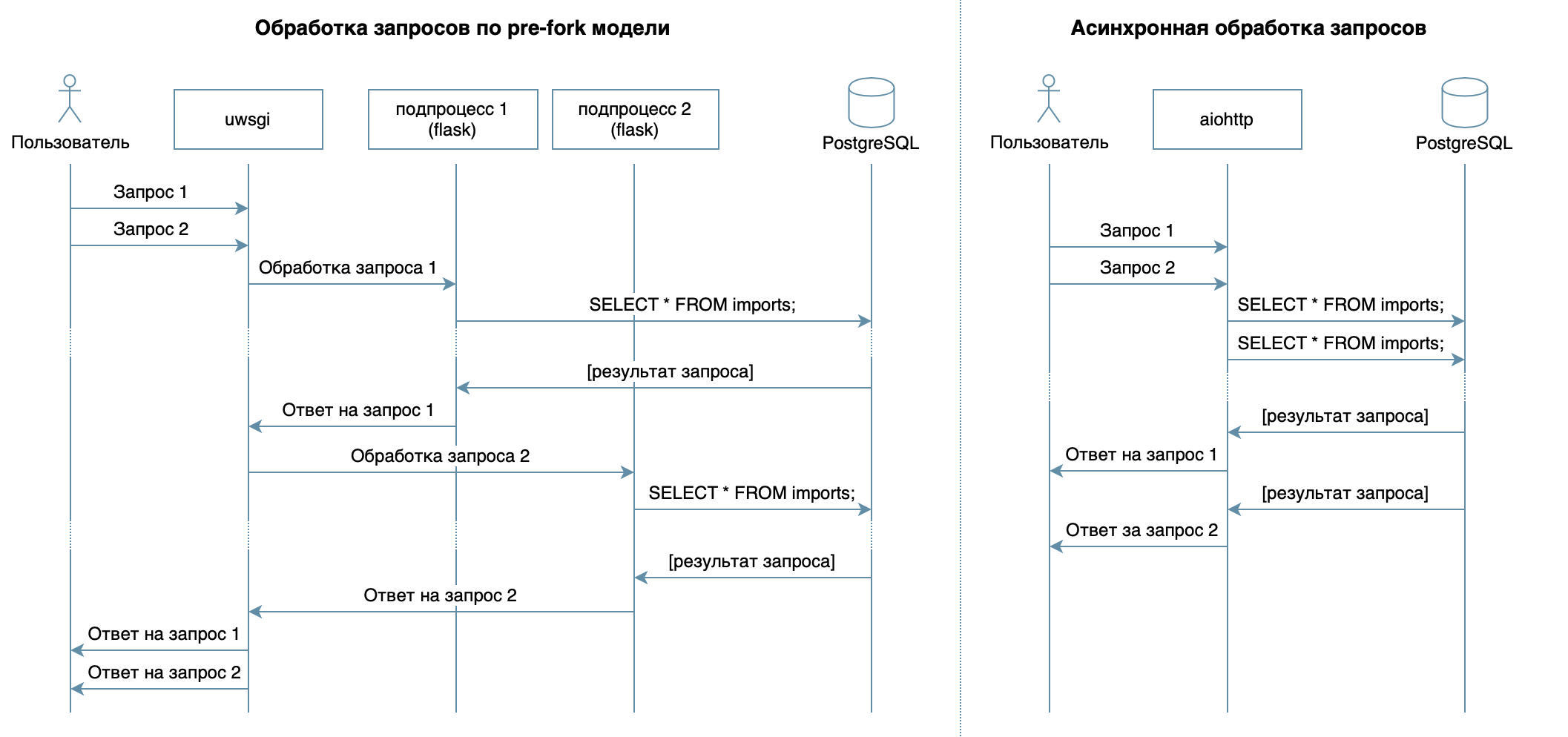
Основная задача сервиса — передача данных по сети между БД и клиентами — не предполагает большой нагрузки на процессор, но требует возможности обрабатывать несколько запросов в один момент времени. В 10 лекции рассматривается асинхронный подход. Он позволяет эффективно обслуживать нескольких клиентов в рамках одного процесса ОС (в отличие, например, от используемой во Flask/Django pre-fork-модели, которая создает несколько процессов для обработки запросов от пользователей, каждый из них потребляет память, но простаивает большую часть времени). Поэтому в качестве библиотеки для написания сервиса я выбрал асинхронный aiohttp.
Асинхронный подход позволяет эффективно обслуживать нескольких клиентов в рамках одного процесса ОС (в отличие, например, от используемой во Flask/Django pre-fork-модели, которая создает несколько процессов для обработки запросов от пользователей, и каждый из них потребляет память, но простаивает большую часть времени).
В 5 лекции видеокурса рассказывается, что SQLAlchemy позволяет декомпозировать сложные запросы на части, переиспользовать их, генерировать запросы с динамическим набором полей (например, PATCH-обработчик позволяет частичное обновление жителя с произвольными полями) и сосредоточиться непосредственно на бизнес-логике. С выполнением этих запросов и передачей данных быстрее всех справится драйвер asyncpg, а подружить их поможет asyncpgsa.
Мой любимый инструмент для управления состоянием БД и работы с миграциями — Alembic. Кстати, я недавно рассказывал о нем на Moscow Python.
Логику валидации получилось лаконично описать схемами Marshmallow (включая проверки на родственные связи). С помощью модуля aiohttp-spec я связал aiohttp-обработчики и схемы для валидации данных, а бонусом получилось сгенерировать документацию в формате Swagger и отобразить ее в графическом интерфейсе.
Для написания тестов я выбрал pytest, подробнее о нем — в 3 лекции.
Для отладки и профилирования этого проекта я использовал отладчик PyCharm (лекция 9).
В 7 лекции рассказывается, как на любом компьютере с Docker (и даже на разных ОС) можно запускать упакованное приложение без необходимости настраивать окружение для запуска и легко устанавливать/обновлять/удалять приложение на сервере.
Для деплоя я выбрал Ansible. Он позволяет декларативно описывать желаемое состояние сервера и его сервисов, работает по ssh и не требует специального софта.
Я решил дать Python-модулю название analyzer и использовать следующую структуру:

В файле analyzer/__init__.py я разместил общую информацию о модуле: описание (docstring), версию, лицензию, контакты разработчиков.
$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
Сервис с REST API, анализирующий рынок для промоакций.
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
Модуль имеет две входных точки — REST API-сервис (analyzer/api/__main__.py) и утилита управления состоянием БД (analyzer/db/__main__.py). Файлы называются __main__.py неспроста — во-первых, такое название привлекает внимание, по нему понятно, что файл является входной точкой.
Во-вторых, благодаря этому подходу к входным точкам можно обращаться с помощью команды python -m:
# REST API
$ python -m analyzer.api --help
# Утилита управления состоянием БД
$ python -m analyzer.db --helpПочему нужно начать с setup.py?
Забегая вперед, подумаем, как можно распространять приложение: оно может быть упаковано в zip- (а также wheel/egg-) архив, rpm-пакет, pkg-файл для macOS и установлено на удаленный компьютер, в виртуальную машину, MacBook или Docker-контейнер.
Главная цель файла setup.py — описать модуль для distutils/setuptools.
В файле необходимо указать общую информацию о модуле (название, версию, автора и т. д.), но также в нем можно указать требуемые для работы модули, «экстра»-зависимости (например для тестирования), точки входа (например, исполняемые команды) и требования к интерпретатору.
Плагины setuptools позволяют собирать из описанного модуля артефакт. Есть встроенные плагины: zip, egg, rpm, macOS pkg. Остальные плагины распространяются через PyPI: wheel, xar, pex.
В сухом остатке, описав один файл, мы получаем огромные возможности. Именно поэтому разработку нового модуля нужно начинать с setup.py.
В функции setup() зависимые модули указываются списком:
setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Но я описал зависимости в отдельных файлах requirements.txt и requirements.dev.txt, содержимое которых используется в setup.py. Мне это кажется более гибким, плюс тут есть секрет: впоследствии это позволит собирать Docker-образ быстрее. Зависимости будут ставиться отдельным шагом до установки самого приложения, а при пересборке Docker-контейнера попадать в кеш.
Чтобы setup.py смог прочитать зависимости из файлов requirements.txt и requirements.dev.txt, написана функция:
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Стоит отметить, что setuptools при сборке source distribution по умолчанию включает в сборку только файлы .py, .c, .cpp и .h. Чтобы файлы с зависимостями requirements.txt и requirements.dev.txt попали в пакет, их необходимо явно указать в файле MANIFEST.in.
import os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
# Возможно, модуль еще не установлен (или установлена другая версия), поэтому
# необходимо загружать __init__.py с помощью machinery.
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
# f-strings в setup.py не используются из-за соображений
# совместимости.
# Несмотря на то, что этот пакет требует Python 3.8, технически
# source distribution для него может собираться с помощью более
# ранних версий Python. Не стоит лишать пользователей этой
# возможности.
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Установить проект в режиме разработки можно следующей командой. (В editable-режиме Python не установит модуль целиком в папку site-packages, а только создаст ссылки, поэтому любые изменения, вносимые в файлы модуля, будут видны сразу.)
# Установить модуль с обычными и extra-зависимостями "dev"
pip install -e '.[dev]'
# Установить модуль только с обычными зависимостями
pip install -e .Как указать версии зависимостей?
Здорово, когда разработчики активно занимаются своими модулями — в таких модулях активнее исправляются ошибки, появляется новая функциональность и можно быстрее получить обратную связь. Но иногда изменения в зависимых библиотеках не имеют обратной совместимости и могут привести к ошибкам в вашем приложении, если не подумать об этом заранее.
Для каждого зависимого модуля можно указать определенную версию, например aiohttp==3.6.2. Тогда приложение будет гарантированно собираться именно с теми версиями зависимых библиотек, с которыми оно было протестировано. Но у этого подхода есть и недостаток — если разработчики исправят критичный баг в зависимом модуле, не влияющий на обратную совместимость, в приложение это исправление не попадет.
Существует подход к версионированию Semantic Versioning, который предлагает представлять версию в формате MAJOR.MINOR.PATCH:
MAJOR— увеличивается при добавлении обратно несовместимых изменений;MINOR— увеличивается при добавлении новой функциональности с поддержкой обратной совместимости;PATCH— увеличивается при добавлении исправлений багов с поддержкой обратной совместимости.
Если зависимый модуль следует этому подходу (о чем авторы обычно сообщают в файлах README или CHANGELOG), то достаточно зафиксировать значения MAJOR, MINOR и ограничить минимальное значение для PATCH-версии: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.
Такое требование можно реализовать с помощью оператора ~=. Например, aiohttp~=3.6.2 позволит PIP установить для aiohttp версию 3.6.3, но не 3.7.
Если указать интервал версий зависимостей, это даст еще одно преимущество — не будет конфликтов версий между зависимыми библиотеками.
Если вы разрабатываете библиотеку, которая требует другой модуль-зависимость, то разрешите для него не одну определенную версию, а интервал. Тогда потребителям вашей библиотеки будет намного легче ее использовать (вдруг их приложение требует этот же модуль-зависимость, но уже другой версии).
Semantic Versioning — лишь соглашение между авторами и потребителями модулей. Оно не гарантирует, что авторы пишут код без багов и не могут допустить ошибку в новой версии своего модуля.
База данных
Проектируем схему
В описании обработчика POST /imports приведен пример выгрузки с информацией о жителях:
{
"citizens": [
{
"citizen_id": 1,
"town": "Москва",
"street": "Льва Толстого",
"building": "16к7стр5",
"apartment": 7,
"name": "Иванов Иван Иванович",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "Москва",
"street": "Льва Толстого",
"building": "16к7стр5",
"apartment": 7,
"name": "Иванов Сергей Иванович",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "Керчь",
"street": "Иосифа Бродского",
"building": "2",
"apartment": 11,
"name": "Романова Мария Леонидовна",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
Первой мыслью было хранить всю информацию о жителе в одной таблице citizens, где родственные связи были бы представлены полем relatives в виде списка целых чисел.
- В обработчике
GET /imports/$import_id/citizens/birthdaysдля получения месяцев, на которые приходятся дни рождения родственников, потребуется выполнить слияние таблицыcitizensс самой собой. Для этого будет необходимо развернуть список с идентификаторами родственниковrelativesс помощью фунцииUNNEST.Такой запрос будет выполняться сравнительно медленно, и обработчик не уложится в 10-секундный таймаут:
SELECT relations.citizen_id, relations.relative_id, date_part('month', relatives.birth_date) as relative_birth_month FROM ( SELECT citizens.import_id, citizens.citizen_id, UNNEST(citizens.relatives) as relative_id FROM citizens WHERE import_id = 1 ) as relations INNER JOIN citizens as relatives ON relations.import_id = relatives.import_id AND relations.relative_id = relatives.citizen_id - В таком подходе целостность данных в поле
relativesне обеспечивается PostgreSQL, а контролируется приложением: технически в списокrelativesможно добавить любое целое число, в том числе идентификатор несуществующего жителя. Ошибка в коде или человеческий фактор (редактирование записей напрямую в БД администратором) обязательно рано или поздно приведут к несогласованному состоянию данных.
Далее, я решил привести все требуемые для работы данные к третьей нормальной форме, и получилась следующая структура:

- Таблица imports состоит из автоматически инкрементируемого столбца
import_id. Он нужен для создания проверки по внешнему ключу в таблицеcitizens. - В таблице citizens хранятся скалярные данные о жителе (все поля за исключением информации о родственных связях).
В качестве первичного ключа используется пара (
import_id,citizen_id), гарантирующая уникальность жителейcitizen_idв рамкахimport_id.Внешний ключ
citizens.import_id -> imports.import_idгарантирует, что полеcitizens.import_idбудет содержать только существующие выгрузки. - Таблица relations содержит информацию о родственных связях.
Одна родственная связь представлена двумя записями (от жителя к родственнику и обратно): эта избыточность позволяет использовать более простое условие при слиянии таблиц
citizensиrelationsи получать информацию более эффективно.
Первичный ключ состоит из столбцов (import_id,citizen_id,relative_id) и гарантирует, что в рамках одной выгрузкиimport_idу жителяcitizen_idбудут родственники c уникальнымиrelative_id.Также в таблице используются два составных внешних ключа:
(relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id)и(relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), гарантирующие, что в таблице будут указаны существующие жительcitizen_idи родственникrelative_idиз одной выгрузки.
Такая структура обеспечивает целостность данных средствами PostgreSQL, позволяет эффективно получать жителей с родственниками из базы данных, но подвержена состоянию гонки во время обновления информации о жителях конкурентными запросами (подробнее рассмотрим при реализации обработчика PATCH).
Описываем схему в SQLAlchemy
В лекции 5 я рассказывал, что для создания запросов с помощью SQLAlchemy необходимо описать схему базы данных с помощью специальных объектов: таблицы описываются с помощью sqlalchemy.Table и привязываются к реестру sqlalchemy.MetaData, который хранит всю метаинформацию о базе данных. К слову, реестр MetaData способен не только хранить описанную в Python метаинформацию, но и представлять реальное состояние базы данных в виде объектов SQLAlchemy.
Эта возможность в том числе позволяет Alembic сравнивать состояния и генерировать код миграций автоматически.
Кстати, у каждой базы данных своя схема именования constraints по умолчанию. Чтобы вы не тратили время на именование новых constraints или на воспоминания/поиски того, как назван constraint, который вы собираетесь удалить, SQLAlchemy предлагает использовать шаблоны именования naming conventions. Их можно определить в реестре MetaData.
# analyzer/db/schema.py
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
# Именование индексов
'ix': 'ix__%(table_name)s__%(all_column_names)s',
# Именование уникальных индексов
'uq': 'uq__%(table_name)s__%(all_column_names)s',
# Именование CHECK-constraint-ов
'ck': 'ck__%(table_name)s__%(constraint_name)s',
# Именование внешних ключей
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
# Именование первичных ключей
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Если указать шаблоны именования, Alembic воспользуется ими во время автоматической генерации миграций и будет называть все constraints в соответствии с ними. В дальнейшем cозданный реестр MetaData потребуется для описания таблиц:
# analyzer/db/schema.py
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Настраиваем Alembic
Когда схема базы данных описана, необходимо сгенерировать миграции, но для этого сначала нужно настроить Alembic, об этом тоже рассказывается в лекции 5.
Чтобы воспользоваться командой alembic, необходимо выполнить следующие шаги:
- Установить модуль:
pip install alembic - Инициализировать Alembic:
cd analyzer && alembic init db/alembic.Эта команда создаст файл конфигурации
analyzer/alembic.iniи папкуanalyzer/db/alembicсо следующим содержимым:-
env.py— вызывается каждый раз при запуске Alembic. Подключает в Alembic реестрsqlalchemy.MetaDataс описанием желаемого состояния БД и содержит инструкции по запуску миграций. script.py.mako— шаблон, на основе которого генерируются миграции.versions— папка, в которой Alembic будет искать (и генерировать) миграции.
-
- Указать адрес базы данных в файле alembic.ini:
; analyzer/alembic.ini [alembic] sqlalchemy.url = postgresql://user:hackme@localhost/analyzer - Указать описание желаемого состояния базы данных (реестр
sqlalchemy.MetaData), чтобы Alembic мог генерировать миграции автоматически:# analyzer/db/alembic/env.py from analyzer.db import schema target_metadata = schema.metadata
Alembic настроен и им уже можно пользоваться, но в нашем случае такая конфигурация имеет ряд недостатков:
- Утилита
alembicищетalembic.iniв текущей рабочей директории. Путь кalembic.iniможно указать аргументом командной строки, но это неудобно: хочется иметь возможность вызывать команду из любой папки без дополнительных параметров. - Чтобы настроить Alembic на работу с определенной базой данных, требуется менять файл
alembic.ini. Гораздо удобнее было бы указать настройки БД переменной окружения и/или аргументом командной строки, например--pg-url. - Название утилиты
alembicне очень хорошо коррелирует с названием нашего сервиса (а пользователь фактически может вообще не владеть Python и ничего не знать об Alembic). Конечному пользователю было бы намного удобнее, если бы все исполняемые команды сервиса имели общий префикс, напримерanalyzer-*.
Эти проблемы решаются с помощью небольшой обертки analyzer/db/__main__.py:
- Для обработки аргументов командной строки Alembic использует стандартный модуль
argparse. Он позволяет добавить необязательный аргумент--pg-urlсо значением по умолчанию из переменной окруженияANALYZER_PG_URL.Кодimport os from alembic.config import CommandLine, Config from analyzer.utils.pg import DEFAULT_PG_URL def main(): alembic = CommandLine() alembic.parser.add_argument( '--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL), help='Database URL [env var: ANALYZER_PG_URL]' ) options = alembic.parser.parse_args() # Создаем объект конфигурации Alembic config = Config(file_=options.config, ini_section=options.name, cmd_opts=options) # Меняем значение sqlalchemy.url из конфига Alembic config.set_main_option('sqlalchemy.url', options.pg_url) # Запускаем команду alembic exit(alembic.run_cmd(config, options)) if __name__ == '__main__': main() - Путь до файла
alembic.iniможно рассчитывать относительно расположения исполняемого файла, а не текущей рабочей директории пользователя.Кодimport os from alembic.config import CommandLine, Config from pathlib import Path PROJECT_PATH = Path(__file__).parent.parent.resolve() def main(): alembic = CommandLine() options = alembic.parser.parse_args() # Если указан относительный путь (alembic.ini), добавляем в начало # абсолютный путь до приложения if not os.path.isabs(options.config): options.config = os.path.join(PROJECT_PATH, options.config) # Создаем объект конфигурации Alembic config = Config(file_=options.config, ini_section=options.name, cmd_opts=options) # Подменяем путь до папки с alembic на абсолютный (требуется, чтобы alembic # мог найти env.py, шаблон для генерации миграций и сами миграции) alembic_location = config.get_main_option('script_location') if not os.path.isabs(alembic_location): config.set_main_option('script_location', os.path.join(PROJECT_PATH, alembic_location)) # Запускаем команду alembic exit(alembic.run_cmd(config, options)) if __name__ == '__main__': main()
Когда утилита для управления состоянием БД готова, ее можно зарегистрировать в setup.py как исполняемую команду с понятным конечному пользователю названием, например analyzer-db:
from setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
После переустановки модуля будет сгенерирован файл env/bin/analyzer-db и команда analyzer-db станет доступной:
$ pip install -e '.[dev]'Генерируем миграции
Чтобы сгенерировать миграции, требуется два состояния: желаемое (которое мы описали объектами SQLAlchemy) и реальное (база данных, в нашем случае пустая).
Я решил, что проще всего поднять Postgres с помощью Docker и для удобства добавил команду make postgres, запускающую в фоновом режиме контейнер с PostgreSQL на 5432 порту:
$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic в целом хорошо справляется с рутинной работой генерации миграций, но я хотел бы обратить внимание на следующее:
- Пользовательские типы данных, указанные в создаваемых таблицах, создаются автоматически (в нашем случае —
gender), но код для их удаления вdowngradeне генерируется. Если применить, откатить и потом еще раз применить миграцию, это вызовет ошибку, так как указанный тип данных уже существует.Удаляем тип данных gender в методе downgradefrom alembic import op from sqlalchemy import Column, Enum GenderType = Enum('female', 'male', name='gender') def upgrade(): ... # При создании таблицы тип данных GenderType будет создан автоматически op.create_table('citizens', ..., Column('gender', GenderType, nullable=False)) ... def downgrade(): op.drop_table('citizens') # После удаления таблицы тип данных необходимо удалить GenderType.drop(op.get_bind()) - В методе
downgradeнекоторые действия иногда можно убрать (если мы удаляем таблицу целиком, можно не удалять ее индексы отдельно):Напримерdef downgrade(): op.drop_table('relations') # Следующим шагом мы удаляем таблицу citizens, индекс будет удален автоматически # эту строчку можно удалить op.drop_index(op.f('ix__citizens__town'), table_name='citizens') op.drop_table('citizens') op.drop_table('imports')
Когда миграция исправлена и готова, применим ее:
$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, InitialПриложение
Прежде чем приступить к созданию обработчиков, необходимо сконфигурировать приложение aiohttp.
import logging
from aiohttp import web
def main():
# Настраиваем логирование
logging.basicConfig(level=logging.DEBUG)
# Создаем приложение
app = web.Application()
# Регистрируем обработчики
app.router.add_route(...)
# Запускаем приложение
web.run_app(app)
Этот код вызывает ряд вопросов и имеет ряд недостатков:
- Как конфигурировать приложение? Как минимум, необходимо указать хост и порт для подключения клиентов, а также информацию для подключения к базе данных.
Мне очень нравится решать эту задачу с помощью модуля
ConfigArgParse: он расширяет стандартныйargparseи позволяет использовать для конфигурации аргументы командной строки, переменные окружения (незаменимые для конфигурации Docker-контейнеров) и даже файлы конфигурации (а также совмещать эти способы). C помощьюConfigArgParseтакже можно валидировать значения параметров конфигурации приложения.Пример обработки параметров с помощью ConfigArgParsefrom aiohttp import web from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter from analyzer.utils.argparse import positive_int parser = ArgumentParser( # Парсер будет искать переменные окружения с префиксом ANALYZER_, # например ANALYZER_API_ADDRESS и ANALYZER_API_PORT auto_env_var_prefix='ANALYZER_', # Покажет значения параметров по умолчанию formatter_class=ArgumentDefaultsHelpFormatter ) parser.add_argument('--api-address', default='0.0.0.0', help='IPv4/IPv6 address API server would listen on') # Разрешает только целые числа больше нуля parser.add_argument('--api-port', type=positive_int, default=8081, help='TCP port API server would listen on') def main(): # Получаем параметры конфигурации, которые можно передать как аргументами # командной строки, так и переменными окружения args = parser.parse_args() # Запускаем приложение на указанном порту и адресе app = web.Application() web.run_app(app, host=args.api_address, port=args.api_port) if __name__ == '__main__': main()
Кстати,ConfigArgParse, как иargparse, умеет генерировать подсказку по запуску команды с описанием всех аргументов (необходимо позвать команду с аргументом-hили--help). Это невероятно облегчает жизнь пользователям вашего ПО:Например$ python __main__.py --help usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT] If an arg is specified in more than one place, then commandline values override environment variables which override defaults. optional arguments: -h, --help show this help message and exit --api-address API_ADDRESS IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0) --api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081) - После получения переменные окружения больше не нужны и даже могут представлять опасность — например, они могут случайно «утечь» с отображением информации об ошибке. Злоумышленники в первую очередь будут пытаться получить информацию об окружении, поэтому очистка переменных окружения считается хорошим тоном.
Можно было бы воспользоваться
os.environ.clear(), но Python позволяет управлять поведением модулей стандартной библиотеки с помощью многочисленных переменных окружения (например, вдруг потребуется включить режим отладкиasyncio?), поэтому разумнее очищать переменные окружения по префиксу приложения, указанного вConfigArgParser.Примерimport os from typing import Callable from configargparse import ArgumentParser from yarl import URL from analyzer.api.app import create_app from analyzer.utils.pg import DEFAULT_PG_URL ENV_VAR_PREFIX = 'ANALYZER_' parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX) parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL), help='URL to use to connect to the database') def clear_environ(rule: Callable): """ Очищает переменные окружения, переменные для очистки определяет переданная функция rule """ # Ключи из os.environ копируются в новый tuple, чтобы не менять объект # os.environ во время итерации for name in filter(rule, tuple(os.environ)): os.environ.pop(name) def main(): # Получаем аргументы args = parser.parse_args() # Очищаем переменные окружения по префиксу ANALYZER_ clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX)) # Запускаем приложение app = create_app(args) ... if __name__ == '__main__': main() - Запись логов в stderr/файл в основном потоке блокирует цикл событий.
В лекции 9 рассказывается, что по умолчанию
logging.basicConfig()настраиваетзапись логов в stderr.Чтобы логирование не мешало эффективной работе асинхронного приложения, необходимо выполнять запись логов в отдельном потоке. Для этого можно воспользоваться готовым методом из модуля aiomisc.
Настраиваем логирование с помощью aiomiscimport logging from aiomisc.log import basic_config basic_config(logging.DEBUG, buffered=True) - Как масштабировать приложение, если одного процесса станет недостаточно для обслуживания входящего трафика? Можно сначала аллоцировать сокет, затем с помощью
forkсоздать несколько новых отдельных процессов, и соединения на сокете будут распределяться между ними механизмами ядра (конечно, под Windows это не работает).Примерimport os from sys import argv import forklib from aiohttp.web import Application, run_app from aiomisc import bind_socket from setproctitle import setproctitle def main(): sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http') setproctitle(f'[Master] {os.path.basename(argv[0])}') def worker(): setproctitle(f'[Worker] {os.path.basename(argv[0])}') app = Application() run_app(app, sock=sock) forklib.fork(os.cpu_count(), worker, auto_restart=True) if __name__ == '__main__': main() - Требуется ли приложению обращаться или аллоцировать какие-либо ресурсы во время работы? Если нет, по соображениям безопасности все ресурсы (в нашем случае — сокет для подключения клиентов) можно аллоцировать на старте, а затем сменить пользователя на
nobody. Он обладает ограниченным набором привиллегий — это здорово усложнит жизнь злоумышленникам.Примерimport os import pwd from aiohttp.web import run_app from aiomisc import bind_socket from analyzer.api.app import create_app def main(): # Аллоцируем сокет sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http') user = pwd.getpwnam('nobody') os.setgid(user.pw_gid) os.setuid(user.pw_uid) app = create_app(...) run_app(app, sock=sock) if __name__ == '__main__': main() - В конце концов я решил вынести создание приложения в отдельную параметризуемую функцию
create_app, чтобы можно было легко создавать идентичные приложения для тестирования.
Сериализация данных
Все успешные ответы обработчиков будем возвращать в формате JSON. Информацию об ошибках клиентам тоже было бы удобно получать в сериализованном виде (например, чтобы увидеть, какие поля не прошли валидацию).
Документация aiohttp предлагает метод json_response, который принимает объект, сериализует его в JSON и возвращает новый объект aiohttp.web.Response с заголовком Content-Type: application/json и сериализованными данными внутри.
from aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Но существует и другой способ: aiohttp позволяет зарегистрировать произвольный сериализатор для определенного типа данных ответа в реестре aiohttp.PAYLOAD_REGISTRY. Например, можно указать сериализатор aiohttp.JsonPayload для объектов типа Mapping.
В этом случае обработчику будет достаточно вернуть объект Response с данными ответа в параметре body. aiohttp найдет сериализатор, соответствующий типу данных и сериализует ответ.
Помимо того, что сериализация объектов описана в одном месте, этот подход еще и более гибкий — он позволяет реализовывать очень интересные решения (мы рассмотрим один из вариантов использования в обработчике GET /imports/$import_id/citizens).
from types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Важно понимать, что метод json_response, как и aiohttp.JsonPayload, используют стандартный json.dumps, который не умеет сериализовать сложные типы данных, например datetime.date или asyncpg.Record (asyncpg возвращает записи из БД в виде экземпляров этого класса). Более того, одни сложные объекты могут содержать другие: в одной записи из БД может быть поле типа datetime.date.
Разработчики Python предусмотрели эту проблему: метод json.dumps позволяет с помощью аргумента default указать функцию, которая вызывается, когда необходимо сериализовать незнакомый объект. Ожидается, что функция приведет незнакомый объект к типу, который умеет сериализовать модуль json.
import json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
Позволяет автоматически сериализовать результаты запроса, возвращаемые
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(
