Параллелизм без потоков: очевидно и вероятно
«Зацепила» крайняя статья про многопоточность [1]. Но, с другой стороны, -, а что ожидал автор, предложив исходное решение без синхронизации? Получил то, что и должен был получить. На другое рассчитывать было бы достаточно наивно. Во-первых, потому, что используется весьма проблемная модель параллелизма. Во-вторых, расплывчатое представление о решаемой проблеме (по крайней мере, если судить по описанию). Но это уже мое личное мнение и хотелось бы его пояснить. И не просто так, а подкрепив решением.
Имеем счетчик. Только это уже не просто счетчик, а общий ресурс, с которому пытаются получить доступ множество параллельных процессов. Налицо некая общая проблема, с которой приходится сталкиваться на практике. Тут можно добавить, что проблема эта давняя, рассматривалась не раз и ее решений предлагалось множество.
Но, может, автор достиг чего-то нового? Да, вроде, нет. То, что нужно синхронизировать — не новость. Нов ли предложенный механизм синхронизации? Не знаю, поскольку не специалист в Python. Надеюсь такие найдутся и ответят на этот вопрос.
Покажу, как подобные проблемы решаю я. Причем совсем не прибегая ни к многопоточности, ни к всему тому, что нынче на волне успеха в так называемом параллельном программировании. И, как сказал автор статьи, «не спешите закрывать вкладку», а посмотрите, что будет дальше. А вдруг вам понравится?
Но для начала…
Краткая история вопроса
Использование переменной-счетчика в качестве общего ресурса — отнюдь не новость. Это элементарный и естественный подход к демонстрации проблем множества параллельных процессов. Насколько я припоминаю, впервые с подобным примером в серьезной литературе я столкнулся в книге [2].Предлагаемые там решения не вызвали восторга, а потому были задвинуты. И, кстати, об этом я не испытываю сожаления.
Несколько иной более формализованный взгляд на работу с общим ресурсом и все с тем же счетчиком (при рассмотрении проблем работы с общей памятью) представлен в [3]. Но опять же, он принципиально не отличался от упомянутого, а потому также не был взят на вооружение.
Перечисленные источники убеждают, что минимум уже лет этак 50 тому назад эти проблемы были известны, как и их рассмотрение и решения в рамках столь популярных нынче потоков и сопрограмм (тьфу-тьфу, корутин). Получается, что годы летят, а проблемы у потоков как были, так и остались. Что-что, а именно это автору статьи показать удалось достаточно убедительно. Но только надо ли было тратить время на демонстрацию того, что было известно и до этого?
Тем не менее, я даже соглашусь с тем, что статья не бесполезна, т.к. послужила триггером к написанию статьи, в которой я представлю альтернативный подход к решению подобных проблем. Альтернативы, ставшей результатом капризного взгляда автора на подобные многопоточные решения.
Автоматное модель доступа к общему ресурсу
Сначала рассмотрим самый простой вариант — счетчик и один процесс. В формализованном виде это представлено на рис. 1. Здесь X, N и counter — глобальные переменные, .cnt, .n — локальные переменные процесса, где X — число наращиваний счетчика, N — максимальное значение задержки перехода из состояния в состояние. При этом counter — собственно счетчик, .cnt — локальный счетчик процесса, .n — конкретное значение задержки. При N=0 задержка на переходе не формируется.
В состоянии s1, которое одновременно считается и начальным состоянием автомата, происходит подсчет циклов изменения счетчика. Когда количество циклов станет равным заданному, происходит переход в заключительное состояние s0.
Чтобы упростить модель, мы схитрили. Даже дважды. Во-первых, нет действий сбросу/установки переменных. Это делает среда при запуске проекта. Во-вторых, зная, что последовательность запуска формально параллельных действий (параллельными считаются множество действий, помечающих один переход) определяется их номером, мы упростили цикл наращивания счетчика до петли при состоянии.
Поясним последнее. Если следовать отмеченному выше порядку действий, то на самом деле сначала выполняется наращивание внутреннего счетчика циклов — действие y1, затем наращивание внешнего счетчика — y2, после этого вычисляется текущее значение задержки — y3 и затем реализуется сама задержка — y4. Собственно параллельными можно считать в полной мере только действия y1 и y2. Они в свою очередь могут исполнятся параллельно действиям y3, y4. Последние по отношению друг к другу последовательны. Все это можно было бы описать в явной форме, но автомат стал бы при этом несколько сложнее.
Задержка введена, чтобы смоделировать скорость процессов, что влияет на моменты обращения к общему ресурсу. Изменяя значение N можно моделировать «разнобой» в поведении процессов.
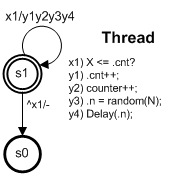
Рис. 1. Автоматный процесс обращения к счетчику
В окончательном виде приложение состоит из множества подобных процессов. Структурная схема решения, состоящего из 10-ти процессов, приведена на рис. 2.

Рис. 2. Структурная модель программы
На рис. 3 приведен вид решения в среде ВКПа (среда автоматного Визуального Компонентного Программирования). В данном случае представлены три окна среды — два прикладных, как примеры реализации двух выбранных процессов, и стандартное окно среды, отражающее глобальные переменные приложения и множество прикладных процессов.

Рис. 3. Реализация приложения в среде ВКПа
В окне переменных подчеркиванием выделен наш общий ресурс — переменная counter и ее свойство — посл. тип. Свойство, как мы увидим далее, определит режим работы процессов с данной переменной. Если флаг взведен, то процесс будет работать с переменной в обычном последовательном режиме. А это означает, что изменение переменной будет отражено ровно в момент изменения ее прикладным процессом. Если флаг сброшен, то новое значение переменной будет помещено в теневую переменную и станет ее текущим значением только в конце дискретного такта, когда все процессы уже завершат работу с переменными на текущем дискретном такте.
Результаты тестирования
Для начала рассмотрим чисто параллельный режим работы процессов, когда общий ресурс работает в режиме переменной параллельного типа (флаг посл.тип сброшен). При N=0, когда все процессы абсолютно одинаковы значение counter будет равно числу изменений счетчика X. И это верно, т.к. параллельные процессы, работая синхронно, считывают в какой-то момент текущее значение общего ресурса (оно для всех процессов будет одно и то же) и наращивают его. Но это новое значение ресурса станет текущим лишь в конце дискретного такта. Поэтому на текущем такте значение ресурса будет увеличено лишь на единицу, несмотря на то, что множество процессов будут пытаться проделать эту операцию одновременно.
Изменим значение N, оставив режим работы с ресурсом прежним. Мы сразу увидим результат: значение ресурса будет больше X, но меньше или равно X*К, где K — число процессов. При этом чем больше будет N, тем ближе будет значение счетчика к максимальному значению, но при соответствующем увеличении времени работы (когда все процессы попадут в состояние s0). Так мы сымитировали разнобой в поведении процессов. Заметим, что мы одновременно показали режим работы с памятью типа CRCW — параллельная запись/параллельное чтение (подробнее см.[4]).
Изменим тип ресурса на последовательный, когда флаг посл.тип взведен. Значение счетчика станет равным максимальному значению, т.е. counter = X*K. В этом случае любой параллельный процесс, получив доступ к ресурсу, изменяет его и это новое значение становится мгновенно текущим значением ресурса. Следующий процесс получит уже новое значение и также увеличивает его и т.д. При этом изменение значения N не повлияет на результат, а лишь увеличит время работы.
Выше было показано, что программировать параллельно можно, не используя при этом потоки. Но если все же к ним тянет, то есть и более детальное их описание, как, например, в [5]. Ну, а когда начитаетесь, то не забудьте просмотреть статью [6]. А, может, даже лучше с нее и начать? Ведь за последние почти 20 лет, т.е. с момента написания данной работы, проблем у потоков меньше не стало.
Нет правил без исключений
Казалось бы в параллельном программировании все должно быть параллельным без исключения. К процессам это относится в полной мере, но в их работе с памятью есть все же нюансы. Они отражены в режимах работы с памятью [4]. Рассматриваются обычно четыре режима и распространяются они на всю память. Но иногда желательно уметь задавать режим для отдельной области памяти. В ВКПа это можно делать вплоть до переменной. Выше мы это и продемонстрировали. Это значительно позволяет упростить алгоритм. Но пользоваться такой возможностью надо осторожно, чтобы не повлиять на само правило — выбранную концепцию параллелизма.
PS
Отвечая на … «Вопрос: какое значение счетчика выведет программа?» из статьи [1] я бы ответил так:
Ответ:
Если все процессы абсолютно одинаковы (а это так, исходя из кода программы), если они параллельны (будем считать, что это так), если запись и чтение счетчика также выполняются параллельно (это тоже должно быть так), то значение счетчика будет равно X (в статье это значение переменной operationsPerThreadCount).
Литература
1. Многопоточность в Python: очевидное и невероятное. [Электронный ресурс], Режим доступа: https://habr.com/ru/articles/764420/ свободный. Яз. рус. (дата обращения 05.10.2023).
2. Шоу А. Логическое проектирование операционных систем: Пер. с англ. — М.: Мир, 1981. — 360 с.
3. Хоар Ч. Взаимодействующие последовательные процессы: Пер. с англ. — М.: Мир, 1989. 264 с.
4. Дж.Макконелл Анализ алгоритмов. Вводный курс. — М.: Техносфера, 2002. — 304 с.
5. Multithreading. [Электронный ресурс], Режим доступа: https://habr.com/ru/companies/otus/articles/549814/ свободный. Яз. рус. (дата обращения 03.10.2023).
6. Эдвард А. Ли Проблемы с потоками. 2006. [Электронный ресурс], Режим доступа: http://www.softcraft.ru/parallel/pwt/pwt.pdf свободный. Яз. рус. (дата обращения 05.10.2023).
