Наш опыт создания API Gateway
Некоторые компании, в том числе наш заказчик, развивают продукт через партнерскую сеть. Например, крупные интернет-магазины интегрированы со службой доставки — вы заказываете товар и вскоре получаете трекинговый номер посылки. Другой пример — вместе с авиабилетом вы покупаете страховку или билет на аэроэкспресс.
Для этого используется один API, который нужно выдать партнерам через API Gateway. Эту задачу мы и решили. В этой статье расскажем подробности.
Дано: экосистема и API-портал с интерфейсом, где пользователи зарегистрированы, получают информацию и т.п. Нам нужно сделать удобный и надежный API Gateway. В процессе нам нужно было обеспечить
- регистрацию,
- контроль подключения к API,
- мониторинг того, как пользователи используют конечную систему,
- учёт бизнес-показателей.
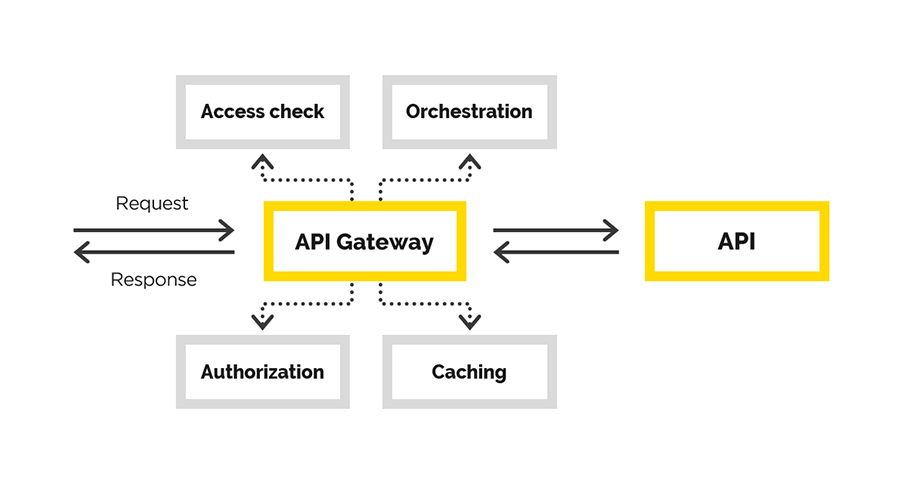
В статье мы расскажем о нашем опыте создания API Gateway, в ходе которого мы решали следующие задачи:
- аутентификация пользователя,
- авторизация пользователя,
- модификация исходного запроса,
- проксирование запроса,
- постобработка ответа.
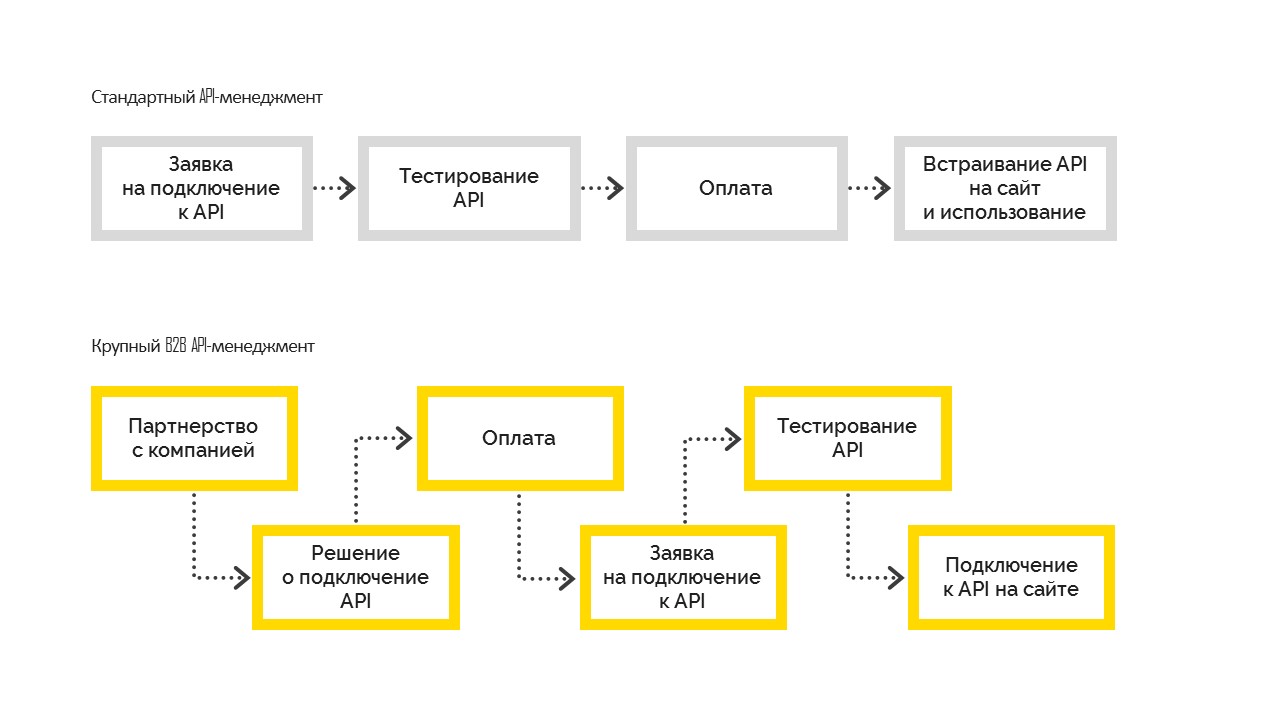
Есть два вида API-менеджмента:
1. Стандартный, который работает следующим образом. Перед подключением пользователь тестирует возможности, затем оплачивает и встраивает на свой сайт. Чаще всего им пользуются в малом и среднем бизнесе.
2. Крупный B2B API Management, когда компания сначала принимает бизнес-решение о подключении, становится партнером компании с контрактным обязательством, после чего подключается к API. И уже после улаживания всех формальностей компания получает тестовый доступ, проходит тестирование и выходит в прод. Но это невозможно без управленческого решения о подключении.
Наше решение
В этой части расскажем о создании API Gateway.
Конечные пользователи создаваемого шлюза к API — партнёры нашего заказчика. Для каждого из них у нас уже хранятся необходимые контракты. Нам нужно будет лишь расширить функциональность, отмечая предоставленный доступ к шлюзу. Соответственно, нужен контролируемый процесс подключения и управления.
Безусловно, можно было взять какое-нибудь готовое решение для решения задачи API Management и создания API Gateway в частности. Например, таким могло быть Azure API Management. Нам оно не подошло, потому что в нашем случае у нас уже был API-портал и огромная экосистема, построенная вокруг него. Все пользователи уже были зарегистрированы, они уже понимали, где и как они могут получить нужную информацию. В API-портале уже существовали нужные интерфейсы, нам лишь был необходим API Gateway. Собственно, его разработкой мы и занялись.
То, что мы называем API Gateway — своего рода прокси. Тут у нас опять был выбор — можно написать свой прокси, а можно выбрать уже что-то готовое. В этом случае мы пошли вторым путём и выбрали связку nginx+Lua. Почему? Нам необходим был надежный, протестированный software, поддерживающий масштабирование. Мы не хотели после реализации проверять и корректность бизнес-логики, и корректность работы прокси.
У любого веб-сервера есть конвейер обработки запроса. В случае nginx он выглядит следующим образом:

(схема из GitHub Lua Nginx)
Нашей целью было встроиться в этот конвейер в тот момент, где мы можем модифицировать исходный запрос.
Мы хотим создать transparent proxy, чтобы функционально запрос оставался таким, каким и пришёл. Мы лишь контролируем доступ к конечному API, помогаем запросу добраться до него. В случае, если запрос был некорректным, ошибку должен показать конечный API, но не мы. Единственная причина, почему мы можем отклонить запрос — из-за отсутствия доступа у клиента.
Для nginx уже существует расширение на Lua. Lua — скриптовый язык, он очень легковесный и лёгкий в освоении. Таким образом, необходимую логику мы реализовали с помощью Lua.
Конфигурация nginx«a (аналогия route приложения), где и выполняется вся работа, вполне понятная. Примечательна здесь последняя директива — post_action.
location /middleware {
more_clear_input_headers Accept-Encoding;
lua_need_request_body on;
rewrite_by_lua_file 'middleware/rewrite.lua';
access_by_lua_file 'middleware/access.lua';
proxy_pass https://someurl.com;
body_filter_by_lua_file 'middleware/body_filter.lua';
post_action /process_session;
}
Рассмотрим, что происходит в этой конфигурации:
more_clear_input_headers — очищает значение указанных после директивы хэдеров.
lua_need_request_body — регулирует, следует ли прочитать исходное тело запроса перед тем, как выполнять директивы rewrite/access/access_by_lua или нет. По умолчанию nginx не читает тело запроса клиента, и если вам необходимо получить к нему доступ, то данная директива должна иметь значение on.
rewrite_by_lua_file — путь до скрипты, в котором описана логика для модификации запроса
access_by_lua_file — путь до скрипта, в котором описана логика, проверяющая наличие доступа к ресурсу.
proxy_pass — url, на который будет проксироваться запрос.
body_filter_by_lua_file — путь до скрипта, в котором описана логика для фильтрации запроса перед возвращением клиенту.
И, наконец, post_action — официально недокументированная директива, с помощью которой можно выполнять ещё какие-либо действия после того, как ответ отдан клиенту.
Далее расскажем по порядку, как мы решали свои задачи.
Авторизация/аутентификация и модификация запроса
Авторизация
Авторизацию и аутентификацию мы построили с помощью доступов по сертификату. Есть корневой сертификат. Каждому новому клиенту заказчика генерируется его личный сертификат, с которым он может получить доступ к API. Этот сертификат настраивается в секции server настроек nginx.
ssl on;
ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem;
ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem;
ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt;
ssl_verify_client on;
Модификация
Может возникнуть справедливый вопрос: что делать с сертифицированным клиентом, если мы внезапно захотели отключить его от системы? Не перевыпускать же сертификаты для всех остальных клиентов.
Так мы плавно и подошли к следующей задаче — модификация исходного запроса. Исходный запрос клиента, вообще говоря, не является валидным для конечной системы. Одна из задач состоит в том, чтобы дописать в запрос недостающие части, чтобы сделать его валидным. Соль в том, что недостающие данные — разные для каждого клиента. Мы знаем, что клиент приходит к нам с сертификатом, с которого мы можем взять отпечаток и вытянуть из базы необходимые данные клиента.
Если в какой-то момент потребуется отключить клиента от нашего сервиса, его данные пропадут из базы и он ничего не сможет делать.
Работа с данными клиента
Нам нужно было обеспечить высокую доступность решения, особенно того, как мы получаем данные клиента. Сложность в том, что первоисточник этих данных — сторонний сервис, который не гарантирует бесперебойную и достаточно высокую скорость работы.
Поэтому нам нужно было обеспечить высокую доступность данных клиентов. В качестве инструмента мы выбрали Hazelcast, который предоставляет нам:
- быстрый доступ к данным,
- возможность организовать кластер из нескольких нод с реплицированными на разных нодах данными.
Мы пошли по самой простой стратегии доставки данных в кэш:
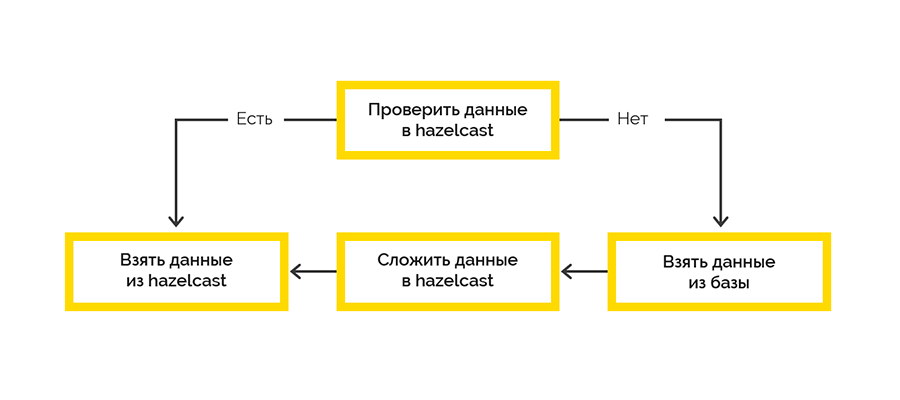
Работа с конечной системой происходит в рамках сессий и есть лимит на максимальное количество. Если же клиент не закрыл сессию, это придётся делать нам.
Данные об открытой сессии приходят от конечной системы и изначально обрабатываются на стороне Lua. Мы решили использовать Hazelcast для сохранения этих данных джобиком, написанным на .NET. Затем с некоторой периодичностью мы проверяем право на жизнь открытых сессий и закрываем протухшие.
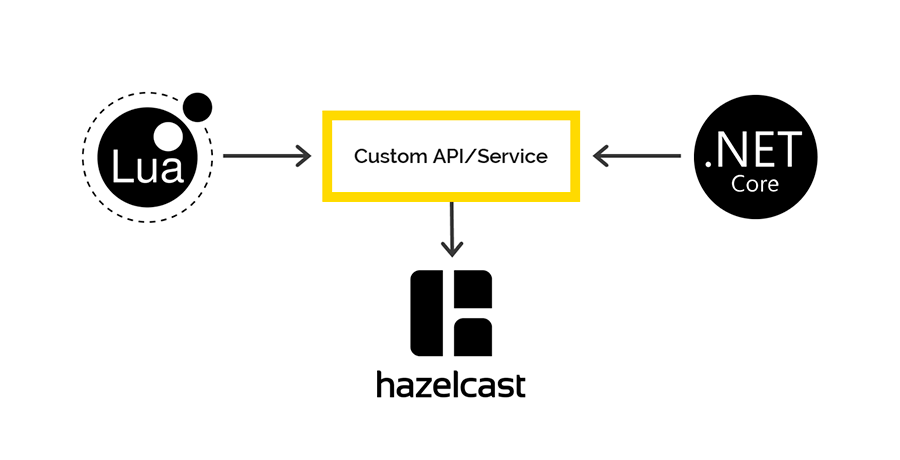
Доступ к Hazelcast и из Lua, и из .NET
Клиентов на Lua для работы с Hazelcast нет, но у Hazelcast есть REST API, которым мы и решили воспользоваться. Для .NET же есть клиент, через который мы планировали получать доступ к данным Hazelcast на стороне .NET. Но не тут-то было.

При сохранении данных через REST и извлечении через .NET клиента используются разные сериализаторы\десериализаторы. Поэтому невозможно положить данные через REST, а достать через .NET client и наоборот.
Если будут заинтересованные, то подробнее расскажем об этой проблеме в отдельной статье. Спойлер — на схемке.
Логирование и мониторинг
Наш корпоративный стандарт для логирования через .NET — Serilog, все логи в итоге попадают в Elasticsearch, их анализ ведём через Kibanа. Нечто подобное хотелось сделать и в этом случае. Единственный клиент для работы с Elastic на Lua, который был найден, сломался на первом же require. И мы использовали Fluentd.
Fluentd — open source решение для обеспечения единого слоя логирования приложения. Позволяет собирать логи с разных слоёв приложения, а потом транслировать их в единый источник.
API Gateway работает в K8S, поэтому мы решили добавить контейнер с fluentd в ту же самую подy, чтобы писать логи в имеющийся открытый tcp port fluentd.
Мы также исследовали, как будет вести себя fluentd, если у него не будет связи с Elasticsearch. В течение двух суток в шлюз непрерывно шли запросы, во fluentd отправлялись логи, но у fluentd был забанен IP Elastic. После восстановления связи fluentd отлично перегнал абсолютно все логи в Elastic.
Заключение
Выбранный подход к реализации позволил нам доставить реально работающий продукт в боевую среду всего за 2.5 месяца.
Если когда-нибудь вам доведётся заниматься подобными вещами, советуем в первую очередь четко понять, какую задачу вы решаете и что из ресурсов у вас уже есть. Будьте внимательны к сложностям интеграции с существующими системами управления API.
Поймите для себя, что именно вы собираетесь разрабатывать — только бизнес-логику обработки запросов или, как могло быть в нашем случае, прокси целиком. Не забывайте, что всё, что вы сделаете сами, должно быть впоследствии тщательно протестировано.
