Основы движков JavaScript: общие формы и Inline кэширование. Часть 1
Привет, друзья. В конце апреля мы запускаем новый курс «Безопасность информационных систем». И уже сейчас хотим поделиться с вами переводом статьи, которая непременно будет очень полезной для курса.
В статье описаны ключевые основы, они являются общими для всех движков JavaScript, а не только для V8, над которым работают авторы движка (Бенедикт и Матиас). Как JavaScript разработчик могу сказать, что более глубокое понимание того, как работает движок JavaScript поможет разобраться в том, как писать эффективный код.

Внимание: если вам больше нравится смотреть презентации, чем читать статьи, тогда посмотрите это видео. Если же нет, тогда пропустите его и читайте дальше.
Пайплайн (pipeline) движка JavaScript
Все начинается с того, что вы пишете код на JavaScript. После этого движок JavaScript обрабатывает исходный код и представляет его в виде абстрактного синтаксического дерева (АСТ). Основываясь на построенном АСТ, интерпретатор может наконец-то заняться работой и начать генерировать байткод. Отлично! Именно этот момент движок выполняет JavaScript код.

Чтобы он исполнялся быстрее можно отправить байткод в оптимизирующий компилятор вместе с данными профилирования (profiling data). Оптимизирующий компилятор делает определенные предположения на основе данных профилирования, затем он генерирует высокооптимизированный машинный код.
Если в какой-то момент предположения оказываются неверными, оптимизирующий компилятор деоптимизирует код и возвращается на этап интерпретатора.
Пайплайны интерпретатора/компилятор в движках JavaScript
А теперь давайте поближе посмотрим на части пайплайна, которые выполняют ваш код на JavaScript, а именно туда, где код интерпретируется и оптимизируется, а также рассмотрим несколько различий между основными движками JavaScript.
В основе всего лежит пайплайн, который содержит интерпретатор и оптимизирующий компилятор. Интерпретатор быстро генерирует неоптимизированный байткод, оптимизирующий компилятор в свою очередь работает дольше, однако на выходе имеет высокооптимизированный машинный код.
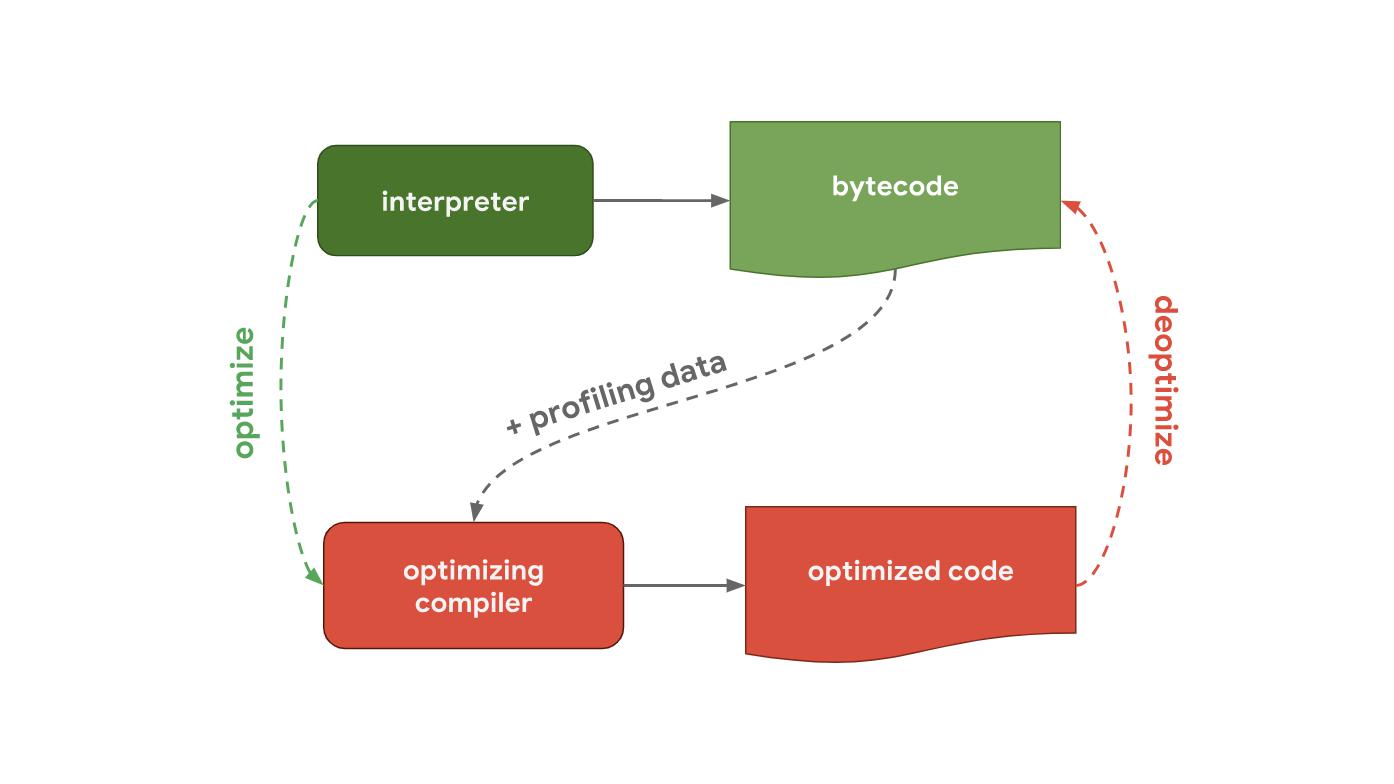
Дальше показан пайплайн, который показывает, как именно работает V8, движок JavaScript, который используется Chrome и Node.js.

Интерпретатор в V8 называется Зажиганием (Ignition), он отвечает за генерацию и выполнение байткода. Он собирает данные профилирования, которые могут быть использованы для ускорения выполнение на следующем этапе, пока обрабатывается байткод. Когда функция становится горячей, например, если она запускается часто, сгенерированный байткод и данные профилирования передаются в Турбовентилятор (TurboFan), то есть в оптимизирующий компилятор для генерации высокооптимизированного машинного кода, основанного на данных профилирования.

Например, JavaScript движок SpiderMonkey от Mozilla, который используется в Firefox и SpiderNode, работает немного иначе. В нем не один, а два оптимизирующих компилятора. Интерпретатор оптимизируется в базовый компилятор (Baseline compiler), который производит в какой-то мере оптимизированный код. Вместе с данными профилирования, собранными во время исполнения кода, компилятор IonMonkey может генерировать сильнооптимизированный код (heavily-optimized code). Если спекулятивная оптимизация не удается, IonMonkey возвращается к базовому коду (Baseline code).

Chakra — JavaScript движок от Microsoft, используется в Edge и Node-ChakraCore, имеет очень похожу структуру и использует два оптимизирующих компилятора. Интерпретатор оптимизируется в SimpleJIT (где JIT означает «Just-In-Time compiler», который производит в какой-то мере оптимизированный код. Вместе с профилирующими данными FullJIT может создавать еще более сильнооптимизированный код.
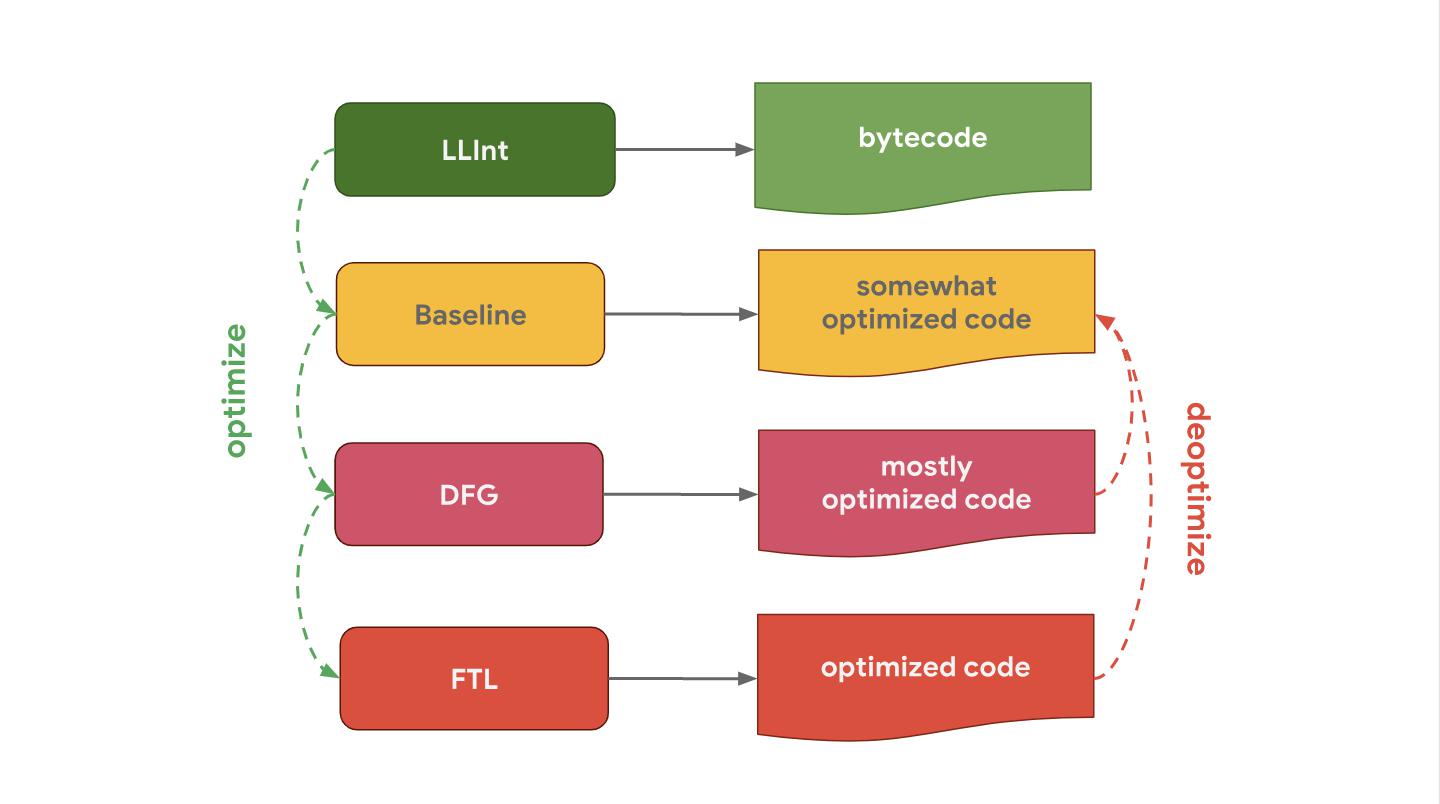
JavaScriptCore (сокращенно JSC), JavaScript движок от Apple, который используется в Safari и React Native, вообще имеет три разных оптимизирующих компилятора. LLInt — низкоуровневый интерпретатор, оптимизируется в базовый компилятор, который в свою очередь оптимизируется в DFG (Data Flow Graph) компилятор, а он уже оптимизируется в FTL (Faster Than Light) компилятор.
Почему некоторые движки имеют больше оптимизирующих компиляторов, чем другие? Здесь все дело в компромиссах. Интерпретатор может быстро обрабатывать байткод, но сам по себе байткод не особо эффективен. Оптимизирующий компилятор, с другой стороны, работает немного дольше, но производит более эффективный машинный код. Это компромисс между быстрым получением кода (интерпретатор) или же некоторым ожиданием и запуском кода с максимальной производительностью (оптимизирующий компилятор). Некоторые движки выбирают добавление нескольких оптимизирующих компиляторов с разными характеристиками времени и эффективности, что позволяет обеспечивать наилучший контроль над этим компромиссным решением и понимать стоимость дополнительного усложнения внутреннего устройства. Другой компромисс относится к использованию памяти, загляните в эту статью, чтобы получше в этом разобраться.
Только что мы рассмотрели основные различия между пайплайнами интерпретаторов и оптимизирующих компиляторов для различных движков JavaScript. Несмотря на эти различия на высоком уровне все движки JavaScript имеют одну и ту же архитектуру: они все имеют парсер и какой-либо пайплайн интерпретатора/компилятора.
Объектная модель JavaScript
Давайте посмотрим, чего еще общего есть в движках JavaScript и какие приемы они используют для ускорения доступа к свойствам объектов JavaScript? Оказывается, все основные движки делают это похожим образом.
Спецификация ECMAScript определяет все объекты как словари с сопоставлением строковых ключей атрибутам свойств.

Помимо самого [[Value]], спецификация определяет следующие свойства:
[[Writable]]определяет, может ли свойство быть переназначено;[[Enumerable]]определяет, отображается ли свойство в циклах for-in;[[Configurable]]определяет, может ли свойство быть удалено.
Нотация [[двойные квадратные скобки]] выглядит странно, однако именно так спецификация описывает свойства в JavaScript. Вы все еще можете получить эти атрибуты свойств для любого заданного объекта и свойства в JavaScript с помощью Object.getOwnPropertyDescriptor API:
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// → { value: 42, writable: true, enumerable: true, configurable: true }
Хорошо, так JavaScript определяет объекты. А что насчет массивов?
Вы можете представить для себя массивы, как особенные объекты. Единственное отличие заключается в том, что массивы имеют специальную обработку индексов. Здесь индекс массива является специальным термином в спецификации ECMAScript. В JavaScript есть ограничения по количеству элементов в массиве — до 2³²−1. Индекс массива — это любой доступный индекс из этого диапазона, то есть любое целочисленное значение от 0 до 2³²−2.
Еще одно отличие заключается в том, что массивы имеют волшебное свойство length.
const array = ['a', 'b'];
array.length; // → 2
array[2] = 'c';
array.length; // → 3
В данном примере массив имеет длину 2 в момент создания. Затем мы присваиваем другой элемент индексу 2 и длина автоматически увеличивается.
JavaScript определяет массивы также, как объекты. Например, все ключи, включая индексы массива, представлены явно в виде строк. Первый элемент массива хранится под ключом »0».

Свойство length — это просто другое свойство, которое оказывается не перечисляемым (non-enumerable) и не настраиваемым (non-configurable).
Как только элемент добавляется к массиву, JavaScript автоматически обновляет атрибут свойства [[Value]] свойства length.

В целом можно сказать, что массивы ведут себя схоже с объектами.
Оптимизация доступа к свойствам
Теперь, когда мы знаем как объекты определяются в JavaScript, давайте взглянем на то, как движки JavaScript позволяют работать с объектами эффективно.
В обыденной жизни доступ к свойствам является наиболее распространенной операцией. Для движка крайне важно делать это быстро.
const object = {
foo: 'bar',
baz: 'qux',
};
// Here, we’re accessing the property `foo` on `object`:
doSomething(object.foo);
// ^^^^^^^^^^
Формы
В программах на JavaScript, достаточно общей практикой является назначение многим объектам одинаковых ключей свойств. Говорят, что такие объекты имеют одинаковую форму (shape).
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape.
Также обычной механикой является доступ к свойству объектов одной формы:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);
Зная это, движки JavaScript могут оптимизировать доступ к свойству объекта, основываясь на его форме. Смотрите как это работает.
Допустим, у нас есть объект со свойствами x и y, он использует структуру данных словарь, о который мы говорили ранее; она содержит строки-ключи, которые указывают на их соответствующие атрибуты.
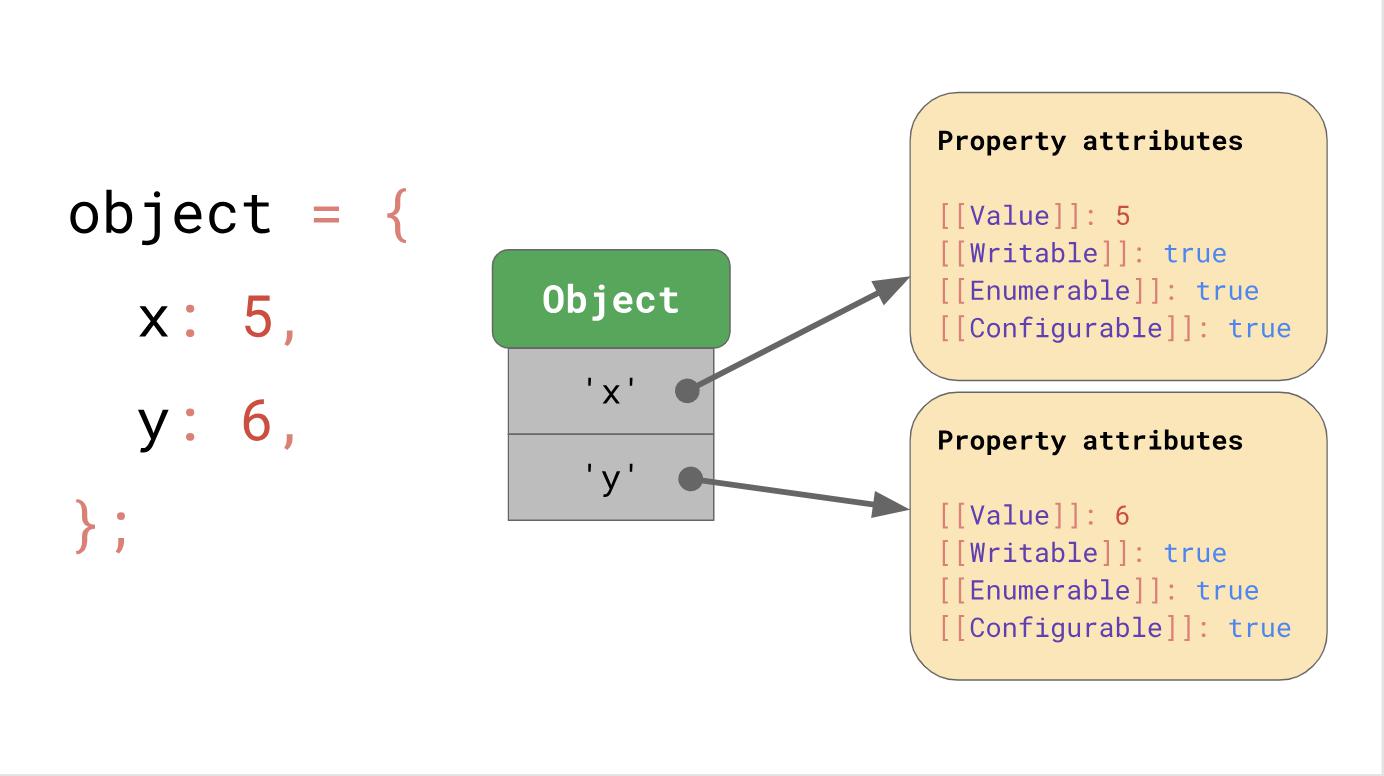
Если вы обращаетесь к свойству, например object.y, движок JavaScript ищет JSObject по ключу ‘y’, затем загружает отвечающие этому запросу атрибуты свойства и наконец возвращает [[Value]].
Но где эти атрибуты свойств хранятся в памяти? Должны ли мы хранить их как часть JSObject? Если мы сделаем так, то будем видеть больше объектов такой формы позже, в таком случае, пустая трата пространства — хранить полный словарь, содержащий имена свойств и атрибутов в самом JSObject, поскольку имена свойств повторяются для всех объектов одной формы. Это вызывает много дублирования и приводит к нерациональному использованию памяти. Для оптимизации движки хранят форму объекта отдельно.

Эта форма (Shape) содержит все имена свойств и атрибуты, кроме [[Value]]. Вместо этого форма содержит смещение (offset) значений внутри JSObject, таким образом движок JavaScript знает, где искать значения. Каждый JSObject с общей формой указывает на конкретный экземпляр формы. Теперь каждому JSObject приходится хранить только уникальные для объекта значения.
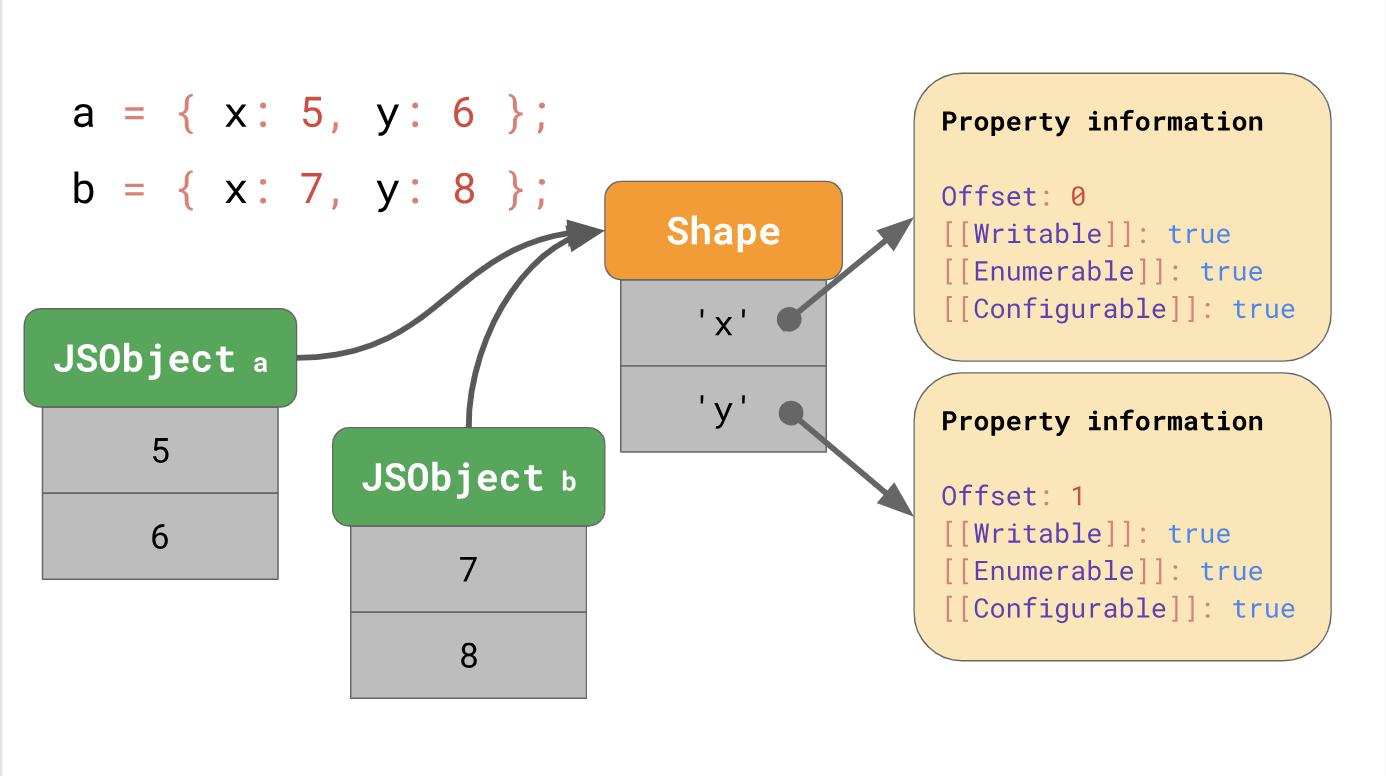
Преимущество становится очевидным, как только у нас появляется много объектов. Их количество не имеет значения, поскольку если они имеют одну форму, мы сохраняем информацию о форме и свойстве всего один раз.
Все движки JavaScript используют формы, в качестве средства оптимизации, но они не называют их непосредственно формами (shapes):
- Документация Academic называет их Hidden Classes (по аналогии с классами в JavaScript);
- V8 называет их Maps;
- Chakra называет их Types;
- JavaScriptCore называет их Structures;
- SpiderMonkey называет их Shapes.
В этой статье мы продолжим называть их формами (shapes).
Переходные цепи и деревья
Что происходит, если у вас есть объект определенной формы, но вы добавляете ему новое свойство? Как движок JavaScript определяет новую форму?
const object = {};
object.x = 5;
object.y = 6;
Формы создают так называемые переходные цепи (transition chains) в движке JavaScript. Вот пример:
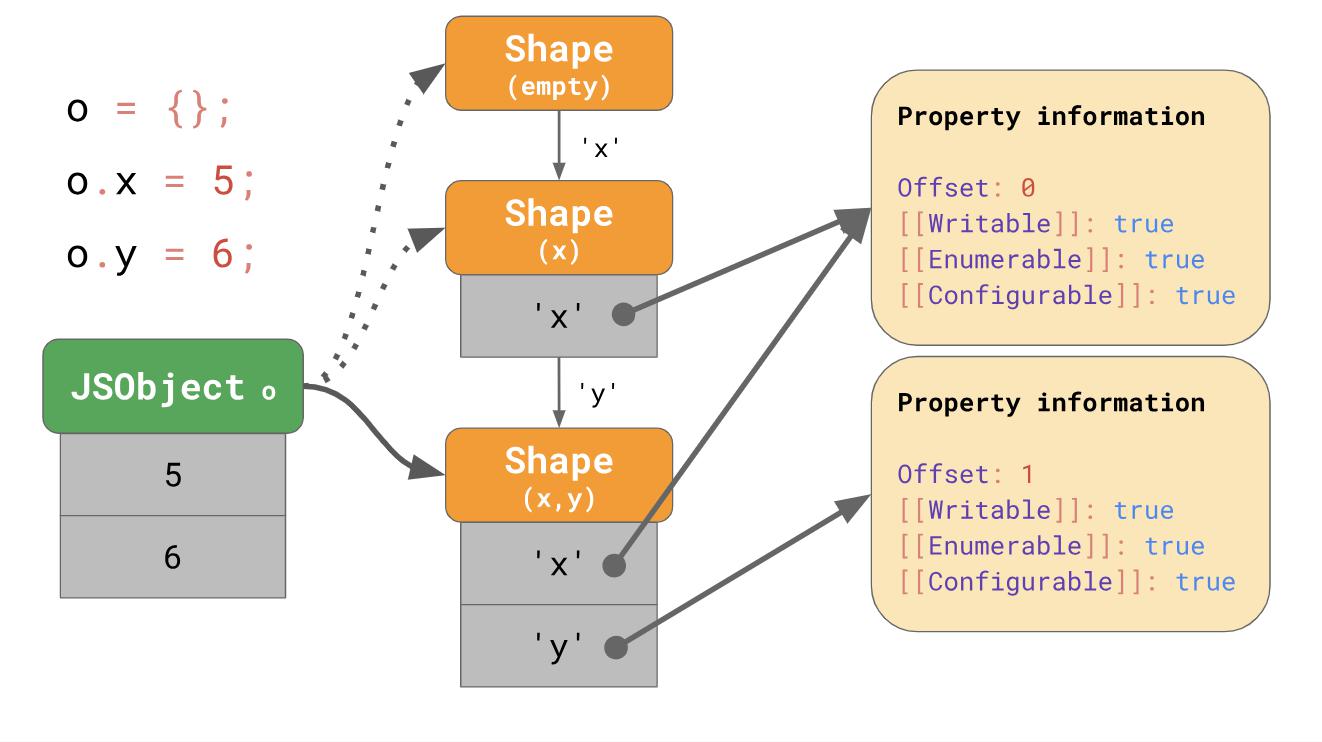
Объект изначально не имеет никаких свойств, он соотносится с пустой формой. Следующее выражение добавляет свойство ‘x’ со значением 5 к этому объекту, тогда движок переходит к форме, которая содержит свойство ‘x’ и значение 5 добавляется в JSObject при первом смещении 0. Следующая строчка добавляет свойство ‘y’, тогда движок переходит к следующей форме, которая уже содержит и ‘x’ и ‘y’, а также добавляет значение 6 к JSObject на смещение 1.
Внимание: Последовательность, в которой добавляются свойства влияет на форму. Например, { x: 4, y: 5 } приведет к иной форме, чем { y: 5, x: 4 }.
Нам даже не нужно хранить всю таблицу свойств для каждой формы. Вместо этого каждой форме нужно знать только новое свойство, которое пытаются в нее включить. Например, в таком случае нам не нужно хранить информацию об «x» в последней форме, поскольку она может быть найдена раньше в цепи. Чтобы это работало, форма соединяется со своей предыдущей формой.
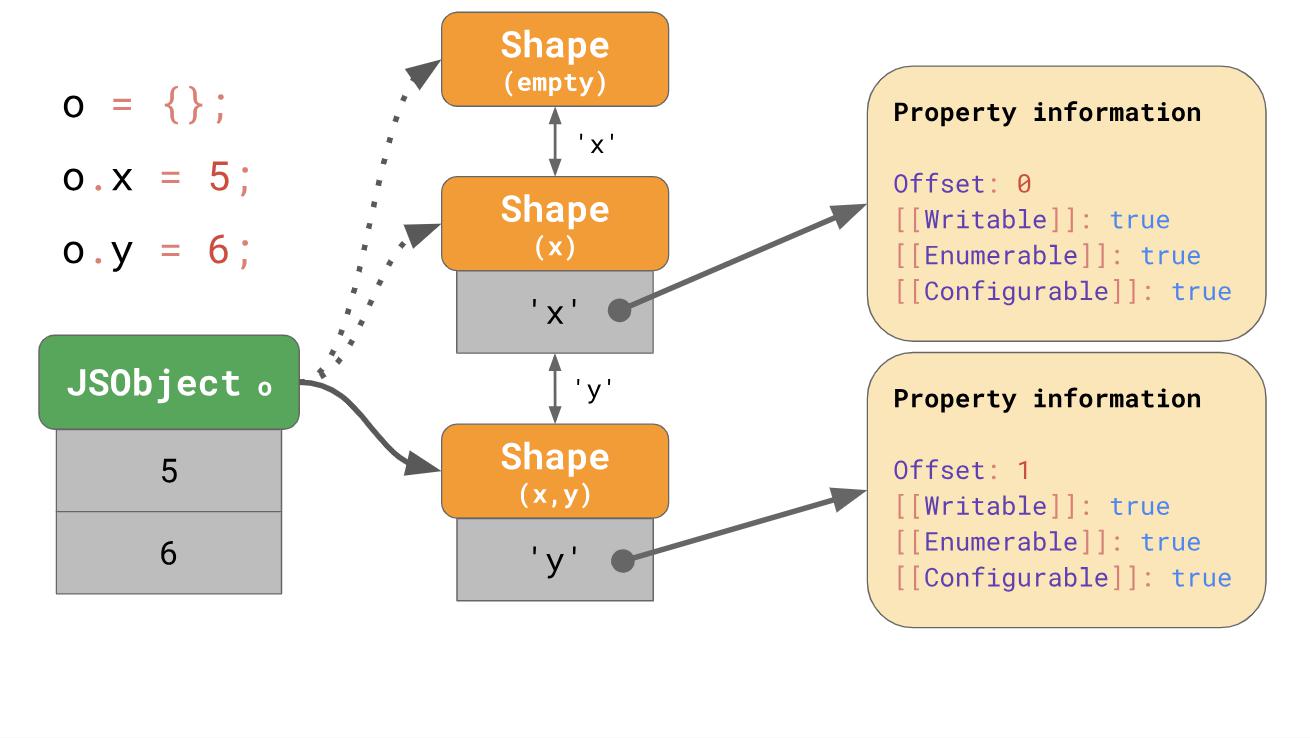
Если вы напишете o.x в своем коде на JavaScript, JavaScript будет искать свойство ‘x’ по цепи перехода, до того момента, как обнаружит форму, которая уже имеет в себе свойство ‘x’.
Но что происходит, если невозможно создать переходную цепь? Например, что происходит, если у вас есть два пустых объекта и вы добавляете им разные свойства?
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;
В этом случае у нас появляется ветка, и вместо цепи перехода мы получаем дерево перехода:
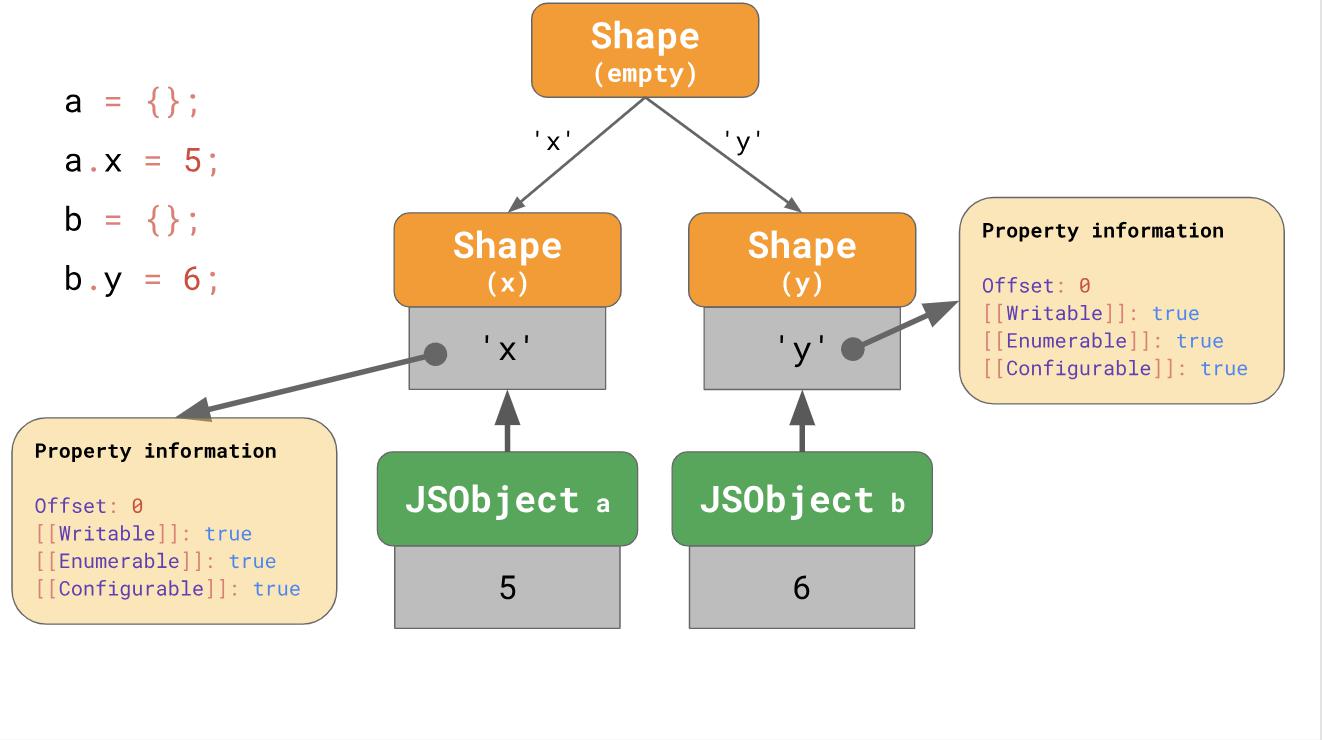
Мы создаем пустой объект a и добавляем ему свойство ‘x’. В итоге у нас есть JSObject, содержащий единственное значение и две формы: пустую и форму с единственным свойством ‘x’.
Второй пример начинается с того, что мы имеем пустой объект b, но затем добавляем другое свойство ‘y’. В итоге здесь у нас получается две цепи форм, а в итоге выходит три цепи.
Значит ли это, что мы всегда начинаем с пустой формы? Не обязательно. Движки применяют некоторую оптимизацию литералов объектов (object literal), которые уже содержат свойства. Скажем, что мы добавляем x, начиная с пустого литерала объекта, или имеем литерал объекта, который уже содержит x:
const object1 = {};
object1.x = 5;
const object2 = { x: 6 };
В первом примере мы начинаем с пустой формы и перехода к цепи, который также содержит x, также как мы наблюдали ранее.
В случае с object2 имеет смысл непосредственно создавать объекты, которые уже имеют х с самого начала, а не начинать с пустого объекта и перехода.
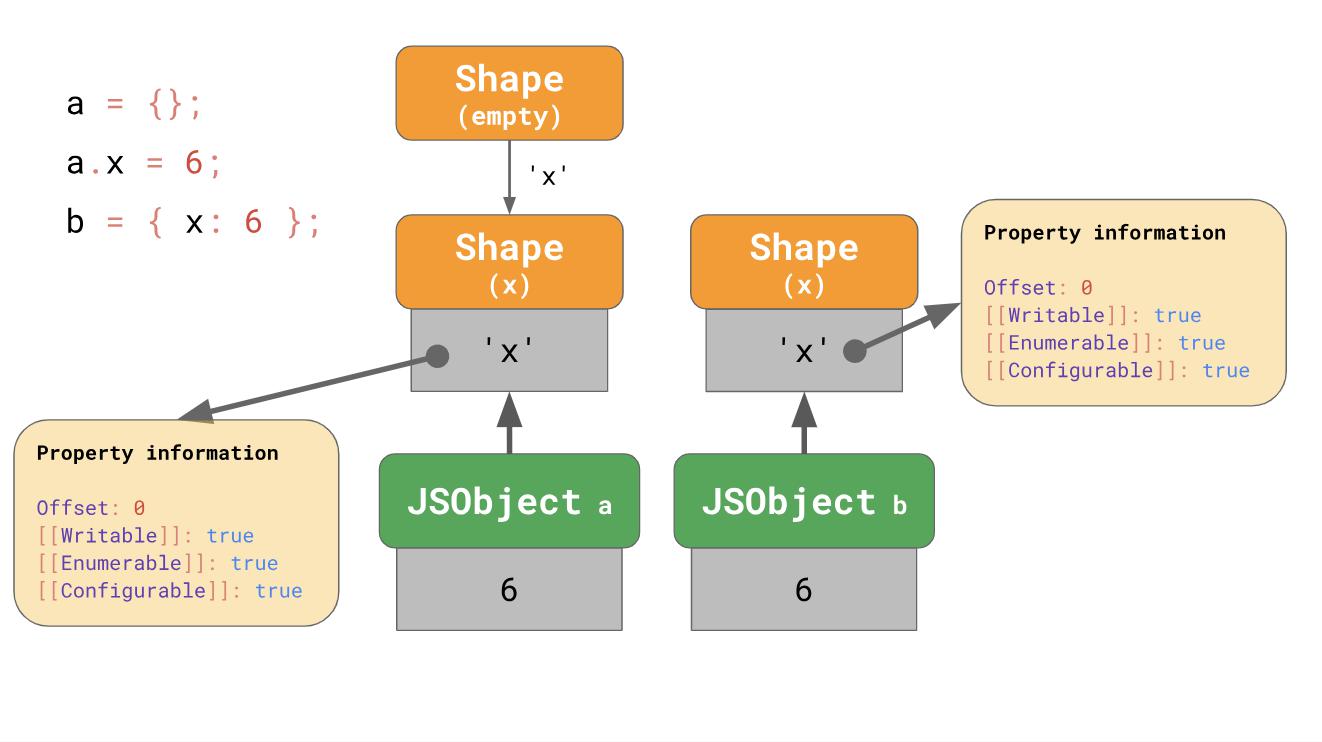
Литерал объекта, который содержит свойство ‘x’ начинается с формы, содержащей ‘x’ с самого начала при этом эффективно пропускается пустая форма. Это то (как минимум), что делают V8 и SpiderMonkey. Оптимизация укорачивает цепи перехода и делает более удобной сборку объектов из литералов.
Пост в блоге Бенедикта об удивительном полиморфизме приложений на React рассказывает о том, как такие тонкости могут повлиять на производительность.
Дальше вы увидите пример точек трехмерного объекта со свойствами ‘x’, ‘y’, ‘z’.
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
Как вы поняли ранее, мы создаем в памяти объект с тремя формами (не считая пустую форму). Чтобы получить доступ к свойству ‘x’ этого объекта, например если вы пишете point.x в своей программе, движок JavaScript должен последовать по связанному списку: начиная с формы в самом низу, а затем постепенно шагая вверх до формы, которая имеет ‘x’ в самом верху.
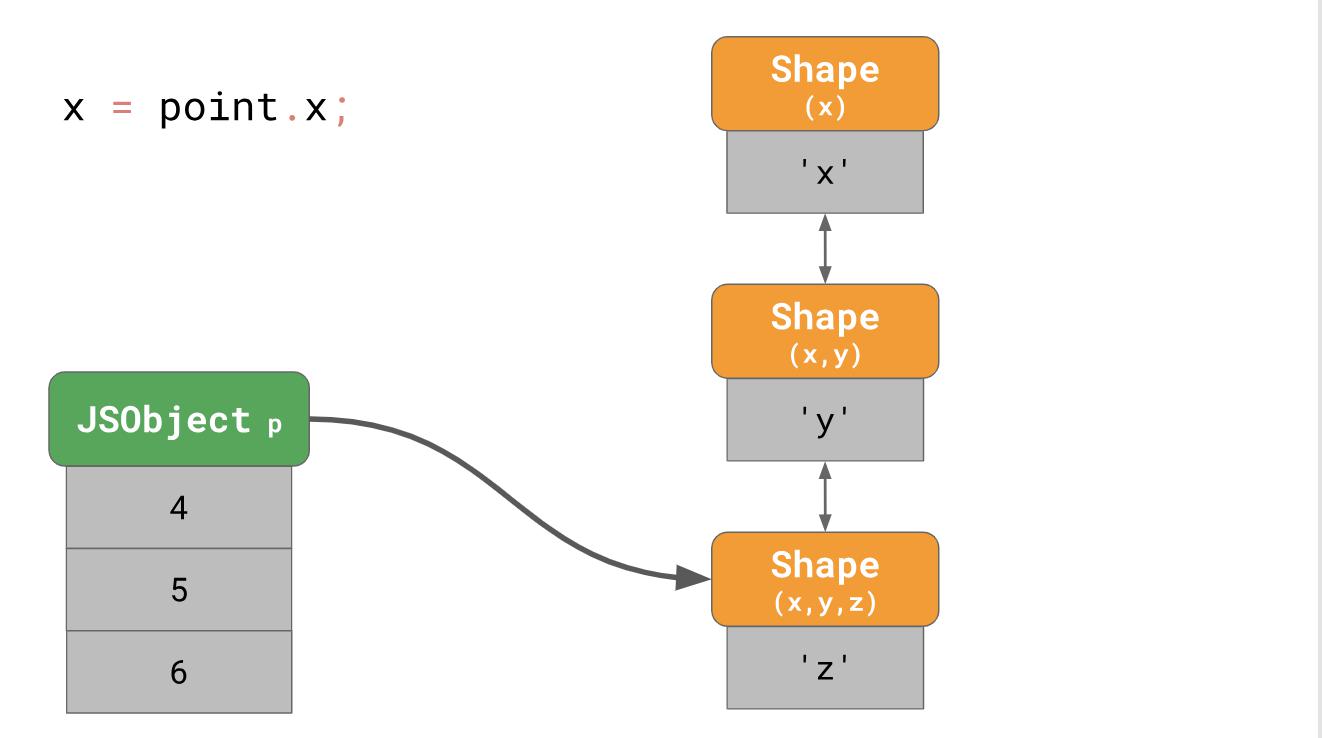
Получается очень медленно, особенно если делать это часто и с большим количеством свойств у объекта. Время нахождения свойства равно O(n), т. е. это линейная функция, которая коррелирует с количеством свойств объекта. Чтобы ускорить поиск по свойствам, движки JavaScript добавляют структуру данных ShapeTable. ShapeTable представляет из себя словарь, где ключи сопоставляются определенным образом с формами и выдают искомое свойство.
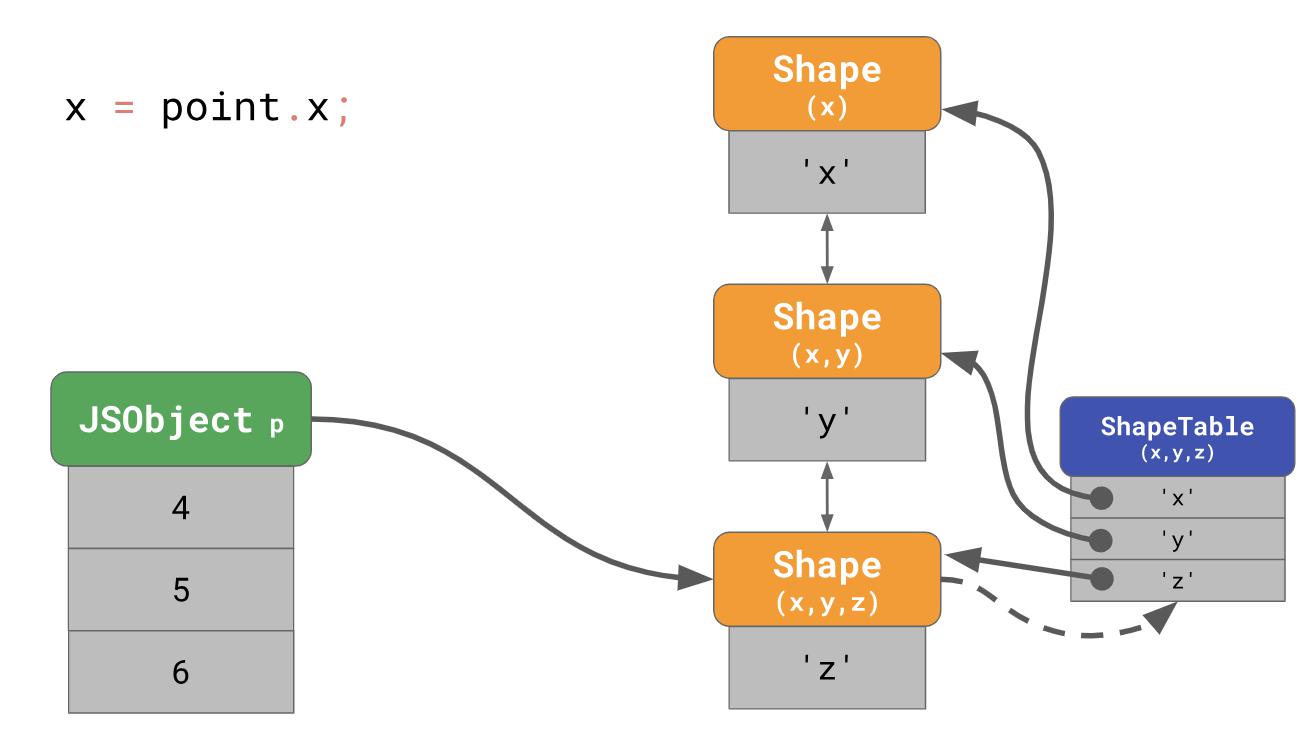
Подождите секундочку, теперь мы возвращаемся к поиску по словарю… Это именно то, с чего мы начинали, когда ставили формы на первое место! Так почему мы вообще беспокоимся о формах?
Дело в том, что формы способствуют другой оптимизации, которая называется Inline кэши (Inline Caches).
О концепции inline кэшей или ICs поговорим во второй части статьи, а сейчас хотим пригласить вас на бесплатный бесплатный открытый вебинар, который уже 9 апреля проведет известный вирусный аналитик и по совместительству наш преподаватель — Александр Колесников
