Пишем поисковый плагин для Elasticsearch
Elaticsearch — популярный поисковый сервер и NoSQL база данных. Одной из интересных его особенностей является поддержка плагинов, которые могут расширить встроенный функционал и добавить немного бизнес-логики на уровень поиска. В этой статье я хочу рассказать о том, как написать такой плагин и тесты к нему.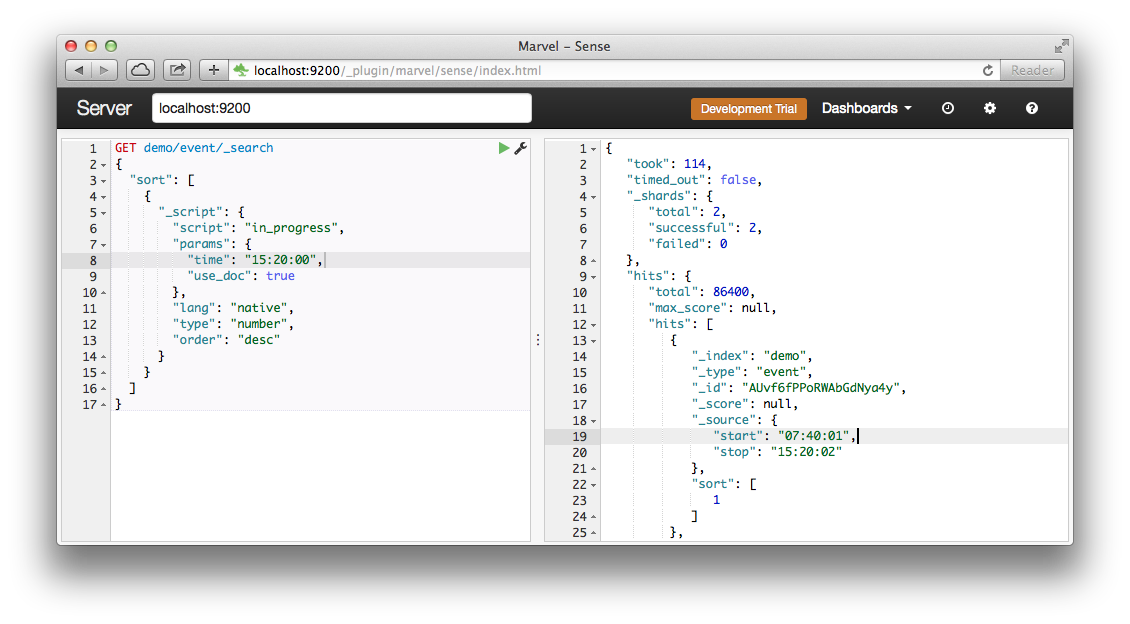 Сразу хочу оговориться, что задача в этой статье сильно упрощена, чтобы не загромождать код. Например, в одном из реальных приложений в документе хранится полное расписание с исключениями, и на основе них скрипт вычисляет нужные значения. Но я бы хотел сосредоточиться на самом плагине, поэтому в примере все очень просто.Также нужно упомянуть, что я не являюсь коммитером Elasticsearch, изложенная информация в основном получена методом проб и ошибок, и может в чем-то быть неверной.
Сразу хочу оговориться, что задача в этой статье сильно упрощена, чтобы не загромождать код. Например, в одном из реальных приложений в документе хранится полное расписание с исключениями, и на основе них скрипт вычисляет нужные значения. Но я бы хотел сосредоточиться на самом плагине, поэтому в примере все очень просто.Также нужно упомянуть, что я не являюсь коммитером Elasticsearch, изложенная информация в основном получена методом проб и ошибок, и может в чем-то быть неверной.
Итак, предположим, что у нас есть документ Event со свойствами start и stop, которые хранят время в виде строки в формате «HH: MM: SS». Задача — для заданного времени time сортировать события так, чтобы активные события (start <= time <= stop) были в начале выдачи. Пример такого документа:
{ «start»:»09:00:00», «stop»:»18:30:00» } Плагин За основу я взял пример от одного из разработчиков Elasticsearch. Плагин состоит из одного или нескольких скриптов, которые надо зарегистрировать: public class ExamplePlugin extends AbstractPlugin { public void onModule (ScriptModule module) { module.registerScript (EventInProgressScript.SCRIPT_NAME, EventInProgressScript.Factory.class); } } Исходный код полностьюСкрипт состоит из двух частей: фабрика NativeScriptFactory, и сам скрипт, наследующий AbstractSearchScript. Фабрика занимается созданием скрипта (а заодно и валидацией параметров). Стоит отметить, что скрипт создается всего 1 раз для поиска (на каждом шарде), так что инициализацию/обработку параметров стоит сделать на этом этапе.
Клиентское приложение должно передать в скрипт параметры:
time — строка в формате «HH: MM: SS», момент времени, который нас интересует
use_doc — определяет, какой метод использовать для доступа к данным документа (об этом чуть позже)
public static class Factory implements NativeScriptFactory {
@Override
public ExecutableScript newScript (@Nullable Map
if (time == null || useDoc == null) { throw new ScriptException («Parameters \«time\» and \«use_doc\» are required»); }
return new EventInProgressScript (time, useDoc); } } Исходный код полностьюИтак, скрипт создан и готов к работе. В скрипте самое важное — метод run ():
@Override public Integer run () { Event event = useDoc ? parser.getEvent (doc ()) : parser.getEvent (source ());
return event.isInProgress (time) ? 1 : 0; } Исходный код полностьюЭтот метод вызывается для каждого документа, так что стоит уделить особое внимание тому, что внутри него происходит, и насколько быстро. Это оказывает непосредственное влияние на производительность плагина.
В общем случае, алгоритм здесь такой:
Читаем нужные нам данные документа Вычисляем результат Возвращаем его в Elasticsearch Для доступа к данным документа нужно использовать один из методов source (), fields (), или doc (). Забегая вперед, скажу что doc () намного быстрее source () и при возможности стоит использовать его.В этом примере на основе данных документа я создаю модель для дальнейшей работы.
public class Event { public static final String START = «start»; public static final String STOP = «stop»;
private final LocalTime start; private final LocalTime stop;
public Event (LocalTime start, LocalTime stop) { this.start = start; this.stop = stop; }
public boolean isInProgress (LocalTime time) { return (time.isEqual (start) || time.isAfter (start)) && (time.isBefore (stop) || time.isEqual (stop)); } } (в тривиальных случаях конечно можно просто использовать данные из документа, и сразу вернуть результат, и это было бы быстрее)Результат в нашем случае — это »1» для событий, происходящих сейчас (start <= time <= stop), и «0» для всех остальных. Тип результата — Integer, т.к. сортировать по Boolean Elasticsearch не умеет.
После обработки скрипта для каждого документа будет определено значение, по которому Elasticsearch их и отсортирует. Задача выполнена!
Интеграционные тесты Помимо того, что тесты хороши сами по себе, это еще и отличная точка входа для отладки. Очень удобно поставить breakpoint, и запустить дебаг нужного теста. Без этого отлаживать плагин было бы весьма затруднительно.Схема интеграционного тестирования плагина примерно такова:
Запустить тестовый кластер Создать индекс и маппинг Добавить документ Попросить сервер вычислить значение скрипта для заданных параметров и документа Убедиться, что значение правильное Для запуска тестового сервера воспользуемся базовым классом ElasticsearchIntegrationTest. Можно настроить число нод, шардов и реплик. Подробнее — на GitHub.Пожалуй, есть два способа создания тестовых документов. Первый — построить документ непосредственно в тесте — пример можно посмотреть здесь. Этот вариант вполне хорош, и сначала я его и использовал. Однако, схема документов меняется, и со временем может оказаться так, что структура, построенная в тесте уже не соответствует реальности. Поэтому второй способ — хранить маппинг и данные отдельно в виде ресурсов. Кроме того, этот способ дает возможность в случае неожиданных результатов на живых сереверах просто скопировать проблемный документ в виде ресурса и увидеть, как тест упадет. В общем, любой способ хорош, выбор за вами.
Для запроса результата вычисления скрипта воспользуемся стандартным Java-клиентом:
SearchResponse searchResponse = client () .prepareSearch (TEST_INDEX).setTypes (TEST_TYPE) .addScriptField (scriptName, «native», scriptName, scriptParams) .execute () .actionGet (); Исходный код полностьюИнтеграция с Travis-CI Необязательная часть программы — интеграция с Continuous Integration системой Travis. Добавим файл .travis: language: java
jdk: — openjdk7 — oraclejdk7
script: — mvn test и CI-сервер будет тестировать ваш код после каждого изменения, выглядит это так. Мелочь, а приятно.Применение Итак, плагин готов и протестирован. Пришло время попробовать его в деле.Установка Про инсталляцию плагинов можно прочитать в официальной документации. Собранный плагин находится в ./target. Для облегчения локальной установки я написал небольшой скрипт, который собирает плагин и устанавливает его: mvn clean package if [ $? -eq 0 ]; then plugin -r plugin-example plugin --install plugin-example --url file://`pwd`/`ls target/*.jar | head -n 1` echo -e »\033[1;33mPlease restart Elasticsearch!\033[0m» fi Исходный кодСкрипт написан для Mac/brew. Для других систем, вероятно, придется поправить путь к файлу plugin. В Ubuntu он находится в /usr/share/elasticsearch/bin/plugin. После установки плагина не забывайте перезапустить Elasticsearch.
Тестовые данные Простенький генератор тестовых документов написан на Ruby. bundle install ./generate.rb Тестовый запрос Попросим Elasticsearch отсортировать все события по результату скрипта «in_progress»: curl -XGET «http://localhost:9200/demo/event/_search? pretty» -d' { «sort»: [ { »_script»: { «script»: «in_progress», «params»: { «time»:»15:20:00», «use_doc»: true }, «lang»: «native», «type»: «number», «order»: «desc» } } ], «size»: 1 }' Результат: { «took» : 139, «timed_out» : false, »_shards» : { «total» : 2, «successful» : 2, «failed» : 0 }, «hits» : { «total» : 86400, «max_score» : null, «hits» : [ { »_index» : «demo», »_type» : «event», »_id» : «AUvf6fPPoRWAbGdNya4y», »_score» : null, »_source»:{«start»:»07:40:01», «stop»:»15:20:02»}, «sort» : [ 1.0 ] } ] } } Видно, что сервер посчитал значения для 86400 документов за 139 миллисекунд. Конечно, этоне сравнится по скорости с простой сортировкой (2 мс), но все равно неплохо для ноутбука. Кроме того, скрипты запускаются параллельно в разных шардах и таким образом масштабируются.Методы source () и doc () Как я писал в начале, скрипту доступны несколько методов доступа к содержимому документа. Это source (), fields (), и doc (). Source () — удобный и медленный способ. При запросе происходит загрузка всего документа в HashMap. Но зато потом доступно абсолютно все. Doc () — это доступ к проиндексированным данным, он гораздо быстрее, но работать с ним немного сложнее. Во-первых, не поддерживается тип Nested, что накладывает ограничения на структуру документа. Во-вторых, проиндексированные данные могут отличаться от того, что находится в самом документе, в первую очередь это касается строк. В качестве эксперимента задания можете попробовать убрать «index»: «not_analyzed» в mapping.json, и посмотреть, как все сломается. Что касается метода fields (), то честно говоря я его так и не попробовал, судя по документации он немногим лучше source ().Теперь попробуем использовать source (), изменив параметр use_doc на false.
Запрос curl -XGET «http://localhost:9200/demo/event/_search? pretty» -d' { «sort»: [ { »_script»: { «script»: «in_progress», «params»: { «time»:»15:20:00», «use_doc»: false }, «lang»: «native», «type»: «number», «order»: «desc» } } ], «size»: 1 }' И вот уже «took»: 587 миллисекунд, т.е. в 4 раза медленнее. В реальном приложении с большими документами разница может быть в сотни раз.Другие применения скрипта Скрипт из плагина можно использовать не только для сортировки, а вообще в любых местах, где поддерживаются скрипты. Например, можно вычислить значение для найденных документов. В этим случае, кстати, производительность уже не настолько важна, поскольку вычисления производятся для отфильтрованного и лимитированного набора документов. curl -XGET «http://localhost:9200/demo/event/_search» -d' { «script_fields»: { «in_progress»: { «script»: «in_progress», «params»: { «time»:»00:00:01», «use_doc»: true }, «lang»: «native» } }, «partial_fields»: { «properties»: { «include»: [»*»] } }, «size»: 1 }' Результат { «took»: 2, «timed_out»: false, »_shards»: { «total»: 2, «successful»: 2, «failed»: 0 }, «hits»: { «total»: 86400, «max_score»: 1, «hits»: [ { »_index»: «demo», »_type»: «event», »_id»: «AUvf6fO9oRWAbGdNyUJi», »_score»: 1, «fields»: { «in_progress»: [ 1 ], «properties»: [ { «stop»:»00:00:02», «start»:»00:00:01» } ] } } ] } } На этом все, спасибо, что дочитали! Исходный код на GitHub: github.com/s12v/elaticsearch-plugin-demo
P.S. Кстати, нам очень нужны опытные программисты и сисадмины для работы над крупным проектом на основе AWS/Elasticsearch/Symfony2 в Берлине. Если вдруг вам интересно — пишите!
