Организация разработки в изолированной сети — как управлять зависимостями?
Всем привет,
Наша компания занимается разработкой CUBA — Open Source Java фреймворка для разработки корпоративных приложений. Платформа CUBA — это целая экосистема, которая включает в себя сам фреймворк и разнообразные аддоны, предоставляющие прикладной функционал, готовый к использованию в несколько кликов. За последние несколько лет фреймворк сильно набрал популярность и сейчас используется более 20 000 разработчиками по всему земному шару. С ростом популярности мы сталкивались с множеством интересных кейсов и в этой статье хотим затронуть один из них. Возможно, этот материал поможет в вашей практике, особенно если вы работаете в организации, в которой вопросы безопасности больно бьют по рукам разработчиков.

Конкретно мы поговорим про тот случай, когда в компании лимитирован доступ к всемирной паутине настолько, что вы не можете пользоваться публичными репозиториями артефактов, например таким, как maven central. Представьте себе, что мы (или вы) поставляем наш фреймворк в такой закрытый контур. Как же нам предоставить все необходимые артефакты, от которых мы зависим, включая транзитивные зависимости? Как потом их обновлять вместе с версиями фреймворка?
В данной статье я хочу рассказать о нашем новом инструменте CUBA SDK — консольной утилите, которая позволяет определять все транзитивные зависимости для Maven-библиотек и управлять ими в удаленных репозиториях. Также в статье мы рассмотрим пример, который позволит вам использовать наши наработки для любого Java приложения с применением Maven-зависимостей.
Проблема загрузки транзитивных зависимостей для внутренних репозиториев
Практически любой современный JVM проект, задействующий Apache Maven или Gradle в качестве инструмента сборки, имеет большое количество транзитивных зависимостей для используемых библиотек или фреймворков. При наличии доступного репозитория в сети эти зависимости автоматически разрешаются с помощью менеджера зависимостей.
Но что делать в случае, если публичные репозитории недоступны из внутренней сети?
Возможные варианты решения проблемы
Казалось бы, все просто — берем Nexus и проксируем обращение к репозиториям через него. Действительно, это решение в большинстве случаев может подойти, но не в тех случаях, где к безопасности предъявляются беспрецедентные требования. К таким организациям относятся предприятия военной промышленности, министерства, центробанк и прочие государственные институты. Выход в интернет в таких местах строго регламентирован и зачастую не позволяет использовать традиционное проксирование.
Что же нам остается?
- Вариант 0. Упрашивание безопасников.
- Вариант 1. Шлюз.
- Вариант 2. Ручное управление зависимостями.
Вариант 0 рассматривать не будем, рассмотрим вариант 1 и 2.
Для варианта со шлюзом: в организации должен быть шлюзовой компьютер, который одновременно может быть подключен или к внешней, или к внутренней сети. После загрузки и проверки необходимых библиотек из внешней сети шлюз переключается во внутреннюю сеть, и после этого библиотеки загружаются во внутренние репозитории. Добавление новых зависимостей или обновление существующих для одного проекта обычно занимает продолжительное время, так как нужно получить доступ к шлюзу, загрузить необходимые артефакты, проверить, что все транзитивные зависимости были загружены корректно, и затем выгрузить зависимости во внутренний репозиторий. Если проектов в организации много, то работа команды разработки может простаивать в ожидании, пока необходимые зависимости станут доступны из внутренних репозиториев.
Для варианта с ручным управлением зависимостями при обновлении или добавлении компонентов придется каждый раз проверять список зависимостей для библиотек и сравнивать с уже загруженными библиотеками.
Как видим из доступных примеров, добавление новых или обновление существующих зависимостей — это довольно сложное действие.
Если не рассматривать систему безопасности в организациях, то проблема доступности репозиториев актуальна и для разработчиков, например, разработчик планирует поработать в самоизоляции в глухой деревне у бабушки, но интернет там не ловит. Чтобы подготовиться для таких случаев, всегда можно попробовать использовать оффлайн плагины для Gradle или Maven. Но если проектов несколько, то для каждого проекта нужно будет
- настроить оффлайн плагин
- на всякий случай добавить в проект все зависимости, которые потенциально могут пригодиться, чтобы оффлайн плагины смогли их корректно добавить в свой кэш
- выгрузить все зависимости в локальную папку
Это не очень удобно, так как в проекте будут лишние зависимости и конфигурации, которые потом нужно будет не забыть удалить из проекта. И все равно останется проблема с созданием нового проекта, потому что может не хватать нужных модулей.
Как мы предлагаем решать эти проблемы?
CUBA SDK
Среди пользователей платформы CUBA есть организации в которых по соображениям безопасности нет доступа к внешней сети или доступ ограничен.
Мы решили облегчить жизнь таким пользователям и сделать консольное приложение CUBA SDK, которое могло бы определять все зависимости для аддонов и платформы CUBA.
В чем отличие CUBA SDK от оффлайн плагинов для Gradle или Maven?
Главное отличие — CUBA SDK не кэширует зависимости конкретного проекта, а позволяет синхронизировать артефакты между внешними и внутренними репозиториями, чтобы разработчикам было комфортно создавать и разрабатывать приложения в закрытой сети.
CUBA SDK не требует проекта и позволяет создать необходимый оффлайн стек фреймворков, аддонов и библиотек со всеми зависимостями.
Для разработчика это может быть полезно, если он работает с несколькими проектами или только планирует начать новый проект и сразу не знает, какие модули будут использоваться в его проекте. С помощью SDK эти модули могут быть заранее загружены в локальный или внутренний репозиторий.
Для организаций это может быть полезно для централизованной синхронизации внутренних репозиториев.
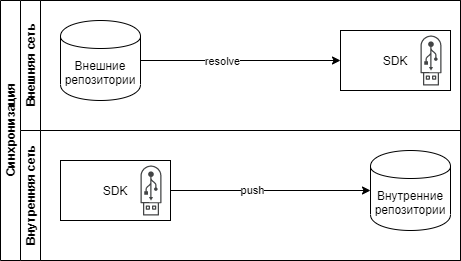
CUBA SDK позволяет с помощью нескольких консольных команд определять все зависимости для артефактов и заливать их в нужные репозитории. Для полностью закрытых сетей можно использовать команды импорта и экспорта или установить CUBA SDK на шлюз.
Преимущества использования CUBA SDK:
- автоматически собирает все зависимости с исходным кодом для загружаемых библиотек
- определяет зависимости для платформы и аддонов CUBA Platform
- проверяет и устанавливает новые версии библиотек
- может работать одновременно с несколькими репозиториями для поиска артефактов, включая локальные maven репозитории
- имеет встроенный Nexus OSS репозиторий артефактов
- даёт возможность загрузки артефактов одновременно в несколько репозиториев, включая локальные maven
- производит импорт и экспорт артефактов со всеми зависимостями
- предоставляет интерактивный режим с подсказками для установки платформы и аддонов CUBA Platform
- использует механизмы Gradle для определения зависимостей
- не зависит от IDE
- может быть установлен на CI сервере
Команды SDK
Полный список доступных команд можно посмотреть на странице GitHub.
CUBA SDK изначально поддерживает три типа компонентов: CUBA Framework, CUBA addon и библиотека, которая может быть загружена через maven координаты. Этот список может быть расширен для других типов компонентов через плагины для CUBA SDK.
Установка компонента в удаленный репозиторий может быть выполнена через команду install. При создании SDK мы предусмотрели вариант, когда SDK может быть установлен на шлюзовом компьютере или на переносном носителе, в этом случае установку компонентов можно сделать через команды resolve и push.
resolve — просто определяет и скачивает все зависимости в локальный кэш SDK
push — заливает уже скачанные артефакты с зависимостями в настроенные target репозитории
Для работы с репозиториями в SDK есть встроенный менеджер репозиториев.
Менеджер репозиториев поддерживает локальные и удаленные репозитории, которые в SDK разделены на две группы:
- source — это репозитории, которые будут использоваться для поиска артефактов
- target — репозитории, в которые нужно будет залить эти артефакты
SDK сам может использоваться как репозиторий, для этого с помощью команды setup-nexus SDK скачивает, устанавливает и настраивает репозиторий Nexus OSS. Для запуска и остановки репозитория используются команды start и stop.
Для проверки и установки обновлений достаточно выполнить команду check-updates.
Определение зависимостей
Самая главная проблема, которую должен был решать SDK — это корректное определение и сбор зависимостей для компонентов. При разработке мы попробовали несколько подходов для определения транзитивных зависимостей компонентов. Изначально возникла идея, что можно просто распарсить .pom файлы и составить дерево зависимостей. Но идея парсить файлы вручную оказалась не очень хорошей, тем более что Apache Maven все это уже умеет делать из коробки.
Maven как менеджер зависимостей
Поэтому мы решили использовать Apache Maven для определения транзитивных зависимостей компонентов.
Для этого в CUBA SDK скачивается дистрибутив maven в домашнюю папку SDK и через Java Runtime запускаются команды.
Например, с помощью команды
dependency:resolve -Dtransitive=true -DincludeParents=true -DoverWriteSnapshots=true -Dclassifier= -f pom.xml мы определяли все зависимости для компонентов, которые описаны в pom.xml, и эти компоненты автоматически скачивались в локальный кэш maven, после чего с помощью команды
org.apache.maven.plugins:maven-deploy-plugin:3.0.0-M1:deploy-file -Durl=артефакты заливались в нужный репозиторий.
Следующая команда позволяет загрузить библиотеку в локальный репозиторий.
org.apache.maven.plugins:maven-dependency-plugin:3.1.1:get -Dartifact=Для выполнения команд Maven в приложении CUBA SDK сгенерировался settings.xml файл. Он содержал список всех репозиториев, которые должны были использоваться для загрузки и выгрузки артефактов.
Gradle как менеджер зависимостей
В первой версии приложения зависимости определялись корректно, но довольно медленно, и при тестировании функционала стали возникать конфликты при определении зависимостей для некоторых аддонов CUBA Platform, хотя при сборке проекта через Gradle таких проблем не возникало.
Поэтому мы решили попробовать переписать всю логику определения зависимостей на Gradle. Для этого мы создали build.gradle скрипт, который содержал необходимые задачи по загрузке и определению зависимостей для компонентов.
Для вызова задач Gradle используется Gradle Tooling API.
Для определения пути к зависимостями через Gradle мы используем artifact resolution query API. Следующий код позволяет получить путь к исходникам библиотеки:
def component = project.dependencies.createArtifactResolutionQuery()
.forComponents(artifact.id.componentIdentifier)
.withArtifacts(JvmLibrary, SourcesArtifact)
.execute()
.resolvedComponents[0]
def sourceFile = component?.getArtifacts(SourcesArtifact)[0]?.fileТаким образом, мы получили пути ко всем файлам в локальном кэше Gradle и сохраняли их в хранилище SDK.
Для загрузки в локальный кэш и определения зависимостей для компонентов мы добавляем компоненты в конфигурацию и через lenientConfiguration получаем все зависимости.
project.ext.properties["toResolve"].tokenize(';').each {
dependencies.add 'extraLibs', it
}
def resolved = [:]
configurations.all.collect {
if (it.canBeResolved) {
it.resolvedConfiguration.lenientConfiguration.artifacts.each { art ->
try {
...
} catch (e) {
logger.error("Error: " + e.getMessage(), e)
logger.error("could not find pom for {}", art.file)
}
}
}
}Мы используем lenientConfiguration, чтобы Gradle скрипт пропускал не найденные зависимости и не падал в случае если компонент не найден в репозиториях.
Для загрузки артефактов в репозитории SDK использует PublishToMavenRepository задачу Gradle.
task publishArtifact(type: PublishToMavenRepository) {
doLast {
if (project.ext.hasProperty("toUpload")) {
def toUpload = new JsonSlurper().parseText(project.ext.properties["toUpload"])
def descriptors = new JsonSlurper().parseText(project.ext.properties["descriptors"])
artifactId toUpload.artifactId
groupId toUpload.groupId
version toUpload.version
descriptors.each { descriptor ->
artifact(descriptor.filePath) {
classifier descriptor.classifier.type
extension descriptor.classifier.extenstion
}
}
}
}
}В результате использования Gradle мы избавились от конфликтов при определении транзитивных зависимостей и заметно ускорили работу приложения.
Сборка проекта
Для сборки CUBA SDK мы использовали тот же подход, что и для CUBA CLI. Мы с помощью инструмента jlink собирали все необходимые модули в кастомную JRE, которая поставляется вместе с приложением. Это позволило сделать SDK независимым от установленной на компьютерах пользователей Java. Пример такой сборки можно посмотреть в CLI Core Sample проекте.
Поддержка сторонних плагинов
Так как CUBA SDK построен на основе библиотеки CLI Core, CUBA SDK поддерживает сторонние плагины. С помощью системы плагинов сейчас в SDK реализованы maven и gradle менеджеры зависимостей компонентов и провайдеры для CUBA компонентов.
Рассмотрим пример, как мы можем расширить функционал SDK с помощью плагина. В данном примере мы напишем провайдер для стартеров Spring Boot из хорошо известного Spring Initializr.
Для начала создадим новый проект, для примера возьмем плагин для CUBA CLI, как описано здесь, и добавим зависимости:
implementation "com.haulmont.cli.core:cli-core:1.0.0"
implementation "com.haulmont.cli.sdk:cuba-sdk:1.0.1"Создадим новый провайдер для стартеров spring boot SpringBootProvider, который наследуем от BintraySearchComponentProvider. BintraySearchComponentProvider позволяет автоматически находить доступные версии компонентов, используя Bintray API.
class SpringBootProvider : BintraySearchComponentProvider() {
var springComponentsInfo: SpringComponentsInfo? = null
override fun getType() = "boot-starter"
override fun getName() = "Spring boot starter"
...
override fun load() {
springComponentsInfo = Gson().fromJson(readSpringFile(), SpringComponentsInfo::class.java)
}
private fun readSpringFile(): String {
return SpringComponentsPlugin::class.java.getResourceAsStream("spring-components.json")
.bufferedReader()
.use { it.readText() }
}Этот провайдер будет искать доступные компоненты из файла spring-components.json, который является json версией yml файла приложения Spring Initializr.
Для маппинга из json в объекты создадим простые data классы:
data class SpringComponent(
val name: String,
val id: String,
val groupId: String?,
val artifactId: String?,
val description: String?,
val starter: Boolean? = true
)
data class SpringComponentCategory(
val name: String,
val content: List
)
data class SpringInitializr(
val dependencies: List
)
data class SpringComponentsInfo(
val initializr: SpringInitializr
) Для того, чтобы добавить наш провайдер к остальным провайдерам SDK, нужно в init событии плагина зарегистрировать провайдер:
class SpringBootComponentsPlugin : CliPlugin {
private val componentRegistry: ComponentRegistry by sdkKodein.instance()
@Subscribe
fun onInit(event: InitPluginEvent) {
val bootProvider = SpringBootProvider()
componentRegistry.addProviders(bootProvider)
bootProvider.load()
}
} Все готово. Теперь, чтобы установить наш плагин в терминале или через IDE, нужно выполнить команду gradle installPlugin.
Запустим SDK
Видим, что наш плагин успешно загрузился. Теперь проверим, что вся наша логика работает с помощью команды resolve boot-starter:
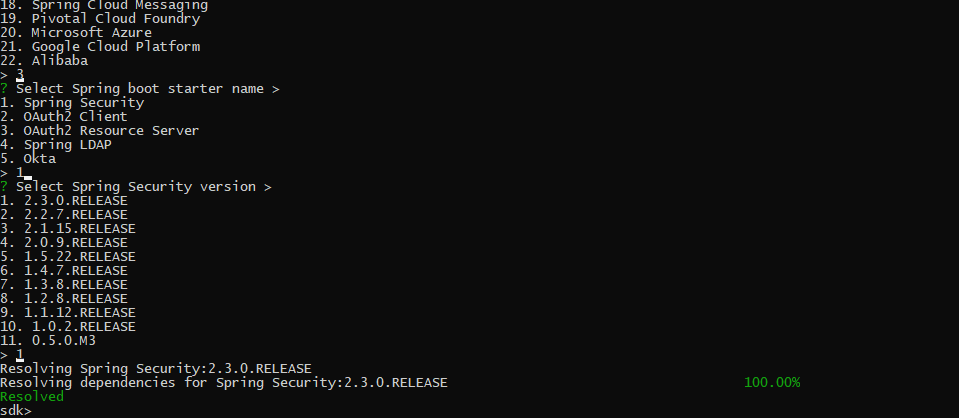
Как видим, подсказки для компонентов и их версий успешно заработали.
Если в вашем хранилище артефактов артефакты и зависимости хранятся отлично от maven репозиториев, то через плагины можно использовать свою реализацию интерфейса ArtifactManager, в которой будет логика работы с вашим хранилищем.
Исходный код тестового плагина можно найти на странице GitHub.
Заключение
В первую очередь, CUBA SDK будет полезен организациям, у которых по соображениям безопасности есть ограничения на доступ к внешней сети.
Если вы самоизолировались в глухой деревне или летите 8 часов в самолете и не готовы платить по 300 евро за 10 мегабайт трафика, то CUBA SDK — отличное решение, которое позволит собрать актуальный стек используемых библиотек и фреймворков локально у вас на компьютере.
