Новые модели поиска и анализа данных. WSDM 2020 глазами команды Яндекс.Толоки
Международные научные конференции помогают следить за трендами в индустрии, узнавать о передовых разработках ведущих компаний, университетов и рассказывать о себе. Конечно, это относится только ко времени, когда мир не погружён в пучину пандемии.
До того, как все страны перешли на режим самоизоляции, мы командой Яндекс.Толоки успели съездить на конференцию WSDM (произносится как wisdom), чтобы провести туториал по краудсорсингу, презентовать нашу статью и пообщаться с коллегами по цеху.
Меня зовут Алексей Друца, я руководитель отдела эффективности и развития управления краудсорсинга и платформизации в Яндексе. В компании занимаюсь теоретическими и прикладными исследованиями в областях, связанных с дискретными алгоритмами, теорией аукционов, машинным обучением, анализом данных и вычислительной математикой. За время работы я опубликовал более 20 научных статей, в том числе в рамках конференций NIPS, KDD, WWW, WSDM, SIGIR и CIKM. В этом посте расскажу о своих впечатлениях после посещения WSDM, а также сделаю небольшой обзор самых интересных докладов.

Плакат конференции
Что за конференция?
WSDM — одна из главных конференций по научным исследованиям, связанным с поиском и анализом данных. В этом году она стала тринадцатой по счёту и проходила с 3 по 7 февраля в Хьюстоне, штат Техас.
Немного статистики. В конференции участвовали около 700 человек. Авторы 615 научных работ подали заявки, чтобы получить возможность презентовать свои статьи на конференции. Организаторы выбрали 91 статью, в том числе нашу работу про сбор краудсорсинговых данных. Из 20 заявок на проведение туториалов организаторы WSDM приняли 9, включая заявку Яндекса.
Главной частью конференции стала стендовая сессия. На всех подобных научных мероприятиях это основной способ представить работы: авторы принятых статей готовят плакаты с исчерпывающей информацией об исследовании и отвечают на вопросы заинтересованных коллег (подробнее о формате). Помимо стендовой сессии участники могли рассказать о своих достижениях в трёх форматах:
- 5-минутный доклад о работе (эту возможность получили 46 участников);
- lightning-talk на 60 секунд с кратким рассказом основной сути доклада (такой формат был предложен 45 участникам);
- демо с демонстрацией работы того или иного инструмента.
Среди опубликованных на конференции работ была статья и от нашей команды. Она также про краудсорсинг, но в ней идёт речь о другом источнике краудсорсинговых данных — собранных через капчу.
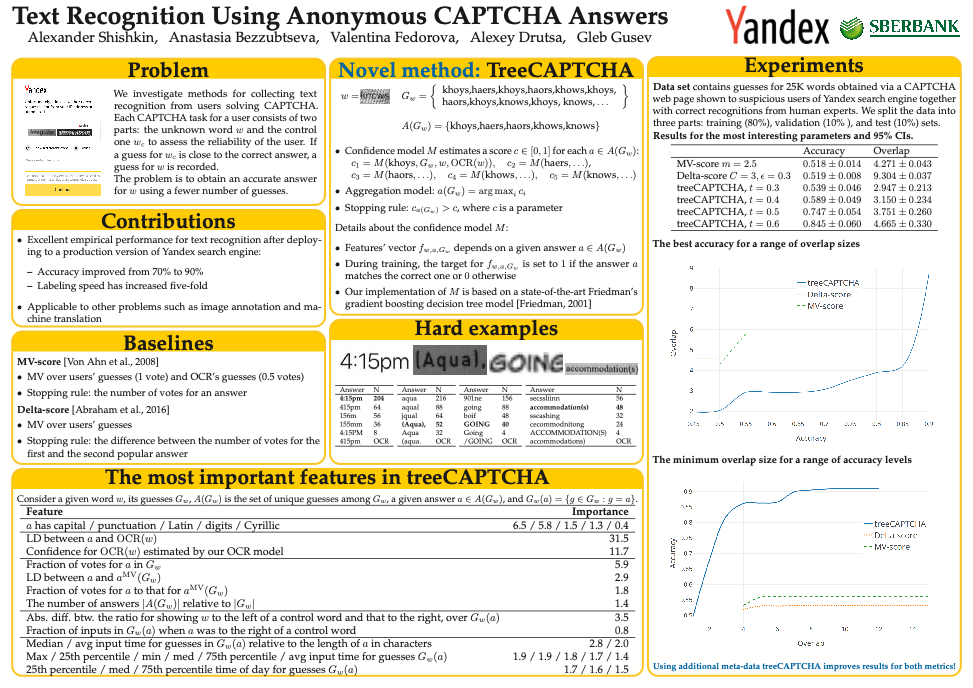
Постер нашей статьи
Метод сбора разметки с помощью капчи давно известен и используется многими компаниями. Работает это так: подозрительным пользователям предлагается ввести текст с двух картинок. Первое изображение — контрольное, у нас уже есть правильный ответ для него. Второе изображение содержит неизвестный нам текст, его мы как раз хотим расшифровать с помощью пользователя. Если человек вводит правильный текст с первой — контрольной — картинки, то мы считаем его достаточно надёжным и записываем себе его второй ответ.
Это очень удобный, масштабируемый и бесплатный способ разметки. Но есть проблема: капча обычно предлагается подозрительным пользователям, часть которых является ботами. При расшифровке картинок такими роботами мы часто получаем похожие, согласованные ошибки. Люди, в отличие от ботов, редко ошибаются в одной и той же букве.
Обычно компании, использующие этот метод разметки, считают корректным тот ответ, который дали большинство пользователей. Но с учётом высокой вероятности допущения похожих ошибок ботами такая схема приводит к получению неверных данных.
Мы же обучили ML-модель, которая по факторам ввода капчи предсказывает, какой ответ будет наиболее корректным. С полным содержанием статьи можно познакомиться здесь.
А что про туториал?
В самый первый день конференции мы провели практический туториал на основе Яндекс.Толоки. Мои коллеги уже рассказывали про наш сервис на Хабре, его подробное описание вот здесь. Если коротко, Толока — это краудсорсинговая платформа, которая помогает выполнять множество задач. С помощью Толоки можно расшифровывать аудиозаписи, проводить фокус-группы, модерировать комментарии или распознавать картинки, используя полученные данные для машинного обучения.
Среди туториалов на WSDM только наш проходил в течение всего дня.

Перед туториалом
Мы рассказали, как правильно решать задачи с помощью краудсорсинга. Чтобы эффективно размечать данные с помощью этого способа организации рабочего процесса, нужно не просто дать людям задание, а правильно декомпозировать, верно сформулировать задачу и настроить процессы, например, контроль качества. Часть информации, которой мы делились с участниками конференции, можно найти в нашем опубликованном видео-курсе. В нём базовая теория краудсорсинга показана на примере решения задачи о сегментации объектов на изображении.
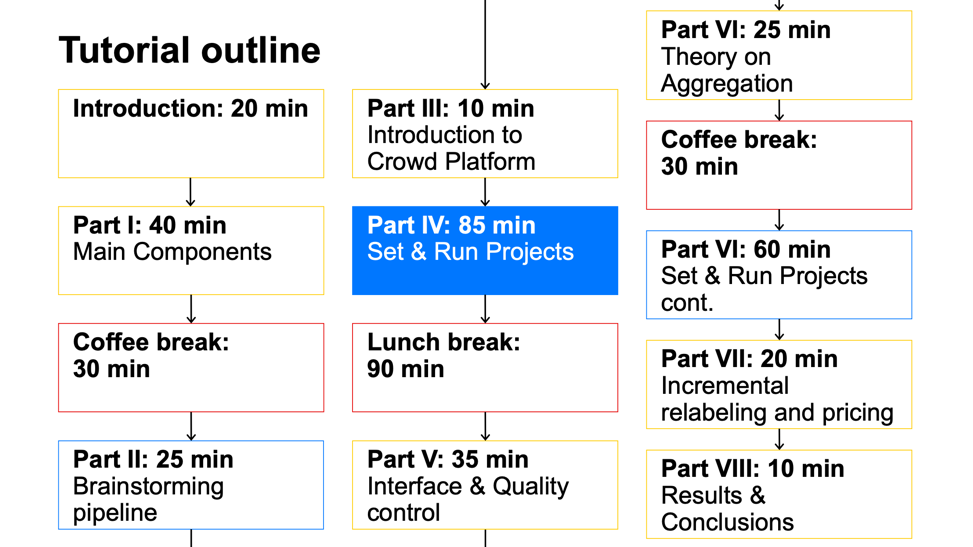
Программа туториала
Для конференции мы специально придумали пайплайн, который включал в себя классификацию, сбор данных в интернете, пост-приемку и сравнения бок-о-бок. Он состоял из четырёх этапов. Участники туториала представляли себя в роли владельцев онлайн-магазина одежды. Они брали картинку, выбирали на ней какой-то элемент одежды (например, ботинки) и давали толокерам задание найти в базе магазина самые похожие товары. Затем эти товары ранжировались по похожести другими толокерами.
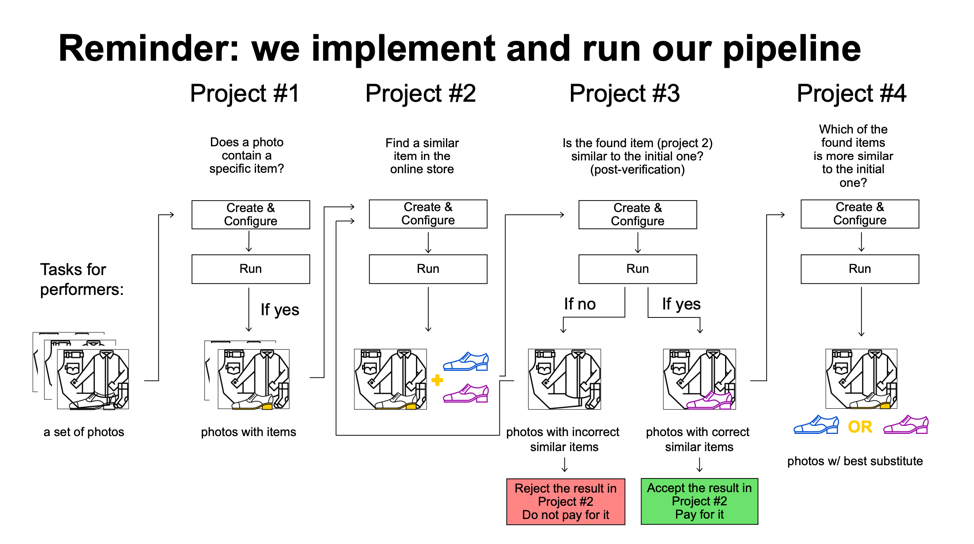
Этапы пайплайна
В конце дня после появления результатов все участники получили обратную связь и практические советы, призванные помочь сделать каждый проект более эффективным.
Например, в реальном мире некоторые шаги нашего пайплайна можно было бы, ориентируясь на имеющиеся данные, автоматизировать с помощью API. Но на конференции нам важно было показать, как каждый из этапов можно обработать именно с помощью краудсорсинга — эффективно и масштабируемо.

Что ещё можно сделать, чтобы получать лучшие результаты и тратить меньше денег
Практически все участники туториала прошли его полностью, дойдя до самых последних шагов. Они научились собирать датасет из похожих товаров онлайн-магазина с помощью краудсорсинга. Разобранный нами на туториале пайплайн достаточно универсальный, он может применяться не только в интернет-торговле, но и в любой индустрии, где нужно предлагать похожие объекты.
О чём рассказывали другие компании?
Полный список опубликованных работ можно найти на сайте конференции.
Мы отметили большое количество работ, связанных с рекомендательными системами поиска и сферой e-commerce. На наш взгляд, большинство команд не предлагали новые научные теории, а представляли результаты внедрения в продукт тех или иных технологий. Было много докладов про решения на основе нейросетей — авторы рассказывали, какие именно библиотеки для этого применялись.
Вот несколько постеров, которые привлекли наше внимание, с комментариями:
• CrowdWorker Strategies in Relevance Judgment Tasks
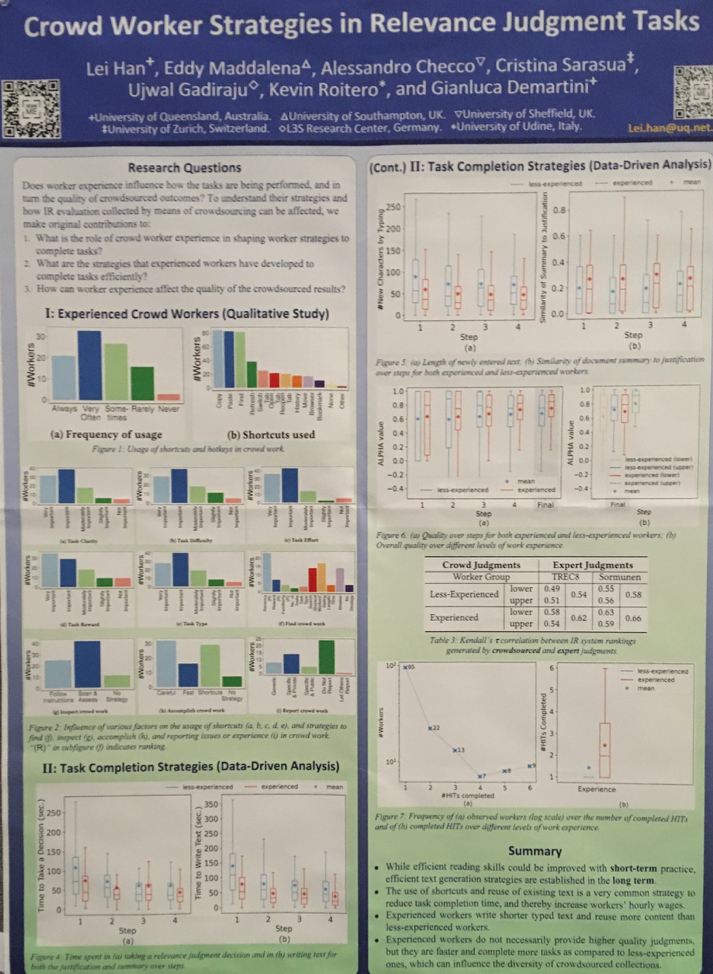
Постер работы CrowdWorker Strategies in Relevance Judgment Tasks
Эта работа заинтересовала нас своей темой. Авторы рассказывают о том, как опыт исполнителей в краудсорсинге влияет на их поведение: клики по заданиям, использование горячих клавиш, время выполнения.
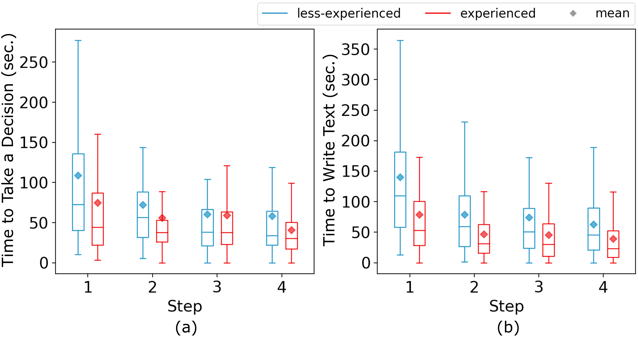
Разница во времени выполнения задач между более и менее опытными исполнителями
После проведённого эксперимента авторы работы выяснили, что уже после двух выполненных на краудсорсинговой платформе заданий менее опытные работники достигают сравнимой с опытными скорости выполнения.
Общий вывод: при наличии способов контроля качества выполнения задач опыт исполнителей сильно не сказывается на итоговом качестве данных.
• Predicting Human Mobility via Attentive Convolutional Network

Постер работы Predicting Human Mobility via Attentive Convolutional Network
Эта статья про предсказание маршрута пользователя — точки, в которой он окажется в будущем. Большинство таких методов предсказания работает с GPS-координатами, а авторы этой работы сконцентрировались на геотегах в социальных сетях.
Авторы работы рассматривают траектории пользователей как картинки и используют для них фильтры. У каждой картинки в качестве показателей получаются последовательные паттерны. Также к этой нейросети добавляется механизм внимания, чтобы учитывать долговременные предпочтения.
Авторы провели эксперименты на трёх датасетах и заключили, что их модель работает лучше, чем существующие модели с GPS-координатами.
• Metrics, User Models, and Satisfaction
Авторы работы изучили, как связаны метрики, описывающие поведение пользователей поисковой системы, с их удовлетворенностью.
Постер работы Metrics, User Models, and Satisfaction
Они подтвердили, что метрики с пользовательскими моделями, которые отражают типичное поведение, также имеют тенденцию быть метриками, которые хорошо коррелируют с оценками удовлетворенности пользователей.
• Hierarchical User Profiling for E-commerce Recommender Systems
Постер работы Hierarchical User Profiling for E-commerce Recommender Systems
Авторы работы решают задачу рекомендаций для разных уровней детализации.
Предложенная ими иерархическая структура профилирования пользователей моделирует многоуровневые интересы пользователей с помощью Pyramid Recurrent Neural Networks, которые обычно состоят из микрослоя, слоя элементов и нескольких слоев рекуррентных нейронных сетей категорий.
Что в итоге?
Эта конференция будет полезна специалистам, которые занимаются улучшением поиска.
Перед посещением WSDM и любой другой конференции мы советуем внимательно изучать программу и принятые работы — это поможет не просто растерянно бродить между постерами, воркшопами и выступлениями, а пообщаться с авторами заинтересовавших проектов.
А ещё не забывайте, что все работы есть в сети, и вы можете изучить их самостоятельно. Это, кстати, отличный способ с пользой провести свободное время.
