Open Source синтез речи SOVA
Всем привет! Ранее мы выкладывали статью про наше распознавание речи, сегодня мы хотим рассказать вам о нашем опыте по созданию синтеза речи на русском языке, а также поделиться ссылками на репозитории и датасеты для свободного использования в любых целях.

Если вам интересна история о том, как мы разработали собственный сервис синтеза речи и каких результатов нам удалось достигнуть, то добро пожаловать под кат.
Про существующие технологии реализации синтеза подробно рассказывать не будем, благо на хабре уже есть хорошая статья от блога компании Тинькофф на эту тему, упомянем лишь то, что существуют два основных подхода:
Фонема — минимальная смыслоразличительная единица языка. Простыми словами, является для устной речи тем же, чем буквы для письменной. В фонему может входить множество аллофнов. Фонема может быть отражением как одной буквы, так и их сочетания.
Аллофон — вариация фонемы в зависимости от окружения. В отличие от фонемы, является не абстрактным понятием, а конкретным речевым звуком. Например, фонема <а> имеет следующие аллофоны: (а) — в слове пат, (а·) — в слове мать, (•а) — в слове пятый и т.д.
Дифон — сегмент речи между серединами соседних фонем. В отличие от аллофона, границы которых совпадают с границами гласных или согласных звуков, дифон представляет собой такие звуковой элемент, начало которого находится примерно посередине одного гласного или согласного звука, а конец — примерно посередине следующего.
Полуфон — сегементы речи, у которых одна из границ совпадает с границей аллофона, а другая — с границей дифона.
- Конкатенативный синтез (unit selection) — заранее готовится база дифонов и полуфонов, которые потом склеиваются между собой. Недавнно на хабре как раз вышла статья о самом известном подобном синтезаторе на русском языке;
- Параметрический — вычисление на основе текста набора акустических признаков, по которым генерируется аудио сигнал. Естественно, что самым популярным представителем параметрического метода являются нейронные сети.
Итак, для создания нашего синтеза было решено использовать параметрический подход, а значит, перед нами встал вопрос, какую архитектуру использовать. После непродолжительных поисков выбор был сделан в пользу Tacotron 2 по ряду причин:
- Популярная архитектура, хорошо справляющаяся со своей задачей. Её рекомендацией являлись, как минимум, её использование банком Тинькофф для своего чат-бота Олега (см. статью выше), а также неявные намёки на её использование у Яндекса.
- Конечно же ещё одной немаловажной причиной стало то, что NVIDIA любезно предоставила свою реализацию Tacotron 2 (репозиторий) с её же вокодером Waveglow (статья, репозиторий), и всё это на pytorch (мы симпатизируем ему больше, чем tensorflow и keras).
Так как сперва нашей задачей было обучение синтеза для русского языка, и собственным набором данных мы ещё не обзавелись, естественно, что для начала работы мы взяли единственный (на тот момент) приемлемый датасет для обучения синтеза на русском языке — RUSLAN (прим. автора: есть подозрение, что это не имя диктора, а акроним от RUSsian LANguage).
Какие проблемы сразу же бросаются в глаза (в уши) при синтезе после обучения на оригинальном датасете с помощью кода NVIDIA:
- Проскакивает случайная простановка ударений даже в тех словах, где ударение единственно возможное
Многие члены моей семьи любили ходить в зоопарк и наблюдать за тем, как едят слоны.
Также попадается озвучка графем, а не фонем («синтез» вместо «синтэз»)
Синтез речи — это увлекательно
- Нестабильность механизма внимания (который занимается, грубо говоря, выявлением соответствия символов входного текста и фреймов мел-спектрограммы), особенно на длинных входных текстах. Такая нестабильность, а другими словами, разрыв линии внимания, как на картинке:
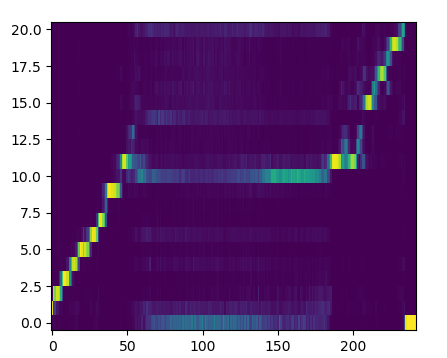
приводит к появлению различных артефактов в речи
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
- Нестабильность срабатывания гейт слоя, генерирующего сигнал об окончании генерации
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
- Все предыдущие моменты касались движка синтеза (так мы называем Tacotron 2 у себя), а что касается самого датасета, то там можно отметить плохие условия записи диктора — слышите это эхо?
Разберём, как мы боролись с каждым из этих пунктов.
Случайная простановка ударений и озвучка графем
Понятное дело, что для устранения этих недостатков надо правильным образом подготовить текст и обучать модель уже на нём, используя какой-то nlp-препроцессор. Начнём с того, как готовились данные.
Данные
Вот тут-то нам и пригодился наш отдел разметчиков: чтобы проставить ударения, над текстом трудились 5 разметчиков в течение двух недель. Результат — полностью размеченный ударениями датасет Руслан (ссылку см. ниже), который мы предоставляем сообществу для экспериментов. Но это касается только обучения, а что с инференсом? Тут всё просто: мы нашли словарь ударений (сначала аналог CMU dict для русского языка, а потом полную акцентуированную парадигму по А.А. Зализняку). Дальше нужно было подготовить код для использования этого словаря, и вуаля — получаем контроль ударений для нашей системы синтеза.
Что касается более естественного озвучивания с помощью фонем, то мы рассматривали два репозитория для решения этой задачи: RusPhonetizer и russian_g2p. В итоге, первый не завёлся, второй оказался слишком медленным (0.24 секунды на предложение из 100 символов), а тут ещё и CMU словарь содержит не только ударения, но и фонетические записи слов, так что решили использовать его. Честно сказать, из-за отсутствия чёткого понимания, какие же всё-таки фонемы нужны, работа с этим словарём вылилась в обычную транслитерацию текста с периодически встречающейся редуцированной «о». Сейчас мы экспериментируем с фонетизатором на основе фонем из russian_g2p.
NLP-препроцессор
Для работы со словарями и конвертацией текста в фонемный вид пакет text из оригинального репозитория такотрона уже не подходил, так что был заведён отдельный репозиторий для преподготовки текста. Опуская все подробности его разработки, резюмируем, каким функционалом он обладает на сегодняшний день:
- единый пайплайн обработки, принимающий на вход отдельные модули, производящие свои собственные операции над текстом;
- два готовых модуля для работы со словарями (ударник и фонетизатор);
- методы модулей для разбиения текста на различные составляющие;
- потенциал расширения арсенала модулей предобработчиков для русского и других языков.
Документация к репозиторию пока что находится в разработке.
Примеры
Контроль ударений:
Мн+огие чл+ены мо+ей семь+и люб+или ход+ить в зооп+арк и наблюд+ать за тем, как ед+ят слон+ы.
Тв+орог или твор+ог, к+озлы или козл+ы, з+амок или зам+ок.
Фонемы вместо графем:
Пример контроля фонем придётся показать на другом дикторе — Наталье — часть датасета которой вместе с весами (обычными, не фонемными) мы также выкладываем в открытый доступ (см. ссылку ниже).
Заодно приведём ещё пару синтезированных на open source модели примеров:
Съешь же ещё этих мягких французских булок да выпей чаю.
Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства.
В чащах юга жил бы цитрус? Да, но фальш+ивый экземпляр!
Нестабильность механизма внимания
Решение этой проблемы потребовало изучения статей по теме и имплементацию методик, представленных в них. Вот что мы нашли:
- Diagonal guided attention (DGA) — здесь идея простая: так как в синтезе, в отличие от машинного перевода, соответствие выходов энкодера и декодера последовательное, то есть система воспроизводит звуки по мере их появления в тексте, то давайте штрафовать матрицу внимания тем больше, чем больше она отступает от диагонального вида. Можно, конечно, возразить, «а что если звук тянется и на линии внимания появляется полка», но мы решили не рассматривать подобные экстремальные случаи. В качестве бонуса получаем ускорение процесса схождения матрицы внимания;
- Pre-alignment guided attention — в этой статье изложен более сложный подход: требуется с помощью стороннего инструмента (например, Montreal-Forced-Aligner) получить временные метки каждой фонемы на аудиозаписи и составить из них матрицу внимания, которая будет являться для системы целевой;
- Maximizing Mutual Information for Tacotron — авторы статьи утверждают, что подобные артефакты в матрице внимания возникают из-за недостаточной связи декодера с текстом. Для укрепления этой связи вводится модуль примитивного предсказания текста из итоговой мел-спектрограммы (эдакая asr в миниатюре) и расчёт ошибки с помощью CTC. Также ускоряет сходимость матрицы внимания.
После проведённых экспериментов можем сказать, что первый вариант определённо выигрывает по соотношению (положительный эффект/затраченные усилия). В качестве доказательства приведём запись, синтезированную моделью, обученной с DGA, из текста длиной 560 символов (без учёта токенов ударения) без его разбиения:
Все смешалось в доме Облонских. Жена узнала, что муж был в связи с бывшею в их доме француженкою-гувернанткой, и объявила мужу, что не может жить с ним в одном доме. Положение это продолжалось уже третий день и мучительно чувствовалось и самими супругами, и всеми членами семь+и, и домочадцами. Все члены семь+и и домочадцы чувствовали, что нет смысла в их сожительстве и что на каждом постоялом дворе случайно сошедшиеся люди более связаны между собой, чем они, члены семь+и и домочадцы Облонских. Жена не выходила из своих комнат, мужа третий день не было дома.
Как видите, на протяжении всей записи движок уверенно держал своё внимание: фраза не «разваливается», не возникает артефактов и мычания.
Нестабильность срабатывания гейт слоя
Напомним, что гейт слой отвечает за остановку генерации, и если он не сработает, то декодер будет продолжать генерировать фреймы, пока не достигнет лимита по шагам декодинга. Это выливается в продолжительное мычание в конце предложения, что забавно, но мешает презентовать свой синтез заказчикам.
Эта проблема решается несколькими небольшими уловками:
- Символ EOS вводится для каждого предложения, даже если у него в конце уже проставлен знак препинания из набора [».»,»!»,»?»];
- В конце каждой аудиозаписи добавляется небольшой участок тишины;
- При расчёте функции потерь для гейт слоя нужно увеличить вес его положительных выходов, чтобы они играли бОльшую роль.
Все вышеперечисленные ухищрения присутствуют в нашем репозитории движка, который мы выложили в открытый доступ (об этом ниже).
Некачественный датасет
Нам повезло, что в команде есть человек, увлекающийся музыкой, так что для облагораживания датасетов, в частности Руслана, мы вручную подбирали параметры различных фильтров и обрабатывали ими аудиодорожки в Logic Pro X. Ниже можете прослушать примеры оригинального и прошедшего обработку Руслана:
Также стоит отметить, что в датасете немного почищена пунктуация, так как движок реагирует на неё весьма чувствительно.
После решения всех насущных вопросов встала задача улучшить и разнообразить звучание, придать ему изюминки. Любой знакомый с темой скажет «Ок, посмотрите в сторону GST и VAE [ссылка раз, ссылка два]», и мы посмотрели.
Введение в пайплайн GST, на субъективный слух автора, не давало каких-то особых запоминающихся изменений, пока мы не попробовали подход, описанный в Text predicted GST — предлагается модели самой подбирать комбинацию стилистических токенов, чтобы добиться лучшего звучания для текущего текста. Для демонстрации работы этого модуля приведём аудио, полученные моделью, которая обучалась на датасете реплик персонажей из популярных зарубежных сериалов (актриса озвучки Екатерина). Уточним, что датасет изначально не предназначался для синтеза.
В общем, как и в жизни: главное найти подход к человеку.
Что касается использования вариационных автоэнкодеров, то эксперименты пока продолжаются, и похвастаться на данный момент нечем, так как столкнулись с определёнными проблемами. Если интересны технические детали — прошу под спойлер.
Проблема posterior collapse (KL loss vanishing), характерная для вариационных моделей в сочетании с авторегрессионным декодером.
В начале обучения, декодер может отставать от вариацинного энкодера и научиться игнорировать неосмысленные латентные переменные, что приводит к почти нулевой ошибке KL для VAE (расстояние Кульбака–Лейблера). Апостериорная оценка латентной переменной p (z|x) ослабевает и становится неотличимой от априорного Гауссовского шума p (z) ~ N (0, 1). Как следствие, вариационный энкодер не моделирует значимые свойства аудио и модель не предоставляет контроль над стилем и эмоцями речи.
Для борьбы с posterior collapse были опробованы уменьшение веса ошибки KL с его монотонным увеличение в процессе обучения, а также не учёт ошибки в начале обучения, равносильный игнорированию вариационных свойств модели и обучению стандартного автоэнкодера. Оба способа, в теории, позволяют декодеру сначала научиться синтезу речи и замедляют обучение вариационного автоэнкодера, повышая общую стабильность модели.
К тому же, так как мы часто слышали вопрос «А можно ли управлять скоростью и высотой тона речи?», мы добавили небольшой инструментарий для проведения этих операций на сгенерированных записях.
В тексте неоднократно упоминалось, что мы выложили в открытый доступ часть своих наработок по синтезу. Вот их список:
- sova-tts-engine — движок на базе Tacotron 2 от NVIDIA. Всё вышеперечисленное, за исключением text predicted GST и VAE, было опубликовано в этом репозитории, плюс проведён избирательный рефакторинг кода;
- sova-tts-tps — тот самый nlp-препроцессор;
- sova-tts-vocoder — практически не изменённый вокодер от NVIDIA, но всё-таки с отличиями;
- sova-tts-binding — пакет для связывания nlp-препроцессора, движка и вокодера в единый инференс-пайплайн. Реализован с прицелом на добавление новых движков и вокодеров;
- sova-tts — упакованный в докер стенд синтеза с простеньким GUI интерфейсом;
- Почищенный датасет и веса Руслана (This work, «SOVA Dataset (TTS RUSLAN)», is a derivative of «RUSLAN: Russian Spoken Language Corpus For Speech Synthesis» by Lenar Gabdrakhmanov, Rustem Garaev, Evgenii Razinkov, used under CC BY-NC-SA 4.0. «SOVA Dataset (TTS RUSLAN)» is licensed under CC BY-NC-SA 4.0 by Virtual Assistant, LLC)
- Датасет и веса Наталии («SOVA Dataset (TTS Natasha)» is licensed under CC BY 4.0 by Virtual Assistant, LLC)
Наш SOVA TTS (весь код + модель и датасет Наталии) вы можете свободно использовать для коммерческих задач бесплатно.
Планы у нас грандиозные, а именно:
- Полноценный нормализатор текста для раскрытия чисел, аббревиатур и сокращений;
- Модуль для решения неоднозначностей в ударениях и словах с буквой «ё»;
- Добавление поддержки ssml;
- Дальнейшие эксперименты с VAE, получение контроля над отдельными словами и фонемами;
- Подготовка эмоционального синтеза, по возможности с контролем уровня эмоции;
- Мультидикторный синтез на одной модели;
- Новые голоса;
- Клонирование голоса;
- Возможный переход на более современные архитектуры типа Flowtron или FastSpeech2;
- Эксперименты с вокодерами: дообучение Waveglow, обучение LPCNet, тестирование MelGAN;
- Оптимизация архитектуры для работы в реальном времени на CPU.
На текущий момент мы продолжаем двигаться в сторону улучшения качества синтеза речи. Если то, что мы делаем, вам интересно — пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Все наши наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Синтез речи: SOVA TTS
Спасибо за внимание, впереди еще много интересного!
