Поговорим об оптимизирующих компиляторах. Сказ второй: Доминирование28.05.2023 17:31
Сегодня мы продолжаем наш разговор об оптимизирующих компиляторах для самых маленьких и не очень. Для тех, кто пока не в курсе происходящего, но желает приобщиться — я поставил себе задачу написать цикл вводных статей в эту область для совсем-совсем начинающих. Первую часть, где рассказывается об SSA-форме, можно и нужно прочитать здесь.
Сегодня мы поговорим о доминировании. Это одна из фундаментальных вещей, на которых стоит как теория компиляторов вообще, так и многие компиляторные оптимизации в частности. Пристегните ремни и запишите стоп-слово на бумажке, чтобы не забыть.
Область видимости значений в С++
В первой части я пару раз упомянул о том, что инструкции в SSA-форме могут использовать в качестве операндов результаты только тех инструкций, которые гарантированно выполнились к тому моменту, когда мы хотим их использовать. Если мы посмотрим на С++ или какой-нибудь другой высокоуровневый язык программирования, то там это естественным образом обеспечивается благодаря тому, что у переменных есть области видимости. Вы можете использовать только те переменные, область видимости которых уже началась и ещё не закончилась в данной точке. Рассмотрим простенький пример:
int scope_example(int x, int y) {
int a = x + 10;
int b = x * y;
if (x < y) {
int c = 12 + b;
} else {
int d = a & 1000;
}
// return c; - Ошибка!
// return d; - Ошибка!
return a + b;
}
Параметры x и y видны внутри всей функции. Область видимости переменных a и b длится с момента их объявления и до самого конца функции. Поэтому их можно использовать внутри веток if и в точке возврата значения. Однако с и d имеют более узкую область видимости. Они существуют только пока не закроется фигурная скобка того блока, где они были объявлены, поэтому их нельзя использовать в качестве возвращаемого значения. В таких языках область видимости любой переменной — это непрерывный линейный кусок кода, от объявления и до закрытия какой-нибудь фигурной скобки. Добрые авторы компилятора даже позаботились о том, чтобы вы не могли испортить себе жизнь при помощи конструкции goto. Например, вот такой код
int scope_example_goto(int x, int y) {
int a = x + 10;
if (x == 100)
goto label_1;
int b = x * y;
if (x < y) {
int c = 12 + b;
label_1:
x++;
} else {
int d = a & 1000;
}
return a + b;
}
Попросту не скомпилируется, выдав ошибку вроде
:5:9: error: cannot jump from this goto statement to its label
goto label_1;
^
:9:13: note: jump bypasses variable initialization
int c = 12 + b;
^
:7:9: note: jump bypasses variable initialization
int b = x * y;
^
1 error generated.
Compiler returned: 1
Как видите, попытка пройти через goto к label_1 так, чтобы переменные b и c не были объявлены, но вы бы пришли при этом в блок, где они должны быть видны, воспринимаются компилятором как злостное читерство.
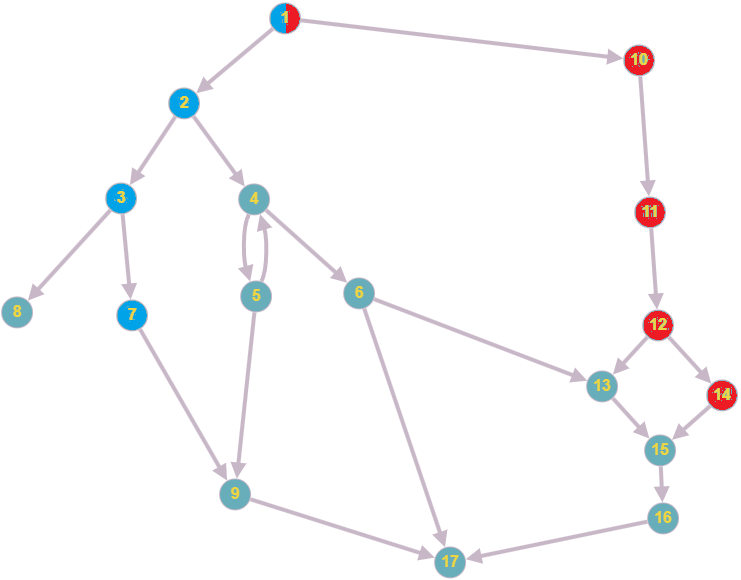
Однако если мы имеем дело с LLVM IR, всё становится несколько сложнее. Дело в том, что базовые блоки в нём могут соединяться друг с другом в совершенно произвольном порядке. Давайте представим вот такой граф потока исполнения (CFG):
Пример CFG. Такое бывает. Бывает и хуже
Каждый узел здесь — это базовый блок, а условные или безусловные переходы создают рёбра между ними. При этом, как мы знаем, в каждом базовом блоке могут находиться инструкции. Возникает вопрос:, а в каких блоках виден их результат?
Давайте сначала попытаемся ответить на этот вопрос без всяких математических формализмов, «на глаз». Инструкция, объявленная в блоке 1, будет видна всюду. Это достаточно очевидно.
Инструкция, объявленная в блоке 10, будет доступна также в блоках 11, 12 и 14. Но можно ли её результатом пользоваться, например, в блоке 13? Ответ на этот вопрос (почти что правильный, но об этом потом) — нет. Мы могли прийти в блок 13 через блоки 1 → 2 → 3 → 6 → 13, и таким образом, вообще не исполнять блок 10. А как мы знаем, если инструкция могла не исполниться, то и пользоваться её результатом нельзя, его попросту нигде нет. По этой же причине нельзя пользоваться этим значением в блоках 15, 16 и 17.
Значения из блока 2 будут видны в блоках 3, 4, 5, 6, 7, 8 и 9. Но вот в блоках 13 или 17 уже нет, поскольку туда тоже можно прийти через блок 10, никогда не исполняя блок 2.
Вполне очевидно, что тут есть какая-то закономерность, которая позволяет строго математически вычислить, в каких блоках будут доступны значения, определённые в том или ином месте CFG.
Что такое доминирование
Определение достаточно простое. Пусть есть ориентированный граф, один из узлов которого помечен как входной, и все остальные узлы из него достижимы по рёбрам. Узел Aдоминирует над узлом B (является доминатором узла B), если любой путь, ведущий из входного узла в B, проходит также через A. В данном случае речь идёт о CFG в LLVM IR, но вообще определять доминирование можно на любых других графах.
В случае, если узел A доминирует над узлом B, но при этом ему не равен, то можно говорить о строгом доминировании между ними. Короче, доминирование между разными узлами — всегда строгое, а сам себя узел доминирует не строго (причём всегда, поскольку путь до узла точно содержит сам этот узел).
Как же проверить, является ли узел A доминатором узла B? Очень просто. Запустите любой графовый обход (сгодится DFS и BFS) от входного узла, но запретите ему проходить через A. Если вам удалось дойти до B, то существует путь в обход A, то есть A не является доминатором B. Если же вы не смогли туда дойти, значит, все пути в B заблокированы проходом через A, и A, таким образом, является доминатором B.
Можно также ввести понятие доминирования и для инструкций: если инструкции A и B лежат в одном блоке, то A доминирует B, если расположена выше. Если в разных — то A доминирует B, если её родительский блок доминирует над родительским блоком B.
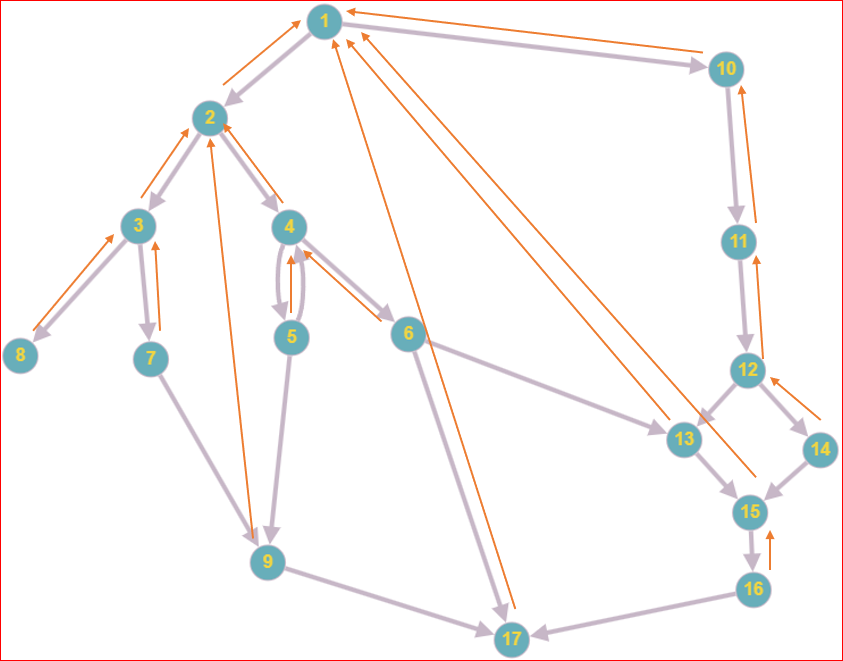
На рисунке ниже синим выделены доминаторы блока 7, а красным — доминаторы блока 14.
Доминаторы блоков 7 и 14 выделены цветами
Как видите, все доминаторы данного блока образуют цепочку от верхнего узла и до текущего. Однако иногда эта цепочка прерывается: так, доминаторами узла 9 являются только узлы 2 и 1, а 3, 4, 5 и 7 — не являются (мимо них можно пройти). Также единственным доминатором узла 17 является узел 1.
Нетрудно заметить, что «Инструкция A доминирует над инструкцией B» — это то же самое, что «Инструкция A всегда точно исполнится к тому моменту, когда мы начнём исполнять B». Суть не поменялась, но зато стало чуть формальнее, и для доминирования уже можно формулировать некоторые строгие математические свойства.
Свойство 1: если A доминирует над B, и B доминирует над C, то A доминирует над С. То есть, отношение доминирования транзитивно.
Это понятно по определению. Мы не можем добраться из начального узла до C, не пройдя через B, и не можем добраться до B, не пройдя через A. Таким образом, любой путь к С содержит также и A, и B.
Свойство 2: у каждого узла (кроме входного) A в графе есть ровно один непосредственный доминатор, IDom (A), такой, что:
IDom (A) строго доминирует A;
Любой узел, строго доминирующий над A, доминирует над IDom (A).
Это напрямую следует из Свойства 1. В любом транзитивном отношении на конечном множестве будет такой ближайший элемент. Говоря простыми словами, из всех доминаторов узла A всегда можно выбрать самый «нижний», ближайший к нему доминатор. Так, на картинке выше непосредственным доминатором узла 7 является узел 3, а узла 14 — узел 12.
Как же найти непосредственный доминатор для заданного узла? Приведу не вполне точную, но понятную для понимания схему алгоритма:
Для начала, из графа удаляются все обратные рёбра циклов. Они нам не потребуются. Дальше рассматриваем граф без обратных рёбер.
Если у узла только один предшественник, то его непосредственный доминатор — этот предшественник.
Если у узла несколько предшественников, то нужно сделать следующее:
Собираем множество доминаторов для каждого предшественника
Объединяем их (т.е. берём только те элементы, которые попали во все эти множества)
Выбираем из них нижний (с точки зрения транзитивности)
Пример: нужно найти IDom для узла 9 с картинки выше. По шагам это выглядит так:
Ребро 5→4 — обратное, его выкидываем.
У узла 9 — два предшественника, это узлы 5 и 7.
Доминаторы узла 5 — это 1, 2, 4 и 5. Доминаторы узла 7 — это 1, 2, 3 и 7.
Пересекаем эти множества, остаётся 1 и 2. Нижним из них является 2, он и будет непосредственным доминатором узла 9.
Дерево доминирования
Как известно, любой программист должен вырастить дерево и построить дом. Сейчас мы совместим два этих процесса вместе и научимся строить так называемое дерево доминирования (DomTree).
Мы уже умеем находить IDom для каждого узла. Давайте просто проведём ребро от каждого узла данного графа (кроме стартового) к его IDom. Получится примерно вот так:
Оранжевым выделены рёбра от узлов к их непосредственным доминаторам
В текстовом представлении, менее громоздком, будет выглядеть вот так:
В квадратных скобках указана глубина узла, дети расположены на 1 отступ правее их IDom.
Нетрудно понять, что такой граф является деревом: число рёбер в нём ровно на 1 меньше, чем узлов. Это дерево называется деревом доминирования. У него есть некоторые интересное свойство. Начав путь из любого узла и переходя по рёбрам дерева доминирования, мы обойдём все доминаторы данного узла и только их, причём в обратном транзитивном порядке.
Именно деревом доминирования компиляторы пользуются, чтобы быстро отвечать на вопрос о том, является ли один узел доминатором другого или нет. Чтобы это проверить, нужно просто пройти по дереву от предполагаемого доминируемого узла до корня и проверить, встретится ли на этом пути предполагаемый доминатор. Проход по дереву в среднем сильно быстрее, чем всякий раз проверять, все ли пути заблокированы предполагаемым доминатором. Существуют также разные способы дальнейшего ускорения этого алгоритма, но это для нашего рассказа значения не имеет.
Область видимости значений в LLVM IR
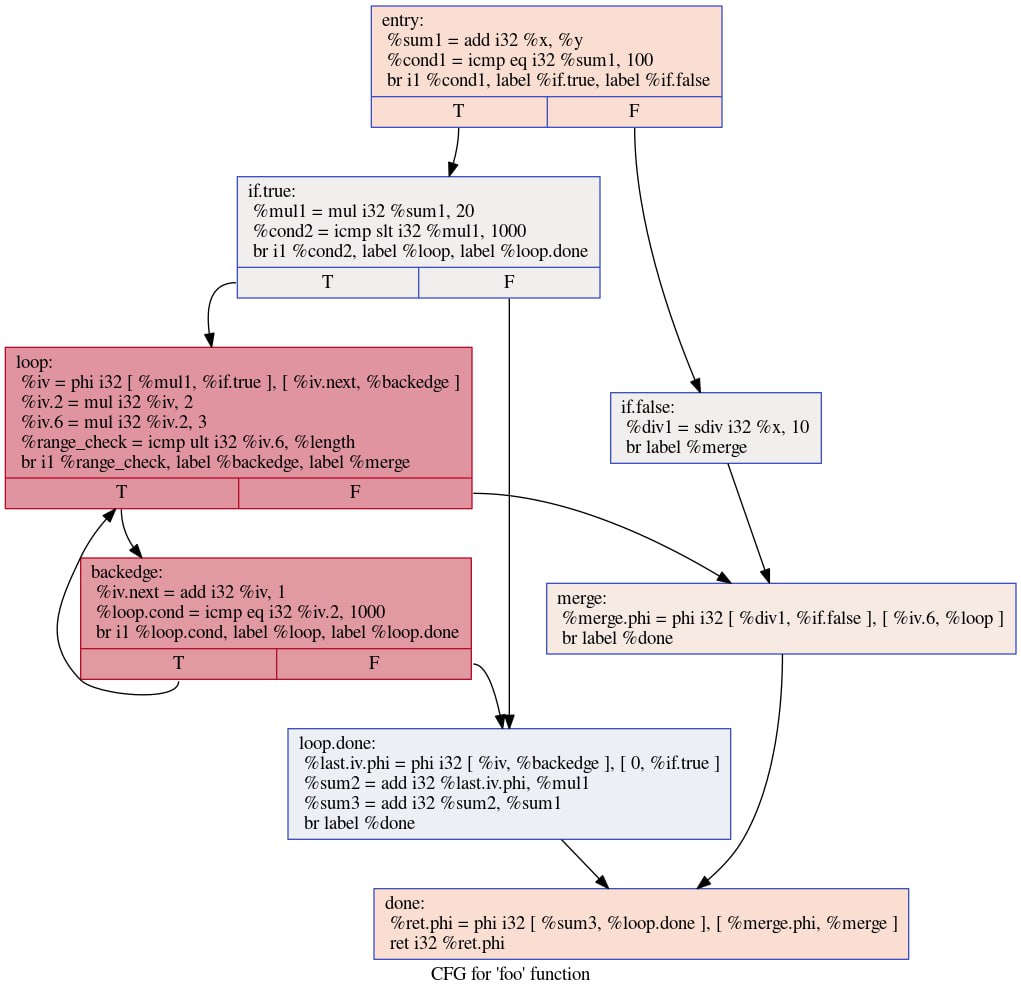
Наконец-то мы можем вернуться к рассмотрению вопроса об области видимости переменных во внутренних представлениях, которые допускают произвольный CFG. Для обычных инструкций всё просто: результат инструкции виден (и может быть использован) во всех местах, над которыми доминирует данная инструкция. Для финод всё чуть сложнее, объясню на примере. Пусть есть функция:
Граф потока управления некоторой функции
Для того, чтобы понять, какие инструкции и где живы, построим также её дерево доминирования:
Итак, все инструкции живы в тех местах, над которыми мы доминируют. То есть, во всём поддереве доминирования. Например, блок if.true доминирует над поддеревом, содержащим также блоки loop, backedge и loop.done. Поэтому инструкции, определённые в if.true, видны во всех этих блоках. Что мы и наблюдаем: например, значение %mul1 определено в if.true и используется в loop.done. А вот в блоке merge им пользоваться нельзя — потому что существует путь из entry в merge мимо if.true (в дереве доминирования видно, что if.true и merge находятся в разных ветках).
Осталось понять, что происходит с финодами. Для них это правило явно нарушается: например, блок if.false не доминирует над блоком merge, однако определённое в нём значение %div1 используется финодой %merge.phi. Финоды как раз и существуют для того, чтобы у нас была возможность воспользоваться одним из нескольких значений в зависимости от того, как мы пришли в блок, поэтому для них отсутствие доминирования между входным значением и блоком — скорее норма. Правило звучит так: результат инструкции виден финодами, если он доминирует над соответствующим входным блоком. То есть значение %div1 видно финоде %merge.phi через входной блок if.false, но не видно через входной блок %loop и не видно было бы обычным инструкциям в merge, если бы они там имелись.
Расстановка финод. Фронтир доминирования
Итак, теперь мы знаем, в каких случаях можно использовать результат инструкции напрямую, а в каких — через финоду. Наконец-то мы готовы поговорить о том, в каких местах нужно расставлять финоды, чтобы смоделировать поведение той или иной переменной в С++. Для этого нам потребуется ещё одно определение.
Фронтиром (или границей) доминирования узла называется такое множество узлов, что
Узел их не доминирует строго
При этом узел доминирует хотя бы одного из их предшественников
Говоря по-простому, к фронтиру относятся все узлы, в которые идут рёбра из поддерева доминирования. Так, на картинке выше фронтиром для блока if.true являются блоки merge и done (потому что в них идут рёбра из блоков loop и loop.done, над которыми он доминирует). А фронтиром блока if.false также является блок merge: это его потомок, над которым он не доминирует.
Интересная ситуация с блоком loop. Он относится к своему собственному фронтиру, потому что является потомком доминируемого блока backedge, но при этом не доминируетстрого сам над собой. Такая, казалось бы, парадоксальная ситуация постоянно возникает для циклов, и удивляться ей не стоит. В ациклических графах такого быть не может.
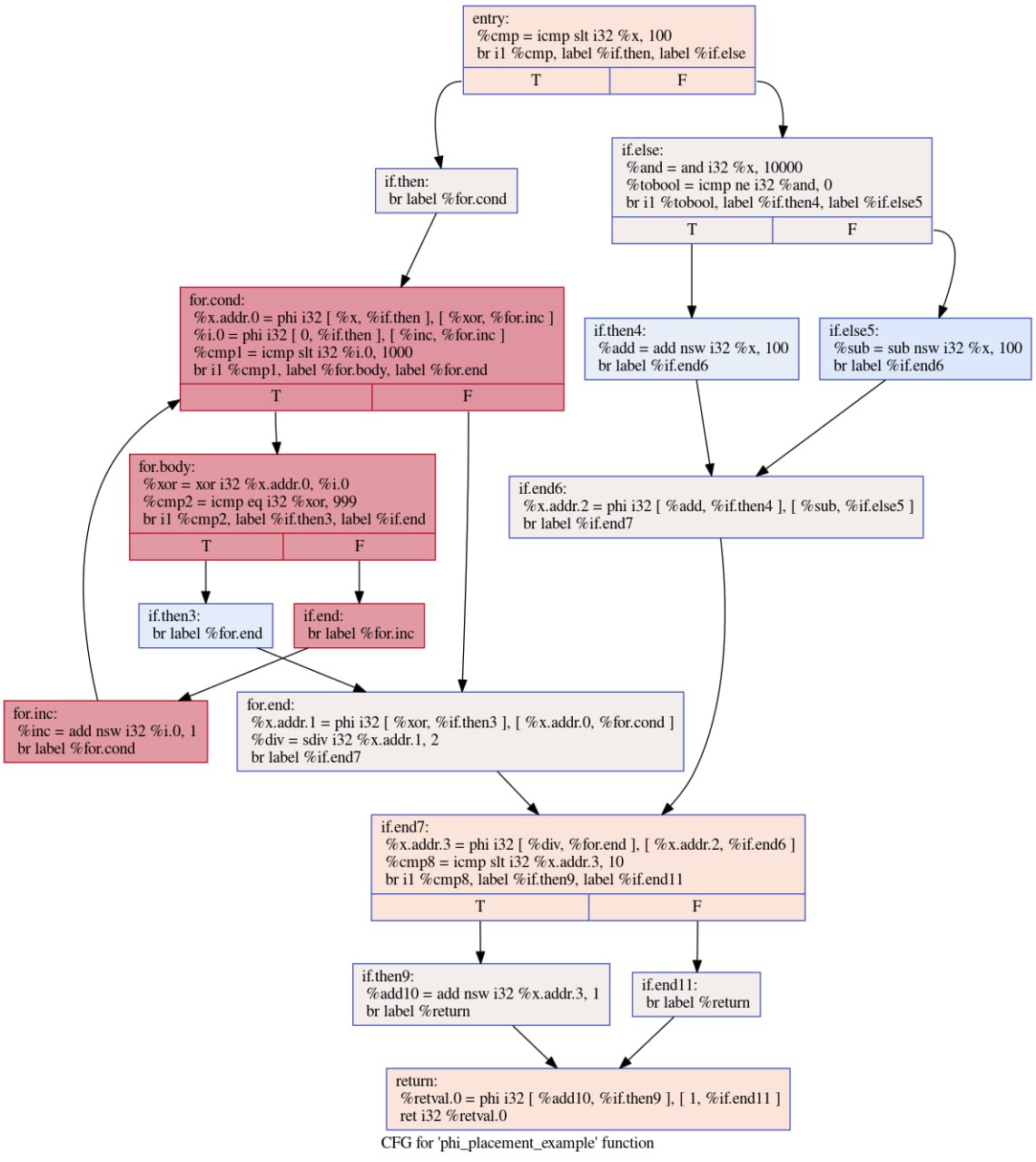
Итак, теперь у нас точно есть весь необходимый математический аппарат, чтобы научиться переводить произвольную программу в SSA-форму с языка типа С++. Рассмотрим такую задачу: пусть есть функция на С++ с каким-то сложным CFG, в которой много раз переприсваивается одна и та же переменная. Нужно построить SSA-форму для неё, расставив финоды там, где это необходимо. Приведём пример:
int phi_placement_example(int x) {
if (x < 100) {
for (int i = 0; i < 1000; i++) {
x ^= i;
if (x == 999) break;
}
x /= 2;
} else {
if (x & 10000) {
x += 100;
} else {
x -= 100;
}
}
if (x < 10)
return x + 1;
return 1;
}
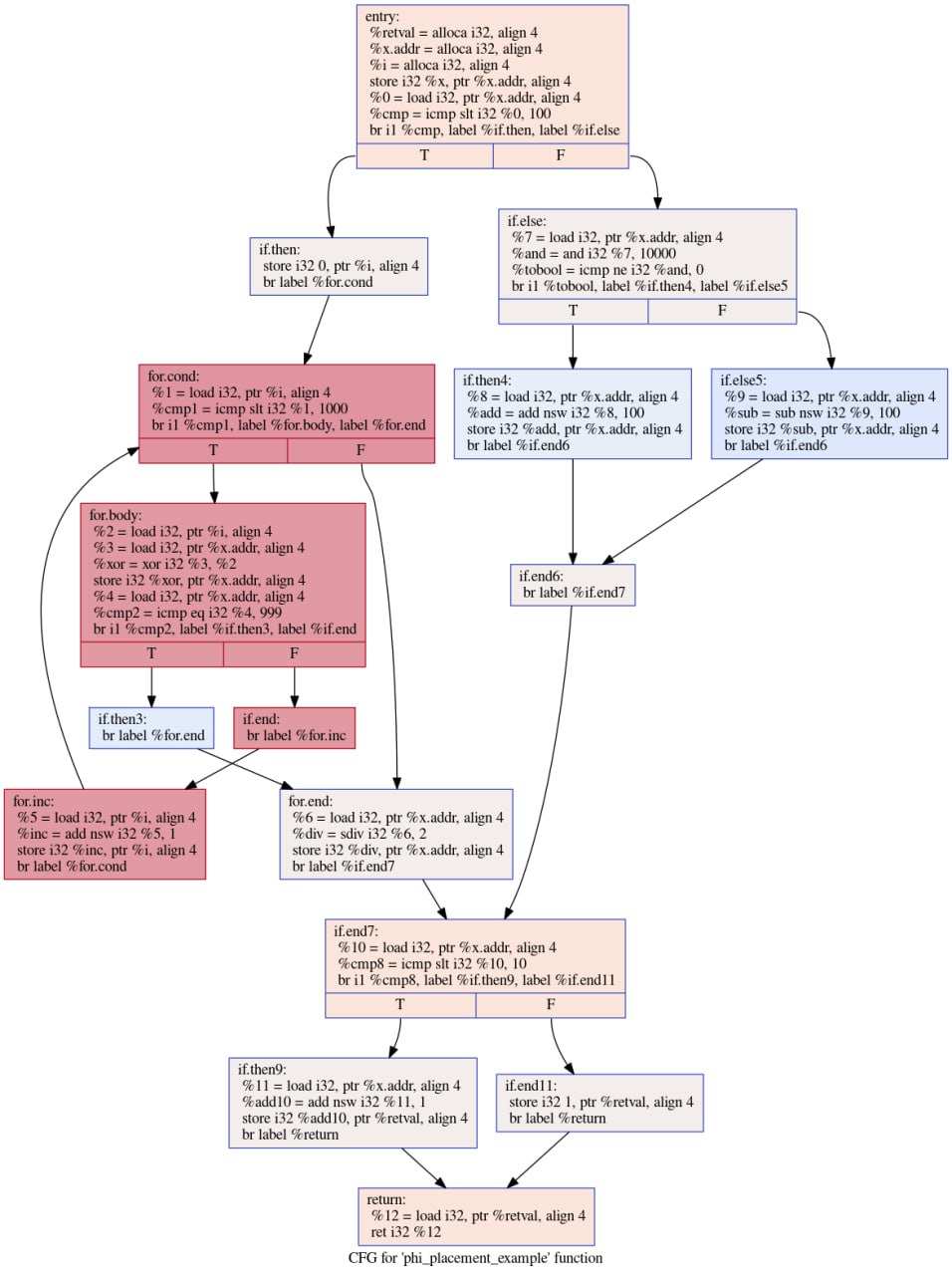
Если мы запустим clang в режиме -O0 на этом примере, то сгенерированный им код не будет содержать никаких финод и вообще будет довольно примитивным:
В режиме -O0 нет никаких финод, а значения передаются через память
Всякий раз, когда нам нужно поменять переменную, clang просто грузит текущее значение из памяти (ячейка alloca на стеке) и пишет туда новое. Это, разумеется, страшно неэффективно, и об оптимизации в этом случае можно вообще не думать. Однако мы уже знаем, что значения между блоками можно передавать напрямую и через финоды. Как же это сделать?
Опишу общую схему алгоритма, который позволит избавиться для всех load/store локальных переменных и полностью перевести работу с ними на чистую SSA-форму. В LLVM этим занимается пасс под названием SROA (и это одна из первых вещей, которые делает компилятор в оптимизирующих режимах).
Будем обрабатывать store по одному. Для каждого store соберём список load-инструкций, которые из него достижимы (и при этом на пути нет другого store). Значение, которое мы пишем в store, может быть зачитано этими load-ами.
Если store доминирует над load, то load удаляется, а в качестве его результата берётся записанное значение
Если store не доминирует над load, то делается следующее:
Находим все рёбра через фронтир доминирования, через которые это значение может протечь
Вставляем там финоды (или используем существующие, если уже есть) и передаём им сохранённое значение в качестве входа. Продолжаем аналогичную процедуру над финодами, пока алгоритм не сойдётся. Возможно, нам придётся протолкнуть значение этой финоды в другие финоды (при переходе через очередной фронтир).
Заметим, что вставка финоды на фронтире позволяет перепрыгнуть в другое поддерево доминирования. Вставлять их внутри поддерева в теории можно (финоды с одним входным значением можно вставлять даже там, где у блока всего один предок, и в этом даже есть некоторый смысл, но с построением SSA-формы он напрямую не связан), но никакой необходимости в этом нет. Вот что получается в результате работы SROA на той же самой функции:
Теперь вместо load/store — финоды
Теперь вся работа с локальными переменными переведена в SSA-форму, и такой код уже можно оптимизировать.
Вместо послесловия
На сегодня всё. В следующий раз поговорим об оптимизациях, которые можно делать на IR в SSA форме, имея только дерево доминирования. Любопытный читатель может также самостоятельно прочитать о том, что такое пост-доминирование (спойлер: то же самое, что доминирование, только пути ищутся не из входа в блок, а из блока в выход, (например, return блок)).