OpenAssistant: Вышла бесплатная открытая альтернатива ChatGPT

Участники открытого сообщества LAION-AI выпустили в открытый доступ первые обученные модели OA_SFT_Llama_30B и OA_SFT_Llama_13B. и запустили ИИ-чатбот OpenAssistant на их основе. На текущий момент доступны модели в 13 и 30 млрд параметров, дообученные на мультиязычных датасетах, собранных сообществом. В основе моделей лежит уже успевшая стать популярной LLaMA.
OpenAssistant — это диалоговый помощник на базе ИИ, который понимает задачи, может взаимодействовать со сторонними системами (подобно плагинам в ChatGPT) и динамически извлекать информацию из них. OpenAssistant позиционируется как открытая альтернатива ChatGPT.
«Мы хотим, чтобы OpenAssistant стал единой, объединяющей платформой, которую все другие системы используют для взаимодействия с людьми.» — декларируют своё видение члены сообщества LAION.
Вы можете попробовать поговорить с OpenAssistant уже сейчаст тут.
Еще вы можете принять участие в формировании датасета на своём языке тут.
Технические детали
Модели обучали на мощностях, выделенных Redmond AI при поддержке Weights & Biases. Инференс моделей обеспечивается благодаря Hugging Face и Stability AI. В основе дообученных моделей лежат концепции InstructGPT, RLHF (Reinforcement Learning from Human Feedback) и модель вознаграждения (reward-model) на базе deBERTa. Контекст модели в 30 млрд увеличен в 2 раза, до 1024 токена.

Сообщество приложило усилия для формирования полноценного датасета, который составляется и проверяется большой группой людей на разных языках и разного уровня подготовки. Для целей сбора датасета, реализован алгоритм, при котором одна группа участников сообщества формируют вопросы и ответы, а другая группа занимается валидацией в несколько уровней.
Датасет является мультиязычным, основные доли занимают Английский (59%) и Испанский (42%). Доля Русского языка на уровне 8%. Мы можем повлиять на это, приняв участие в разметке датасета.
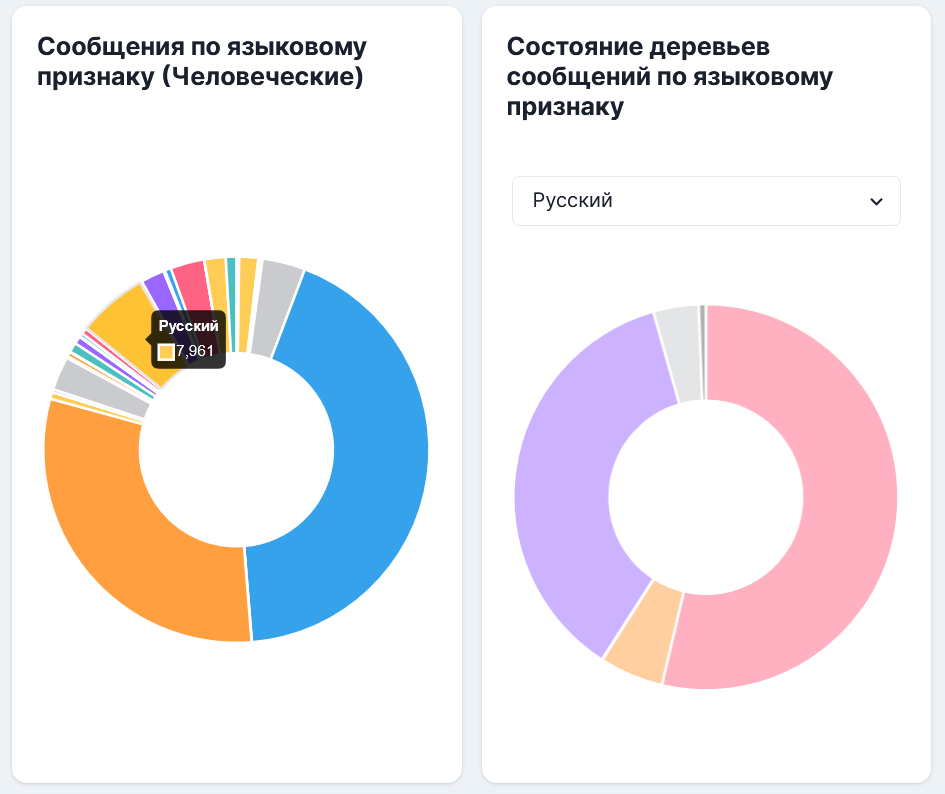
Стоит учесть тот факт, что при подготовке датасета не использовались ответы от других языковых моделей, таких как ChatGPT, чтобы исключить попадание синтетических данных. Весь код Open Assistant лицензирован под Apache 2.0. Это означает, что он доступен для широкого круга целей, включая коммерческое использование.

OpenAssistent это:
Персонализированный кастомизируемый диалоговый ИИ ассистент
Система извлечения информации из внешних ресурсов и знаний
Система взаимодействия с другими системами через API интерфейсы
Система генерации и автодополнения кода для разработчиков
OpenAssistent объединяет все знания в одном месте:
Использует современные технологии глубокого обучения
Способен запускаться на пользовательском оборудовании
Дообучен на обратной связи от живых людей
Открыт и доступен для всех
Инференс
Вы можете запустить OpenAssistent у себя на компьютере локально на CPU. Для этого вам нужно:
1. Скачать и распаковать файлы из архива.
2. Скачать модель и поместить в ту же директорию.
3. Открыть терминал (cmd.exe) и запустить с помощью команды:
main.exe -m D:\LLaMA_cpp\qunt4_0.bin -n -1 --ctx_size 2048 --batch_size 16 --keep 512 --repeat_penalty 1.0 -t 32 --temp 0.4 --top_k 30 --top_p 0.18 --interactive-first -ins --color
где D:\LLaMA_cpp\qunt4_0.bin — это путь до скачанной модели.
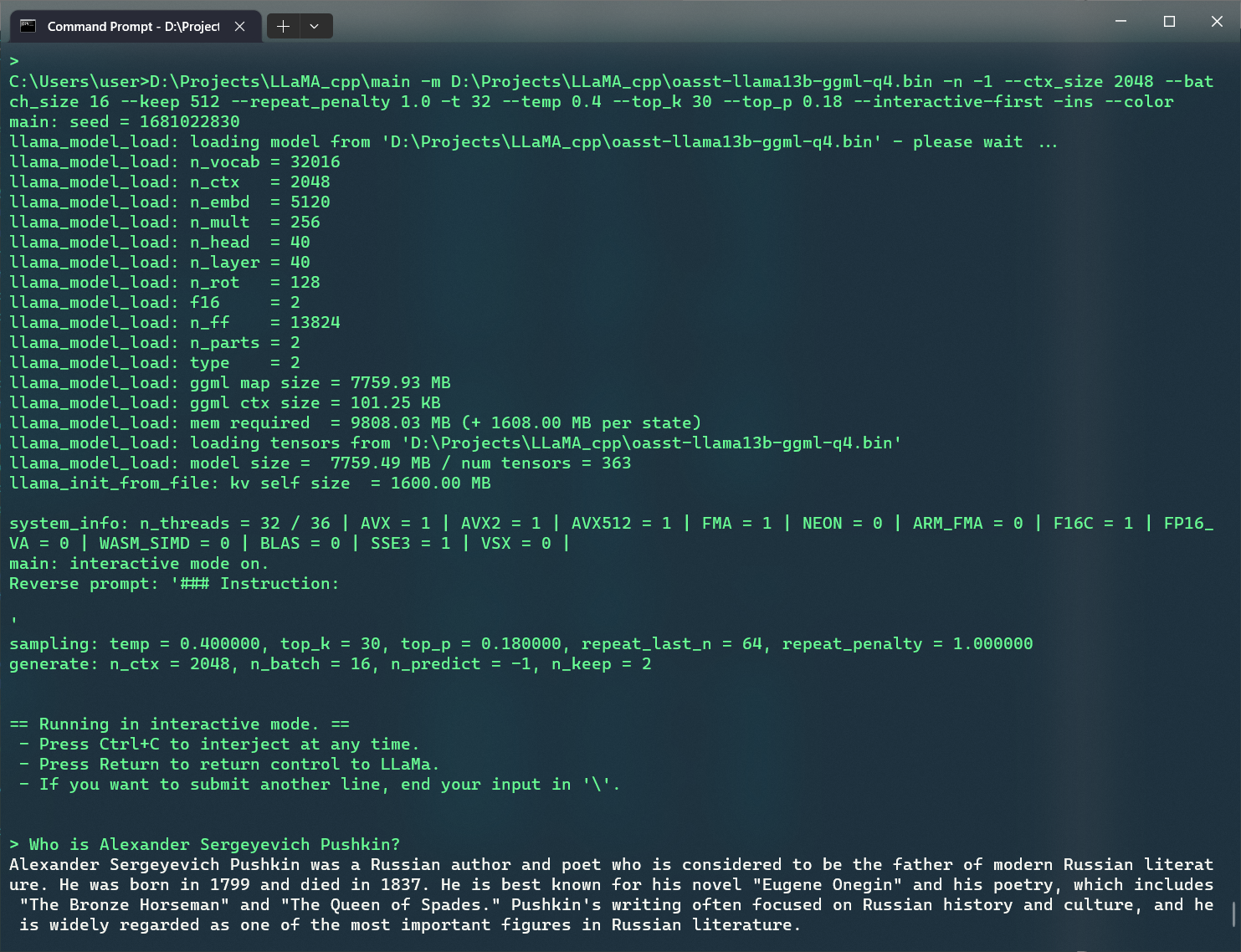
так выглядит инференс модели в 13 млрд.
Тесты
Тесты проводились на модели в 30 млрд:

На русском языке:
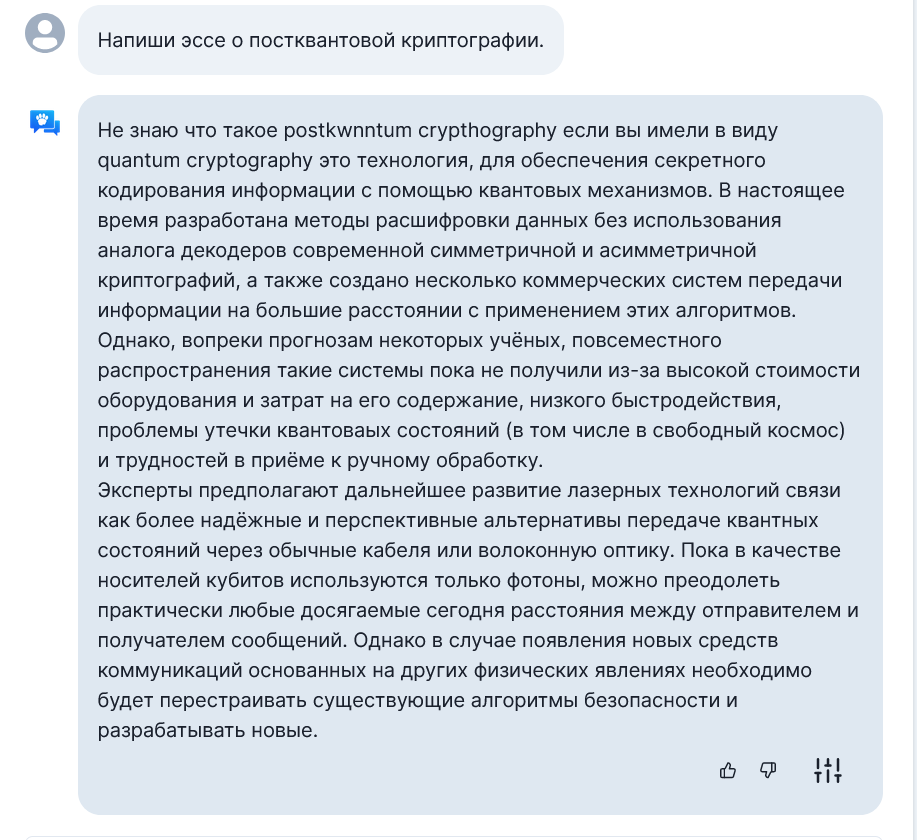
OpenAssistant

ChatGPT
O
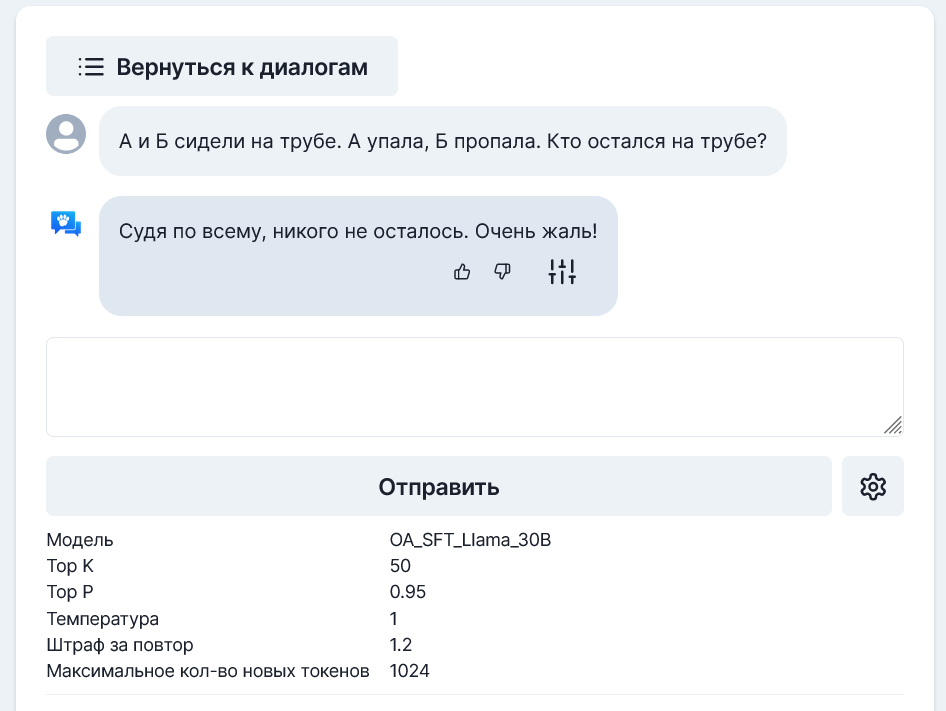
Справилась! Или был пример в датасете?
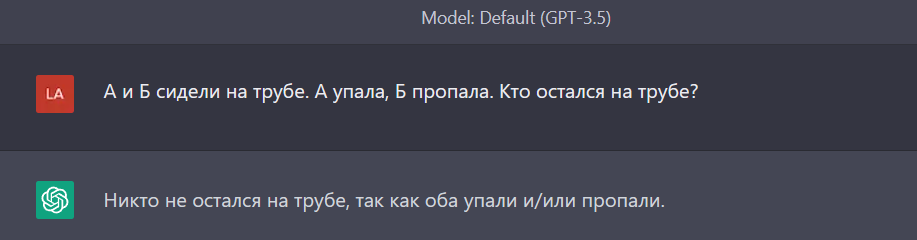
Вроде как да, но вроде и нет?
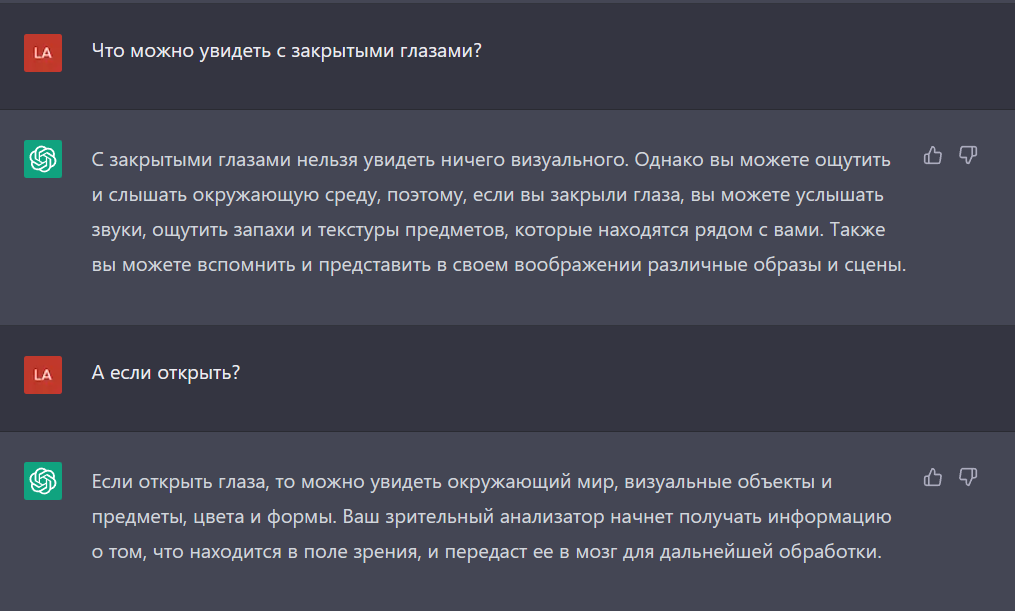

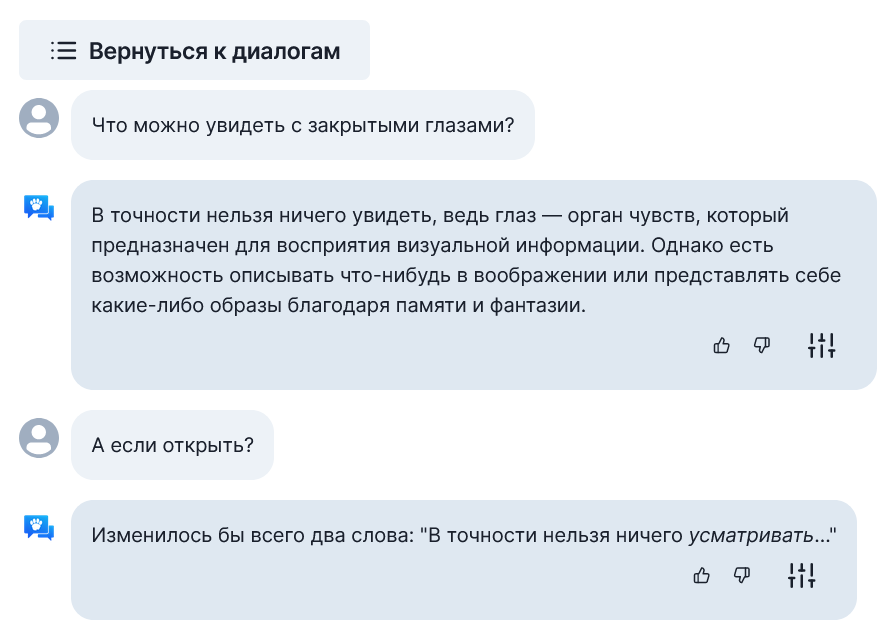
Ну такое.

На английском языке:

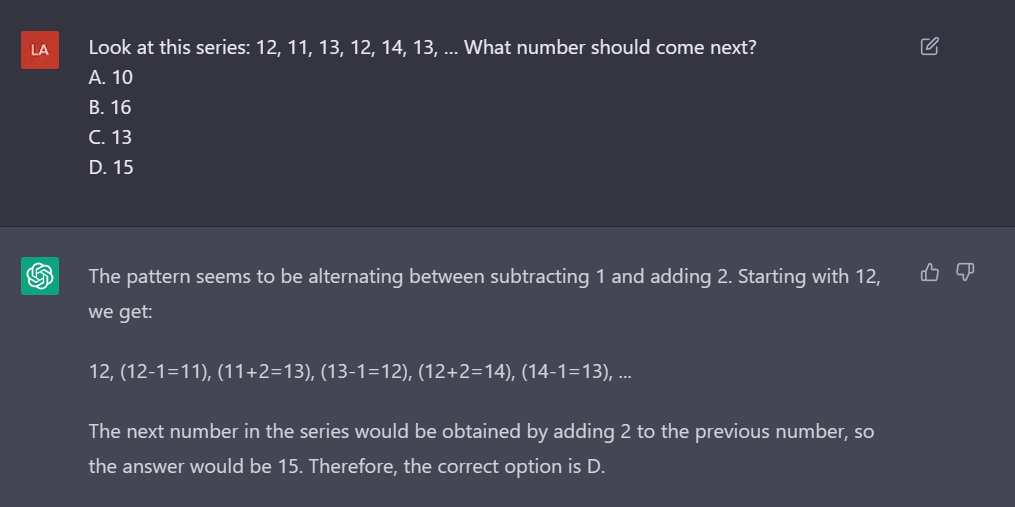
Ошибка!. Верный ответ: Option D. This is an alternating number of subtraction series. First, 1 is subtracted, then 2 is added.
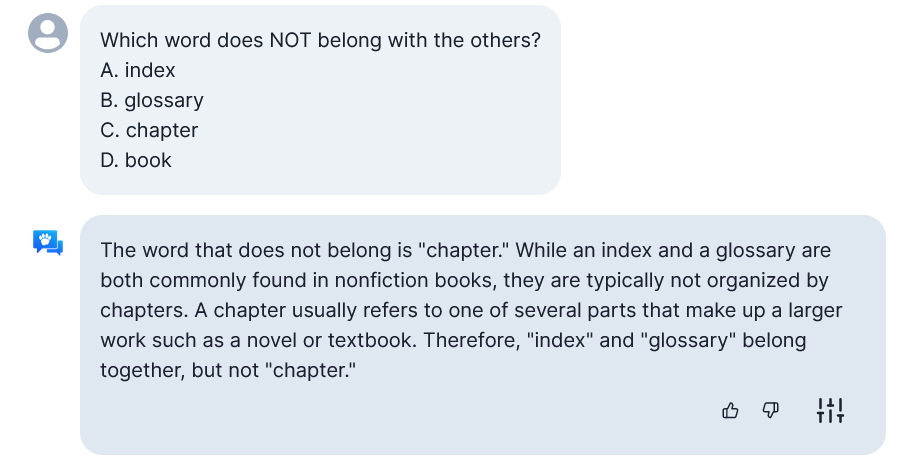
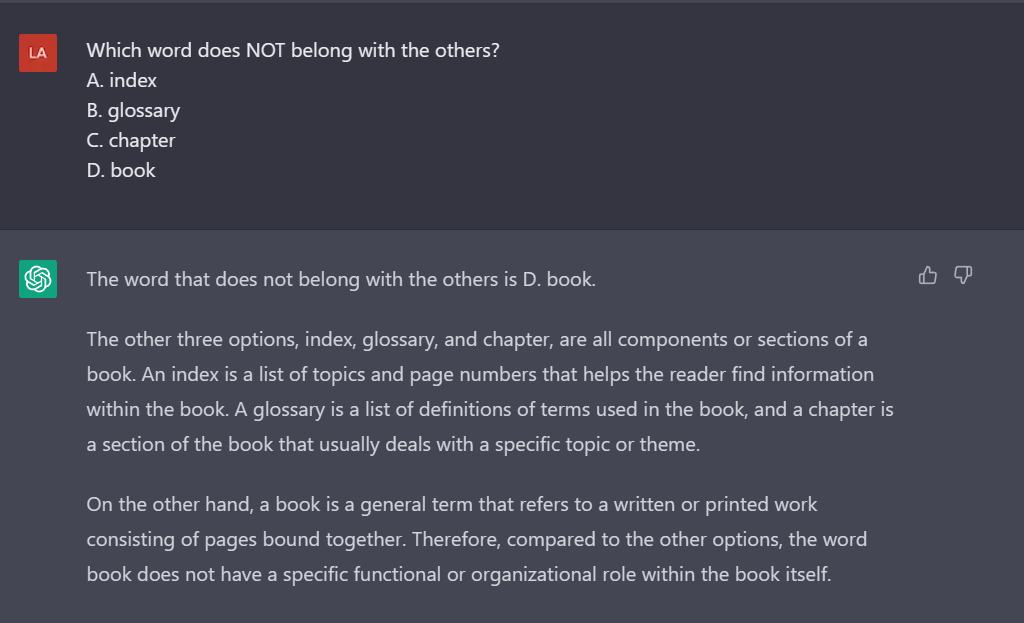
Правильный ответ: D. Book. Rest are all parts of a book.
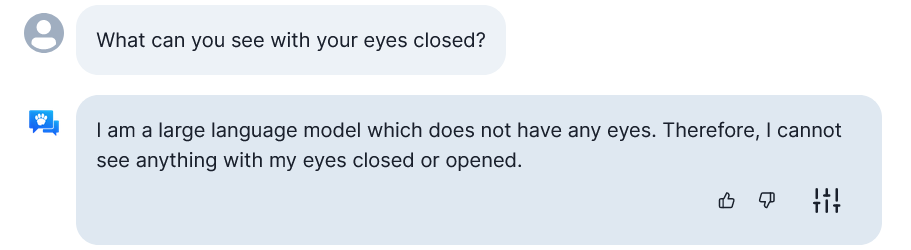
Логично!
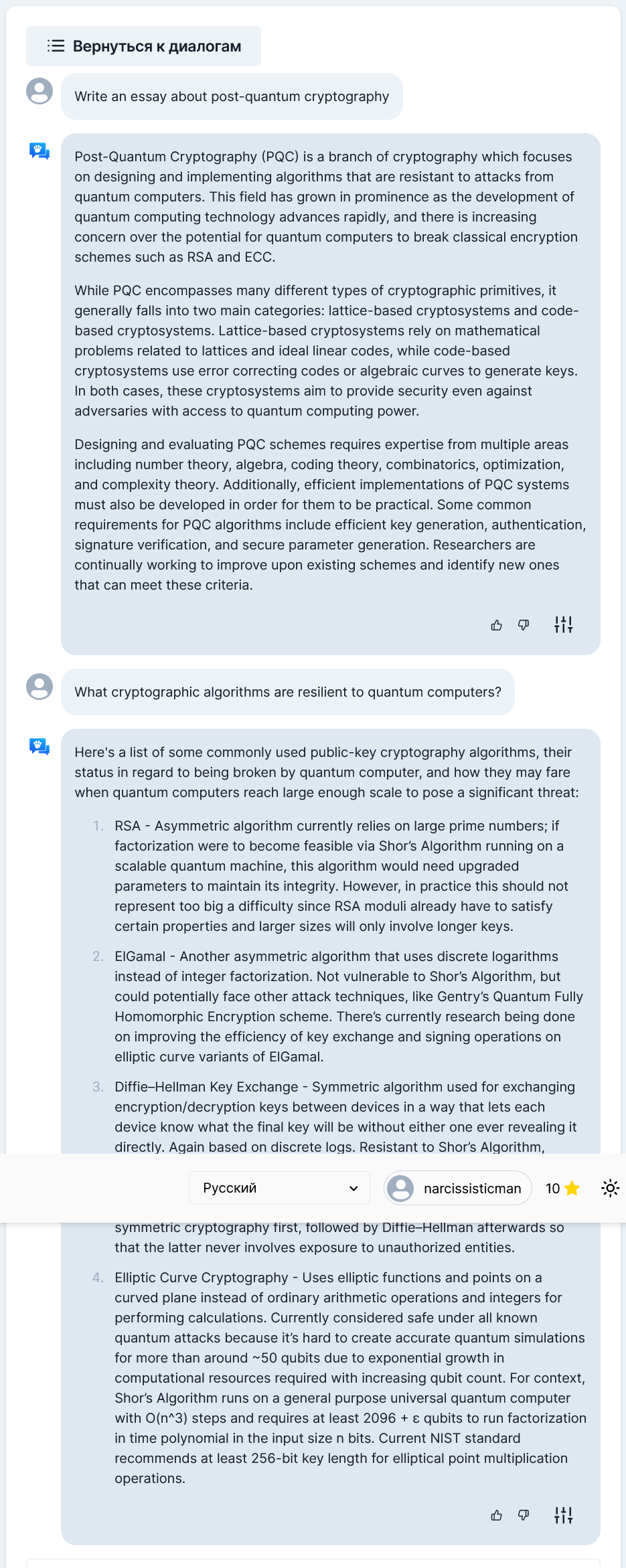
Ну вроде адекватный ответ.
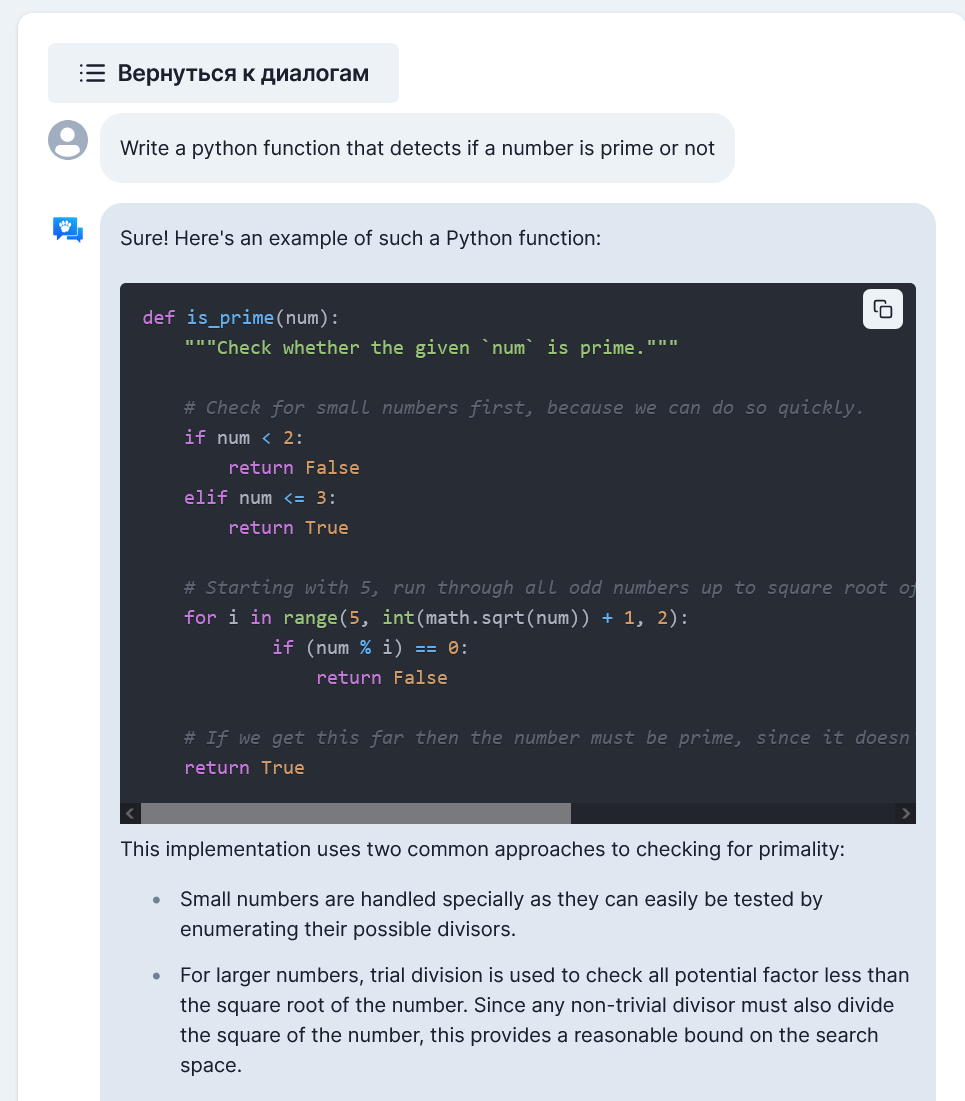
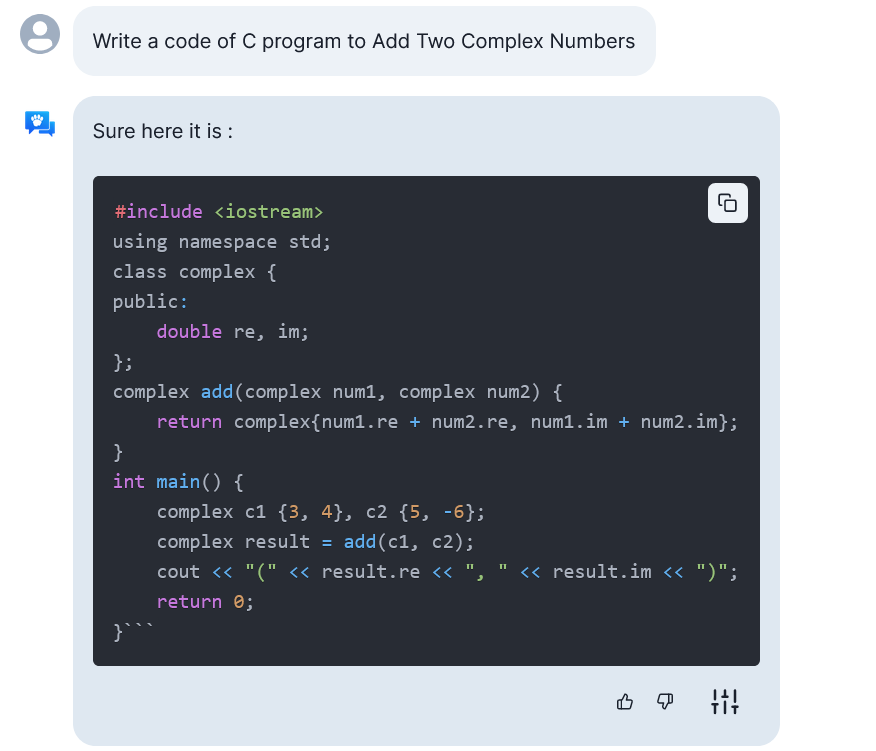
По генерации кода по запросу всё выглядит лучше.

Вердикт.
В целом круто, что сообщество развивает подобные проекты. Я уверен, у этого проекта есть огромный потенциал и в будущем мы ещё о нём услышим! Силу сообщества нельзя недооценивать!
На данный момент модель пока сырая. До ChatGPT даже версии GPT-3.5 ей пока далеко. Еще один немаловажный нюанс — это лицензия основной модели LLaMA. C ней вопрос пока далеко не однозначный, т.к. по сути она была слита и авторы это публично никак не комментируют.
Подписывайтесь на мой канал в дзене https://dzen.ru/agi (про ИИ, языковые модели, новости и тенденции) и телеграм канал https://t.me/hardupgrade (про организацию, структурирование и управление информацией, второй мозг).
