Поднимаем кластер PostgreSQL в Docker и Testcontainers
Привет Хабр!
В одной их своих предыдущих статей я рассказывал о том, как запустить PostgreSQL в Docker. Тогда речь шла об использовании «ванильных» образов Postgres и поднятии одного хоста. В большинстве случаев этого достаточно как для тестов, так и для экспериментов, но нужно понимать, что в промышленной эксплуатации чаще всего используются высокодоступные (отказоустойчивые, кластеризованные) конфигурации PostgreSQL.
Такое решение помимо собственно отказоустойчивости позволяет частично решить проблему производительности, перераспределяя чтение данных с primary хоста на реплики. Все запросы на запись при этом по-прежнему будут идти на primary хост.
Терминология
Небольшое отступление касательно терминологии:
primary = master = мастер-хост
slave = standby = secondary = реплика
failover — автоматический процесс превращения резервного хоста (реплики) в основной (при возникновении аварийной ситуации). Реплика становится новым primary и начинает обслуживать запрос на запись.
switchover — ручной процесс переноса primary с одного хоста на другой в кластере.
Больше терминологии здесь.
Из коробки PostgreSQL предоставляет механизм для превращения (promote) реплики в primary в случае аварии, но не предоставляет полноценного решения для построения HA-кластера (High Availability). На рынке существует целый ряд таких решений от разных вендоров (вы можете встретить термин HA-утилиты). Я рекомендую посмотреть видеодоклад Алексея Лесовского для расширения кругозора в этой области.
Наверное, самым популярным решением на данный момент является Patroni, но я в этой статье буду использовать repmgr от EnterpriseDB. Дело в том, что для repmgr уже есть готовые образы от bitnami, которые регулярно обновляются.
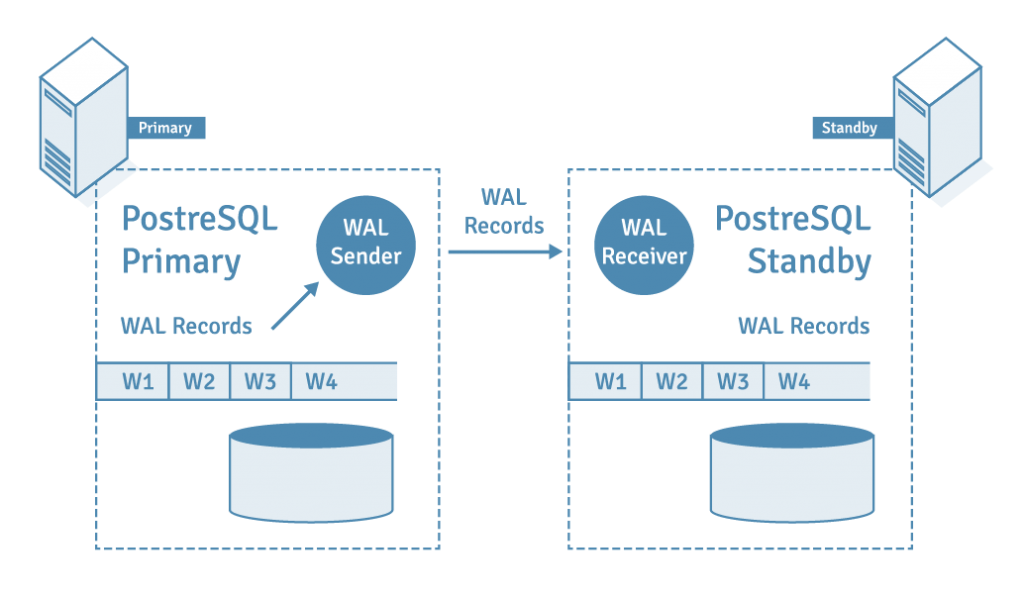
Отказоустойчивость в кластере PostgreSQL достигается за счёт WAL и потоковой репликации. Более подробно об этом можно почитать в блоге Selectel. Важно понимать: любые изменения, которые вы совершаете на primary, сначала попадают в WAL, а потом транслируются по сети на реплику и проигрываются там.
Лирическое отступление
Поэтому выполнение какой-либо DML команды, обернутое в блок BEGIN/ROLLBACK, не является безопасным: оно защищает только от видимого внешнему наблюдателю изменения данных, но потенциально может замедлить или даже уронить ваш кластер БД.
Например, есть большая таблица на 100 Гбайт; нужно проверить миграцию, которая обновит примерно половину строк в этой таблице. Что может пойти не так? Может закончиться CPU или место на диске (MVCC и WAL), забиться сеть. В это время все остальные запросы, приходящие на кластер, будут простаивать и, вероятно, прерываться по таймауту. Снаружи ситуация будет выглядеть как denial of service.
Прежде чем выполнить какую-либо команду на БД, подумайте, к чему она приведёт.
Кластер через docker-compose
Сначала давайте поднимем кластер PostgreSQL в Docker через compose-файл. Исходные коды, как обычно, доступны на GitHub.
Мой вариант compose-файла базируется на таковом от bitnami. Дополнительно я добавил мониторинг через postgres_exporter. Для запуска выполните команду из директории с compose-файлом:
docker-compose --project-name="habr-pg-ha-14" up -dИмейте в виду, что кластер будет подниматься некоторое время: на Linux быстрее, на macOS/Windows дольше. В зависимости от мощности вашего компьютера для старта кластера может потребоваться до двух минут.
version: "3.9"
services:
pg-1:
container_name: postgres_1
image: docker.io/bitnami/postgresql-repmgr:14.9.0
ports:
- "6432:5432"
volumes:
- pg_1_data:/bitnami/postgresql
- ./create_extensions.sql:/docker-entrypoint-initdb.d/create_extensions.sql:ro
environment:
- POSTGRESQL_POSTGRES_PASSWORD=adminpgpwd4habr
- POSTGRESQL_USERNAME=habrpguser
- POSTGRESQL_PASSWORD=pgpwd4habr
- POSTGRESQL_DATABASE=habrdb
- REPMGR_PASSWORD=repmgrpassword
- REPMGR_PRIMARY_HOST=pg-1
- REPMGR_PRIMARY_PORT=5432
- REPMGR_PARTNER_NODES=pg-1,pg-2:5432
- REPMGR_NODE_NAME=pg-1
- REPMGR_NODE_NETWORK_NAME=pg-1
- REPMGR_PORT_NUMBER=5432
- REPMGR_CONNECT_TIMEOUT=1
- REPMGR_RECONNECT_ATTEMPTS=2
- REPMGR_RECONNECT_INTERVAL=1
- REPMGR_MASTER_RESPONSE_TIMEOUT=5
restart: unless-stopped
networks:
- postgres-ha
pg-2:
container_name: postgres_2
image: docker.io/bitnami/postgresql-repmgr:14.9.0
ports:
- "6433:5432"
volumes:
- pg_2_data:/bitnami/postgresql
- ./create_extensions.sql:/docker-entrypoint-initdb.d/create_extensions.sql:ro
environment:
- POSTGRESQL_POSTGRES_PASSWORD=adminpgpwd4habr
- POSTGRESQL_USERNAME=habrpguser
- POSTGRESQL_PASSWORD=pgpwd4habr
- POSTGRESQL_DATABASE=habrdb
- REPMGR_PASSWORD=repmgrpassword
- REPMGR_PRIMARY_HOST=pg-1
- REPMGR_PRIMARY_PORT=5432
- REPMGR_PARTNER_NODES=pg-1,pg-2:5432
- REPMGR_NODE_NAME=pg-2
- REPMGR_NODE_NETWORK_NAME=pg-2
- REPMGR_PORT_NUMBER=5432
- REPMGR_CONNECT_TIMEOUT=1
- REPMGR_RECONNECT_ATTEMPTS=2
- REPMGR_RECONNECT_INTERVAL=1
- REPMGR_MASTER_RESPONSE_TIMEOUT=5
restart: unless-stopped
networks:
- postgres-ha
pg_exporter-1:
container_name: pg_exporter_1
image: prometheuscommunity/postgres-exporter:v0.11.1
command: --log.level=debug
environment:
DATA_SOURCE_URI: "pg-1:5432/habrdb?sslmode=disable"
DATA_SOURCE_USER: habrpguser
DATA_SOURCE_PASS: pgpwd4habr
PG_EXPORTER_EXTEND_QUERY_PATH: "/etc/postgres_exporter/queries.yaml"
volumes:
- ./queries.yaml:/etc/postgres_exporter/queries.yaml:ro
ports:
- "9187:9187"
networks:
- postgres-ha
restart: unless-stopped
depends_on:
- pg-1
pg_exporter-2:
container_name: pg_exporter_2
image: prometheuscommunity/postgres-exporter:v0.11.1
command: --log.level=debug
environment:
DATA_SOURCE_URI: "pg-2:5432/habrdb?sslmode=disable"
DATA_SOURCE_USER: habrpguser
DATA_SOURCE_PASS: pgpwd4habr
PG_EXPORTER_EXTEND_QUERY_PATH: "/etc/postgres_exporter/queries.yaml"
volumes:
- ./queries.yaml:/etc/postgres_exporter/queries.yaml:ro
ports:
- "9188:9187"
networks:
- postgres-ha
restart: unless-stopped
depends_on:
- pg-2
networks:
postgres-ha:
driver: bridge
volumes:
pg_1_data:
pg_2_data:
Инициируем auto failover
Одной из функциональных возможностей repmgr является switchover — ручная управляемая смена мастер-хоста в кластере. К сожалению, в образах от bitnami эта операция не поддерживается (в старом репозитории была issue на это, но сейчас репозиторий удален).
Для тестирования доступен только failover режим. Как его инициировать? Просто погасите контейнер с primary:
docker stop postgres_1В логах на реплике появятся записи типа:
LOG: database system was not properly shut down; automatic recovery in progress
…
LOG: database system is ready to accept connectionsПосле этого бывшая реплика станет primary и будет готова обслуживать запросы на запись.
Теперь можно вернуть обратно в строй первый хост:
docker start postgres_1Он поднимется, увидит, что есть новый мастер, и продолжит функционировать как реплика:
INFO ==> This node was acting as a primary before restart!
INFO ==> Current master is 'pg-2:5432'. Cloning/rewinding it and acting as a standby node...
...
LOG: database system is ready to accept read-only connectionsКто сейчас primary?
Возникает вопрос: «Как понять, в какой роли функционирует конкретный хост?» Ответить на него поможет простой запрос:
select case when pg_is_in_recovery() then 'secondary' else 'primary' end as host_status;Из консоли контейнера его удобнее выполнять без явного входа в psql:
psql -c "select case when pg_is_in_recovery() then 'secondary' else 'primary' end as host_status;" "dbname=habrdb user=habrpguser password=pgpwd4habr"А ещё удобнее сделать это из командной строки:
docker exec postgres_1 psql -c "select case when pg_is_in_recovery() then 'secondary' else 'primary' end as host_status;" "dbname=habrdb user=habrpguser password=pgpwd4habr"Кластер в Testcontainers
Автоматизированное тестирование и Continuous Integration (CI) — две практики, которые, на мой взгляд, сильно изменили разработку ПО. Когда нужно проверить взаимодействие приложения с каким-либо хранилищем или брокером сообщений, удобно и полезно использовать Testcontainers. В библиотеке pg-index-health, которую я совместно с open source сообществом поддерживаю и развиваю, есть функционал по сбору статистики на всех хостах кластера. Для его полноценной проверки нам потребовалось поднимать кластер PostgreSQL в end-to-end тестах.
Готового модуля для кластера в Testcontainers не было, поэтому мы сделали небольшую обёртку PostgresBitnamiRepmgrContainer над стандартным JdbcDatabaseContainer и упаковали всё это в PostgreSqlClusterWrapper. Большое спасибо Алексею @Evreke Антипину за проделанную работу!
PostgreSqlClusterWrapper умеет поднимать двухнодовый кластер, а также «гасить» первый хост, вызывая тем самым auto failover. Jar-ник доступен в Maven Central.
Основной сложностью стала правильная инициализация кластера: поднять первый хост, затем второй; дождаться, пока второй хост войдет в кластер и начнёт стримить WAL с primary. Для этой цели мы использовали LogMessageWaitStrategy и Awaitility.
Зачем PostgreSqlClusterWrapper может пригодиться вам? Главным образом, это возможность проверить поведение вашего приложения при возникновении нештатной ситуации на БД: сможет ли оно продолжить корректно работать при смене мастера.
Тюнинг параметров JDBC драйвера
JDBC driver поддерживает клиентскую балансировку и сам может переподключаться к новому primary-хосту, если в connection URL указать сразу несколько хостов базы данных.
В общем виде строка подключения выглядит следующим образом:
jdbc:postgresql://localhost:32769,localhost:32770/test_db?connectTimeout=1&hostRecheckSeconds=2&socketTimeout=600&targetServerType=primaryЗдесь мы видим два инстанса БД на разных портах: localhost:32769 и localhost:32770, но гораздо важнее и интереснее параметры подключения.
targetServerType=primary указывает, что нас интересует только мастер-хост БД. Если вы хотите организовать чтение с реплики, то вам подойдёт вариант targetServerType=secondary или targetServerType=preferSecondary.
Параметр connectTimeout определяет, как много времени мы готовы ждать до установления соединения с сервером БД. Значение по умолчанию — 10 секунд. Уменьшение этого значения позволяет более агрессивно перебирать хосты в списке и пытаться к ним подключиться.
Опция hostRecheckSeconds влияет на частоту проверки, кто у нас сейчас мастер, а кто реплика.
И, наконец, socketTimeout выступает в качестве глобального ограничителя времени выполнения всех запросов к БД. Установка этого параметра не обязательна; более того, конкретное значение нужно аккуратно подбирать под ваши нужды.
Безусловно, это далеко не все параметры, которые поддерживает JDBC драйвер, но это, на мой взгляд, необходимый минимум.
В промышленных приложениях обычно используется пул соединений к БД. Каждая реализация connection pool«а имеет свой набор параметров, позволяющих тонко управлять соединениями в пуле. Более подробно об этом можно почитать в статье Database timeouts. Для HikariCP, как минимум, имеет смысл настроить connectionTimeout и validationTimeout:
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import javax.annotation.Nonnull;
import lombok.SneakyThrows;
import lombok.experimental.UtilityClass;
import org.postgresql.Driver;
@UtilityClass
public class HikariDataSourceProvider {
@Nonnull
@SneakyThrows
public HikariDataSource getDataSource(@Nonnull final String jdbcUrl,
@Nonnull final String username,
@Nonnull final String password) {
final HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setMaximumPoolSize(3);
hikariConfig.setConnectionTimeout(250L);
hikariConfig.setMaxLifetime(30_000L);
hikariConfig.setValidationTimeout(250L);
hikariConfig.setJdbcUrl(jdbcUrl);
hikariConfig.setUsername(username);
hikariConfig.setPassword(password);
hikariConfig.setDriverClassName(Driver.class.getCanonicalName());
return new HikariDataSource(hikariConfig);
}
}
Я подготовил пару приложений, демонстрирующих использование PostgreSqlClusterWrapper, и разместил их на GitHub: консольное и spring-boot. Пусть они станут отправной точкой для ваших экспериментов!
