Оптимизация производительности .NET (C#) приложений

Статей с подобным заголовком достаточно много, поэтому постараюсь избежать банальных тем. Надеюсь, что даже очень опытные разработчики найдут здесь что-то новое для себя. В данной статье будут рассмотрены только простые механизмы и подходы к оптимизации, которые позволят применить их, затратив минимум усилий. И эти изменения не увеличат энтропию вашего кода. В статье не будет уделено внимание что и когда нужно оптимизировать и как искать проблемы производительности, эта статья скорее о подходе к написанию кода в целом.
1. ToArray vs ToList
public IEnumerable GetItems()
{
return _storage.Items.Where(...).ToList();
}
Согласитесь, очень типовой код для промышленных проектов. Но что в нём не так? IEnumerable интерфейс возвращает коллекцию, по которой можно «пробежаться», данный интерфейс не предполагает того, что мы можем добавлять/удалять элементы. Соответственно, нет необходимости заканчивать LINQ выражение приведением к List’у (ToList). В данном случае, предпочтительнее будет приведение к Array (ToArray). Так как List является обвёрткой над Array, а все дополнительные возможности, предоставляемые этой обвёрткой, мы срезаем интерфейсом. Соответственно, зачем платить больше. C одной стороны эта оптимизация не существенная, как говорят «оптимизация на спичках», но это не совсем так. Дело в том, что в типовом приложении, в котором многочисленные сервисы возвращают неизменяемые модели для слоя представления, таких «лишних» вызовов ToList может быть мириады. В описанном выше примере интерфейс IEnumerable введён для большей наглядности. Данный подход актуален для всех случаев, когда нужно возвращать коллекцию, которую в последствии вы не собираетесь менять.
Предвижу комментарий о том, что Array и List будут работать не эквивалентно в случае многопоточного обращения к коллекции. Это действительно так. Но если вы, как разработчик, рассматриваете возможность многопоточного доступа к такой коллекции c возможностью её изменения, то с высокой степенью вероятности вам уже не подходят ни Array, ни List.
2. Параметр «путь к файлу» не всегда лучший выбор для вашего метода
При разработке API избегайте сигнатур методов, которые на вход получают путь к файлу (для последующей обработки вашим методом). Вместо этого предоставляйте возможность передать на вход массив байт или в крайнем случае Stream. Дело в том, что со временем, ваш метод может быть применён не только к файлу с диска, но и к файлу, переданному по сети или к файлу из архива, к файлу из базы данных, к файлу содержание которого сформировано динамически в памяти и т.д. Предоставляя метод с входным параметром «путь к файлу» вы обязываете пользователя вашего API предварительно сохранить данные на диск, чтобы потом прочесть их снова. Это бессмысленная операция критически влияет на производительность. Диск — крайне медленная штука. Для удобства вы можете предоставить метод с входным параметром «путь к файлу», но внутри всегда используйте публичный перегруженный метод с массивом байт или stream’ом на входе. Есть «маркер», который может помочь найти лишние операции записи/чтения диска, попробуйте найти в вашем проекте использование стандартных методов: Path.GetTempPath(), Path.GetRandomFileName() (из System.IO). С высокой степенью вероятности, вы встретите workaround вышеописанной проблемы или похожей. Внимательный и опытный читатель заметит, что в некоторых случаях, запись на диск может наоборот улучшить производительность, например, если мы имеем дело с большими файлами. Это действительно так, это необходимо учитывать, но предполагаю что это очень редкая ситуация со специфичной реализацией.
3. Избегайте использования потоков в качестве параметров и возвращаемого результата ваших методов
В чём здесь проблема… когда мы получаем поток из некоторого «чёрного ящика», мы должны держать в голове его состояние. Т.е. открыт ли поток? Где находится маркер чтения/записи? Может ли измениться его состояние независимо от нашего кода? Если поток объявлен как базовый класс Stream, мы даже не владеем информацией, какие операции над ним доступны. Всё это решается дополнительными проверками, а это дополнительный код и издержки. Также, неоднократно сталкивался с ситуацией, когда, получая Stream из некоторого «неясного» метода, разработчик предпочитал перестраховаться и «перегнать» данные из него в полностью контролируемый новый локальный MemoryStream. Хотя, исходный поток мог быть вполне безопасным. Может даже это и был уже любезно подготовленный для чтения MemoryStream. Иногда может доходить до абсурда — внутри метода, массив байт кладётся в MemoryStream, далее данный MemoryStream возвращается как результат метода, объявленного как базовый Stream, снаружи этот Stream оборачивается новым MemoryStream’ом и далее вызывав ToArray () получаем массив байт, который изначально у нас и был. Ирония в том, что внутри и снаружи нашего метода код вполне корректный. В итоге, если у вас есть возможность передавать / получать «чистые» данные, не используйте для этого потоки — не создавайте капканов, для тех, кто будет этим пользоваться. Если же в вашем приложении уже есть передача / возврат потоков, проанализируйте их использование на основе вышеизложенного.
4. Наследование enum’ов
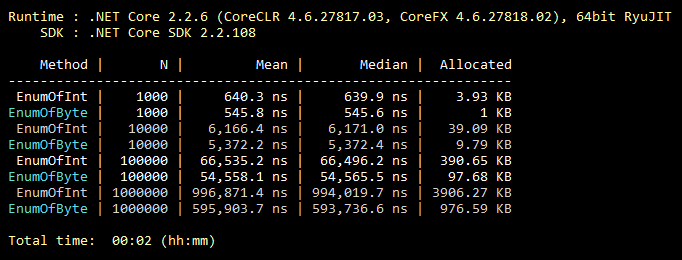
Данная оптимизация банальная, её знают все, даже студенты. Но из моего опыта, ей крайне редко пользуются. Итак, по умолчанию enum наследуется от int. Однако его можно наследовать от byte, который вмещает 256 значений (или 8 «flaggable» значений). Что почти всегда покрывает функциональность «среднего» enum«а. Минимальное изменение в коде и все значения вашего enum«а занимают вдвое меньше памяти навсегда. Ниже иллюстрация бенчмарка по заполнению коллекции значениями enum«ов, наследуемых от int и byte.
public class CollectEnums
{
[Params(1000, 10000, 100000, 1000000)] public int N;
[Benchmark]
public EnumFromInt[] EnumOfInt()
{
EnumFromInt[] results = new EnumFromInt[N];
for (int i = 0; i < N; i++)
{
results[i] = EnumFromInt.Value1;
}
return results;
}
[Benchmark]
public EnumFromByte[] EnumOfByte()
{
EnumFromByte[] results = new EnumFromByte[N];
for (int i = 0; i < N; i++)
{
results[i] = EnumFromByte.Value1;
}
return results;
}
}
public enum EnumFromInt
{
Value1,
Value2
}
public enum EnumFromByte: byte
{
Value1,
Value2
}5. Ещё пару слов о классах Array и List
Следуя логике, итерирование по массиву всегда эффективнее, итерирования по «листу» так как «лист» это обвёртка над массивом. Также, следуя логике, «for» всегда быстрее «foreach», так как «foreach» делает много действий, требуемых реализацией интерфейса IEnumerable. Здесь всё логично, но не верно! Давайте взглянем на результаты бенчмарка:

public class IterationBenchmark
{
private List _list;
private int[] _array;
[Params(100000, 10000000)] public int N;
[GlobalSetup]
public void Setup()
{
const int MIN = 1;
const int MAX = 10;
Random random = new Random();
_list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList();
_array = _list.ToArray();
}
[Benchmark]
public int ForList()
{
int total = 0;
for (int i = 0; i < _list.Count; i++)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForeachList()
{
int total = 0;
foreach (int i in _list)
{
total += i;
}
return total;
}
[Benchmark]
public int ForeachArray()
{
int total = 0;
foreach (int i in _array)
{
total += i;
}
return total;
}
[Benchmark]
public int ForArray()
{
int total = 0;
for (int i = 0; i < _array.Length; i++)
{
total += _array[i];
}
return total;
}
}
Дело в том, что для итерирования по массиву, «foreach» не использует реализацию IEnumerable. В этом частном случае выполняется максимально оптимизированное итерирование, без проверки на выход за границы массива, так как конструкция «foreach» не оперирует индексами и «накосячить» в коде здесь нет возможности. Такое вот исключение. Поэтому, если в каком-то критичном участке кода, вы заменили использование «foreach» на «for» раде оптимизации — вы выстрелили себе в ногу. Обратите внимание, это актуально только для массивов. На StackOverflow есть несколько веток, где обсуждается это особенность.
6. Всегда ли поиск через хеш-таблицы оправдан?
Все знают, что хеш-таблицы очень эффективны для поиска. Но часто забывают, что цена за быстрый поиск — медленное добавление в хеш-таблицу. Что из этого следует? Для того чтобы использование хеш-таблицы было оправданным необходимо, чтобы кол-во элементов хеш-таблицы было не менее 8 (примерно). И чтобы кол-во операций поиска в критичном коде было хотя бы на порядок выше кол-ва операций добавления. В противном случае используйте коллекцию попроще. На моей практике был случай, когда самым «узким местом» в нагруженном коде был вызов метода Dictionary.Add (). Воспоминание об этом и стало триггером к написание этого пункта. Для иллюстрации ниже пример очень плохого кода:
private static int GetNumber(string numberStr)
{
Dictionary dictionary = new Dictionary
{
{"One", 1},
{"Two", 2},
{"Three", 3}
};
dictionary.TryGetValue(numberStr, out int result);
return result;
}
Может что-то подобное встречается и в вашем проекте?
7. Встраивание методов
Код разбит на методы чаще всего по 2-ум причинам. Обеспечить повторное использование кода и обеспечить декомпозицию, когда одна задача разбивается на несколько подзадач, даже если решение каждой из них используется в одном единственном месте. Для человека так проще. Inlining — это обратный процесс декомпозиции, т.е. код метода встраивается в то место где метод должен вызываться, в итоге мы экономим на стеке вызовов и передаче параметров. Я никоим образом не рекомендую всё «запихивать» в один метод. Но те методы, которые мы могли бы теоретически за «инлайнить» можно пометить соответствующим атрибутом: [MethodImpl(MethodImplOptions.AggressiveInlining)]
Этот атрибут подскажет системе, что этот метод можно встраивать. Это вовсе не значит что метод, помеченный этим атрибутом, будет обязательно встроен. Например, невозможно встроить рекурсивные или виртуальные методы. Стоит также отметить, что механизм встраивания чрезвычайно «нежный». Есть много других причин, по которым система откажется встраивать ваш метод. Тем не менее, команда Microsoft, работающая над .NET Core, активно пользуется этим атрибутом.
8. Оценочный Capacity
У меня (и надеюсь, у большинства разработчиков тоже) выработан рефлекс: проинициализировал коллекцию — задумался, можно ли для неё задать Capacity. Однако, далеко не всегда заранее известно точное кол-во элементов коллекции. Но это не повод игнорировать этот параметр. Например, если, рассуждая о том, какое кол-во элементов будет в вашей коллекции вы предполагаете размытое «пару тыщ» это уже повод задать Capacity равное 1000. Немного теории, например, для List по умолчанию Capacity = 16, для того чтобы только дойти до 1000, система сделает 1008 (16 + 32 + 64 + 128 + 256 + 512) лишних копирований элементов и создаст 7 временных массивов на откуп следующему вызову GC.Т. е. вся эта работа выполнится впустую. Также, в качестве Capacity никто не запрещает использовать формулу. Если размер вашей коллекции оценочно равен одной трети другой коллекции, можно задать Capacity равное otherCollection.Count / 3. При установке оценочного Capacity стоит хорошо понимать диапазон возможного размера коллекции и насколько его значение равномерно распределёно. Всегда есть вероятность навредить, но при правильном использовании оценочный Capacity даст вам хороший выигрыш.
9. Всегда конкретизируйте ваш код
Активно используйте (на первый взгляд, необязательные) ключевые слова C#, такие как: static, const, readonly, sealed, abstract и т.д. Естественно, там, где они имеют смысл. Причём здесь производительность? Дело в том, чем более детально вы опишете компилятору свою систему, тем более оптимальный код он сможет сгенерировать. Внимательный и опытный читатель может заметить что, например ключевое слово sealed никак не влияет на производительность. Сейчас это действительно так, но в следующих версиях всё может измениться. Дайте компилятору и виртуальной машине шанс! Бонусом получите, выявление многих ошибок неправильного использования вашего кода на этапе компиляции. Общее правило: чем более чётко система описана, тем оптимальнее результат (судя по всему, с людьми также).
10. По возможности используйте одну версию .NET для всех проектов Solution’а
Стоит стремиться, к тому, чтобы все сборки в рамках вашего приложения относились к одной и той же версии .NET. Это касается как NuGet пакетов (редактируется в packages.config/json), так и ваших собственных сборок (редактируется в Project properties). Это позволит сэкономить оперативную память и ускорить «холодный» старт, так как в памяти вашего приложения не будет копий одних и тех же библиотек, под разные версии .NET. Стоит отметить, что не во всех случаях разные версии .NET будут порождать копии в памяти. Но исходите из того, что, приложение, построенное на одной версии .NET это всегда лучше. Также, это избавит от целого ряда потенциальных проблем, лежащих за пределами темы данной статьи. Консолидация версий всех NuGet пакетов, используемых вами, тоже внесёт вклад в улучшение производительности вашего приложения.
Пару слов о полезных инструментах
ILSpy — бесплатный инструмент позволяющий посмотреть восстановленный исходный код сборки. Если у меня возникает вопрос о том, какой механизм .NET более эффективный, в первую очередь, я открываю ILSpy (а не Google или StackOverflow), и уже там смотрю, как он реализован. Например, чтоб узнать, что лучше использовать с точки зрения производительности для получения данных по HTTP, класс HttpWebRequest или WebClient, достаточно посмотреть их реализацию через ILSpy. В данном конкретном случае WebClient это обвёртка над HttpWebRequest. Исходных кодов .NET боятся не стоит, их пишут такие же обычные программисты.
BenchmarkDotNet — бесплатная библиотека «бенчмарков». Есть простой и понятный StopWatch (из System.Diagnostics). Но иногда его бывает недостаточно. Так как по-хорошему нужно учитывать не единичный результат, а среднее нескольких сравнений, а лучше сравнить их медиану, чтоб минимизировать влияние ОС. Также, нужно учесть «холодный старт» и объём выделяемой памяти. Для таких сложных тестов BenchmarkDotNet и создан. Именно эту библиотеку используют разработчики .NET Core в официальных тестах. Библиотека простая в использовании, но если вдруг её авторы читают сей пост, прошу, дайте более удобную возможность влиять на структуру таблицы результатов.
U2U Consult Performance Analyzers — бесплатный плагин к Visual Studio, дающий подсказки по улучшению кода с точки зрения производительности. Полагаться 100% на советы данного анализатора не стоит. Так как сталкивался с ситуацией когда один «совет» меня немного удивил и после детального анализа он действительно оказался ошибочным. К сожалению, сей пример утерян, так что верьте на слово. Тем не менее, если им пользоваться вдумчиво, очень полезный инструмент. Например, он подскажет, что вместо myStr.Replace("*", "-") эффективнее использовать myStr.Replace('*', '-'). А два Where выражения в LINQ лучше объединить в одно. Всё это оптимизации «на спичках», но они легко применяются и не приводят к увеличению кода/сложности.
В качестве заключения
Если каждый 10-ый прочитавший статью, проанализирует и применит вышеуказанные подходы к своему текущему проекту или (критической его части), а также будет придерживаться этих подходов в будущем, то ВМЕСТЕ мы сможем спасти целый лес! Лес??? Т.е. сэкономленные нами ресурсы компьютерных систем, переведённые в электричество, полученное от сжигания древесины останутся не использованными. В данном случае лес это лишь некий эквивалент. Вероятно, странное заключение получилось, но, надеюсь, вы прониклись мыслью.
