PostgreSQL Antipatterns: когда мешает внешний ключ
Внешние ключи (foreign keys) — мощный и удобный механизм контроля логической целостности данных в базе. Но он бывает не только лишь полезен, и может неплохо пригрузить вашу БД.
Внимательный взгляд на план запроса поможет избежать многих проблем — как при чтении из базы, так и при вставке в нее.

Традиционно, начнем с самой простой ситуации — пара табличек, одна на другую ссылается:
CREATE TABLE tblpk(
k
integer
PRIMARY KEY
);
CREATE TABLE tblfk(
k
integer
REFERENCES tblpk -- эквивалентно tblpk(k), поскольку k - PK
ON DELETE CASCADE -- "ничейные" записи нам не нужны
, v
integer
);Наполним их некоторыми данными:
INSERT INTO tblpk(k)
SELECT
generate_series(1, 1e3); -- [1..1000]
INSERT INTO tblfk(k, v)
SELECT
(random() * (1e3 - 1))::integer + 1 -- random = [0..1]
, (random() * 1e6)::integer
FROM
generate_series(1, 1e6);Медленный SELECT
А теперь попробуем самым примитивным запросом, через JOIN, для каждой записи tblpk из первого десятка найти максимальное значение tblfk.v:
SELECT
k
, max(v)
FROM
tblpk
JOIN
tblfk
USING(k)
WHERE
k <= 10
GROUP BY
k;И… Parallel Seq Scan по миллиону записей tblfk — это совсем не то, чего бы хотелось:
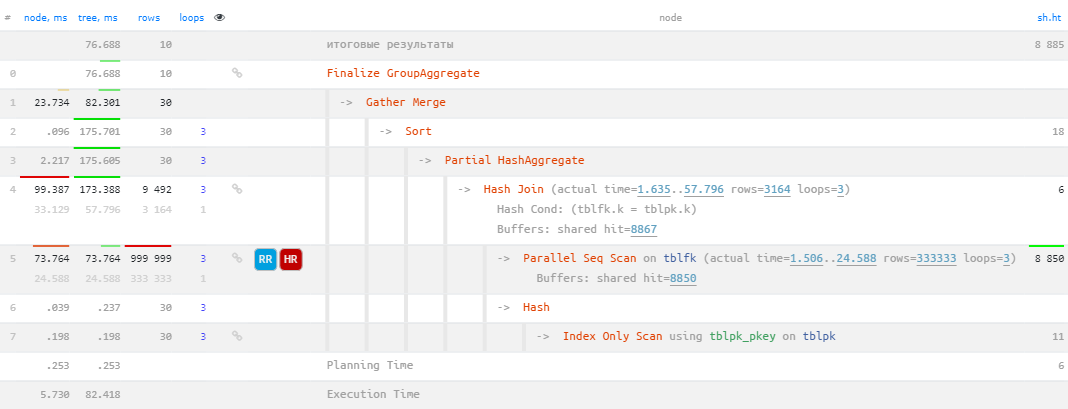 Вычитываем миллион записей
Вычитываем миллион записей
К счастью, теперь, в продолжение темы про подсказки об упущенных индексах, наш сервис визуализации explain.tensor.ru научился различать не только условия на самом узле чтения (Seq Scan), но и стоящем выше него Hash Join.
В нашем примере каждый из 3 параллельных воркеров «свои» 333333 записи tblfk превращал в Hash Join в 3164 результирующую запись:
-> Hash Join (actual time=1.635..57.796 rows=3164 loops=3)
Hash Cond: (tblfk.k = tblpk.k)
Buffers: shared hit=8867
-> Parallel Seq Scan on tblfk (actual time=1.506..24.588 rows=333333 loops=3)
Buffers: shared hit=8850А если условие фильтрации для tblfk у нас получается известно (tblfk.k = tblpk.k), то нам ничто не мешает порекомендовать создать подходящий индекс:
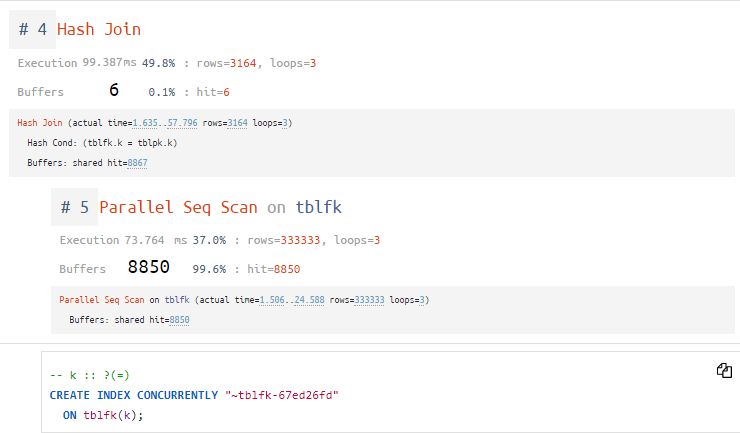 Hash Join + Seq Scan = index
Hash Join + Seq Scan = index
Нам рекомендовано создать индекс:
CREATE INDEX CONCURRENTLY "~tblfk-67ed26fd"
ON tblfk(k);Запомним это, но пока не будем его накатывать.
А заодно запомним, что PostgreSQL не создает автоматически индексы для внешних ключей.
UPDATE/DELETE «тупит»… на триггере?
Вполне вероятно, что у вас в базе уже есть подобная табличка, но выборки вы из нее делаете крайне редко и их неспешность списываете на большой обрабатываемый объем — какие-нибудь логи, записи изменение, действий пользователя, …
Но вот там захотелось удалить (или даже обновить, если речь идет о старых версиях PostgreSQL) запись из основной таблицы:
DELETE FROM
tblpk
WHERE
k = 1000;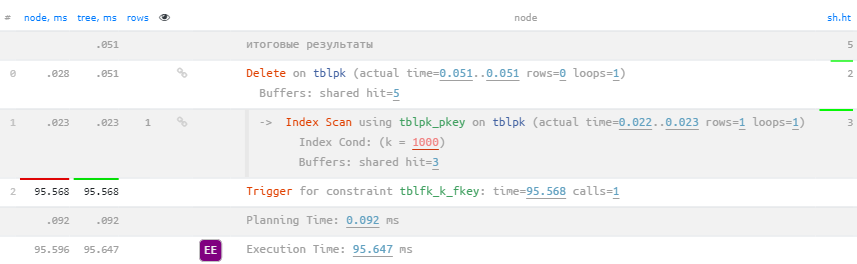 Удаление по foreign key
Удаление по foreign key
Оу… подсказка сразу акцентирует наше внимание, что 99.9% всего времени ушло вовсе не на выполнение запроса, а на Trigger for constraint tblfk_k_fkey.
Помните ON DELETE CASCADE в начале? Вот это он и есть — отработка внешнего ключа через триггер.
Давайте включим auto_explain и пристально посмотрим в лог сервера на аналогичном запросе:
LOAD 'auto_explain';
SET auto_explain.log_analyze = 'on';
SET auto_explain.log_buffers = 'on';
SET auto_explain.log_min_duration = 0;
SET auto_explain.log_nested_statements = 'on';
SET auto_explain.log_timing = 'on';
SET auto_explain.log_triggers = 'on';
DELETE FROM
tblpk
WHERE
k = 999;2022-05-11 15:02:44.196 MSK [17696] LOG: duration: 264.759 ms plan:
Query Text: DELETE FROM ONLY "public"."tblfk" WHERE $1 OPERATOR(pg_catalog.=) "k"
Delete on tblfk (cost=0.00..16925.00 rows=996 width=6) (actual time=264.757..264.757 rows=0 loops=1)
Buffers: shared hit=6252 dirtied=1279
-> Seq Scan on tblfk (cost=0.00..16925.00 rows=996 width=6) (actual time=0.181..143.802 rows=1016 loops=1)
Filter: (999 = k)
Rows Removed by Filter: 998497
Buffers: shared hit=4425 dirtied=467
2022-05-11 15:02:44.196 MSK [17696] CONTEXT: SQL statement "DELETE FROM ONLY "public"."tblfk" WHERE $1 OPERATOR(pg_catalog.=) "k""Собственно, вот он и есть — виновник наших тормозов — »Seq Scan на миллион»:
 При удалении читаем миллион записей
При удалении читаем миллион записей
Логично, что к нему рекомендовано создание того же индекса — таки создадим же его:
CREATE INDEX CONCURRENTLY "~tblfk-67ed26fd"
ON tblfk(k);Ну, как там наше удаление теперь?
DELETE FROM
tblpk
WHERE
k = 1;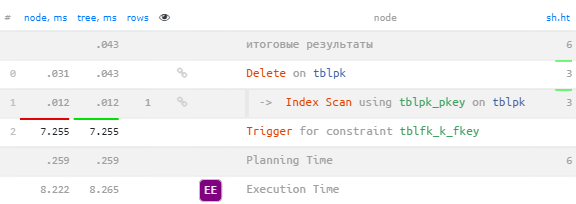 Удаление по индексированному FK
Удаление по индексированному FK
А вот теперь стало все отлично — 7ms вместо 95ms, поскольку удаление из tblfk теперь пользуется нашим индексом:
2022-05-11 15:13:16.566 MSK [17696] LOG: duration: 3.166 ms plan:
Query Text: DELETE FROM ONLY "public"."tblfk" WHERE $1 OPERATOR(pg_catalog.=) "k"
Delete on tblfk (cost=12.14..2399.04 rows=996 width=6) (actual time=3.151..3.151 rows=0 loops=1)
Buffers: shared hit=1550 dirtied=291
-> Bitmap Heap Scan on tblfk (cost=12.14..2399.04 rows=996 width=6) (actual time=0.149..0.760 rows=531 loops=1)
Recheck Cond: (1 = k)
Heap Blocks: exact=508
Buffers: shared hit=511
-> Bitmap Index Scan on "~tblfk-67ed26fd" (cost=0.00..11.89 rows=996 width=0) (actual time=0.092..0.092 rows=531 loops=1)
Index Cond: (k = 1)
Buffers: shared hit=3
2022-05-11 15:13:16.566 MSK [17696] CONTEXT: SQL statement "DELETE FROM ONLY "public"."tblfk" WHERE $1 OPERATOR(pg_catalog.=) "k""INSERT совсем небыстр
Теперь-то у нас все хорошо? С индексом SELECT работает по нашим таблицам теперь быстро, UPDATE/DELETE — тоже, а как там поживает INSERT?
Восстановим удаленные нами записи в основной таблице:
INSERT INTO tblpk VALUES(1),(998),(999),(1000);И докинем еще тысячу записей в дополнительную:
INSERT INTO tblfk(k, v)
SELECT
(random() * (1e3 - 1))::integer + 1
, (random() * 1e6)::integer
FROM
generate_series(1, 1e3);Как-то все не очень быстро стало. И если мы теперь заглянем в лог сервера, то увидим массу похожих записей:
2022-05-11 15:23:00.005 MSK [17696] LOG: duration: 0.296 ms plan:
Query Text: SELECT 1 FROM ONLY "public"."tblpk" x WHERE "k" OPERATOR(pg_catalog.=) $1 FOR KEY SHARE OF x
LockRows (cost=0.28..8.30 rows=1 width=10) (actual time=0.292..0.292 rows=1 loops=1)
Buffers: shared hit=5 dirtied=1
-> Index Scan using tblpk_pkey on tblpk x (cost=0.28..8.29 rows=1 width=10) (actual time=0.017..0.017 rows=1 loops=1)
Index Cond: (k = 361)
Buffers: shared hit=3
2022-05-11 15:23:00.005 MSK [17696] CONTEXT: SQL statement "SELECT 1 FROM ONLY "public"."tblpk" x WHERE "k" OPERATOR(pg_catalog.=) $1 FOR KEY SHARE OF x"То есть при вставке каждой нашей записи сервер идет в основную таблицу, находит запись с искомым ключом (по индексу, конечно) и вешает на нее FOR KEY SHARE-блокировку, чтобы никто ее не успел сменить значение первичного ключа на этой записи, пока мы тут вставляем остальные.
Неудивительно, что в плане запроса мы увидим тот же несчастный триггер, обслуживающий foreign key, который занял 90% всего времени:
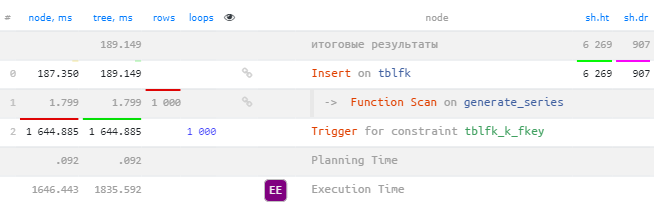 Вставка с проверкой и блокировкой foreign key
Вставка с проверкой и блокировкой foreign key
Отсюда вывод: если вам необходимо вставлять много и быстро в PostgreSQL, то это вполне реально, но внешними ключами придется пожертвовать.
Подробнее о способах оптимизации записи в PostgreSQL можно почитать в статье «Пишем в PostgreSQL на субсветовой: 1 host, 1 day, 1TB» или расшифровке моего доклада «Массовая оптимизация запросов PostgreSQL».
