Поиск без интернета. Новая бета приложения Яндекс

Но для начала нужно понять главное: зачем мы вообще взялись за офлайн-поиск, если сайты из результатов поиска все равно недоступны при отсутствии сети?
EDGE-поиск
На радарах Яндекса традиционно видны люди, которые вводят запрос, но затем покидают страницу, не дождавшись загрузки из-за плохого мобильного интернета. В этой ситуации мы не могли повлиять на общее качество сети и скорость загрузки всех сайтов, но сделать менее болезненным хотя бы процесс поиска и сэкономить этим немного времени стоило попытаться. Собственно, поэтому этот проект изначально и назывался EDGE-поиском, т.е. поиском при медленном интернете.
Ускорить поиск можно двумя способами. Во-первых, максимально оптимизировать веб-версию и те API, которые использует приложение. И эта работа тоже ведется, но даже этого недостаточно. Во-вторых, можно заранее загрузить на устройство то, что пригодится при плохом соединении. Очевидно, что уместить весь индекс интернета в телефоне физически невозможно. Поэтому нужно было зайти со стороны локального хранения уже готовых результатов поиска по конкретным запросам. По каким? Предсказывать будущие запросы человека с высокой точностью пока никто не умеет (но мы учимся). Поэтому берем популярные повторяющиеся запросы.
Когда мы говорим про популярные запросы, то многие представляют себе запрос [вконтакте] и несколько подобных. На самом деле у нас сотни тысяч менее очевидных запросов, которые регулярно повторяются в больших количествах. А это уже многие сотни мегабайт результатов. Причем сохранять мы планировали не только результаты поиска, но и подсказки, которые появляются в процессе ввода запроса. И здесь многие спросят: зачем хранить в офлайне подсказки, ведь человек вполне способен ввести запрос и без них?
При вводе запросов в приложении Яндекс пользователи видят не обычные поисковые подсказки, а в виде отдельных слов/пар слов (т.е. предиктивный ввод текста). Обычные подсказки нельзя отредактировать: если нужно дописать слово, то придется вводиться весь запрос самостоятельно. Подсказки в виде слов позволяют вносить правки, покрывают куда бОльшее число запросов и значительно ускоряют их ввод человеком.
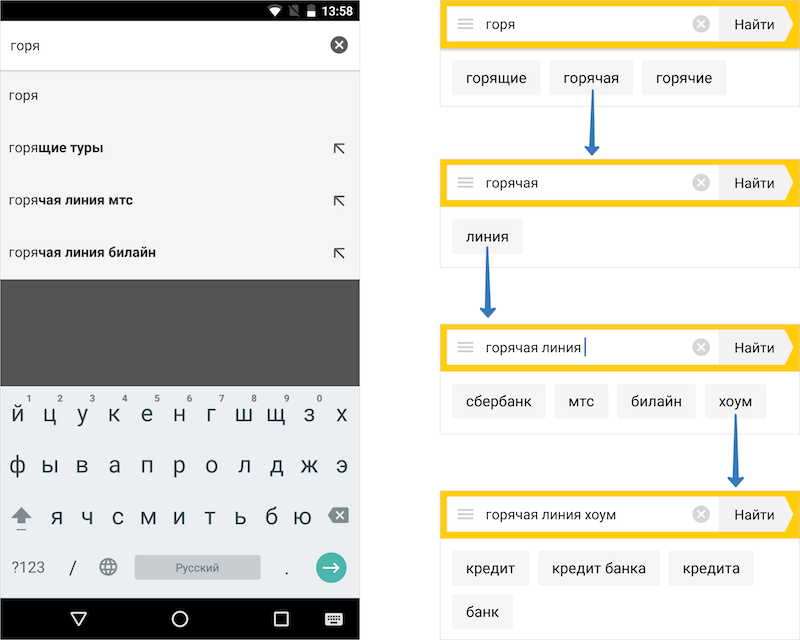
Но главное в том, что подсказки оказались особенно полезны при работе в офлайн-режиме. Эти подсказки помогают людям сформулировать свой вопрос так, как это делает большинство, а это, в свою очередь, увеличивает шанс того, что ответ будет получен из локального кэша. Именно поэтому важно было сохранить и подсказки.
Эмпирически мы подобрали определенный минимум поисковых запросов (порядка 150 тыс.) и подсказок, меньше которого хранить смысла уже не оставалось. Но объем всего этого багажа по-прежнему выходил за рамки приличного (несколько сотен мегабайт). Даже с учетом того, что для каждого запроса хранились лишь топ-10 результатов. Нужно было что-то делать.
От оптимизации к офлайну
Начали искать все то, что можно было отправить «под нож». Каждый результат содержал в себе не только ссылки на сайты, но и фавиконки и сниппеты. Фавиконки — это картинки, а значит, здесь можно было добиться серьезной экономии. Один и тот же сайт может встречаться в результатах для совершенно разных запросов, поэтому мы изначально не дублировали фавиконки, а хранили их по сайтам. А дальше мы сделали так, что вероятность сохранения фавиконки прямо пропорциональна частоте появления сайта в результатах поиска. Иными словами, мы отказались от большинства фавиконок, но визуально это не сильно бросается в глаза.
А вот от сниппетов отказаться уже не так просто, потому что это не менее важная для людей информация, чем заголовок. Именно в сниппете зачастую уже содержится ответ на вопрос. Поэтому для обычных запросов мы отбросили сниппеты лишь у двух последних результатов. Для навигационных, где первые результаты обычно уже хорошо отвечают на запросы, мы сократили не только количество сниппетов до первых 3–4, но и сами результаты до 5 сайтов вместо 10. Аналогично сократили все выдачи, где есть ответ колдунщика.
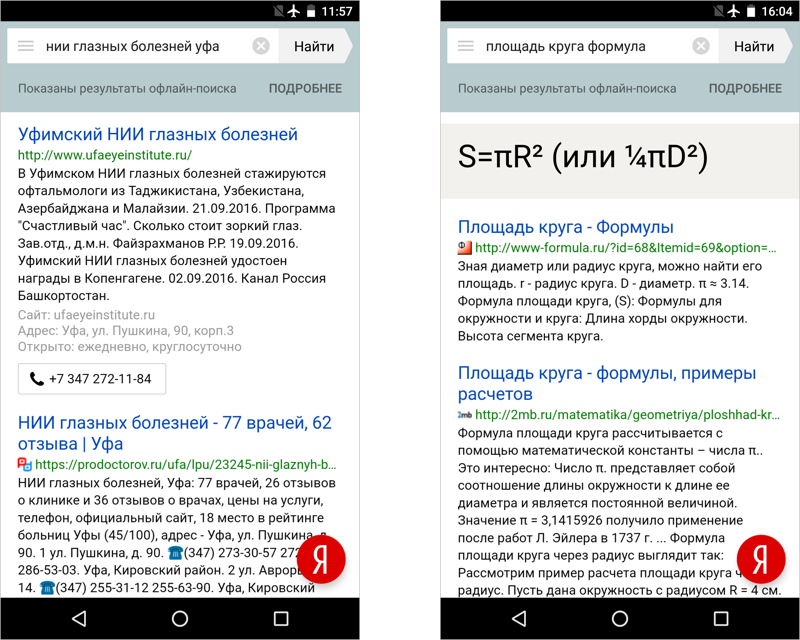
Чем больше мы сокращали обычные результаты поиска в пользу уже готовых ответов, тем ближе подходили к пониманию, что наш EDGE-поиск уже не просто ускоряет работу, а способен отвечать на широкий круг вопросов вообще без соединения с интернетом. Сами того не замечая, мы уже работали над офлайн-поиском. А значит, ставку надо делать на готовые ответы. Осознав это, мы приступили к обогащению базы важными фактами, которые до этого не могли попасть туда из-за ограничения популярности запроса. Эти результаты содержат только ответы, без выдачи сайтов.
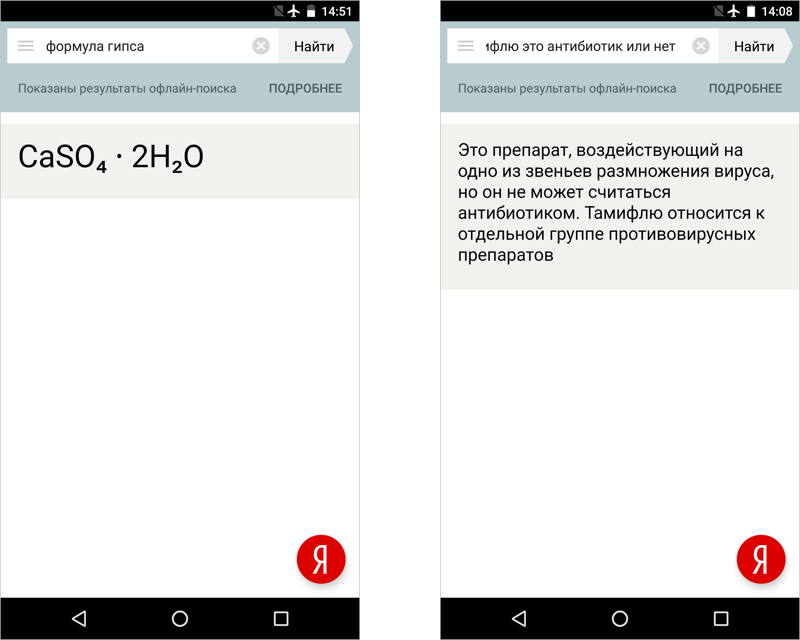
По похожей схеме мы скопировали в базу все карточки объектного ответа и все запросы, для которых объектный ответ доступен. Карточки при офлайн-поиске отличаются от оригиналов почти полным отсутствием картинок: мы убрали их из соображений экономии.
Рост базы фактов требовал дальнейшей работы над оптимизацией и такой структуры хранения данных, которая бы бережно относилась к ресурсам устройства.
Словари
База скачивается на устройство не целиком, а в виде отдельных словарей, причем только при Wi-Fi-соединении и только при достаточном уровне заряда. Разбивка на словари сделана по двум причинам. Во-первых, если при загрузке соединение рвётся, то во время следующей попытки будут скачиваться только те словари, которые не успели скачаться раньше. Во-вторых, для дополнительной экономии места база загружается и хранится на устройстве в сжатом виде, но при каждом запросе распаковывается не целиком, а только нужными частями.
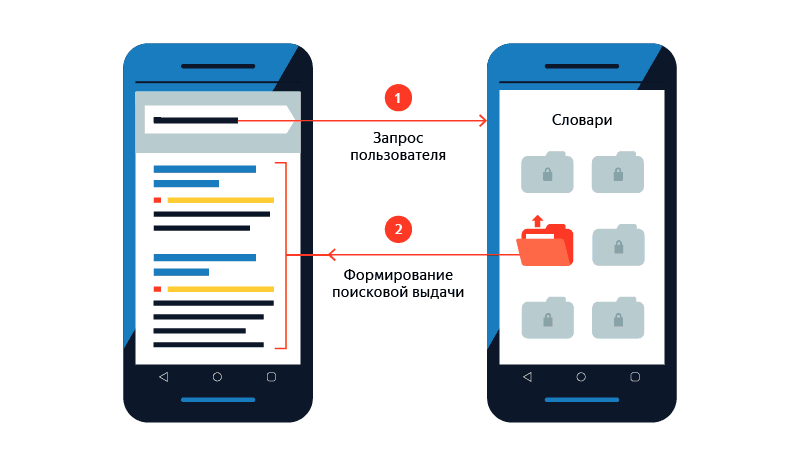
Каждый словарь содержит запросы, начинающиеся на определенные буквы, а также все данные для выдач и подсказок по этим запросам. Отсортировать данные перед разбивкой на словари именно по первым буквам запросов оказалось логичнее, чем, например, по их популярности. Представьте ситуацию: в первом словаре лежат самые популярные запросы, во втором — чуть менее популярные и так далее. Но популярность запросов часто меняется, а это приведет к необходимости регулярно обновлять словари только ради того, чтобы переместить запрос из одного в другой. Это затраты трафика, энергии и времени. Поэтому было важно сделать так, чтобы при актуализации базы запросы не перемещались между словарями. Алфавитный порядок оказался простым и эффективным решением.
Ответы на одни и те же запросы могут различаться в разных частях страны, поэтому для разных регионов формируются свои словари. Причем при кратковременных визитах в другой регион приложение не будет спешить с обновлением словарей — мы предусмотрели сценарии командировок и туризма.
Как бы мы не старались, офлайн-поиск покрывает не все возможные запросы, но уже сейчас выручает в среднем при каждом третьем. Как и для любого среднего результата, это значит, что одна часть пользователей сталкивается с офлайн-ответами куда чаще, чем другая. Поэтому мы, конечно же, позволяем полностью отключить офлайн-поиск в настройках.
Нашей команде было бы интересно узнать мнение читателей Хабра об этом направлении и получить отзывы о работе беты приложения Яндекс для Android. Спасибо.
