PostgreSQL: PipelineDB — агрегирующие запросы в режиме реального времени
Вас когда-либо просили посчитать количество чего-то на основании данных в бд за последний месяц, сгруппировав результат по каким-то значениям и разбив всё это ещё по дням/часам?
Если да — то вы уже представляете, что вам придётся написать что-то вроде такого, только хуже
SELECT hour(datetime), somename, count(*), sum(somemetric)
from table
where datetime > :monthAgo
group by 1, 2
order by 1 desc, 2
Время от времени самые разнообразные подобные запросы начинают появляться, и если один раз стерпишь и поможешь — увы, обращения будут поступать и в будущем
А плохи такие запросы тем, что хорошо отнимают ресурсы системы на время выполнения, да и данных может быть так много, что даже реплику для таких запросов будет жаль (и своего времени)
А что если я скажу, что прямо в PostgreSQL можно создать вьюху, которая на лету будет учитывать только новые поступающие данные в прямо подобном запросе, как выше?
Так вот — это умеет делать расширение PipelineDB

Ранее PipelineDB был отдельным проектом, но теперь доступен как расширение для PG 10.1 и выше
И хотя предоставляемые возможности уже давно существуют в иных продуктах, специально созданных для сбора метрик в режиме реального времени — у PipelineDB есть существенный плюс: меньший порог вхождения для разработчиков, которые уже умеют SQL)
Возможно для кого-то это несущественно. Лично я не ленюсь пробовать всё, что кажется подходящим для решения той или иной задачи, но и не двину тут же юзать одно новое решение на все случаи. Потому в этой заметке я не призываю тут же бросать всё и устанавливать PipelineDB, это лишь обзор основного функционала, т.к. штука мне показалась любопытной.
И так, в целом документация у них хорошая, но я хочу поделиться опытом, как это дело попробовать на практике и вывести результаты в Grafana
Чтобы не захламлять локальную машину всё разворачиваю в докере
Используемые образы: postgres:latest, grafana/grafana
Установка PipelineDB на Postgres
На машине с postgres выполнить последовательно:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Открыть в любом редакторе файл
postgresql.conf - Найти ключ
shared_preload_libraries, расскоментить и установить значениеpipelinedb - Ключ
max_worker_processesустановить в значение 128 (рекомендация доки) - Ребутнуть сервер
Создание потока и вьюх в PipelineDB
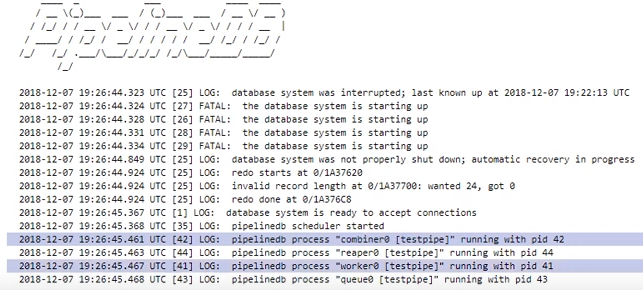
- Бд в которой будем работать:
CREATE DATABASE testpipe; - Создание расширения:
CREATE EXTENSION pipelinedb; - Теперь самое интересное — создание стрима. Именно в него необходимо добавлять данные для дальнейшей обработки:
По сути очень похоже на создание обыкновенной таблицы, только получить данные из этого стрима простымCREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;selectнельзя — нужна вьюха - собственно как её создать:
Называются они Continuous Views и по дефолту materialize, т.е. с сохранением состоянияCREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
В выраженииWITHпередаются дополнительные параметры.
В моём случаеttl = '3 month'говорит о том, что хранить нужно данные только за последние 3 месяца, а брать дату/время из колонкиM. Фоновый процессreaperищет устаревшие данные и удаляет их
Для тех, кто не в курсе — функцияminuteвозвращает дату/время без секунд. Таким образом все события, произошедшие в одну минуту будут иметь одно и то же время в результате агрегации - Такая вьюха — практически таблица, потому индекс по дате для выборки будет полезным, если данных будет храниться много
create index on viewflow (m desc, action);
Использование PipelineDB
Помни: вставлять данные в стрим, а читать — из подписавшихся на него вьюх
insert into flow_stream VALUES (now(), 'act1', 21);
insert into flow_stream VALUES (now(), 'act2', 33);
select * from viewflow order by m desc, action limit 4;
select now()
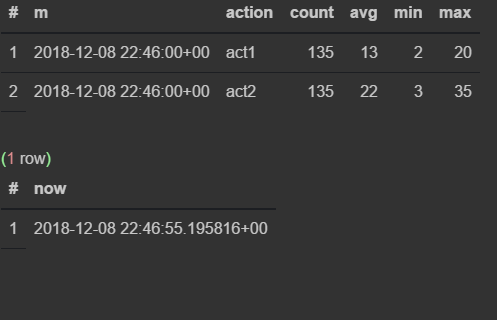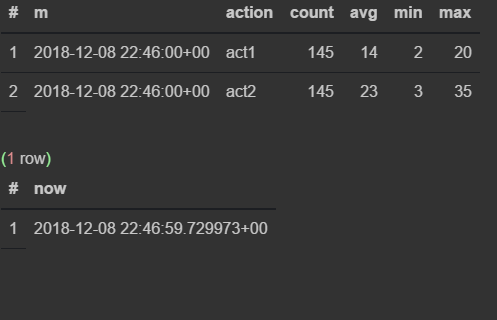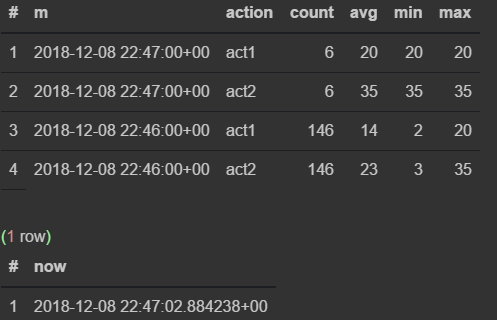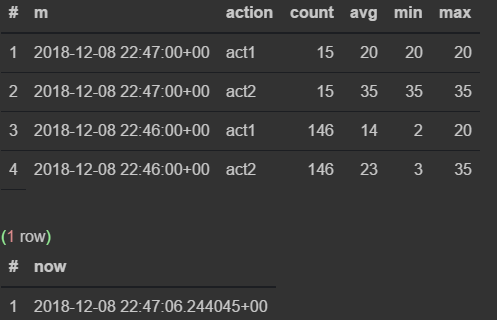
Сначала наблюдаю, как меняются данные в 46-ю минуту
Как только наступает 47-я — предыдущая прекращает обновляться и начинает тикать текущая минута
Если обратить внимание на план запроса, то можно увидеть оригинальную таблицу с данными
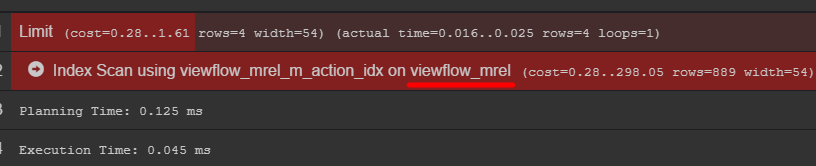
Рекомендую сходить в неё и узнать, как на самом деле хранятся ваши данные
using Npgsql;
using System;
using System.Threading;
namespace PipelineDbLogGenerator
{
class Program
{
private static Random _rnd = new Random();
private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" };
static void Main(string[] args)
{
var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe";
using (var conn = new NpgsqlConnection(connString))
{
conn.Open();
while (true)
{
var dt = DateTime.UtcNow;
using (var cmd = new NpgsqlCommand())
{
var act = GetAction();
cmd.Connection = conn;
cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)";
cmd.Parameters.AddWithValue("dtmsk", dt);
cmd.Parameters.AddWithValue("action", act);
cmd.Parameters.AddWithValue("duration", GetDuration(act));
var res = cmd.ExecuteNonQuery();
Console.WriteLine($"{res} {dt}");
}
Thread.Sleep(_rnd.Next(50, 230));
}
}
}
private static int GetDuration(string act)
{
var c = 0;
for (int i = 0; i < act.Length; i++)
{
c += act[i];
}
return _rnd.Next(c);
}
private static string GetAction()
{
return _actions[_rnd.Next(_actions.Length)];
}
}
}
Вывод в Grafana
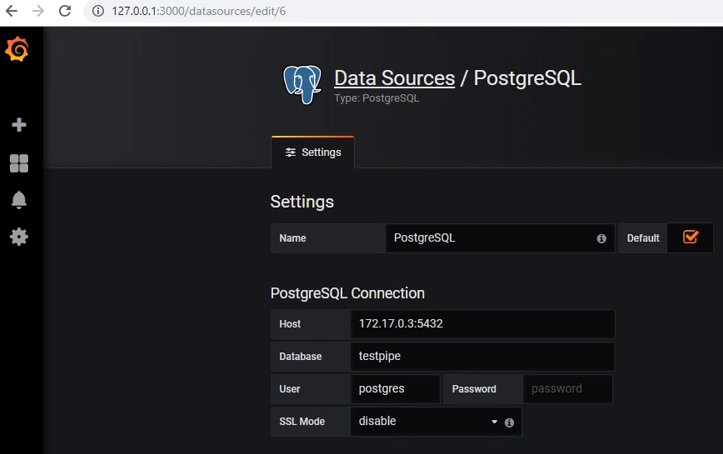
Для получения данных из postgres нужно добавить соответствующий источник данных:
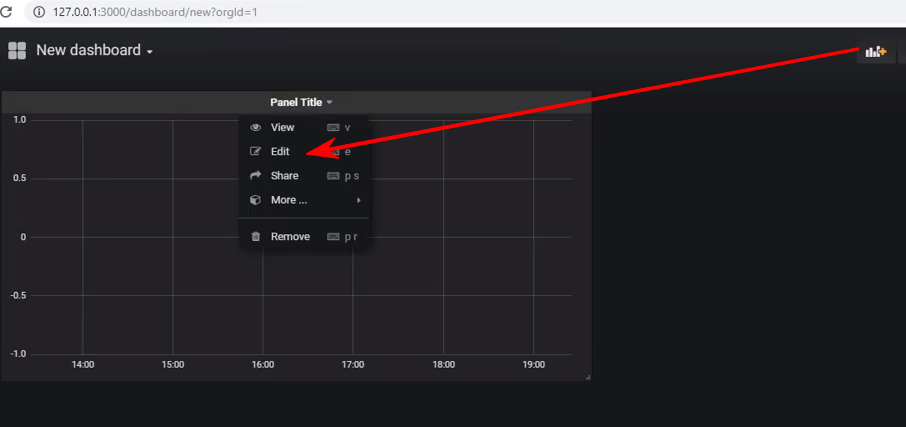
Создать новую дашборду и добавить на неё панель типа Graph, а после нужно перейти в редактирование панели:
Далее — выбрать источник данных, переключиться в режим написания sql-запроса и ввести такое:
select
m as time, -- Grafana требует колонку time
count, action
from viewflow
where $__timeFilter(m) -- макрос графаны, принимает на вход имя колонки, на выходе col between :startdate and :enddate
order by m desc, action;
И тут же получается нормальный график, конечно, если вы запустили генератор событий
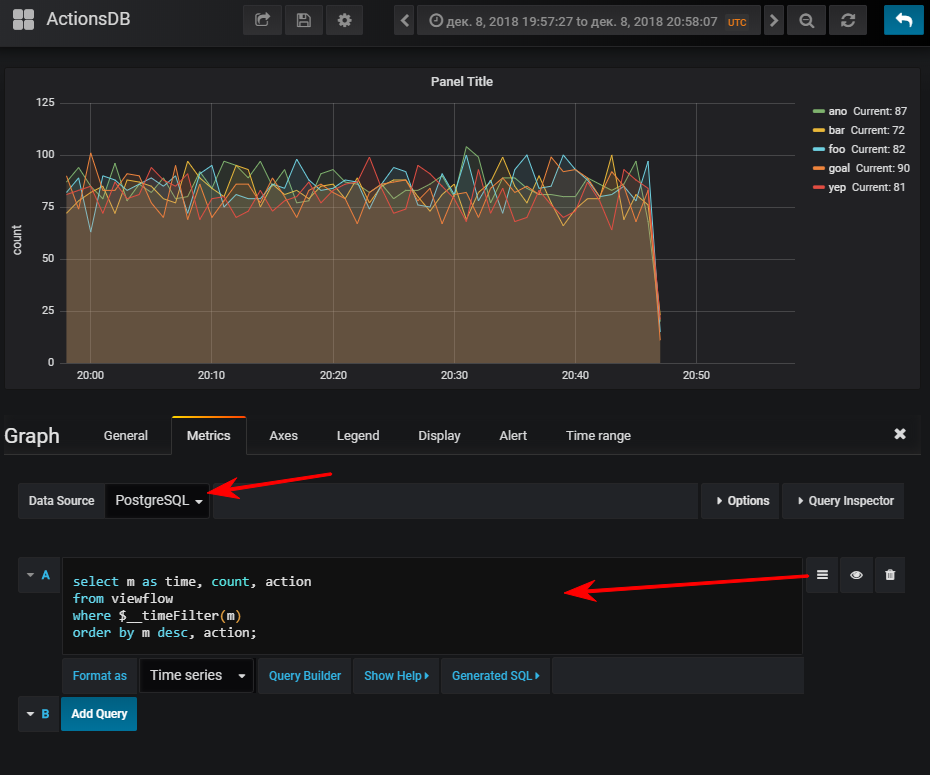
FYI: наличие индекса может оказаться очень важным. Хотя его использование зависит от объёма получившейся таблицы. Если вы планируете хранить небольшое количество строк за небольшое количество времени, то очень легко может оказаться, что seq scan будет дешевле, а индекс лишь добавит доп. нагрузку при обновлении значений
На один стрим может быть подписано несколько вьюх
Допустим я хочу видеть сколько выполняются методы апи в разрезе по процентилям
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS
select minute(dtmsk) m,
action,
percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50,
percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95,
percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99
from flow_stream
group by 1, 2;
create index on viewflow_per (m desc);
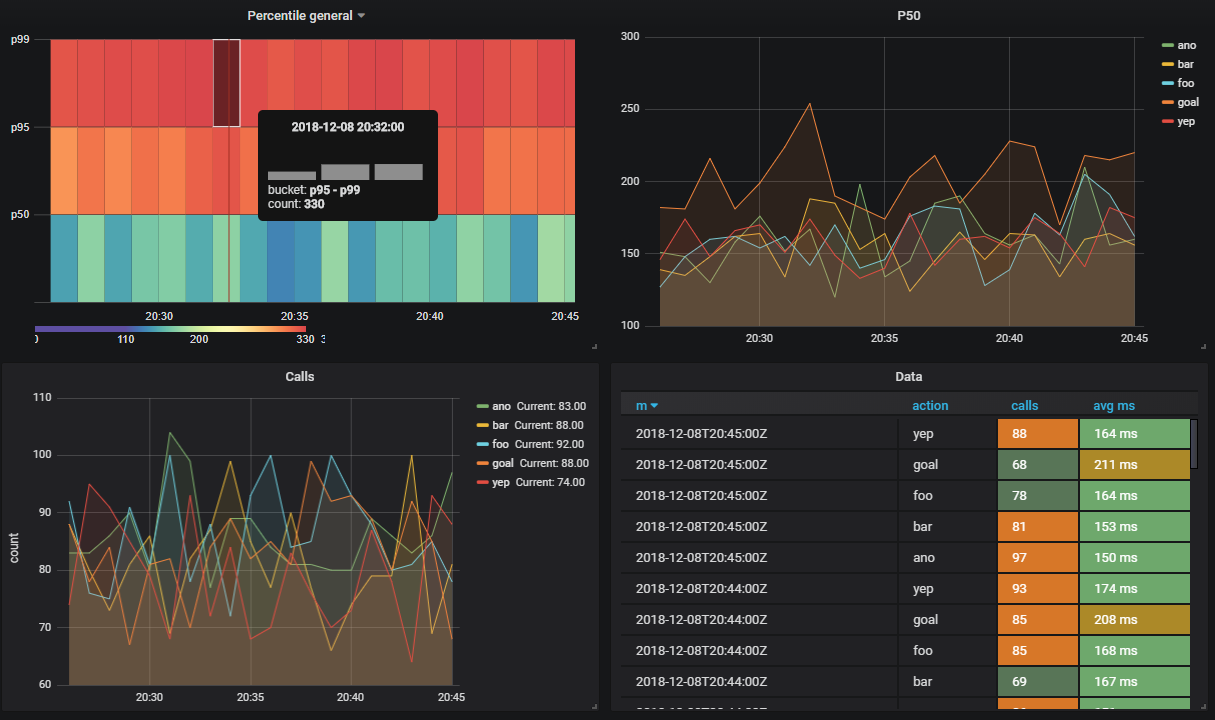
Итого
В целом штука рабочая, вела себя хорошо, без нареканий. Хотя под докером загрузка их демо базы в архиве (2.3 гб) оказалась малость долгим делом
Хочу заметить — я не проводил нагрузочные тесты
Официальная документация http://docs.pipelinedb.com/index.html
Может быть интересным
