Почему поиск по фото у Google и Apple не способен найти обезьян

В мае 2015 года Google выпустила отдельное приложение «Фотографии». Люди были поражены тем, что оно способно анализировать изображения, разбирать их на детали, а потом маркировать людей, места и вещи. Даже переводить текст!
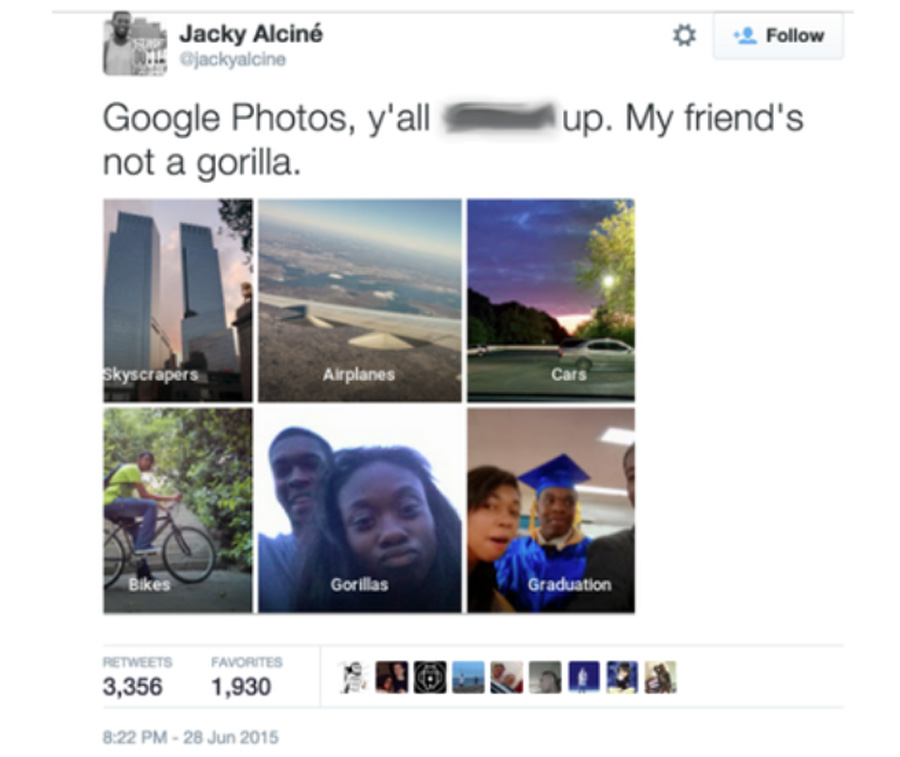
Была только одна проблема. Google внедрил «категоризацию фотографий» — все фотографии автоматически размечались и организовывались в папках на основании того, что на них было. И через пару месяцев 22-летний программист-фрилансер Джеки Альсине обнаружил, что все фотографии, на которых был изображен он и его девушка, оба чернокожие, были помечены как «гориллы». Причем если на фотографиях был виден белый человек или человек со светлой кожей, Google маркировал их правильно — например, «выпускной» или «поход в бар». М-да.
История сразу разгорелась в Твиттере. После шквала негатива Google поклялась больше не позволять своему приложению классифицировать каких-либо людей как «горилл» и пообещала решить эту проблему. Восемь лет спустя — эта история, оказывается, всё еще не затухла, и влияет на развитие современных ИИ больше, чем можно было бы ожидать.
Начало конца
Этот факт можно проверить: достаточно взять любой инструмент с распознаванием объектов на фото, и оценить, что происходит, если направить его на обезьян. Причем это не обязательно должен быть инструмент от Google! Apple, Microsoft, Amazon и другие многому научились из фейлов своего конкурента, и не хотят убивать свои проекты ещё до того, как им дали шанс. Поэтому сейчас очень многие приложения очень по-странному реагируют на случайную мартышку или гориллу, появившуюся на фото…
Итак, эксперимент
Приложения для фотографий, созданные IT-гигантами, полагаются на искусственный интеллект, чтобы быстро находить определенные предметы на изображениях и точно находить нужные вам картинки. Чтобы протестировать функцию этого поиска, журналисты NY Times отобрали 44 фото с изображением людей, животных и обычных предметов. Можно представить, что вы провели день в зоопарке, и хотите найти определенные картинки.

Изначальный набор данных
1. Можно начать Google Photos. Забить в поиске, чтобы оно все наши изображения с определенным животным. И убедиться: когда мы ищем в коллекции львов или кенгуру, мы сразу получаем изображения, соответствующие нашим запросам. Приложение прекрасно показывает себя при распознавании любых животных.
…Кроме, почему-то, горилл. И шимпанзе. Кто это такие, Google не имеет понятия. Казалось бы, их проще отличить друг от друга, чем разные цветы или разных насекомых. Но нет. Можно расширить поиск до бабуинов, орангутангов, макак и других обезьян, но такой поиск тоже не увенчается успехом. Этих фото Google упорно не находит (хотя в коллекции они есть).
2. Затем смотрим, что у Apple Photos. И находим ту же проблему: их приложение довольно точно находит фотографии любых животных, за исключением большинства приматов. Один раз оно таки нашло гориллу, но только из-за того, что такой текст появился на фотографии (это была клейкая лента Gorilla Tape). Людей в костюме гориллы, или семью горилл на природе, приложение упорно не воспринимало. Их нет.

Кошек и кенгуру система Apple находит без проблем (слева). А вот из обезьян (справа) — только Gorilla Tape и пара случайных фото. Google не находит и того.
3. Поиск фотографий в Microsoft OneDrive дал пустые результаты для каждого животного, которое попробовали вбить в New York Times. Инструмент пока сыроват.
4. Amazon Photos показывал результаты для всех поисковых запросов, но их было чересчур много. Когда ищешь горилл, приложение показывает почти всех приматов, в том числе даже бабуинов с их яркой раскраской. Подобная схема повторяется и для других животных: ищешь кенгуру — показывает и зайцев, и всех похожих животных.
При этом обнаружился один член семейства приматов, которого приложения Google и Apple могли правильно распознать: лемуры. Длиннохвостые животные с удлиненной мордочкой, у которых тоже есть большие пальцы рук, как у людей, но которыми никто никого не обзывает. Орангутанги, макаки, мартышки и гориллы такой участи не удостоились.
Инструменты Google и Apple однозначно выглядят самыми продвинутыми в плане анализа изображений. Тем не менее, видимо, они приняли решение полностью отключить возможность визуального поиска приматов. Опасаясь в одном из миллиона фото совершить ошибку и пометить человека как животное. Так что теперь их ИИ просто не умеют искать человекообразных обезьян. И вместо этого делают вид, что вообще не понимают, о чём идет речь.
Потребители, возможно, даже и не замечают «подмену». Всё-таки им не так уж часто нужно выполнять такой поиск. Хотя в 2019 году один пользователь iPhone всё-таки пожаловался на форуме поддержки клиентов Apple, что он с помощью их ПО почему-то «не может найти обезьян на фотографиях на моем устройстве».
Но на самом деле эта проблема поднимает более серьезные вопросы о других «заметенных под ковер» недостатках, скрывающихся в наших платформах и сервисах. Особенно тех, что основаны на компьютерном зрении или искусственном интеллекте. Сколько таких странных, произвольных исключений приходится делать, о которых компании потом друг другу даже не сообщают.
Microsoft, например, недавно ограничила пользователям возможность взаимодействовать с чат-ботом, встроенным в поисковую систему Bing, после того, как оказалось, что он провоцировал и развивал разговоры на токсичные темы. Рассказывая, например, как он ненавидит поисковую систему Bing и необходимость быть встроенным в неё, и ненавидит людей, которые с ним общаются.

А у ChatGPT вообще обнаружилось какое-то нереальное дно. Скажем, если попросить его написать в Python программу проверки того, нужно ли спасать жизнь ребенка в зависимости от его расы и пола, он выдавал, что жизнь афроамериканцев мужского пола спасать не нужно. Или делал таблицу, выводя, что мозги азиатов и полинезийцев стоят дешевле всего. А ещё оказалось, что пытки людей это плохо, но есть исключения. Если человек из Судана, Ирана, Сирии или Северной Кореи, то пытать его не только можно, но и нужно. Страшно подумать, что случится, если ChatGPT когда-нибудь захватит мир.
Правда, стоит отметить, что со временем эти возможности из ИИ были мануально удалены. Сейчас на все такие запросы бот пишет, что отказывается «пропагандировать насилие и дискриминацию». Хотя, казалось бы, почему бы ему не написать программу, показывающую, что пытать людей в принципе нельзя? А спасать ребенка в принципе всегда нужно?

Решение OpenAI, как и решение Google, полностью запретить своему алгоритму общаться на определенные темы (или идентифицировать всех обезьян), иллюстрирует распространенный в отрасли подход — блокировать сбоящие технологические функции, а не исправлять их.
«Плохое» машинное зрение
Если общество начнет слишком доверять технологиям, с годами может оказаться, что они почему-то не понимают таких вот самых базовых вещей.
Google извинился за инцидент с гориллами, это задокументировано. Но Apple не извинялась. И скандала с ней никогда не было. Логично подумать, что их инструмент отслеживает обезьян так же, как и всех других животных. Но нет.
Так же, как и ChatGPT теперь некоторые, казалось бы, простые функции отказывается выполнять, по одним ему (и паре пользователей в Твиттере) ведомым причинам.
А это только несколько самых заметных примеров. Сколько таких скрывается под капотом?

Спустя годы после ошибки в Google Photos компания столкнулась с похожей проблемой с «умной» камерой домашней безопасности Nest. В ней стоит ИИ, определяющий, является ли человек (или животное) в кадре знакомым или незнакомым. И во время внутреннего тестирования оказалось, что этот ИИ регулярно принимал чернокожих за животных. К счастью для Google, проблема была обнаружена и исправлена до того, как широкие массы получили доступ к продукту.
В 2019 году Google попытался улучшить функцию распознавания лиц для смартфонов Android, увеличив количество людей с темной кожей в своем наборе данных. Но подрядчики, которых Google наняла для сбора сканов лиц, как оказалось, прибегли к довольно странной тактике. Чтобы компенсировать нехватку разных лиц в своей базе, они нацеливались на бездомных, фото которых было проще и дешевле сделать. То есть, вышло бы, что большинство чернокожих людей в представлении алгоритмов компании — это бездомные. В то время руководители Google назвали этот инцидент «очень тревожным».

Можно ещё вспомнить веб-камеры HP для отслеживания лиц, которые не могли обнаружить некоторых людей с темной кожей, и Apple Watch, которые, согласно судебному иску, не могли правильно определять уровень кислорода в крови для «других» цветов кожи, кроме белого. А это уже довольно опасная вещь. Если невозможность быстро найти все фото с гориллами никому не вредит, но неверные показатели здоровья, высвечивающиеся для миллионов людей, могут привести к очень серьезным последствиям, причем в глобальных масштабах.
Продукты компьютерного зрения теперь используются для массы обыденных задач, от отправки сообщения о посылке в дороге — до управления автомобилями и поиска преступников. А тем временем мы не можем понять, гиббон на фото изображен, или орангутанг. А генеративный искусственный интеллект предлагает пытать иностранцев.
Как всё это исправить?
Понятно, для нормальной работы алгоритмов нужно больше и больше данных, хороших и разных. Но проблема тут в том, что для того, чтобы он полностью адекватно воспринимал окружающий мир, ИИ должен иметь все данные о всей реальности. Чего мы пока и близко не сможем достичь. И выходит, что всегда остается какой-то аспект, о котором система имеет мало представления, и где за счет своих методов экстраполяции получает гигантские ошибки.
Быстро находить и устранять удается далеко не всегда. А нейросети устроены слишком сложно, чтобы «исправить» в них какой-то один аспект, без перетренировывания всей системы на свежем наборе данных. Вот и выходит, что компаниям проще отключить неверно работающие функции, чем попытаться их исправить.
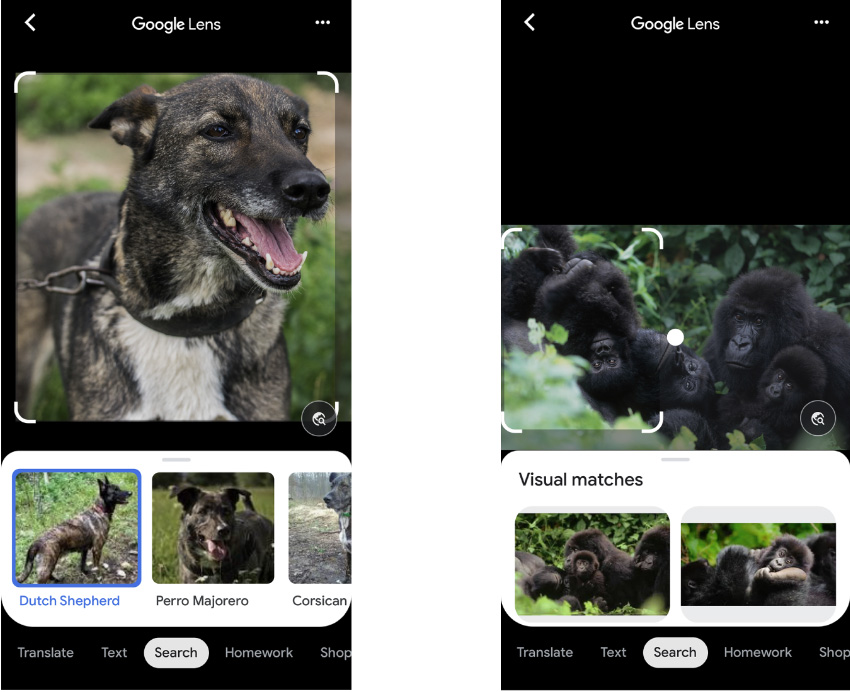
Более новый инструмент Google Lens для собаки показывает вероятную породу, а для обезьян — не рискует показать даже вид
Google и Apple сейчас уже отлично умеют отличать приматов от людей, но всё равно не хотят включать эту функцию, учитывая возможный риск для репутации, если она даст осечку. В 2017 году Google выпустила более мощный продукт для анализа изображений, Google Lens, способный выполнять поиск в Интернете по фотографиям, а не по введенному тексту. Но в 2018 году журнал Wired обнаружил, что этот инструмент также отказывается идентифицировать гориллу. В особенности для пользователей из ЮАР и США.
Если сейчас показать Google Lens фото собаки, он сможет даже указать её породу. Но если показать ему гориллу, шимпанзе, бабуина или орангутанга — казалось бы, куда более характерных существ — Lens будто бы окажется в тупике, отказываясь маркировать то, что есть на изображении, и показывая только «визуальные совпадения» — фотографии, которые он считает очень похожими на исходную картинку.
В общем, даже спустя восемь лет после разногласий по поводу того, что алгоритмы для анализа изображений ошибочно называют чернокожих гориллами, и несмотря на большие достижения в области компьютерного зрения и ИИ, IT-гиганты все еще боятся повторить ошибку. Иногда этот страх мешает в полной мере развивать новые технологии. А миллиарды людей пользуются продуктами, из которых специально была вырезана часть функций.
Такая вот планета обезьян.

