Планировщик ОС
Дизайн и поведение планировщика Go позволяют многопоточным программам работать более эффективно и производительно. Это возможно благодаря тому, что планировщик Go учитывает особенности работы планировщика операционной системы (OS). Однако, если многопоточная программа не учитывает принципы их взаимодействия, все преимущества теряются. Поэтому важно понимать, как работают оба планировщика, чтобы правильно проектировать многопоточные приложения.
В этой статье я решил разобраться с основными механизмами и принципами работы планировщик ОС. Большая часть статьи перевод «Scheduling In Go: Part I — OS Scheduler», автора Билла Кеннеди.
Планировщик операционной системы
Планировщики операционных систем — это сложные программные компоненты, которым приходится учитывать конфигурацию оборудования, на котором они работают. Это включает в себя наличие нескольких процессоров и ядер, кэш-память процессора и архитектуру NUMA. Без этих знаний планировщик не сможет работать максимально эффективно. К счастью, чтобы сформировать общее представление о работе планировщика OS, необязательно углубляться во все эти детали.
Любая программа представляет собой набор машинных инструкций, которые должны выполняться последовательно. Для этого операционная система использует концепцию потока (Thread). Поток отвечает за выполнение инструкций в определенном порядке, пока не останется больше команд для выполнения. Именно поэтому поток можно назвать «путем выполнения».
Каждая запущенная программа создает процесс (Process), которому выделяется начальный поток. Потоки могут порождать новые потоки, и все они работают независимо друг от друга. Важно понимать, что решения о планировании выполняются на уровне потоков, а не процессов. Потоки могут выполняться параллельно (если каждый из них работает одновременно на отдельном ядре) или конкурентно (если они поочередно используют одно и то же ядро). При этом каждый поток хранит свое состояние, что позволяет ему выполнять инструкции безопасно и независимо от других потоков.
Задача планировщика OS — распределять вычислительные ресурсы так, чтобы процессорные ядра не простаивали, если есть потоки, готовые к выполнению. При этом планировщик создает иллюзию одновременного выполнения всех активных потоков, чередуя их выполнение. Однако не все потоки равны: потоки с более высоким приоритетом должны выполняться чаще, но и потоки с низким приоритетом не должны оставаться без процессорного времени. Еще одна важная задача — минимизация задержек при переключении контекста, что требует быстрых и оптимальных решений.
Для достижения этих целей используются сложные алгоритмы планирования, разработанные и усовершенствованные на основе многолетнего опыта. Чтобы лучше понять, как работает планировщик, стоит разобрать несколько ключевых понятий.
Выполнение инструкций
Счетчик команд (Program Counter, PC), также известный как указатель команд (Instruction Pointer, IP), отвечает за отслеживание следующей инструкции, которую должен выполнить поток. В большинстве процессоров PC указывает не на текущую, а на следующую инструкцию, которая будет исполнена.

Если вы когда-либо видели stack trace (трассировку стека) в Go-программе, то могли заметить небольшие шестнадцатеричные числа в конце каждой строки. Например, на рисунке 1 можно увидеть такие значения, как +0x3f и +0x5b.

Эти числа обозначают смещение значения PC (счетчика команд) относительно начала соответствующей функции.
Смещение +0×39 указывает на следующую инструкцию, которую поток выполнил бы внутри этой функции, если бы программа не завершилась с паникой.
Смещение +0×72 показывает следующую инструкцию внутри функции main, если бы выполнение вернулось туда.
Более того, инструкция перед этим указателем указывает на последнюю выполненную команду перед паникой.
Теперь давайте посмотрим на код, который привел к трассировке стека.
package main
func example(slice []string, str string, i int) {
panic("stack trace")
}
func main() {
example(make([]string, 2), "hello", 10)
}Шестнадцатеричное число +0×3f обозначает смещение PC (счетчика команд) внутри функции example. Это соответствует 63 байтам (в десятичной системе) ниже начальной инструкции функции. Ниже приведен дизассемблированный код этой функции из скомпилированного бинарного файла. Найдите 12-ю инструкцию , которая находится в самом низу списка. Обратите внимание, что строка кода перед этой инструкцией содержит вызов panic .

PC (Program Counter) указывает на следующую инструкцию, а не на текущую.
Состояния потока
Еще одной важной концепцией является состояние потока, которое определяет, как планировщик взаимодействует с ним. Поток может находиться в одном из трех состояний: Waiting (Ожидание), Runnable (Готов к выполнению) или Executing (Выполняется).
Waiting (Ожидание): Поток приостановлен и ждет чего-то, чтобы продолжить выполнение. Это может быть ожидание аппаратных ресурсов (диск, сеть), операционной системы (системные вызовы) или синхронизационных механизмов (атомарные операции, мьютексы). Такие задержки являются одной из причин снижения производительности.
Runnable (Готов к выполнению): Поток ожидает выделения процессорного ядра для выполнения своих машинных инструкций. Если активных потоков слишком много, они дольше ждут своей очереди, а время их выполнения уменьшается. Эти задержки планирования также могут негативно сказываться на производительности.
Executing (Выполняется): Поток получил процессорное ядро и выполняет свои инструкции. Именно в этом состоянии выполняется реальная работа приложения, к которому стремятся разработчики.
Типы работы
Поток может выполнять два типа работы: CPU-Bound и IO-Bound.
CPU-Bound: Работа, которая никогда не приводит поток в состояние ожидания (Waiting). Поток постоянно выполняет вычисления. Например, вычисление числа π до N-й цифры после запятой — это CPU-Bound задача.
IO-Bound: Работа, из-за которой поток попадает в состояние ожидания (Waiting). Это задачи, связанные с доступом к ресурсам по сети или системными вызовами. Например, поток, который обращается к базе данных, является IO-Bound. Также сюда можно отнести события синхронизации (мьютексы, атомарные операции), которые заставляют поток ждать.
Переключение контекста
Если ваша операционная система — Linux, macOS или Windows, значит, вы работаете с вытесняющей (preemptive) системой планирования потоков. Это имеет несколько важных последствий:
Во-первых, планировщик непредсказуем, когда дело касается выбора потока для выполнения. Приоритеты потоков и события (например, поступление данных по сети) делают невозможным предсказание того, какой поток будет запущен в следующий момент.
Во-вторых, нельзя писать код, исходя из предположения, что раз поведение системы было одинаковым в 1000 случаях, значит, оно гарантированно будет таким всегда. Если в вашем приложении требуется детерминированность, необходимо самостоятельно управлять синхронизацией и оркестрацией потоков.
Физический процесс смены потоков на процессорном ядре называется переключением контекста (context switch). Это происходит, когда планировщик снимает поток, находящийся в состоянии Executing (Выполняется), и заменяет его потоком из состояния Runnable (Готов к выполнению). Поток, который был снят, может либо вернуться в Runnable, если он еще способен выполняться, либо перейти в Waiting (Ожидание), если он был заменен из-за запроса, связанного с IO-Bound работой.
Переключения контекста считаются дорогостоящими, поскольку требуют времени на замену потоков на ядре. Время задержки при переключении зависит от различных факторов, но в среднем составляет 1000–1500 наносекунд. Учитывая, что современное железо может выполнять примерно 12 инструкций на наносекунду на одно ядро, одно переключение контекста может стоить 12 000–18 000 инструкций. Таким образом, во время переключения контекста процесс теряет возможность выполнить большое количество инструкций.
Если программа выполняет IO-Bound работу, переключения контекста будут полезны. Когда один поток переходит в состояние Waiting, его место может занять другой поток из Runnable. Это позволяет ядру всегда оставаться загруженным работой, что является ключевым аспектом эффективного планирования потоков.
Однако если программа выполняет CPU-Bound работу, переключения контекста могут стать серьезной проблемой. В таких случаях потоки всегда заняты вычислениями, и их постоянная принудительная остановка ухудшает производительность. Это кардинально отличается от поведения при IO-Bound нагрузке.
Меньше — значит больше
Когда процессоры имели только одно ядро, планирование потоков было относительно простым. Поскольку был только один процессор с одним ядром, в любой момент времени мог выполняться только один поток. Идея заключалась в том, чтобы определить период планирования и попытаться выполнить все потоки в этом периоде. Нужно было взять период планирования и разделить его на количество потоков, которые нужно выполнить.
Например, если период планирования составляет 1000 мс (1 секунда), а потоков 10, то каждому потоку отводится по 100 мс. Если потоков 100, то каждому отводится по 10 мс. Однако что происходит, когда потоков 1000? Разделив 1000 мс на 1000 потоков и дав каждому по 1 мс, вы столкнетесь с проблемой — значительная часть времени будет уходить на переключение контекста, а не на выполнение работы приложения.
Что нужно сделать — это установить ограничение на то, насколько малым может быть временной отрезок для потока. В последнем примере, если минимальный отрезок времени составляет 10 мс и у вас есть 1000 потоков, то период планирования должен быть увеличен до 10000 мс (10 секунд). А если потоков 10 000? Тогда период планирования составит 100 000 мс (100 секунд). С 10 000 потоками, при минимальном отрезке времени 10 мс, потребуется 100 секунд, чтобы все потоки выполнились хотя бы раз, если каждый поток использует полностью свой временной отрезок.
Это очень простая модель. На самом деле, есть гораздо больше факторов, которые планировщик должен учитывать при принятии решений о том, какой поток будет выполнен следующим. Вы контролируете количество потоков, используемых в вашем приложении. Когда потоков много и происходит IO-Bound работа, возникает больше хаоса и недетерминированного поведения. Требуется больше времени на планирование и выполнение.
Вот почему существует правило «Меньше — значит больше». Меньше потоков в состоянии Runnable означает меньше накладных расходов на планирование и больше времени для выполнения каждого потока. Большее количество потоков в состоянии Runnable означает, что каждый поток будет получать меньше времени для выполнения. Это означает, что приложение будет выполнять меньше работы за тот же период времени.
Линии кэширования
Доступ к данным из основной памяти имеет такую высокую задержку (~100 до ~300 тактов процессора), что процессоры и ядра имеют локальные кэши для хранения данных рядом с аппаратными потоками, которые их используют. Доступ к данным из кэшей имеет значительно меньшую задержку (~3 до ~40 тактов процессора), в зависимости от того, какой кэш используется. Сегодня одним из аспектов производительности является то, насколько эффективно можно загружать данные в процессор, чтобы снизить эти задержки при доступе к данным. При написании многопоточных приложений, которые изменяют состояние, необходимо учитывать механизмы системы кэширования.
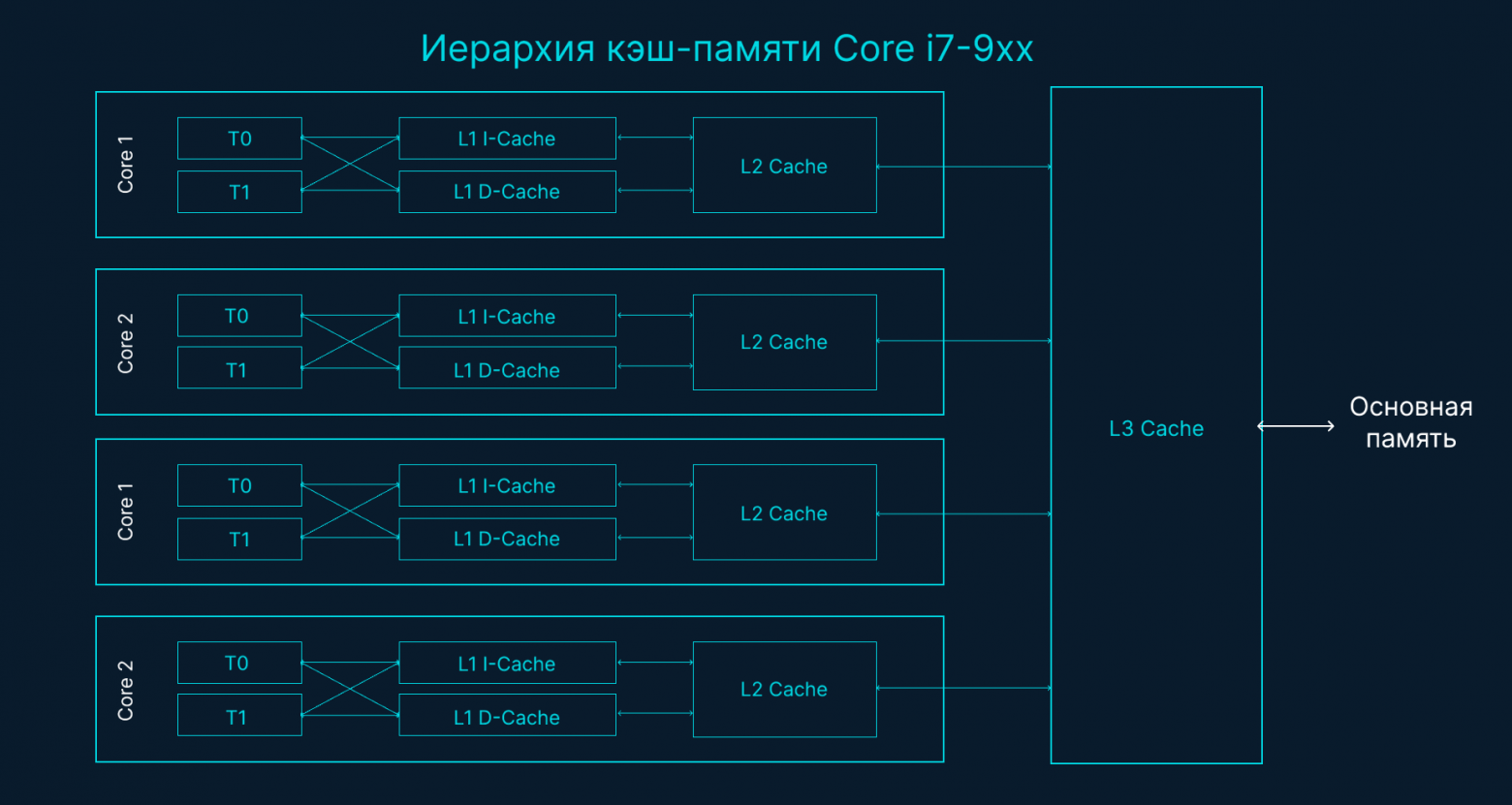
Данные обмениваются между процессором и основной памятью с использованием линий кэша. Линия кэша — это блок памяти размером 64 байта, который передается между основной памятью и системой кэширования. Каждое ядро получает свою собственную копию любой линии кэша, которую оно использует, что означает, что аппаратное обеспечение использует семантику значений. Именно поэтому мутации в памяти в многопоточных приложениях могут приводить к проблемам с производительностью.
Когда несколько потоков, работающих параллельно, обращаются к одному и тому же значению данных или даже к данным, расположенным рядом друг с другом, они будут обращаться к данным в одной и той же линии кэша. Любой поток, работающий на любом ядре, получит свою собственную копию этой линии кэша.

Если один поток на заданном ядре изменяет свою копию линии кэша, то благодаря особенностям аппаратного обеспечения все остальные копии этой же линии кэша должны быть помечены как «грязные». Когда поток пытается получить доступ для чтения или записи к грязной линии кэша, необходимо выполнить доступ к основной памяти (~100–300 тактов процессора), чтобы получить новую копию линии кэша.
Возможно, на двухъядерном процессоре это не является большой проблемой, но что будет, если система использует 32-ядерный процессор, на котором одновременно работают 32 потока, все обращающиеся и изменяющие данные в одной и той же линии кэша? Что, если у системы два физических процессора с 16 ядрами каждый? Это будет значительно хуже из-за добавленной задержки при взаимодействии между процессорами. Приложение будет постоянно обращаться к памяти, производительность упадет, и, скорее всего, вы не сможете понять, что произошло.
Это называется проблемой согласованности кэша (cache-coherency problem), что также приводит к таким проблемам, как ложное разделение (false sharing). При написании многопоточных приложений, которые будут изменять общие данные, необходимо учитывать систему кэширования.
Сценарий принятия решений по планированию
Допустим, нужно написать планировщик операционной системы, исходя из предоставленной информации. Рассмотрим один сценарий, который планировщик должен учесть при принятии решения о планировании.
При запуске приложения, создается основной поток и начинает выполняться на ядре 1. Пока поток выполняет свои инструкции, начинается получение строк кэша, так как требуется доступ к данным. Затем поток решает создать новый поток для параллельной обработки. Вопрос:
Как планировщик должен поступить, когда новый поток готов к выполнению?
Переключить основной поток с ядра 1? Это может улучшить производительность, так как велика вероятность, что новый поток будет использовать те же данные, которые уже закэшированы. Но основной поток не получит своего полного квантового времени.
Заставить поток ждать, пока ядро 1 снова станет доступным, ожидая завершения квантового времени основного потока? Поток не будет работать, но при этом будет устранена задержка на извлечение данных, когда поток начнет работать.
Заставить поток ждать следующего доступного ядра? Это приведет к сбросу и повторной загрузке строк кэша для выбранного ядра, что вызовет дополнительные задержки. Однако поток начнется быстрее, а основной поток сможет завершить свой квант времени.
Интересно. Эти вопросы — лишь малая часть того, что планировщик ОС должен учитывать при принятии решения. К счастью, я не тот, кто принимает такие решения. Единственное, что я понял: если есть свободное ядро, оно будет использовано. Нужно, чтобы потоки выполнялись, когда это возможно. В следующей статье я хочу разобраться с планировщиком Go, учитывая вышеизложенную информацию.
