PHP-Compiler, или ныряем в кроличью нору FFI
Однажды Энтони Феррара (Anthony Ferrara) решил скомпилировать PHP в низкоуровневый код, но результат получился слабым. Главной проблемой, с которой он столкнулся, было отсутствие подходящего бэкенда. К лучшему все изменилось после того, как в дело вступил FFI.
Я советую прочитать статью «A PHP Compiler, aka The FFI Rabbit Hole», перевод который вы найдёте под катом.

Мое хобби — создавать игрушечные компиляторы и языки программирования. Но сегодня я хочу познакомить читателей блога с чем-то мало похожим на игрушку — с php-compiler. У меня много таких проектов, которые, надеюсь, однажды перейдут из категории экспериментальных в проекты, готовые к использованию в продакшене.
В этой статье будет много разговоров о компиляторах и компонентах, поэтому неплохо начать с вводной информации о том, как они работают и чем отличаются.
Виды компиляторов
Существуют три основных способа выполнения программ.
Интерпретация: подавляющее большинство динамических языков (например, PHP, Python (CPython), Ruby и т. д.) можно интерпретировать с помощью какой-либо виртуальной машины.
На наиболее абстрактном уровне виртуальная машина — гигантский switch в цикле. Инструменты языка программирования парсят и компилируют исходный код в форму промежуточного представления, часто называемую «опкоды» или «байт-код».
Главное преимущество виртуальной машины — простота ее сборки для динамических языков, в результате чего не нужно тратить время на компиляцию кода.
Компиляция: значительная часть языков, которые мы считаем статическими, компилируется заранее (ahead of time, AOT) прямо в нативный машинный код. Многие языки (C, Go, Rust и т. д.) используют AOT-компилятор.
Суть AOT в том, что вся компиляция происходит целиком до выполнения кода. Это значит, что вы сначала компилируете код и через некоторое время выполняете его.
Основное преимущество AOT-компиляции — генерация очень эффективного кода, а главный недостаток — длительность компиляции.
Just In Time (JIT): JIT относительно недавно стал популярным методом, благодаря которому можно взять лучшее от виртуальной машины и AOT. Многие языки программирования — Lua, Java, JavaScript, Python через интерпретатор PyPy, HHVM, PHP 8 и прочие — используют JIT.
В сущности, JIT — просто сочетание виртуальной машины и AOT-компилятора. Вместо того, чтобы компилировать всю программу за раз, он выполняет какую-то часть кода на виртуальной машине. Такая компиляция преследует две цели:
1) выяснить, какие части кода «горячие», а значит, наиболее полезны для компиляции в машинный код;
2) собрать информацию о рантайме кода, например, какие типы данных используются чаще всего.
Затем JIT-компилятор ненадолго приостанавливает выполнение кода, чтобы скомпилировать только эту небольшую часть в машинный код. JIT попеременно то интерпретирует исходный код, то выполняет скомпилированный.
Главный плюс JIT-компиляции в том, что в некоторых сценариях использования она объединяет скорость развертывания виртуальной машины с производительностью, характерной для AOT. Это невероятно сложный процесс, так как нужно собрать два полнофункциональных компилятора и интерфейс между ними.
Подытожим:
интерпретатор выполняет код;
AOT-компилятор генерирует машинный код, который потом выполняет компьютер;
IT-компилятор тоже выполняет код, но по частям — время от времени он преобразовывает некоторую часть выполняемого кода в машинный код, а затем его выполняет.
Немного объяснений
Я много раз использовал и «компилятор», и кучу других терминов. Все они многозначны, поэтому немного поговорим об этом.
Компилятор: значение термина «компилятор» зависит от контекста.
Если мы говорим о сборке рантаймов языков программирования (эти рантаймы тоже называют компиляторами), то компилятор — программа, которая преобразовывает код из одного языка в другой с отличной от него семантикой. Это не просто иное представление кода — код именно преобразовывают. Примеры такого преобразования: из PHP в опкоды, из C в промежуточное представление, из ассемблера или регулярного выражения в машинный код. Да, в версии PHP 7.0 есть компилятор, который компилирует исходный код языка PHP в опкоды.
В контексте использования рантаймов языков программирования (также известных как компиляторы) под компилятором обычно подразумевают определенный набор программ, который преобразует оригинальный исходный код в машинный. Стоит отметить, что компилятор (например, gcc) обычно состоит из нескольких более мелких компиляторов, которые работают последовательно, чтобы трансформировать исходный код.
Да уж, запутано…
Виртуальная машина (VM): я упомянул выше, что виртуальная машина — гигантский switch в цикле. Чтобы понять, почему ее называют виртуальной, давайте немного поговорим о том, как работает настоящий физический CPU.
Настоящая машина выполняет команды, закодированные в нули и единицы. Эти команды можно представить как код ассемблера:

Этот код просто добавляет 1 к регистру rsi, затем добавляет к нему 2.
Посмотрите, как та же операция представлена в опкодах PHP:

Если не принимать во внимание соглашение об именах, то можно сказать, что по сути они равнозначны. Опкоды PHP — команды-кирпичики для виртуальной машины PHP, а ассемблер — то же самое для CPU.
Разница в том, что команды ассемблера очень низкоуровневые, и их сравнительно немного, в то время как в команды опкода виртуальной машины PHP встроено больше логики. В примере команда ассемблера incq ожидает аргумент в виде целого числа. С другой стороны, опкод POST_INC содержит всю логику, необходимую для того, чтобы сначала преобразовать аргумент в целое число. В виртуальной машине PHP гораздо больше логики, что в свою очередь:
а) делает существование PHP и любого интерпретируемого языка возможным,
б) становится главной причиной того, что интерпретируемые языки часто используют VM.
Парсер: парсер очень похож на компилятор, но он не преобразовывает исходный код, а лишь меняет представление. В качестве примера работы парсера можно привести преобразование текста (написанного вами исходного кода) во внутреннюю структуру данных (такую, как дерево или граф).
Дерево абстрактного синтаксиса (Abstract Syntax Tree, AST): AST — внутренняя структура данных, которая представляет исходный код программы в виде дерева. Таким образом, вместо $a = $b + $c; получаем что-то вроде Assign ($a, Add ($b, $c)). Главная характеристика дерева — у каждого узла только один родитель. PHP выполняет внутреннее преобразование исходного файла в AST перед компиляцией в опкоды.
Если дан следующий код:

то можно ожидать, что AST будет выглядеть так:

Граф потока управления (control flow graph, CFG): CFG во многом похож на AST, но если у первого может быть несколько корневых элементов, то у второго только один. Это можно объяснить так: CFG включает в себя связи между циклами и т. п., так что можно увидеть все возможные пути управления, проходящие через весь код. Расширение Opcache Optimizer для PHP использует внутри CFG.
Если дан следующий код:

то можно ожидать, что CFG будет выглядеть так:
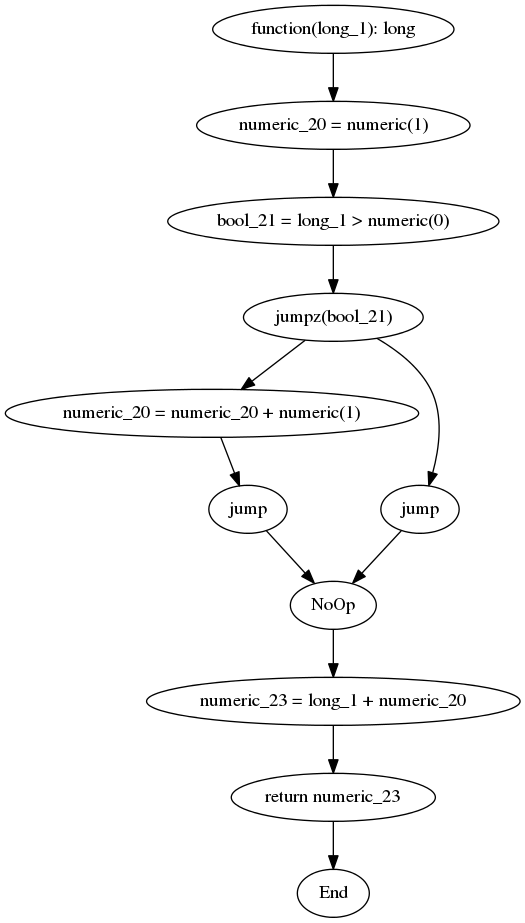
В этом случае long — целое число PHP, numeric — целое число или число с плавающей запятой, jumpz — переход к другой команде в зависимости от того, равна ли bool_21 0 или нет.
Заметьте, можно увидеть, как именно исполняется код. По этой же причине компилятор использует CFG, но вместо образа оперирует структурой данных.
Промежуточное представление (Intermediary Representation, IR): IR — язык программирования, который полностью «живет» в компиляторе. Вы никогда не будете писать на этом языке, его для вас генерируют. Тем не менее, стоит отметить, что IR нужен для некоторых манипуляций компилятора (например, для реализации оптимизаций), а также для того, чтобы компоненты компилятора были разделены (в итоге их легче настраивать). Вышеупомянутые структуры AST и CFG — формы IR.
Немного предыстории
Я впервые попытался выполнить PHP поверх PHP в рамках проекта PHPPHP еще в 2013 году. Суть проекта состояла в том, чтобы «перевести» исходный код из репозитория php-src с языка C на PHP. Не было и речи о том, что виртуальная машина будет работать «быстро» (слово «быстро» в кавычках, так как эта машина примерно в 200 раз медленнее, чем PHP, и нет никакого способа ее разогнать). Я просто развлекался, мне нравилось экспериментировать и учиться чему-то новому и интересному.
Полтора года спустя я создал набор инструментов Recki-CT, который работал по иной схеме. Вместо того, чтоб реанимировать прошлую попытку — PHP в PHP, я создал многоступенчатый компилятор. Он парсил PHP в AST, преобразовывал AST в CFG, проводил оптимизацию, затем выдавал код через бэкенд. Для этой задачи я собрал два начальных бэкенда: один компилировал код в расширение PECL, а второй использовал расширение JitFu для непосредственного выполнения кода, оперативно компилировал его и запускал в виде нативного машинного кода. Эта реализация работала довольно неплохо, но была мало применима на практике по ряду причин.
Несколько лет спустя я снова вернулся к этой идее, но решил не создавать единый монолитный проект, а заняться серией взаимосвязанных проектов по парсингу и анализу PHP. В рамках этих проектов были реализованы следующие инструменты: PHP-CFG — парсинг CFG, PHP-Types — система вывода типов, PHP-Optimizer — базовый набор оптимизаций поверх CFG. Я разработал эти инструменты для того, чтобы встроить их в другие проекты для различных целей (например, Tuli — ранняя версия статического анализатора кода PHP). В проекте PHP-Compiler я пытался компилировать PHP в низкоуровневый код, но результат получился слабым.
Главной проблемой, с которой я столкнулся при создании полезного низкоуровневого компилятора, было наличие (точнее отсутствие) подходящего бэкенда. Библиотека libjit (используемая расширением JitFu) работала хорошо и быстро, но не могла генерировать бинарники. Я мог бы написать расширение на C, привязанное к LLVM (HHVM использовала инфраструктуру LLVM и многие другие), но это ОЧЕНЬ трудозатратный процесс. Я не захотел идти этим путем и отложил эти проекты до лучших времен.
В игру вступают PHP 7.4 и FFI
Нет, версия PHP 7.4 еще не вышла (Пост был опубликован в 22 апреля 2019 года). Возможно, она будет выпущена через полгода. Несколько месяцев назад небольшое предложение по включению расширения FFI в PHP успешно прошло голосование. Я решил поиграть с этим расширением, чтобы узнать, как оно работает.
Спустя некоторое время я вспомнил о своих проектах, связанных с компиляторами. Я стал думать, насколько сложно будет загрузить libjit в PHP, но затем сообразил, что эта библиотека не может генерировать исполняемые файлы. Я начал искать возможные варианты решения проблемы и наткнулся на библиотеку libgccjit. Так началось мое путешествие по кроличьей норе.
Вот все новые проекты, над которыми я работал последние несколько месяцев.
FFIMe
Мой первый шаг — создание обертки над libgccjit. FFI требует заголовочный файл, похожий на C, но сам не может обрабатывать макросы препроцессора C. Непонятно? Ок, просто знайте, что у каждой библиотеки есть по крайней мере один заголовочный файл, который описывает функции, и FFI нужна его сокращенная версия.
Я не хотел вручную редактировать несколько сотен описаний функций и кучу типового кода, поэтому решил собрать библиотеку, которая бы сделала это за меня.
Встречайте FFIMe.
Для начала мне был нужен препроцессор языка С для «компиляции» заголовочных файлов в форму, достаточную для FFI. Я приступил к работе и примерно месяц спустя понял, что мне нужно большее. Я не мог просто обработать заголовки, их нужно было распарсить. После существенного рефакторинга кода FFIMe теперь может генерировать вспомогательные классы для использования с FFI. Не без недостатков, конечно, но для моих задач достаточно.

По сути, FFIMe получает путь к Shared Object File и к директивам #include. Он парсит получившийся С, убирает несовместимый с FFI код и затем генерирует класс. Хорошо, МНОГО классов. Теперь сгенерированный файл можно рассмотреть (файл из примера выше на GitHub).
Если вы посмотрите на этот файл, то увидите ОГРОМНОЕ количество кода — почти 5 000 строк. Он включает в себя все числовые #define заголовков C как константы класса, все ENUM как константы класса, а также все функции и классы-обертки всех базовых типов C. Файл также рекурсивно содержит все другие заголовки (поэтому у заголовка выше есть некоторые на первый взгляд лишние файловые функции).
Код использовать весьма просто. Примечание: не обращайте внимание на то, что делает библиотека, просто смотрите на типы и на вызовы, затем сравните с эквивалентным кодом на C:

Теперь можно работать с библиотеками C в PHP как будто бы они в C! Ура!
Стоит отметить, что, несмотря на некоторые недоработки FFI, которые позже были исправлены, работать с ним довольно просто. Неплохая альтернатива погружению в дебри PHP (кхе-кхе). Дмитрий Стогов — автор FFI для PHP — проделал великолепную работу.
PHP-CParser
Сделав рефакторинг FFIMe, я решил собрать полнофункциональный C parser. Он работает так же, как PHPParser разработчика Никиты Попова, но не в PHP, а в C.
Пока поддерживается не весь синтаксис C, но PHP-CParser использует стандартную грамматику C, так что теоретически он способен парсить все без исключения.
В начале препроцессор C обрабатывает заголовочные файлы — он резолвит все стандартные директивы, такие как #include, #define, #ifdef и т. д. Потом PHP-CParser парсит код в AST (по мотивам CLANG).
Таким образом, например, следующий код C:

и includes_and_typedefs.h:

даст такой AST:

Синие имена — имена классов объектов, а красные имена в нижнем регистре — имена свойств указанных объектов. Так, внешний объект здесь — PHPCParser\Node\TranslationUnitDecl с массивом свойств declarations. И так далее…
Очень редко кому-то надо парсить код C в PHP, поэтому я полагаю, что эту библиотеку будут использовать только с FFIMe. Но если вы захотите ее использовать — вперед!
PHP-Compiler
Я вернулся к проекту PHP-Compiler и начал работу над ним. В этот раз я добавил несколько этапов к компилятору. Я решил не компилировать непосредственно из CFG в нативный код, а применить Virtual Machine interpreter (именно так и работает PHP). Это ГОРАЗДО более зрелый подход, чем тот, который я использовал в PHPPHP. Я не остановился на этом и создал компилятор, который может брать опкоды виртуальной машины и генерировать нативный машинный код. Это позволило применить как JIT-компиляцию (Just In Time), так и AOT-компиляцию (Ahead of Time). Таким образом, я могу не только запускать код или компилировать его во время запуска, но и предоставить компилятору кодовую базу для того, чтобы он сгенерировал файл машинного кода.
Это означает, что со временем я смогу (сейчас — теоретически) компилировать сам компилятор в нативный код, что может в перспективе прилично ускорить работу интерпретатора (не знаю, будет ли он работать так же шустро, как PHP 7, но я надеюсь на это). Если же стадия компиляции будет быстрой, то есть шанс не просто реализовать PHP в PHP, а делать это с максимальной скоростью.
Я начал собирать PHP-Compiler поверх libgccjit и получил весьма интересные результаты. Простой набор бенчмарков, взятых из пакета PHP, показывает, что хотя сейчас и есть МНОГО накладных расходов, скомпилированный код может быть действительно блестящим.
Следующие тесты сравнивают производительность PHP-Compiler, PHP 7.4 с OPcache (Zend Optimizer) и без него, а также экспериментального JIT (в включенном и выключенном состоянии) для PHP 8.

Заметен ощутимый простой при старте (помните, это PHP!). Однако компиляция кода (как в режиме JIT, так и в режиме AOT) происходит значительно быстрее, чем в PHP 8 с JIT-компиляцией в особо сложных вариантах использования.
Стоит отметить, что мы сравниваем совершенно разные вещи. Не стоит ожидать такие же показатели в продакшен-проектах, но по ним можно сделать вывод о перспективности такого подхода…
Сейчас можно использовать эти 4 команды:
php bin/vm.php — запустить код в виртуальной машине;
php bin/jit.php — компилировать весь код, затем запустить его;
php bin/compile.php — компилировать весь код и вывести файл a .o;
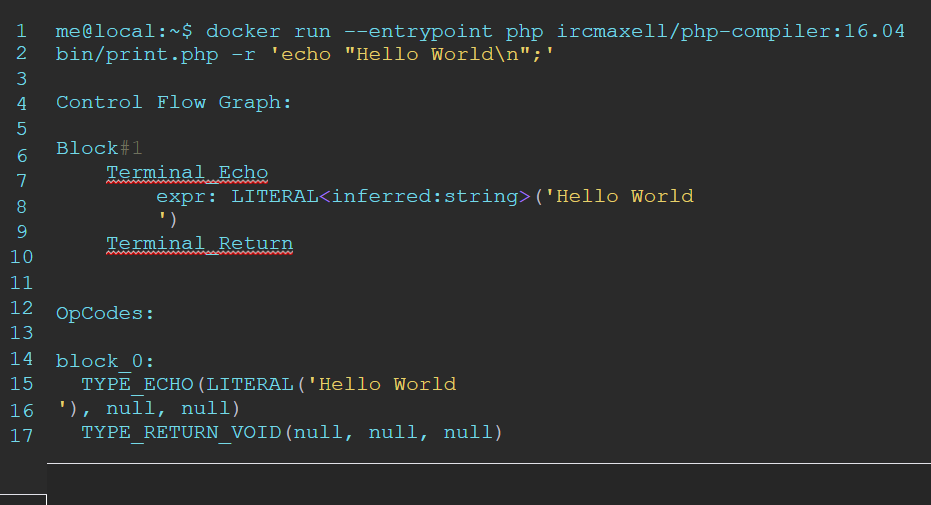
php bin/print.php — компилировать и вывести CFG и сгенерированные опкоды (полезно для отладки).
В командной строке все работает как PHP:

Да, здесь echo «Hello World\n»; работает как нативный машинный код. Перебор? Определенно. Прикольно? Однозначно!
Подробности в описании проекта.
Я приостановил сборку, потому что не знал, стоит ли и дальше использовать libgccjit или лучше перейти на LLVM?
Есть только один способ выяснить это…
PHP-Compiler-Toolkit
Как вы уже поняли, я не умею давать названия вещам…
PHP-Compiler-Toolkit — уровень абстракции поверх libjit, libgccjit и LLVM.
Вы просто «встраиваете» код, похожий на код языка C, в кастомное промежуточное представление через нативный интерфейс PHP. Например, это выражение (обратите внимание, что long long — 64-битное целое число, как и тип PHP int):

можно использовать так:

Это «описывает» код. Отсюда можно передать контекст бэкенду для компиляции:

и потом просто получить в ответ:

Вот мы и получили чистый нативный код.
Теперь я могу собрать фронтенд (PHP-Compiler) поверх этой абстракции и менять бэкенды для тестирования.
Выходит, что тестирование было хорошей идеей, потому что первые прогоны показывают, насколько медленно работает libgccjit в этой конфигурации. Замеры компиляции:
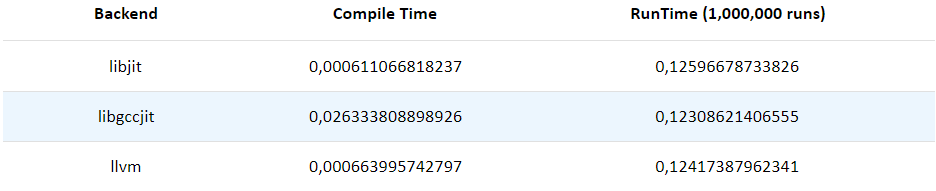
Хотя все бэкенды и имеют сравнимые показатели в рантайме, продолжительность компиляции для libgccjit зашкаливает. Хм, может я был прав, когда думал перейти на LLVM?…
Да, и для такой простой функции накладные расходы FFI весьма значительные. На запуск этого же кода в PHP уходит примерно 0,02524 секунды.
Чтобы продемонстрировать, что PHP-Compiler может в перспективе работать гораздо быстрее, чем PHP, представьте себе такой бенчмарк:
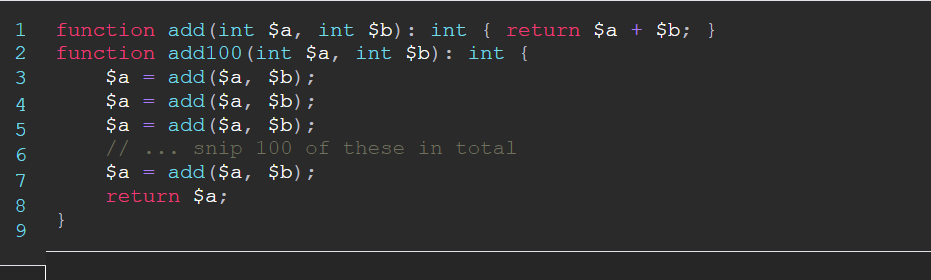
В нативном PHP запуск этого кода миллион раз займет примерно 2,5 секунды. Не то чтобы медленно, но и не супер быстро. Однако с PHP-Compiler мы видим следующее:

В этом искусственном примере можно увидеть десятикратный прирост производительности по сравнению с нативным PHP 7.4.
Вы можете посмотреть этот пример и скомпилированный код в examples folder of php-compiler-toolkit.
PHP-LLVM
После проекта PHP-Compiler-Toolkit я начал работу над PHP-LLVM. Эксперименты с Toolkit показали, что у libgccjit нет реальных преимуществ перед LLVM, у которой есть преимущества в производительности и функциональности, поэтому я решил перевести PHP-Compiler исключительно на нее.
Я не стал обращаться непосредственно к LLVM C-API, а написал обертку над ним. Я преследовал две цели:
1) я получаю более объектно-ориентированный API, так как, чтобы получить тип значения, пишу $value→typeOf (), а не LLVMGetType ($value);
2) с оберткой я могу не обращать внимание на различия в версиях LLVM.
Таким образом, в идеале можно добавить поддержку различных версий LLVM и проверить, поддержка каких возможностей реализована.
PHP-ELF-SymbolResolver
Стоит отметить, что в LLVM были ошибки, поэтому мне нужно было видеть, какие символы на самом деле компилируются в LLVM.Таким образом, я хотел проверить общий файл объекта (.so), который содержит скомпилированную библиотеку LLVM. Для этого я написал PHP-ELF-SymbolResolver, который парсит файлы формата ELF и показывает объявленные символы.
По определенным причинам я сомневаюсь, что этот проект будет востребован вне FFIMe, но, возможно, кому-то будет нужно декодировать нативную библиотеку ОС в PHP. В таком случае вы знаете, где взять библиотеку!
Использование макросов
Портируя PHP-Compiler на PHP-LLVM, я понял, что генерация кода с использованием API как билдера быстро становится многословной. Код невозможно прочитать. Например, возьмем сравнительно «простую» встроенную функцию __string__alloc, которая определяет новую внутреннюю структуру строки. Если использовать API как билдер, то она будет выглядеть примерно так:

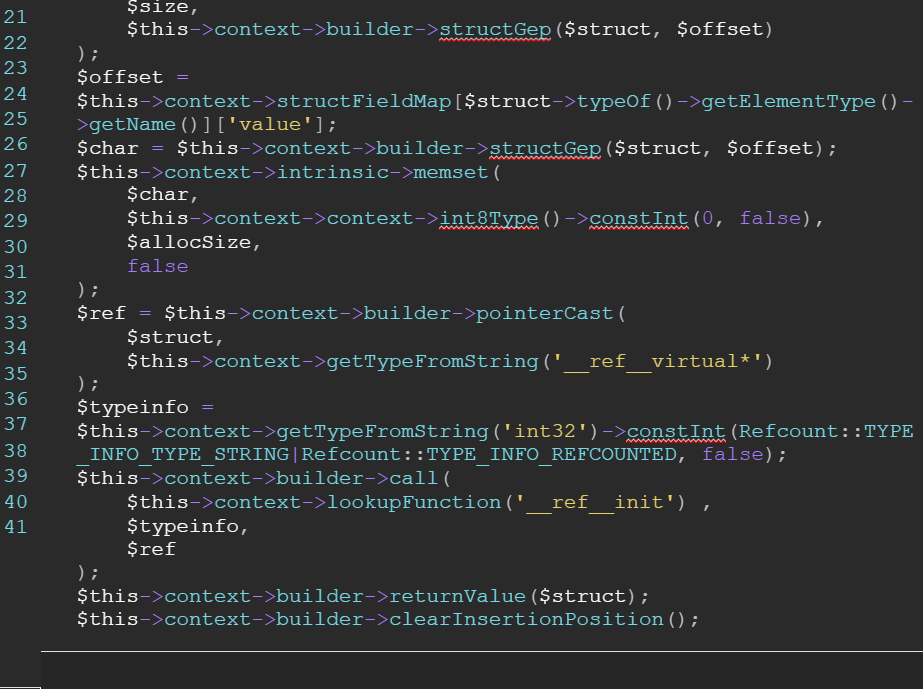
Просто куча мусора. Трудно понять что-либо, а если какую-то часть кода и можно прочитать, то с ней очень сложно работать).
Чтобы избежать такого результата, я написал систему макросов с помощью PreProcess.io и Yay. Теперь тот же код выглядит так:

Читать код стало гораздо легче. Это смесь синтаксиса C и PHP, заточенная под нужды PHP-Compiler.
Язык макросов частично задокументирован на GitHub-е.
Подробности о применении макросов смотрите на src/macros.yay (GitHub).
Беспокоитесь о производительности? Правильно делаете. На обработку файлов нужно время (примерно одна секунда на файл). Есть два способа борьбы с этим:
1) предварительная обработка возможна только при установке PHP-Compiler с dev-зависимостями с помощью композера, иначе будут загружены только скомпилированные файлы PHP;
2) предварительная обработка произойдет «на лету» только при изменении файла .pre, даже с dev-зависимостями.
В итоге накладные расходы в режиме разработки несущественны, а в продакшене их просто нет.
Запуск
Сначала установите PHP 7.4 с включенным расширением FFI. Насколько мне известно, эта версия PHP еще не вышла (и до того, как выйдет, пройдет еще немало времени).
Запуск FFIMe:
Объявите FFIMe dev-зависимостью композера («ircmaxell/ffime»: «dev-master») и запустите генератор кода через файл стиля rebuild.php. Например, файл rebuild.php, используемый PHP-Compiler-Toolkit, выглядит так:
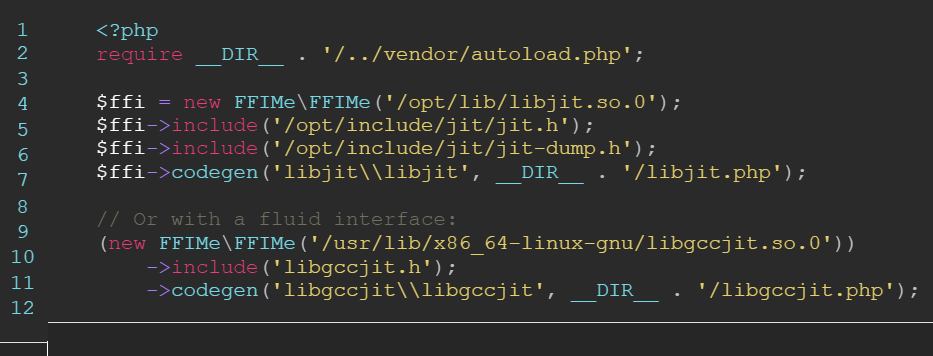
Потом сравните сгенерированные файлы. Я предлагаю включать сгенерированные файлы через композер с ключевым словом files, а не загружать их автоматически, потому что композер сгенерирует ОГРОМНОЕ количество классов в один файл.
Замените строку »…so.0» путем к общей библиотеке, которую вы хотите загрузить, и файл .h заголовками, которые нужно парсить (можно много раз вписать →include ()).
Предлагаю поиграть с FFIMe и открыть ишью на GitHub для всего, что вы не поняли. Я выпущу стабильную версию FFIMe, только если этот проект заинтересует других разработчиков — нужно провести тесты и настроить непрерывную интеграцию.
Запуск PHP-Compiler нативным образом
Сейчас PHP-Compiler работает нестабильно, что-то может ломаться, поэтому сначала установите зависимости (можно использовать LLVM 4.0, 7, 8 и 9).

После окончания установки просто запустите их.
Вы можете задать выполнение в командной строке, используя аргумент -r:

Еще можно задать файл:

При компиляции bin/compile.php также можно задать выходной файл с -o (по умолчанию будет перезаписан исходный файл без расширения .php). Для системы будет сгенерирован готовый к выполнению бинарник:

Или по умолчанию:

Список поддерживаемого будет очень часто меняться. Код, который работает сегодня, может не работать на следующей неделе. Сейчас реализована поддержка для очень небольшого числа версий PHP…
Запуск PHP-Compiler с Docker
Удобства ради я опубликовал два docker-образа для PHP-Compiler. Оба основаны на старой версии Ubuntu (16.04) из-за некоторых проблем с PHP-C-Parser, до которых у меня не дошли руки. Но вы можете скачать их и поиграть с ними:
Ircmaxell/php-compiler:16.04 — полнофункциональный компилятор, полностью установленный и сконфигурированный со всем необходимым для его запуска;
Ircmaxell/php-compiler:16.04-dev — только dev-зависимости. Контейнер предназначен для работы с вашей собственной сборкой PHP-Compiler, чтобы вы могли разрабатывать его в стабильной среде.
Для запуска кода:

Код будет по умолчанию запущен с bin/jit.php. Если вы хотите запустить код с другой точки входа, то ее можно изменить:
Да, и если вы хотите «передать» скомпилированный код, то можно расширить docker-файл. Например:
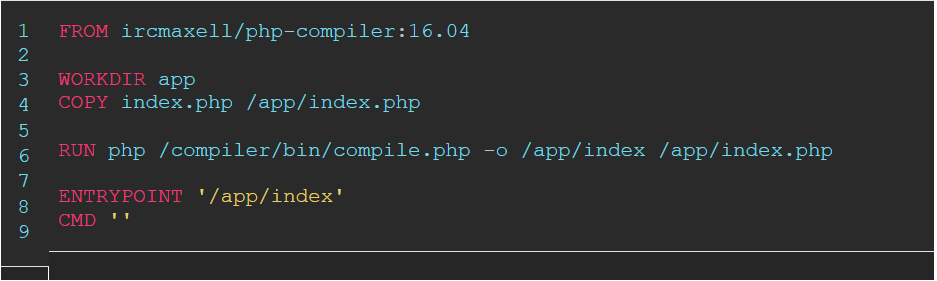
Во время запуска сборки docker код будет скомпилирован в index.php, а файл машинного кода будет сгенерирован в /app/index. Затем этот бинарник будет выполнен при запуске docker run … Обратите внимание: контейнер не предназначен для продакшена, так как в нем много лишнего, это просто демонстрация работы.
Что дальше
Теперь, когда PHP-Compiler поддерживает LLVM, можно продолжать работу по расширению поддержки языка. Еще многое предстоит сделать: например, массивы, объекты, нетипизированные переменные, обработку ошибок, стандартную библиотеку и т. д.). Хе-хе. В PHP-CFG и PHP-Types также есть, чем заняться: поддержкой исключений и ссылок, исправлением пары ошибок и многим другим.
Да, нужны тесты. Много тестов. И тестировщики. Пробуйте, ломайте — это легко, обещаю. И создавайте ишью.
Протестируете?
PHP Russia 2021 пройдет 28 июня в Москва, Radisson Slavyanskaya. Но уже сейчас можно ознакомиться с расписанием и присмотреть доклады, которые вы точно не захотите пропустить.
А еще вы можете выбрать формат участия: онлайн или офлайн. Не забудьте купить билеты уже сегодня!
На всех наших офлайн площадках мы соблюдаем антиковидные меры:
1. Все сотрудники конференции сдают тест ПЦР и ходят в масках.
2. Участникам выдаём комплект медицинских масок и санитайзеры.
3. Во всех помещениях конференции и в фойе работают мощные рециркуляторы воздуха.
4. Каждый микрофон мы протираем спиртовыми салфетками, прежде чем передать его участнику.
5. В зоне кофебрейков и обедов соблюдаются нормы социальной дистанции.
