Озвучка самокатов, часть 2: MIDI через пьезоизлучатель
Всем привет! В первой части статьи мы рассказали о том, как на наших IoT модулях реализована схема управления пьезоэлектрическим излучателем (баззером) с регулировкой частоты и амплитуды; как эта схема управляется микроконтроллером программно, воспроизводя простые звуки и мелодии. Такая реализация показала себя надежной в эксплуатации, нетребовательной к ресурсам и на начальном этапе решала задачу базовой озвучки самоката. Шло время, появлялись новые сценарии взаимодействия с пользователями и нам самим хотелось чего-то большего — например, хорошо было бы сделать звучание самоката более «фирменным», узнаваемым и приятным на слух. Так мы и задумались о «звуковом рефакторинге» — об этом и расскажем вам в этой статье.
Как улучшить качество звука?
Мы начали искать варианты изменения звучания нашего баззера. Первое, что приходит в голову — возможно ли реализовать полифонию и если да, то насколько качественную? Погуглив и почитав форумы, вдохновившись звучанием 8-битных игровых приставок и мелодий из тех времен, нам показалось, что мы нашли варианты решения проблемы. Может и у нас получится что-то интересное на текущем железе? А если воспроизводить хотя бы две ноты одновременно, возможностей открывалось ещё больше!
Но все упиралось в ту аппаратную начинку, которая у нас уже имелась, да еще и численностью несколько десятков тысяч устройств, и нужно было провести много экспериментов, чтобы понять, не станет ли это проблемой, и возможно ли её обойти программно.
Прошло N звукочасов. Казалось, мы перепробовали всё, и никакой вариант, кроме исходного, нам не подходил. Читая статьи, разбирая примеры чужих реализаций, мы собрали такой список идей для полифонии:
Воспроизводить две частоты с полной амплитудой попеременно — такой вариант мы попробовали, но слышали частоту переключения нот. Например, если менять частоты каждые 10 мс, то было отчетливо слышно частоту 100Гц
Складывать два прямоугольных сигнала по амплитуде — такой вариант показался интересным, но давал большое количество искажений. Также существенно было то, что обеспечивая запас по амплитуде для суммы нот, амплитуда воспроизведения одиночной ноты должна быть меньше, а значит, её громкость получалась ниже
Выдавать на баззер непосредственно звуковую волну, используя как ЦАП один из PWM — амплитудный или частотный. Это уже было больше похоже на попытку сделать из одного устройства (пьезокерамического излучателя) подобие другого (электромагнитного динамика);, но здесь всё обошлось простыми тестами с генератором — баззер резко терял в громкости при подаче на него синусоиды или прямоугольных импульсов с коэффициентом заполнения, отличным от 0,5. Мы не нашли объяснение этому эффекту и списали его на физические свойства керамической пластины. Если кто-то знает, какие процессы при этом происходят, было бы интересно почитать в комментариях
Подавать на один физический пин баззера одну частоту, на второй — другую (одновременно) так, как будто у нас два разных пьезоизлучателя. В теории частоты должны как-то складываться в пьезокерамике —, но такое нельзя реализовать в нашем железе: баззер подключен по мостовой схема и оба плеча включаются от одного источника импульсов через инвертор
Пробовали и гибридный вариант, без уменьшения амплитуды при сложении импульсов — положительная полуволна отвечает за одну частоту, отрицательная за другую, а при наложении +V и -V виртуальный ноль эмулировался через ШИМ с частотой 50 кГц и коэффициентом заполнения 0,5. Всё это выглядело примерно так:
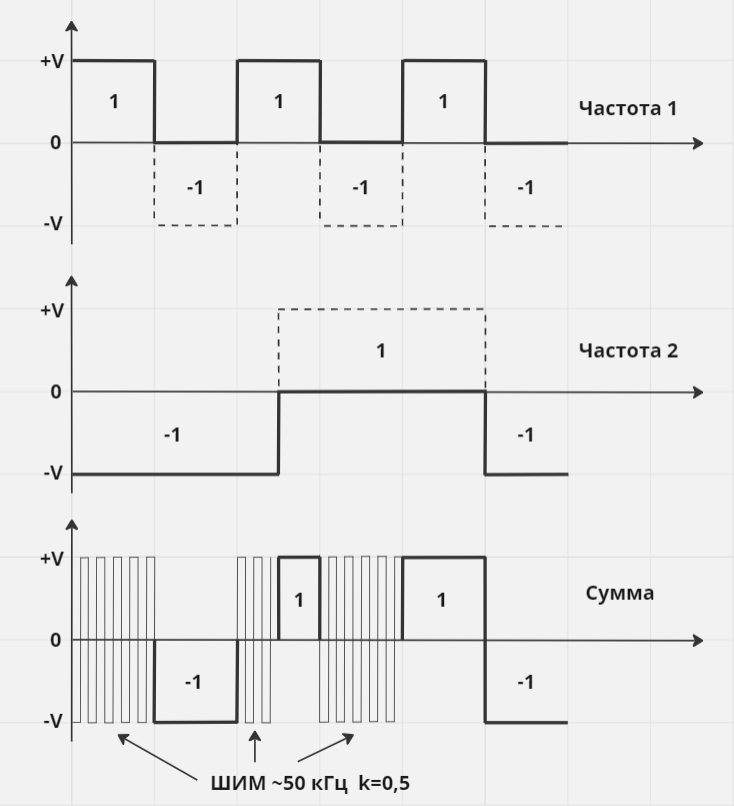
Результат сложения частот
А звучало так:
Всё осложнялось ещё и тем (как мы описывали в предыдущей статье), что баззер на некоторых нотах воспроизводил какие-то смежные частоты (призвуки), которые даже на слух перебивали основную воспроизводимую частоту и ломали всю мелодию. Например, тестовая мажорная гамма, воспроизведенная на баззере и снятая микрофоном, вот так выглядит на спектр-анализаторе в Adobe Audition:

Спектр баззера
На второй картинке, для сравнения, спектр стандартного электронного инструмента, где видно, как плавно, «лестницей», поднимаются все частоты:

Спектр стандартного электронного инструмента
Кажется, не стоит даже пытаться. Никакой полифонии, ничего другого, кроме прямоугольных импульсов с коэффициентом заполнения 0,5 и желательно на основной частоте баззера. Вся затея изначально была обречена на неудачу, проще оставить звуки самокатов такими, какие они есть.

Грусть, ночь и баззер
Но что, если мы пытаемся подойти к проблеме не с той стороны? Мы решаем её снизу, обдумывая проектирование слоя управления излучателем звука для достижения характеристик, которые ему, возможно, и не нужны. Что, если попытаться решить её сверху, отдав наш IoT с текущей реализацией аппаратной части в руки профессиональных музыкантов и посмотреть, что из этого можно сделать без хардовых доработок? Вдруг текущих возможностей самого излучателя и схемы раскачки уже вполне достаточно?
Так мы и поступили — провели несколько встреч с представителями студий звукового дизайна, которые имели в портфолио опыт озвучивания нестандартного оборудования. Мы, со своей стороны, описали технические возможности и предоставили IoT’ы для анализа звучания и оценки частотных характеристик. И одна из студий, потестировав баззер, резюмировала — они смогут добиться фирменного звучания и воспроизводить сложные звуки, например, способом очень быстрого перебора правильно подобранных частот. Баззер при этом остается «одноголосым», но с нашей стороны нужен функционал для быстрой кастомизации и проигрывания мелодий.
Решено — сотрудничаем! Ну, а мы принялись за реализацию техники.
Формируем ТЗ
После обсуждения того, какие ещё фичи стоит заложить в новый функционал, появилось промежуточное ТЗ:
Основной набор мелодий — это «захардкоженные» последовательности, которые используются для озвучивания событий из жизни самоката, а также служебные события. Здесь всё, как и раньше: меняться такие звуки будут редко, поэтому хранить их имеет смысл прямо в прошивке. Из этого возникают требования к формату хранения мелодий — минимальный размер и быстрое декодирование в рантайме; что-то вроде массива значений частота/длительность/амплитуда, но не привязанный к реализации в «железе». Воспроизводиться эти мелодии должны уметь как при запущенной RTOS, так и без неё.
Динамические мелодии — мы хотели оставить возможность кастомизации озвучки, например, добавляя их по необходимости на SD-карту или передавая на IoT в формате json. Это порождало требование универсального формата хранения и передачи мелодий, с которыми будет удобно работать как на бэкэнде, так и на железке.
Иметь эталонные исходники звуков в каком-то стандартном музыкальном формате и способ их конвертации в формат микроконтроллера. Это дало бы возможность автоматизировать встраивание мелодий в прошивку, запускать CI/CD скрипты конвертации, тестирования и ещё много чего полезного.
Инструментарий для разработки мелодий. Сотрудничество со студией саунд-дизайна принесло задачу обеспечить техническую составляющую процесса создания мелодий; как минимум, модуль IoT, на котором музыкант мог бы оперативно проигрывать звуки. У нас возникала идея сделать тестовую прошивку с USB MIDI device на этапе отладки звукового дизайна, чтобы запускать мелодии прямо из секвенсоров. Но мы отказались от этого: процесс воспроизведения звука будет очень сильно отличаться от его конечного варианта в IoT-модуле, а хотелось тестировать мелодии сразу максимально близко к «боевым» условиям и не заниматься параллельной разработкой.
Тернистый путь из MIDI в баззер
С форматом исходников мелодий всё просто, тут лучше всего подошёл MIDI. Легковесный формат, который несложно хранить и парсить. Можно использовать MIDI на микроконтроллере, но, исходя из рассуждений выше, нужен был формат меньше и проще для декодирования в рантайме, и в качестве такого формата отлично подошла обычная строка. Её удобно передавать по воздуху или через CLI, перекодировав в base64, чтобы не иметь проблем с непечатными символами. Терминал Tera Term, который мы обычно используем для взаимодействия с Shell IoT«а под Windows, поддерживает перетаскивание файла прямо в консоль, что даёт почти готовый способ быстрого воспроизведения мелодий. Таким образом, каждая мелодия может быть в 3-х форматах:
Исходный MIDI
Си-строка для хранения и воспроизведения в прошивке
Cтрока в base64 для передачи на микроконтроллер
Для конвертации MIDI используем Python; общая схема преобразования выглядит так:
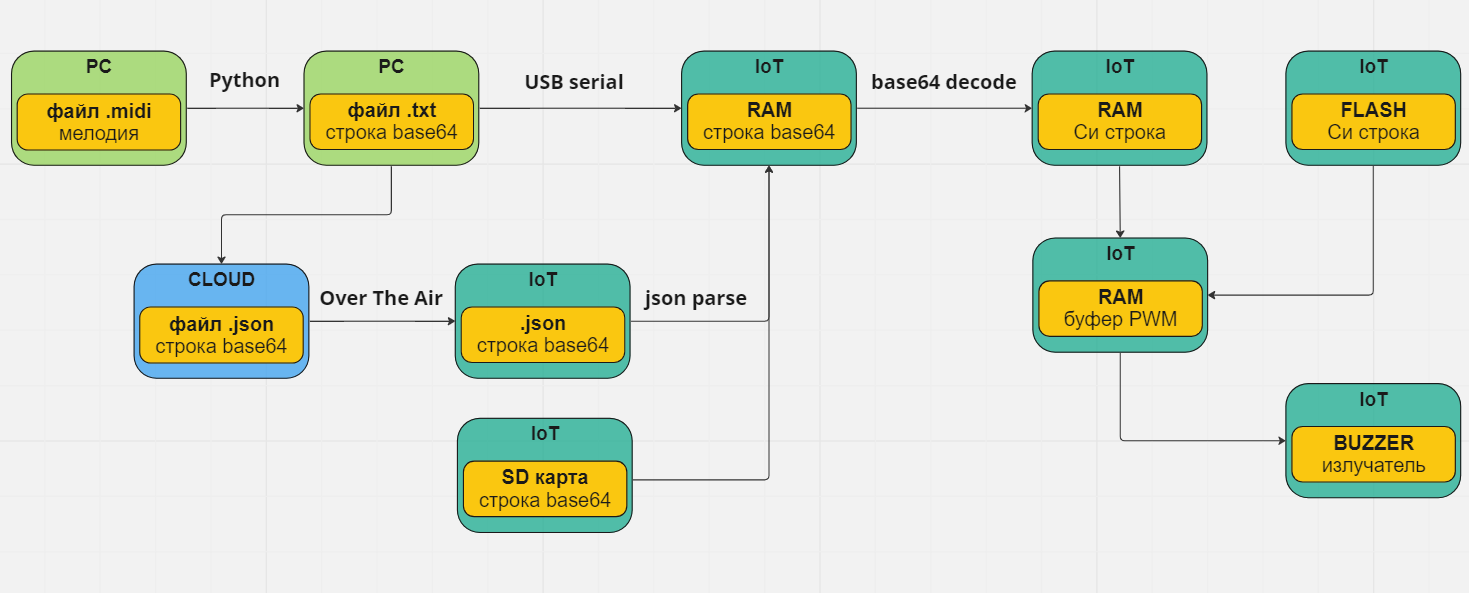
Общая структурная схема
Разбираем MIDI
На первом этапе нужно реализовать разбор MIDI файла, извлечь нужные данные и сформировать выходной массив нот. Раз мы решили, что будем хранить в IoT строку — то постараемся уложиться в минимальное количество байт на каждую ноту, но так, чтобы это всё ещё поддавалось удобному обратному преобразованию в периоды и частоты ШИМ.
Что мы имеем по железу? У нас есть частота выходного ШИМ, длительность его сигнала, а также второй ШИМ, регулирующий размах напряжения пьезоизлучателя. Или, музыкально выражаясь, нота, её длительность и громкость — минимальный набор для обработки MIDI событий. Чтобы звучание мелодий в секвенсоре и на IoT модуле было максимально похожим, ограничимся MIDI файлами с одной дорожкой и отсутствием одновременно звучащих нот. Если ноты в мелодии накладываются, то при конвертации придётся выбирать из них самую приоритетную, а это дополнительная логика и дополнительная возможность несоответствия звучания баззера изначально задуманному.
Не будем приводить полный разбор спецификации формата MIDI, опишем лишь основные события, из которых можно взять данные для конвертации. Используем библиотеку Mido для просмотра событий тестового MIDI файла, запустив такой код:
from mido import MidiFile
sound = MidiFile('test_sound.mid')
print(sound)И посмотрим на вывод в консоли, держа под рукой документацию Mido:
MidiFile(type=1, ticks_per_beat=480, tracks=[
MidiTrack([
MetaMessage('set_tempo', tempo=300000, time=0),
MetaMessage('end_of_track', time=0)]),
MidiTrack([
MetaMessage('track_name', name='Track 0', time=0),
Message('program_change', channel=0, program=25, time=0),
MetaMessage('time_signature', numerator=4, denominator=4, clocks_per_click=24, notated_32nd_notes_per_beat=8, time=0),
Message('note_on', channel=0, note=48, velocity=76, time=0),
MetaMessage('key_signature', key='C', time=0),
Message('control_change', channel=0, control=101, value=0, time=0),
Message('control_change', channel=0, control=100, value=0, time=0),
Message('control_change', channel=0, control=6, value=6, time=0),
Message('note_off', channel=0, note=48, velocity=64, time=480),
Message('note_on', channel=0, note=55, velocity=51, time=0),
Message('note_off', channel=0, note=55, velocity=64, time=240),
Message('note_on', channel=0, note=55, velocity=51, time=0),
Message('note_off', channel=0, note=55, velocity=64, time=240),
Message('note_on', channel=0, note=40, velocity=64, time=0),
Message('note_off', channel=0, note=40, velocity=64, time=240),
Message('note_on', channel=0, note=67, velocity=64, time=0),
Message('note_off', channel=0, note=67, velocity=64, time=240),
Message('note_on', channel=0, note=67, velocity=64, time=0),
Message('note_off', channel=0, note=67, velocity=64, time=240),
Message('note_on', channel=0, note=70, velocity=76, time=0),
Message('note_off', channel=0, note=70, velocity=64, time=240),
MetaMessage('end_of_track', time=0)])
])
Для каждой ноты видны пары событий note_on/note_off, которые обозначают, как можно догадаться, начало и конец воспроизведения ноты, код которой содержится в поле note. MIDI-код ноты может принимать значение от 0 до 127, для его хранения зарезервируем один байт данных в строке. Найти частоту ШИМ на IoT по коду ноты можно по формуле:

где n — MIDI-код ноты, f — частота в Гц. Это достаточно тяжелые вычисления для микроконтроллера, поэтому имеет смысл хранить таблицу частот и брать соответствующее коду ноты значение.
Параметр time — это дельта между событиями в «тиках» MIDI мелодии. Длительность одного «тика» в микросекундах можно посчитать, используя заголовок time_signature, например, вот так, но с целью минимизировать количество данных, не будем использовать абсолютные длительности по времени, а передадим на IoT длительность ноты в музыкальных долях и общий темп мелодии в BPM (Beats Per Minute) — ударах в минуту.
Beat или удар — это одна четвертная доля, тогда для нахождения длительности нот, относительно четвертных, достаточно взять дельту из события note_off и разделить на заголовочный параметр ticks_per_beat:
dur = 1/4 * time / ticks_per_beat
1/4 * 480 / 480 = 1/4'
1/4 * 240 / 480 = 1/8'
...Если у события note_on параметр time не равен 0, это означает, что начало ноты отстоит по времени от предыдущего события (обычно это note_off), что в случае одноголосой мелодии означает паузу соответствующей длительности.
Для расчета BPM нам понадобится параметр tempo из события set_tempo, он определяет количество микросекунд на один удар, четвертную ноту. Для дефолтного темпа 120 BMP это значение было бы 500 000 (60 000 000 микросекунд в минуте, 120 ударов в минуту, 60 000 000 / 120 = 500 000), а для получения наших BMP воспользуемся такой формулой:

Для параметра длительности также зарезервируем отдельный байт для каждой ноты и ограничимся таблицей возможных музыкальных долей, от 2/1 до 1/64, их полуторные доли и триоли. На микроконтроллере заведём таблицу множителей для всех длительностей, значение множителя означает длительность в количестве длительностей 1/64 нот. Длительность 1/64 считаем не в миллисекундах, а сразу в единицах таймера; в примере ниже для изменения длительности ноты использовалось изменение предделителя. Таким образом, чтобы получить длительность каждой ноты, нужно умножить значение предделителя для 1/64 (для темпа 120) на множитель из таблицы, а также умножить на общий коэффициент темпа всей мелодии, рассчитанный, как отношение 120 / BMP. В такой реализации нет поддержки изменения темпа мелодии во время воcпроизведения (хотя формат MIDI это позволяет), для нашей задачи это показалось избыточным.
typedef enum
{
// целые длительности
NOTE_DIV_2_1 = 0,
NOTE_DIV_1_1,
NOTE_DIV_1_2,
NOTE_DIV_1_4,
NOTE_DIV_1_8,
NOTE_DIV_1_16,
NOTE_DIV_1_32,
NOTE_DIV_1_64,
// полуторные ноты (ноты с точкой)
NOTE_DIV_1_1_o,
NOTE_DIV_1_2_o,
NOTE_DIV_1_4_o,
NOTE_DIV_1_8_o,
NOTE_DIV_1_16_o,
NOTE_DIV_1_32_o,
// триоли
NOTE_DIV_1_2_3,
NOTE_DIV_1_4_3,
NOTE_DIV_1_8_3,
NOTE_DIV_1_16_3,
NOTE_DIV_1_32_3,
} NOTE_DIV_t;
static float NotesDivCoefBuff[] =
{
128, 64, 32, 16, 8, 4, 2, 1, // NOTE_DIV_2_1 ... NOTE_DIV_1_64
96, 48, 24, 12, 6, 3, // NOTE_DIV_1_1_o ... NOTE_DIV_1_32_o
21.33, 10.67, 5.33, 2.67, 1.33 // NOTE_DIV_1_2_3 ... NOTE_DIV_1_32_3
};
static float Buzzer_GetNoteDivCoef(NOTE_DIV_t noteDiv)
{
return NotesDivCoefBuff[noteDiv];
}
#define MELODY_DEFAULT_TEMPO 120
// коэффициент для темпа, взятого из заголовка мелодии.
// eсли BMP мелодии 60, то все длительности умножатся на 2
float tempoCoef = (float)MELODY_DEFAULT_TEMPO / MelodyHeaderParams->BMP;
// для каждой ноты считаем коэффициент длительности в 1/64 долях
float noteDurationCoef = tempoCoef * Buzzer_GetNoteDivCoef(NOTE_DIV_1_4);
/* реализация для stm32 с изменением предделителя таймера */
// значение предделителя таймера для длительности 1/64 и темпе 120
#define BUZZER_TIM_PSC_1_64 99
// находим значение предделителя таймера длительности ноты
u16 timDurationPrescaler = ((float)(BUZZER_TIM_PSC_1_64 + 1) * noteDurationCoef) - 1;
LL_TIM_SetPrescaler(BUZZER_DURATION_TIMER, timDurationPrescaler);
Итак, сама нота и её длительность есть, остаётся громкость. В предыдущей статье мы рассказывали, что управляем амплитудой импульсов раскачки баззера при помощи ШИМ; остается понять, откуда взять значение амплитуды. В событиях note_on и note_off есть параметр velocity — динамика или атака инструмента, по спецификации MIDI может иметь значение 0–127 (строго говоря, от 1 до 127, а значение 0 в некоторых источниках описывается как эквивалент note_off). Вообще, спецификация не определяет, как именно интерпретировать параметр velocity, но можно представить его как «энергию», вложенную в звукоизвлечение, а итоговая громкость ноты — это физическое следствие, которое зависит от конкретного инструмента. Например, для пианино, чем резче и быстрее мы нажимаем на клавишу, тем ярче звучит нота, и тем выше её амплитудная громкость. В событиях note_on и note_off значение velocity обозначает, соответственно, скорость нажатия (скорость атаки, attack velocity) и скорость отпускания клавиши (release velocity); attack velocity можно использовать для расчета громкости ноты. Сам стандарт MIDI рекомендует логарифмическую зависимость максимальной амплитуды сигнала от velocity:

Вот пример зависимости RMS от velocity для некоторых синтезаторов (источник):
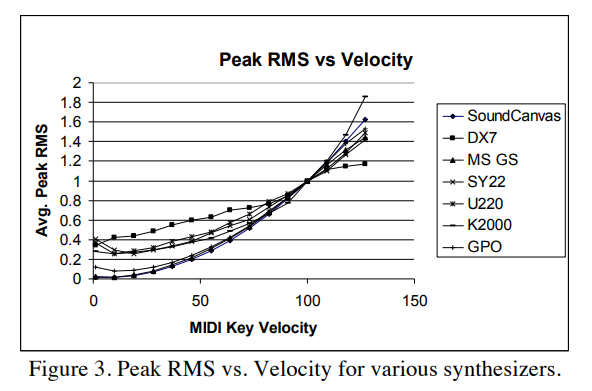
Пример зависимости RMS от velocity
Максимальная амплитуда обозначает максимальное значение, которое достигает огибающая амплитуды сигнала MIDI генератора — обычно амплитуда сначала нарастает, потом достигает максимума и спадает. Форма этой огибающей характеризует инструмент и характер звучания.
Как всё это применить к баззеру? Мы решили начать с простого и на первоначальном этапе не экспериментировать с огибающей, а воспроизводить на баззере каждую ноту подачей импульсов постоянной частоты и амплитуды. С амплитудой напряжения получилось следующее: снятие звука баззера микрофоном показало динамический диапазон около 10–13 dB при изменении напряжения 10–30 Вольт. Разница уровней сигнала на разных частотах доходила до 10 dB, даже с учетом погрешности микрофона. Таким образом, всю вариативность по напряжению перекрывала ужасная АЧХ, и в конце концов, мы оставили линейную зависимость амплитуды напряжения от velocity, приведенную к единицам ШИМ напряжения раскачки баззера.
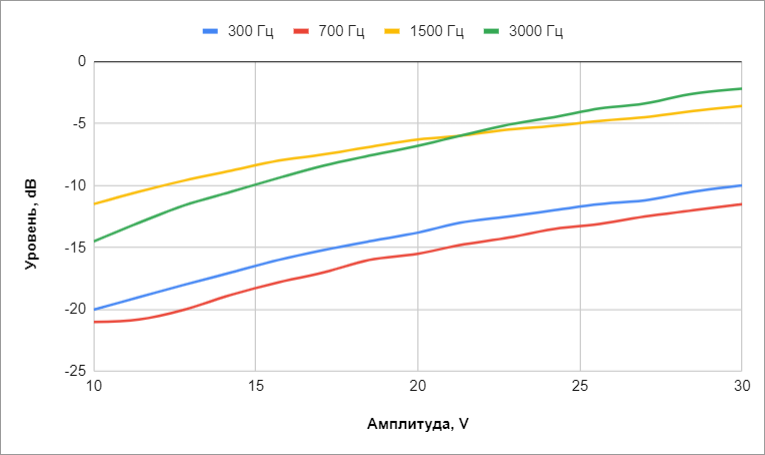
Разница уровней сигнала в зависимости от частоты
Кодирование в строку
Следующий шаг — выбрать формат строки для хранения мелодий. Нам уже известно, какие данные она должна содержать, и из них можно выделить такую структуру: заголовок, в котором будут находиться общие для всей мелодии параметры, такие как темп, или общее количество нот, а также тело строки, содержащее непосредственно массив параметров нот. Получилась такая структура:
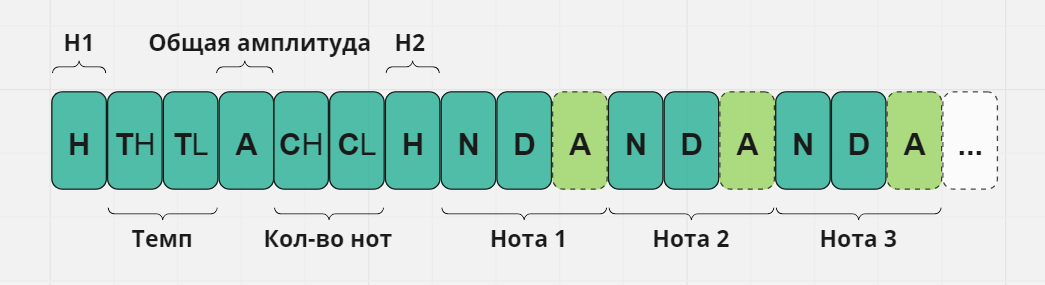
Формат строки, кодирующей мелодию
Строка состоит из символов, ASCII коды которых кодируют нужные нам байты:
H1/H2 — символы-метки начала и конца заголовка
TH/TL — High и Low байты для хранения темпа мелодии
A — Общая амплитуда — это наиболее часто встречающаяся амплитуда среди нот мелодии. Это значение использовано для некоторой оптимизации строки по размеру. Python-скрипт парсинга MIDI файла сначала проходит по всем нотам мелодии, сохраняет их «velocity» в массив и выбирает значение, встречающееся чаще всех, считая его дефолтным. Рассчитанная на его основе амплитуда сохраняется в заголовке как общая амплитуда, а для каждой отдельной ноты амплитуда рассчитывается и записывается отдельным значением только в том случае, если параметр «velocity» этой ноты не равен дефолтному. На многих звуках громкость большинства нот была одинаковой, и такой алгоритм убирал по одному байту из каждой ноты.
CH/CL — High и Low байты общего количества нот мелодии, используется на IoT для дополнительной проверки правильности декодируемой строки: количество нот, считанное из заголовка и декодированное из тела строки, должно совпадать.
N, D, A — два или три символа для каждой ноты, где в символе N кодируется сама нота, в символе D номер её длительности, а опциональный символ A кодирует амплитуду, но присутствует только, если амплитуда ноты не равна дефолтной (как описано выше). Признаком того, что третий символ есть, является значение длительности D, а точнее, его 7-й бит (0b10000000): если значение D меньше 128, то дополнительного символа нет и берём значение D как есть, а если больше, то от значения D отнимаем 128 (0b10000000) и считываем дополнительный символ как значение амплитуды.
После Python писать на Си было уже лень, и мы стали сразу генерировать пару файлов sounds.c/sounds.h для прошивки с массивом структур такого типа:
#define SOUNDS_TABLE()\\
X(SOUND_NO, "Disable sound", "S1 0""\\x94""01S""\\x9c""6")\\
X(SOUND_VERY_FAST_BEEP, "Very fast beep", "S1""\\xa8""X""\\x94""02S""\\x90""5""\\x9c""6")\\
X(SOUND_FAST_BEEP, "Fast beep", "S1""\\x5c""X""\\x94""02S""\\x84""4""\\x9c""5")\\
X(SOUND_MID_BEEP, "Mid beep", "S1""\\x5c""X""\\x94""02Sx3""\\x9c""4")\\
X(SOUND_SLOW_BEEP, "Slow beep", "S1""\\x5c""X""\\x94""02Sl2""\\x9c""3")
#define X(a, b, c) a,
typedef enum
{
SOUNDS_TABLE()
SOUND_ENUM_SIZE
} SOUND_ID_t;
#undef X
#define X(a, b, c) {.Descr = b, .SamplesStr = c},
static Sound_t SoundBuff[] =
{
SOUNDS_TABLE()
};
#undef X
В C/C++ можно записать строку как несколько отдельных строковых констант, которые конкатенируются на этапе компиляции и могут быть разделены пробелами. Непечатные символы в строке можно записать ACSII-кодом после управляющей последовательности \x. Их можно вставлять внутрь символьной строки, но лучше использовать отдельную пару », чтобы избежать проблем интерпретации на разных платформах.»\x21A0» может восприниматься как четырехзначный код символа, если строка кодируется не одним байтом, как в Си. Непечатные символы в строке мелодии, конечно, появлялись, и можно было записать всё в виде »\xXX\xXX», но мы хотели сохранить хоть какую-то читаемость заголовка мелодии в IDE и экспортировали строки, используя способности компилятора собрать в одну строку символы и коды:
char* str1 = "Hello ";
char* str2 = "Wor" "l" "d";
char* str3 = "\\x21\\x21" /* или даже так, компилятор игнорирует комментарий */ "\\x21";
printf("%s%s%s", str1, str2, str3);
> Hello World!!!Синтебаззер
Как было упомянуто выше, IoT воспроизводит каждую ноту с постоянной амплитудой. Стоит сказать, что такая реализация и стала основной, а описанный ниже функционал — тестовый, и в продакшн-версию не вошёл. Было интересно поэкспериментировать с огибающей сигнала и характером звучания. Для этого расширим формат строки, добавив ещё один параметр — назовём его «эффект» — в заголовок мелодии и в каждую ноту. По аналогии с амплитудой, байт эффекта в ноте будет опциональным, то есть добавляться только в том случае, если значение для конкретной ноты отличается от значения в заголовке. Маркером его присутствия будет значение кода ноты N больше 128.
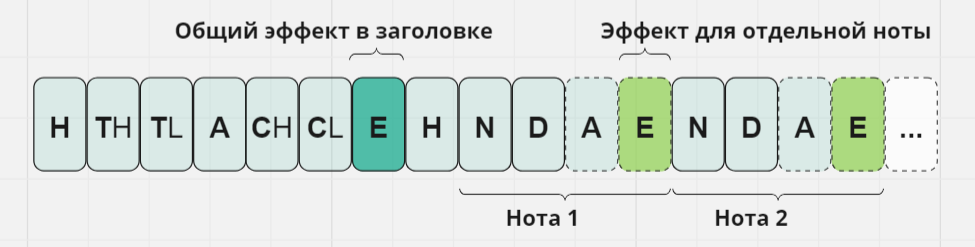
Расширенный формат строки
Не претендуя на какую-либо экспертизу в этой области, мы попробовали реализовать плавную ADSR-огибающую для эмуляции поведения реальных инструментов:
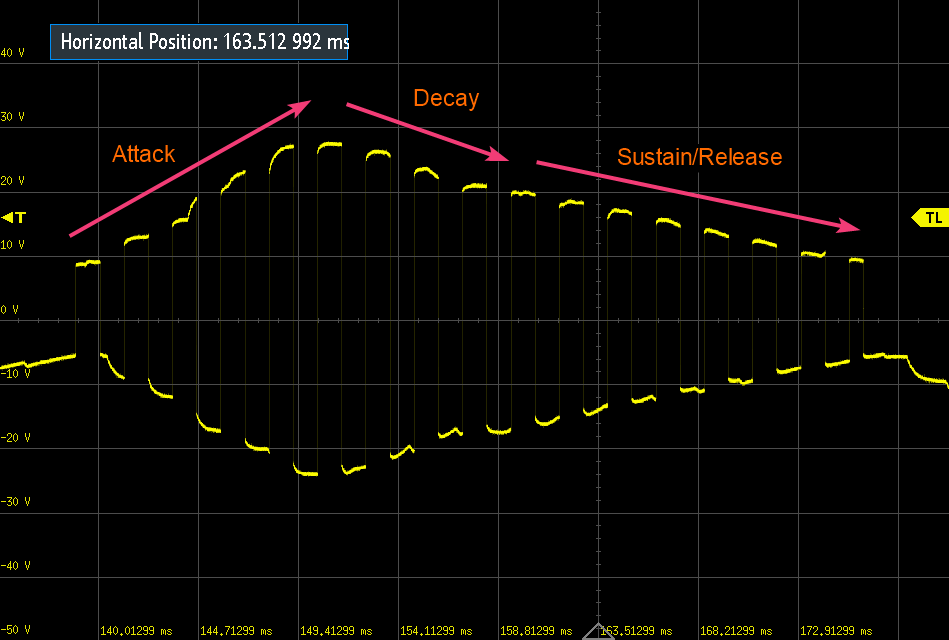
Осциллограмма эксперимента с огибающей
В видео ниже записаны одни и те же мелодии баззера в трёх вариантах — с постоянной амплитудой, с использованием плавной огибающей, и огибающей с эффектом тремоло.
Эпилог
После реализации описанных технических шагов, следующий этап был уже творческий — создание мелодий студией звукового дизайна. Для нас это был отчасти магический черный ящик, из которого появлялись новые варианты озвучки, на каждой итерации мы слушали и высказывали пожелания, дорабатывали прошивку. В результате появился тот набор звуков, который вы можете слышать на IoT модулях наших самокатов. На видео ниже записаны несколько мелодий самоката, сначала исходная MIDI-версия, воспроизведённая в секвенсоре инструментом Electric Piano, а после эта же мелодия, как её видит IoT — воспроизведённая после всех конвертаций и записанная микрофоном непосредственно с баззера:
Подводя итоги, можно сказать, что текущая реализация нравится нам своей простотой и надежностью, а также тем, что удалось решить конкретную техническую задачу — озвучить флот из 60 тысяч самокатов с существующей схемотехникой. Не будучи специалистами в области аудио, мы пробовали разные подходы, от попыток улучшить что-то своими силами до частичного делегирования этой задачи профессионалам. Итоговый результат получился как раз на стыке этих подходов, понадобились как доработки с нашей стороны, так и привлечение специалистов творческих профессий.

С уверенностью можем сказать — для нас это был классный опыт, которым хотелось поделиться с уважаемыми читателями! Мы получали ценные знания, выстраивали процессы взаимодействия со студиями звукового дизайна, меняли внутренние подходы к разработке. Всё это позволило решить интересную многогранную задачу, а также заложило основу для дальнейшего развития, например, применение полноценного динамика в IoT-модуле. Вероятно, что-то можно было сделать лучше, или применить другие технические решения, но мы считаем, что у нас получилось главное — вдохнуть новую волну в звучание наших самокатов!
