Повышение производительности с использованием uop-кэша на Sandy Bridge+
В современных x86 процессорах Intel, конвеер можно разделить на 2 части: Front End и Back End.
Front End отвечает за загрузку кода из памяти и его декодирование в микрооперации.
Back End отвечает за выполнение микроопераций, пришедших от Front End. Поскольку эти микрооперации могут выполняться ядром не по порядку, то Back End также следит за тем, чтобы результат выполнения этих микроопераций строго соответствовал порядку в котором они идут в коде.
В большинстве случаев не эффективное использование Front End’a не оказывает заметного влияние на производительность. Пиковая пропускная способность на большинстве процессоров Intel — 4 микрооперации за такт, поэтому, например, для Memory/L3-bound кода ЦПУ не сможет полностью ее утилизировать.
Если верить оффициальной документации, то пиковая пропускная способность у Ice Lake была увеличена с 4 до 5 микроопераций за такт. К сожалению, доступа с этой модели цпу у меня нет, поэтому убедиться в этом на практике не предоставляется возможности.
Однако в некоторых случаях различие в производительности может быть достаточно существенно. Под катом — анализ влияния кэша микроопераций на производительность.
Содержание статьи
- Окружение
- Обзор Front End’a процессоров Intel
- Анализ пиковой пропускной способности µop cache --> IDQ
- Пример
Окружение
Для всех замеров в данной статье будет использоваться i7-8550U Kaby Lake, HT включен/Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. В данном случае такое окружение может быть существенным, т.к. у каждой модели CPU определены свои перфоманс эвенты. В частности, для микроархитектур старше Sandy Bridge некоторые из эвентов, используемых в дальнейшем, просто не имеют смысла.
Обзор Front End’a процессоров Intel
Высокоуровневая организация конвеера — публично доступная информация и опубликована в оффициальной документации Intel по оптимизации софта. Более детальное описание некоторых особенностей, которые опущены в оффициальной документации можно найти в других авторитетных источниках, таких как Agner Fog или Travis Downs. Так, например, схема конвеера для Skylake в документации Intel имеет вид:
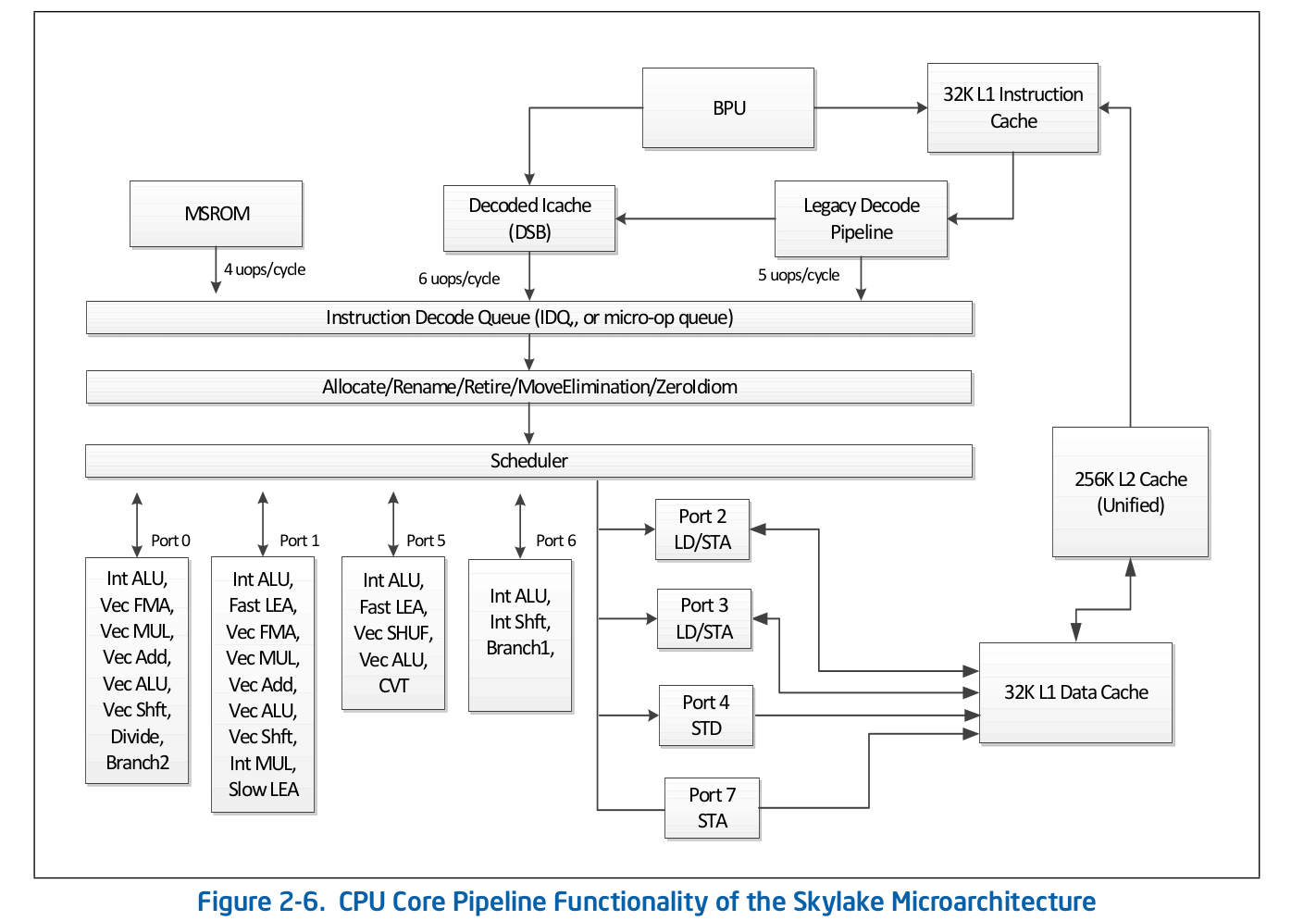
Рассмотрим подробнее верхнюю часть данной схемы — Front End.

За декодирование кода в микрооперации отвечает Legacy Decode Pipeline. Он состоит из следующих компонентов:
- Instruction Fetch Unit — IFU
- Кэш инструкций первого уровная — L1i
- Кэш трансляций логических адресов инструкций — ITLB
- Перфетчер инструкций
- Пре-декодер инструкций
- Очередь пре-декодированных инструкций
- Декодеры пре-декодированных инструкций в микрооперации
Рассмотрим каждую из частей Legacy Decode Pipeline по отдельности.
Instruction Fetch Unit.
Отвечает за загрузку кода, предекодирование (определение длины инструкции и свойств типа «является ли инструкция ветвлением») и доставку в очередь пре-декодированных инструкций.
Кэш инструкций первого уровная — L1i
Для загрузки кода IFU использует L1i — кэш инструкций первого уровная и L2/LLC — кэш второго и offcore-кэш верхнего уровня, общие для кода и данных. Загрузка выполняется кусками по 16 байт, также выровненные на 16-байт. При загрузке следующего по порядку 16-байтного куска кода происходит обращение к L1i и, если соответсвующая линия не найдена, то выполняется поиск в L2 и, в случае не успеха, в LLC и памяти. До Skylake, LLC кэш был инклюзивным — каждая линия в L1(i/d) и L2 должны была содержаться в LLC. Таким образом LLC «знал» про все линии во всех ядрах и, в случае LLC промаха было известно, содержат ли кэши в других ядрах требуемую линию в состоянии Modified, а значит данная линия могла быть загружена из друго ядра. В Skylake, LLC стал не инклюзивным L2-victim кэшем, однако в 4 раза был увеличен размер L2. Мне не известно, является ли L2 инклюзивным по отношению к L1i. L2 не инклюзивный по отношению к L1d.
Кэш трансляций логических адресов инструкций — ITLB
Перед тем как загружать данные из кэша, необходимо выполнить поиск соответствующей линии. Для n-way ассоциативных кэшей, каждая линия может находится в n различных местах в самом кэше. Для определеления возможных позиций в кэше используется индекс (как правило несколько младших бит адреса). Для определения, соответствует ли линия тому адресу, который нам нужен — используется тэг (оставшая часть адреса). Какие адреса использовать: физические или логические — зависит от релазации кэша. Использование физических адресов требует выполнения адресной трансляции. Для трансляции адресов используется TLB — буффер, который кэширует результаты page walk’ов, сокращая тем самым задержку на получение физического адреса из логического при последующих обращениях. Для инструкций есть свой Instruction TLB буффер, располагающийся отдельно от Data TLB. В цпу ядре также присутствует общий для кода и данных TLB второго уровня — STLB. Является ли STLB инклюзивным — мне не известно (по слухам, это не инклюзивный victim кэш по отношению к D/I TLB). Используя инструкцию Software перфетча prefetcht1 можно подтянуть линию с кодом в L2, однако соответствующая TLB запись будет подтянута только в DTLB. Если STLB не инклюзивный, то, при поиске этой линии с кодом в кэшах, будет получено ITLB miss --> STLB miss --> page walk (на самом деле не все так просто, посколько ядро может инициировать спекулятивный page walk до того как произойдет TLB miss). Документация Intel также не рекомендует использовать SW перфетчи для кода, Intel Software Optimization Manual/2.5.5.4:
The software-controlled prefetch is intended for prefetching data, but not for prefetching code.
Однако Travis D. упоминал, что подобный префетч может быть весьма эффектиным (и скорее всего это так и есть), но мне пока что это не очевидно и для того, чтобы в этом убедиться нужно будет отдельно исследовать этот вопрос.
Перфетчер инструкций
Загрузка данных в кэш (L1d/i, L2, etc) происходит при обращении к незакэшированному участку памяти. Однако, если бы это происходило только при таких условия, то в результате мы бы получили не эффективное использование пропускной способности кэша. Например, на Sandy Bridge для L1d — 2 операции на чтение, 1 на запись по 16 байт за такт; для L1i — 1 операция на чтение по 16 байт, пропускная способность на запись не указана в документации, у Agner Fog также не обнаружилось. Для решения этой проблемы существуют Hardware префетчеры, которые умеют определять паттерн доступа к памяти и подтягивать нужные линии в кэш до того, как код по факту к ним обратится. Документация Intel определяет 4 префетчера: 2 для L1d, 2 для L2:
1. L1 DCU — префетчит последовательные кэш линии. Только для чтений вперед
2. L1 IP — если инструкция по некоторому адресу читает из памяти по адресам с определенным шагом (напр. 0×5555555545a0, 0×5555555545b0, 0×5555555545c0, …, то память по адресу, следующему такому паттерну, будет запрефетчена)
3. L2 Spatial — при обращении к кэш линии в L2 будет запрефетчена соседняя кэш-линия, так что итоговая область будет выровнена на 128-байт. В ряде случаев префетчит только в LLC
4. L2 Streamer — префетчит последовательные кэш линии. В отличии от L1 DCU может префетчить при последовательном чтении «назад». В ряде случаев префетчит только в LLC
Документация Intel никак не описывает принцип работы L1i перфетчера. Все что известно — это то, что в этом процессе учавствует Branch Prediction Unit (BPU), Intel Software Optimization Manual/2.6.2:

У Agner Fog каких-либо деталей также не просматривается.
Префетч кода в L2/LLC явно определены только для Streamer. Optimization Manual/2.5.5.4 Data Prefectching:
Streamer: This prefetcher monitors read requests from the L1 cache for ascending and descending sequences of addresses. Monitored read requests include L1 DCache requests initiated by load and store operations and by the hardware prefetchers, and L1 ICache requests for code fetch.
Для Spatial префетчера это явно не прописано:
Spatial Prefetcher: This prefetcher strives to complete every cache line fetched to the L2 cache with the pair line that completes it to a 128-byte aligned chunk.
Но это может быть проверено. Каждый из этих префетчеров может быть выключен с помощью MSR 0x1A4, как описано в мануале Model-Specific Registers
В Linux есть msr драйвер, позволяющий настраивать msr вручную для каждого физического ядра. Например $ sudo wrmsr -p 1 0x1a4 1 выключит L2 Streamer для ядра 1.
Пре-декодер инструкций
После того как очередные 16-байт кода загружены, они попадают в пре-декодер инструкций. Его задача — определить длину инструкции, декодировать префиксы и пометить, является ли соответствующая инструкция ветвлением (скорее всего еще много разных свойств, но документация о них умалчивает). Intel Software Optimization Manual/2.6.2.2:
The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
• Determine the length of the instructions.
• Decode all prefixes associated with instructions.
• Mark various properties of instructions for the decoders (for example, «is branch.»).
Очередь пре-декодированных инструкций.
Из IFU инструкции складываются в очередь предекодированных инструкций. Данная очередь появилась начиная с Nehalem, в соответвствии с документацие Intel ее размер — 18 инструкций. Agner Fog также упоминает, что в эту очередь вмещается не больше 64 байт.
Также в Core2 данная очередь использовалась как кэш циклов (loop cache). Если все микрооперации из цикла содержатся в очереди, то в ряде случаев можно было бы избежать затраты на загрузку и предекодирование. Loop Stream Detector (LSD) может доставлять инструкции, которые уже есть в очереди до тех пор, пока BPU не просигналит, что цикл закончился. У Agner Fog есть ряд интересных замечаний касательно LSD на Core2:
- Состоит из 4 линий по 16 байт
- Пиковая пропускная способность до 32 байт кода за такт
Начиная с Sandy Bridge, данный кэш циклов переехал из очереди пре-декодировнных инструкций обратно в IDQ.
Декодеры пре-декодированных инструкций в микрооперации
Из очереди пре-декодированных инструкций код поступает на декодирование в микрооперации. За декодирование отвечают декодеры — всего их 4. В соответствии с документацией Intel, один из декодеров умеет декодировать инструкции, состоящие из 4-х микроопераций и менее. Остальные декодируют инструкции состоящие из одной микрооперации (micro/macro fused), Intel Software Optimization Manual/2.5.2.1:
There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Инструкции, декодируемые в большое количество микрооперация (напр. rep movsb, используемая в реализации memcpy в libc на определенных размерах копируемой памяти) поступают из Microcode Sequencer (MS ROM). Пиковая пропускная способность секвенсера — 4 микрооперации за такт.
Как можно видеть на схеме конвеера, Legacy Decode Pipeline может декодировать до 5 микроопераций за такт на Skylake. На Broadwell и старше пиковая пропускная способность Legacy Decode Pipeline’a была 4 микрооперации за такт.
Кэш микроопераций
После того, как инструкции декодированы в микрооперации, из Legacy Decode Pipeline они попадают в специальную очередь микроопераций — Instruction Decode Queue (IDQ), а также в так называемый кэш микроопераций (Decoded ICache, µop cache). Кэш микроопераций изначально появился в Sandy Bridge и используется для того, чтобы избежать фетчинга и декодирования инструкций в микрооперации, повышая тем самым пропускную способность доставки микроопераций в IDQ — до 6 за такт. После попадания в IDQ, микрооперации уходят в Back End на выполнение с пиковой пропускной способностью — 4 микрооперации за такт.
В соответствии с документацией Intel, кэш микроопераций состоит из 32-х сетов, каждый сет содержит по 8 линий, каждая линия может кэшировать до 6 микроопераций (micro/macro fused), позволяя в общей сложности кэшировать до 32×8 * 6 = 1536 микроопераций. Кэширование микроопераций происходит с гранулярностью в 32 байта, т.е. микрооперации, которые соответствуют инструкциям из разных 32-байтных регионов не могут попасть в одну линию. Тем не менее, одному 32-байтному региону может соответствовать до 3-х различных линий кэша. Таким образом каждому 32-байтному региону может соответствовать до 18 микроопераций в µop cache.
The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:• All micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
• Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
• A multi micro-op instruction cannot be split across Ways.
• Up to two branches are allowed per Way.
• An instruction which turns on the MSROM consumes an entire Way.
• A non-conditional branch is the last micro-op in a Way.
• Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
• A pair of macro-fused instructions is kept as one micro-op.
• Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog также упоминает, что за такт может быть загружены микрооперации только из одной линии (явно не прописано в документации Intel, хотя и легко проверяется в ручную).
Анализ пиковой пропускной способности µop cache --> IDQ
В ряде случаев для исследования поведения Front End очень удобно использовать nop-ы длинной в 1 байт. При этом мы можем быть уверены, что исследуем именно Front End, а не Resource Stall на Back End в силу каких-либо причин. Дело в том, что nop-ы, также как и другие инструкции, декодируются в Legacy Decode Pipeline, сладываются в µop cache и отправляются в IDQ. Далее nop-ы, также как и другие инструкции, забирает Back End. Существенное отличие состоит в том, что из ресурсов на Back End nop использует только Reorder Buffer и не требует выделения слота в Reservation Station (a.k.a Scheduler). Таким образом, сразу после попадания в Reorder Buffer, nop готов к retirement’у, который будет выполнен в соответствии с порядком в программном коде.
Для тестирования пропускной способности объявим функцию
void test_decoded_icache(size_t iteration_count);с реализацией на nasm:
align 32
test_decoded_icache:
;nop'ы, от 0 до 23 включительно
dec rdi
ja test_decoded_icache
ret
ja было выбрано не случайно. ja и dec используют разные флаги — ja читает из CF и ZF, dec не записывает в CF, поэтому Macro Fusion не применяется. Это сделано чисто для удобства подсчета микроопераций в цикле — каждой инстукции соответствует одна микрооперация.
Для замеров нам понадобятся следующие perf эвенты:
1. uops_issued.any — Используется для подсчета микроопераций которые Renamer забирает из IDQ.
Intel System Programming Guide документирует этот эвент как количество микроопераций, которые Renamer кладет в Reservation Station:
Counts the number of uops that the Resource Allocation Table (RAT) issues to the Reservation Station (RS).
Данное описание не совсем коррелирует со значениями, которые можно получить из экспериментов. В частности, nop-ы попадают в данный каунтер, хотя очевиндо, что в Reservation Station они совсем не нужны.
2. uops_retired.retire_slots — итоговое количество retired микроопераций с учетом micro/macro-fusion
3. uops_retired.stall_cycles — количество тактов, за которые не было ни одной retired микрооперации
4. resource_stalls.any — количество тактов простаивания конвеера по причине недоступности любого из ресурсов Back End
В Intel Software Optimization Manual/B.4.1 приведена содеражательная схема, которая характеризует описанные выше эвенты:

5. idq.all_dsb_cycles_4_uops — количество тактов, за которые из µop cache было доставлено по 4 (и более) инструкции.
То, что данная метрику учитывает доставку более 4х микроопераций за такт — не прописано в документации Intel, однако очень хорошо согласуется с экспериментами.
6. idq.all_dsb_cycles_any_uops — количество тактов, за которые доставлялась хотя бы одна микрооперация.
7. idq.dsb_cycles — Итоговое количество тактов, при которых была доставка из µop cache
8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core — Количество тактов, за которые Renamer забирал по N или меньше микроопераций и не было простоя на стороне Back End, N — 1, 2, 3.
Для исследования возьмем iteration_count = 1 << 31. Анализ происходящего в ЦПУ начнем с исследования количества микроопераций и для начала замерием средний retirement bandwidth, т.е. uops_retired.retire_slots/uops_retired.total_cycle:

Что сразу бросается в глаза, так это проседание пропускной способности retirement’a при размере цикла в 7 микроопераций. Для того, чтобы понять в чем дело, рассмотрим как меняется средняя скорость доставки из µop cache — idq.all_dsb_cycles_any_uops / idq.dsb_cycles:

и как связаны общее количество тактов и тактов за которые µop cache доставлял в IDQ:

Таким образом можно заметить, что при цикле из 6 микроопераций мы получаем эффективное использование пропускной способности µop cache — 6 микроопераций за такт. В силу того, что Renamer не может забрать столько, сколько доставляет µop cache, то часть тактов µop cache ничего не доставляет, что хорошо видно на предыдущем графике.
При цикле из 7 микроопераций мы получаем резкое падение пропускной способности µop cache — 3.5 микрооперации за такт. При этом, как видно из предыдущего графика, µop cache постоянно находится в работе. Таким оразом, при цикле размером в 7 микроопераций мы получаем не эффективную утилизацию пропускной способности µop cache. Дело в том, что, как было отмечено ранее, µop cache за такт может доставлять микрооперации только из одной линии. В случае, если микроопераций 7 — первые 6 попадают в одну линию, а оставшаяся 7я — в другую. Такими образом и получаем 7 микроопераций за 2 такта, или же 3.5 микрооперации за такт.
Рассмотрим теперь каким образом Renamer забирает микрооперации из IDQ. Для этого нам понадобятся idq_uops_not_delivered.core и idq_uops_not_delivered.cycles_le_N_uop_deliv.core:

Можно заметить, что при 7-ми микрооперациях, половину тактов Renamer забирает только 3 микрооперации за раз. Отсюда мы и получаем пропускную способность retirement’а в среднем 3.5 микрооперации за такт.
Другой интересный момент, связанный с данным примером можно увидеть, если рассмотреть эффективную пропускную способность retirement’а. Т.е. не учитывая uops_retired.stall_cycles:

Можно заметить, что при 7-ми микрооперациях, каждые 7 тактов выполняется retirement 4-х микроопераций, а каждый 8-й такт происходит простаивании с отсутствием retired микроопераций (retirement stall). Проведя ряд экспериментов, удалось обнаружить, что такое поведение наблюдалось всегда при 7-ми микрооперациях, вне зависимости от их компоновки 1–6, 6–1, 2–5, 5–2, 3–4, 4–3. Мне на известно, почему происходит именно так, а не, например за один такт выполняется retirement 3-х микроопераций, за следующий — 4-х. Agner Fog упоминал, что переходы по ветвлениям могут использовать только часть слотов retirement station. Может быть это ограничение и есть причина такого поведения retirement’а.
Пример
Для того, чтобы понять, оказывает ли это все влияние на практике, рассмотрим следующий чуть более практический пример, чем с nop-ами:
Даны два массива unsigned'ов. Необходимо накопить сумму средних арифметических для каждого индекса и записать ее в третий массив.
Пример реализации может выглядеть следующим образом:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}Скомпилируем с gcc-флагами -Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Вполне очевидно, что функция arithmetic_mean не будет присутствовать в коде и будет вставлена напрямую в main:
(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8
#...
Заметим, что компилятор выравнил код цикла на 32 байта (nop DWORD PTR [rax+0x0]), а это как раз то, что нам нужно. Убедившись в отсутствии resource_stalls.any на Back End (все замеры выполнены с учетом прогретого L1d кэша) можно приступать к рассмотрению каунтеров, связанных с доставкой в IDQ:
Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Заметим, что retirement badwidth в данном случае = 15147004678 / 4724790623 = 3.20585733562, а также, что половину тактов Renamer забирает только по 3 микрооперации.
Добавим теперь ручную раскрутку цикла в реализацию:
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++; //компилятор объединит этот idx++ с предыдущим в один idx+=2
}
__asm__ __volatile__("" ::: "memory");
}Получившиеся перф каунтеры имеют вид:
Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
В данном случае имеем retirement bandwidth = 13037919196 / 3444833440 = 3.78477491672, а также эффективную утилизацию пропускной способности Renamer.
Таким образом мы не только избавились от одного ветвления и одной операции инкремента в цикле, но и увеличили retirement bandwidth используя эффективную утилизацию пропускной способности кэша микроопераций, что дало итоговые 28% прироста к производительности.
Заметим, что только лишь сокращение одного ветвления и операции инкремента дает прирост производительности в среднем на 9%.
Небольшое замечание
На ЦПУ, который использовался для выполнения данных экспериментов, выключен LSD. Кажется, что LSD мог бы обработать такую ситуацию. Для ЦПУ со включенным LSD подобные случаи нужно будет исследовать отдельно.
