Подключаем Firewall через ePBR

Спустя неожиданно длительный перерыв возвращаюсь для продолжения разбора технологий, использующихся в построении сетей ЦОД. Настало время разобрать тему подключения внешних устройств, таких как Firewall, Proxy и других сетевых сервисов. А что делать, когда необходимо создать целую цепочку из таких сервисов, пропустив через них весь или только часть трафика? Конечно, использовать статику, но не обычную же.
Сразу оговорюсь, что в данной статье опущены примеры взаимодействия с EVPN, однако вы сможете найти примеры настроек в источнике [1], [2].
Начнем с теоретического описания технологии.
ePBR — Enhanced Policy‑based Redirect, технология, разработанная компанией Cisco. Поддерживается на Cisco Nexus, начиная с версии 9.3.(x), для создания цепочек прохождения трафика через сетевое устройство по определенному маршруту. Тут делаем вывод, что технология относительно новая и ей присущи проблемы и неожиданное поведение. Плюс, начиная с версии 10.2.(1) ePRB получил расширение функционала, то есть технология развивается, и в дальнейшем мы увидим еще более гибки инструмент.
Однако, не смотря на то, что технология развивается в новых версиях NX‑OS, компании в РФ пока не торопятся переходить с версии 9.3.10, так как она:
Является стабильной и рекомендованной.
NX‑OS 10 получил нововведение в лицензировании с помощью SmartNet, что накладывает некие финансовые издержки на компанию.
Тут стоит уточнить, что технология разработана компанией Cisco и является проприетарной. К сожалению, остальные производители не представили подобных технологий или я не наткнулся на них в момент изучения темы (напишите в комментарии, если знакомы с аналогами).
После непродолжительного вступления пора переходить к сути данного материала. Что же это за зверь такой?
Начнем с того, что ePRB существует 2-х типов
ePBR L3 — доступен, начиная с версии NX‑OS 9.3.10.
ePBR L2 — доступен, начиная с версии NX‑OS 10.2.(1). К сожалению, выходит за рамки данного материала.
ePBR L3
Предположим, у нас есть небольшая сеть, как показано на схеме ниже:
Для упрощения в данном случае не берем, что хост может быть подключен к нескольким Leaf устройствам и никаких Firewall у нас нет. Как можно заметить, все действительно очень просто и не требует глубокого понимания сетей.
Если все было бы так так просто… В современных сетях просто уже не бывает, поэтому усложним нашу схему и добавим Border Leaf, к которому подключен Firewall. И, конечно же, требование обязательного направления трафика на Firewall. В этом случае цепочка прохождения трафика через сеть уже не такая простая, как в предыдущем случае:
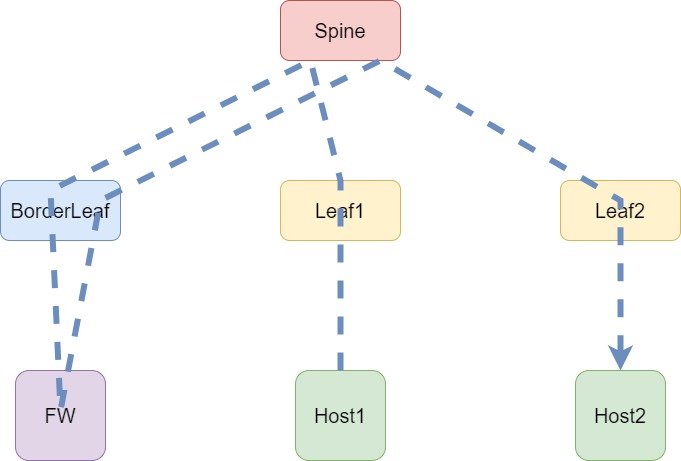
Но даже в этом случае задачу не сложно решить путем разделения клиентов на VRF и анонсирование маршрутов через FW или использовав более интересные решения с использованием маршрутизации. Продолжаем усложнять повышать надежность сети и добавим дополнительный BorderLeaf:
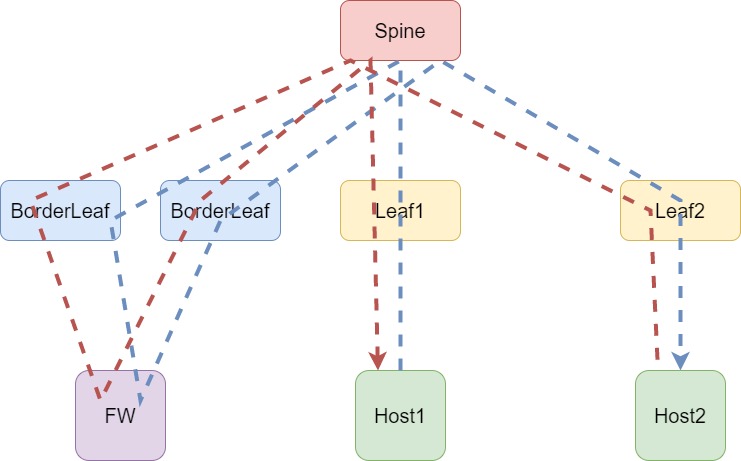
На данной схеме, помимо BorderLeaf, добавил дополнительный трафик — ответ на запрос. Все-таки сервисы в сети часто работают по принципу запрос‑ответ. Как видно выше, и в этом случае все работает без проблем. С одним «НО» — Firewall должен быть подключен через LAG интерфейс, иначе возникает ассиметричный трафик и получится ситуация, как на схеме ниже:
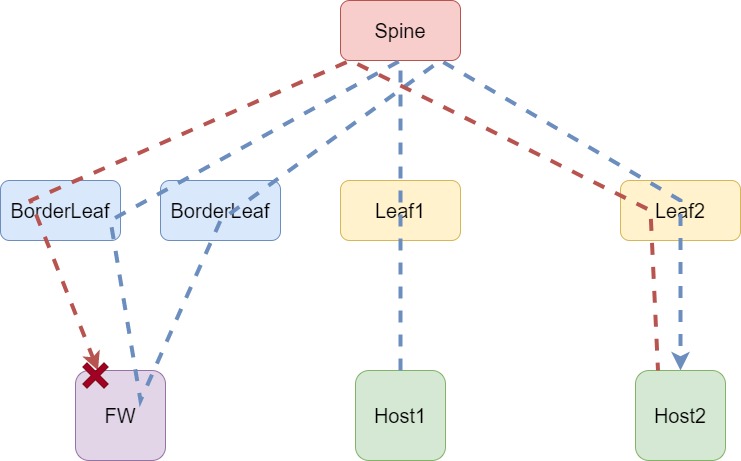
Firewall не любит ассиметричный трафик, поэтому нам придется с этим смириться и отключить statefull‑inspection, что ведет к уменьшению общей безопасности инфраструктуры. Да и ИБ спасибо за это не скажет. Получается, отключение statefull‑inspection никого не устраивает.
Пойдем еще дальше и максимально повысим надежность сети, добавив второй Firewall в сеть. При этом помним, что 2 Firewall, как и бесконечность, не предел. Поэтому добавим их в режиме Active/Active (а еще лучше, вообще не собираем из них стек/кластер и оставляем работать как независимые устройства. Риски и нюансы работы оставим за границами данного материала).
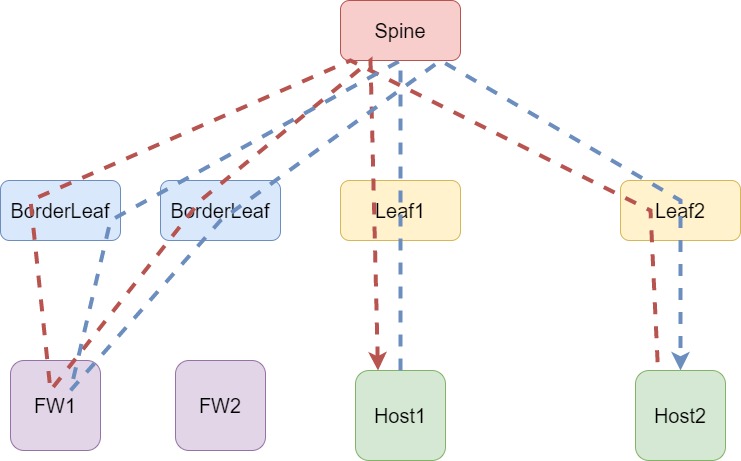
У вас может появиться вопрос, что сложного и тут разрулить трафик симметрично по FW. Ведь достаточно анонсировать разные префиксы через отдельное устройство — и никаких проблем. Конечно, не забываем учитывать, как именно подключены FW — mLAG или через независимые интерфейсы. Могу только согласиться с этим решением, но это не единственный вариант. Однако с помощью маршрутизации достаточно тяжело решить вопрос в тех случаях, когда необходимо отправить трафик на несколько устройств. Например, рядом с FW появляется Proxy сервер, как показано ниже.
Для решения задач подобного класса и повышения гибкости сети появилась технология ePBR, позволяющая распределить определённый трафик на отдельные устройство или даже создать цепочку для трафика, которая проведет его через несколько устройств. В общем случае это будет работать следующим образом:
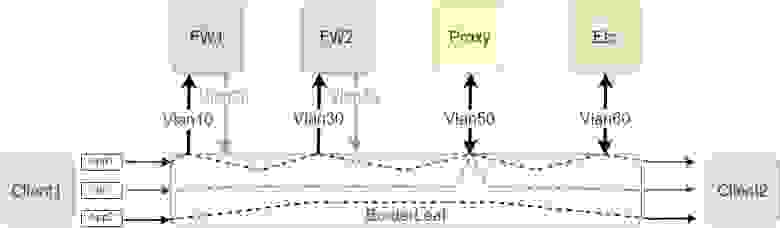
Как можете заметить, технология работает локально на одном устройстве. То есть объединить несколько BorderLeaf в одно логическое устройство и распределять так трафик не выйдет. Однако это и не требуется. В основе ePBR, как можно догадаться по названию, лежит обычный PBR с ACL. Да, снова модные и современные технологии оказались всего лишь надстройкой над давно известными решениями.
В защиту ePBR могу сказать только, что такая простая основа никак не вредит, а наоборот, упрощает работу. Так как не появилось каких‑либо сложных технологий по вычислению хэшей для трафика, то нет необходимости синхронизации сессий на нескольких BorderLeaf. И, большой плюс, что так же просто, хоть и топорно, решается вопрос с ассиметричным трафиком. Разберем на примере конфигурацию и, уверен, все сразу станет понятнее.
Первое, что необходимо сделать, это описать Service. С точки зрения ePBR — удаленный хост (ы) (да‑да, есть возможность балансировать трафик, но об этом позже), куда будем отправлять входящий трафик:
epbr service FW1
service-end-point ip 192.168.10.1 interface Ethernet1/1.10
reverse ip 192.168.20.1 interface Ethernet1/1.20
epbr service FW2
service-end-point ip 192.168.30.1 interface Ethernet1/2.30
reverse ip 192.168.40.1 interface Ethernet1/2.40service‑end‑point — непосредственно интерфейс FW1, на которой отправится запрос от клиента к серверу.
reverse — интерфейс FW1, на который будет отправляться ответ от сервера к клиенту (то есть обратный трафик, для поддержания симметрии).
Таким образом возможно описать все наши сервисы. Далее необходимо выделить различные типы трафика или приложения (как на схеме выше). Делается это достаточно топорно через ACL, хоть и расширенный. То есть можно описать не только IP источника и назначения, но и выделить интересующие порты:
IP access list APP1
10 permit ip 10.1.1.0 0.0.0.240 20.1.1.1 0.0.0.255
IP access list APP2
10 permit ip 10.2.2.0 0.0.0.240 20.1.1.1 0.0.0.255Осталось объединить трафик и сервисы в одну политику:
epbr policy CLIENTS
statistics
match ip address APP1
10 set service FW1
20 set service FW2
30 set service Proxy
40 set service Etc
match ip address APP2
10 set service ProxyВыше создается политика с названием CLIENTS, в которой для каждого типа трафика определяется своя цепочка перенаправления трафика. Для APP1 — трафик пройдет по 4 устройствам. Для APP2 трафик пойдет только через Proxy. Для Debug рекомендую включать параметр statistics, который поможет в момент отладки понять, как именно проходит трафик через устройство. Однако, на прод трафике параметр бесполезен и может значительно повышать нагрузку на оборудование.
Осталось дело за малым. Указать, на каком интерфейсе BorderLeaf находится клиент, с которого получаем запросы, и на каком интерфейсе ожидаем реверсивный трафик:
interface Ethernet1/48.2001
epbr ip policy CLIENTS
interface Ethernet1/48.2002
epbr ip policy CLIENTS reverse
Или когда клиенты находятся за одним интерфейсом
interface Ethernet1/48.2001
epbr ip policy CLIENTS
epbr ip policy CLIENTS reverseНо и тут не обошлось без нюансов. Когда в цепочке находится больше одного устройства (например, для трафика APP1), важно, чтобы все интерфейсы были с клиентами и сервисами были в одном VRF, иначе устройство будет выдавать ошибку и не сможет применить конфигурацию. Если же в цепочке только один сервис, то допускается для запросов клиента использовать один VRF (сервис так же должен быть с ним в одном VRF) для реверсивного трафика другой VRF. Пример:
epbr service FW1
vrf VRF1
service-end-point ip 192.168.10.1 interface Ethernet1/1.10
reverse ip 192.168.20.1 interface Ethernet1/1.20
interface Ethernet1/48.2001
vrf member VRF1
epbr ip policy CLIENTS
interface Ethernet1/48.2002
vrf member VRF2
epbr ip policy CLIENTS reverseОтвечу на следующий вопрос. Как устройство распознает реверсивный трафик? Уверен, что вы уже догадались. Так как в основе выбора трафика приложений лежит ACL, в котором описываются параметры запроса, то для реверсивного трафика автоматически формируется аналогичный ACL, но параметры в нем указываются в обратном порядке. Для примера возьмем ACL для APP1:
IP access list APP1
10 permit ip 10.1.1.0 0.0.0.240 20.1.1.1 0.0.0.255
IP access list APP1_reverse
10 permit ip 20.1.1.1 0.0.0.255 10.1.1.0 0.0.0.240 Вот и вся магия. Далее автоматически создается аналогичная политика ePBR с новым реверсивным ACL и в ней применяются все сервисы в обратном порядке. Одним словом — статика и ничего лишнего.
Тут возникает сомнение, так ли хороша эта статика. Что делать, если один или несколько сервисов перестанут быть доступными. Это решаемо с помощью IP SLA. В рамках настройки сервиса есть возможность указать параметры для мониторинга сервиса, как показано в примере ниже:
epbr service FW1
service-end-point ip 192.168.10.1 interface Ethernet1/1.10
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2
reverse ip 192.168.20.1 interface Ethernet1/1.20
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2В данном случае мониторинг происходит через ICMP, но есть поддержка:
ICMP
TCP
UDP
HTTP
DNS
etc
И описываем механизм работы в случае сбоя сервисов в политике:
epbr policy CLIENTS
match ip address APP1
10 set service FW1 fail-action bypass
20 set service FW2 fail-action drop
30 set service Proxy fail-action forwardBypass — в случае сбоя отправить трафик в следующий сервис.
Drop — в случае сбоя трафик должен быть отброшен.
Forward — при сбое отправить трафик по таблице маршрутизации.
Что ж. Цепочки сервисов это, конечно, интересно. Но разговор-то начали про подключение нескольких Firewall и о том, как же балансировать трафик между ними, да еще и сохранять симметричность. Но, поверьте, все было не зря. Теперь нам понятен механизм ePBR и как формируются правила для симметрии. Для балансировки требуется не так много действий — описать несколько устройств как один сервис с несколькими end‑point:
epbr service FW
service-end-point ip 192.168.10.1 interface Ethernet1/1.10
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2
reverse ip 192.168.20.1 interface Ethernet1/1.20
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2
service-end-point ip 192.168.30.1 interface Ethernet1/1.30
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2
reverse ip 192.168.40.1 interface Ethernet1/1.40
probe icmp frequency 4 retry-down-count 1 retry-up-count 1 timeout 2И привязать это все в политику, не забыв указать метод балансировки:
epbr policy CLIENTS
match ip address APP1
load-balance method src-ip
10 set service FWВарианта балансировки трафика всего 2:
load‑balance method src‑ip — балансировка по сети источника.
load‑balance method dst‑ip — балансировка по сети назначения.
Со стороны конфигурации это все. Не сложно ведь. Однако самое интересное происходит глубже.
Чтобы далее нам было проще понимать друг друга, введем новое понятие — Bucket. Если дословно переводить — Корзина, куда помещается трафик, для того, чтобы перенести его с одного интерфейса в другой. По умолчанию создается столько бакетов, сколько заведено service‑end‑point в рамках одного сервиса, однако этот параметр настраивается. Есть возможность настроить различное количество бакетов под каждый тип трафика:
epbr policy CLIENTS
match ip address APP1
load-balance bucket 4 method src-ip
match ip address APP2
load-balance bucket 8 method dst-ip При балансировке, потоки трафика разбиваются на бакеты и отправляется по своим путям. Для того, чтобы разбить потоки трафика на бакеты, как это ни парадоксально, используются все те же ACL. Отсюда и ограничения количества методов балансировки по источнику или назначению. Выглядит это следующим образом:
IP access list APP1 - исходный ACL, который создается вручную для описания типа трафика
10 permit ip 10.1.1.0 0.0.0.240 20.1.1.1 0.0.0.255
IP access list epbr_p1_1_fwd_bucket_1 - сформирован автоматически для работы бакета
10 permit ip 10.1.1.0 0.0.0.248 20.1.1.1 0.0.0.255
IP access list epbr_p1_1_fwd_bucket_2 - сформирован автоматически для работы бакета
10 permit ip 10.1.1.8 0.0.0.248 20.1.1.1 0.0.0.255То есть устройство берет наш ACL с описанным трафиком и автоматически делит его на равные части, чтобы хватило всем бакетам (когда бакетов не четное число, а service‑end‑point четное — кому‑то достается больше).
В итоге политика ePBR будет выглядеть следующим образом:
show epbr statistics policy CLIENTS
Policy-map CLIENTS, match APP1
Bucket count: 2
traffic match : epbr_APP1_1_fwd_bucket_1
FW1 : 0
FW2 : 0
traffic match : epbr_APP1_1_fwd_bucket_2
FW1 : 0
FW2 : 0Как всегда, есть нюансы, о которых не стоит забывать. Так как в основе ePBR лежит PBR, который в своей работе использует TCAM — необходимо разметить область ingress RACL, а значит, придется пожертвовать другими регионами.
Правила выделения региона в данном случае следующие:
Каждая запись ACL использует одну запись TCAM.
При использование реверсивных политик требуется в два раза больше записей.
При балансировке трафика необходимо выделять регион кратный количеству бакетов.
У вас мог возникнуть вопрос, а как же подключить несколько Firewall к нескольким BorderLeaf. И ответ тут довольно прост. Точно так же, как и с одним BorderLeaf.
Плюс используем LAG интерфейс. Так как ePBR проприетарная технология от Cisco, то ничего не мешает использовать VPC для подключения Firewall через mLAG.
При таком подключении у Firewall не будет воспринимать трафик как ассиметричный, если он придет не с того интерфейса и сможет без ошибок его обрабатывать.
Что же касается BorderLeaf, то тут единственное требование, что конфигурация ePBR должна быть одинакова на обоих устройствах, для корректного разделения трафика на бакеты и распределение по сервисам.
А раз мы имеем дело с TCAM, то при изменении конфигурации необходимо отключить ePBR, снять политики с интерфейсов. При изменении сервисов требуется убрать их из политик и так далее. Получается, ePBR не выйдет настраивать налету, как это получается с другими решениями. Но тут можно только порадоваться, что для ePBR компания Cisco ввела транзакционный метод настройки и стало возможно подготовить отдельно список конфигураций и применить его сразу, не отключая ничего отдельно, избегая большого простоя в сети. Реализуется это двумя способами в зависимости от изменения. При конфигурации ACL требуется короткая команда:
epbr session access-list APP1 refreshПри изменении политик или сервисов требуется больше действий:
switch(config)#epbr session // Заходим в режим настройки ePBR. Тут возможно настроить сервисы и политики, но конфигурация от сюда не применяется сразу
switch(config-epbr-sess)#epbr service FW1
switch(config-epbr-sess-svc)# no service-end-point ip 192.168.10.1 interface Ethernet1/1.10
switch(config-epbr-sess-svc)#service-end-point ip 192.168.100.1 interface Ethernet1/1.100
switch(config-epbr-sess-svc-ep)# service-end-point ip 192.168.110.1 interface Ethernet1/1.110
switch(config-epbr-sess)#commit // Применение конфигурацииВ примере выше показана перенастройка FW1, однако одновременно можно изменить и политику, так же применив все изменения через commit. Стоит учитывать, что в прод среде в момент применения конфигурации появится небольшая потеря трафика, так как могут меняться записи в TCAM и происходит генерация новой политики. Однако, такой метод конфигурации оказывает значительно меньшее воздействие на сеть, нежели в ручном режиме менять все конфигурации.
На этой прекрасной ноте заканчиваю материал. Информация для подготовки этого материала бралась из официальной документации производителя [1] [2] [3]
Если у вас есть вопросы или дополнения — добро пожаловать в комментарии.
Также приглашаю всех на бесплатный урок, где рассмотрим использование /31 префикса в сетях IPv4 при подключении узлов точка‑точка. Узнаем историю и необходимость появления такого варианта настройки. Сравним его с классическим префиксом /30 для подключения точка‑точка.
