Новые инструменты для работы c ML-моделями и обзор MLOps от CERN

Привет всем, кто работает с ML-моделями и занимается аналитикой данных! В новом дайджесте для вас много интересных обзоров по инструментам — как говорится, ни ClearML и Airflow едиными. Рынок решений стремительно развивается, и наши подборки помогут вам держать руку на пульсе. Еще больше полезных текстов по DataOps и MLOps публикуем в Telegram-сообществе «MLечный путь».
Как вам, кстати, ренессансная GPU на обложке, которую сгенерила нейросеть для блога Andreesen and Horowitz? Что тут сказать — просто поделитесь промтом.
Используйте навигацию, чтобы перейти к интересующему вас блоку:
→ Теория
→ Практика
→ Исследования
→ Мнение
→ Инструменты
Теория
The Map Of Transformers
На Medium вышел подробный лонгрид по Transformer-архитектуре нейронных сетей. Объем и содержание текста впечатляет. Здесь и таксономия, и математика, и пояснительные визуализации. Если хотите разобраться в технологии, этот лонгрид точно займет вас на ближайшие несколько дней.
91% of ML Models Degrade in Time
В статье перевели на человеческий и разобрали результаты исследования о времени деградации моделей. Исследование провели уважаемые ученые из MIT, Гарварда, Кембриджа, Университета Монтеррея — ссылка на первоисточник прилагается. В тексте приведены все графики и пояснения к ним. Особенно интересно почитать про типы возникающих проблем и рекомендации, как выстроить работу с ML-моделями, чтобы не стать жертвой их деградации. Например, авторы рекомендуют ставить оповещения на момент, когда пора переобучать модель. Или разработать/внедрить эффективный и надежный механизм автоматического переобучения моделей (привет, MLOps!).
How Shadow Data Teams Are Creating Massive Data Debt
В этой статье разбирают типы аналитических команд: централизованные, децентрализованные и теневые. Фокус в тексте делается на последнем. Теневые команды не занимаются полноценным дата-инжинирингом — скорее «костылят» и копят технический долг. Они появляются, когда бизнес нанимает еще одну команду аналитиков (скорее даже дата-сайентистов) в добавок к основной с целью уменьшить time to market для новых фичей и моделей. Лично у меня появляется вопрос, как сохранять баланс между скоростью получения данных и их качеством. Возможно, про это расскажут в следующей части статьи. Бонусом автор рассматривает, как поменялись аналитические системы за последние два десятилетия, и, что самое интересное, описывает, какие их элементы практически не поменялись.
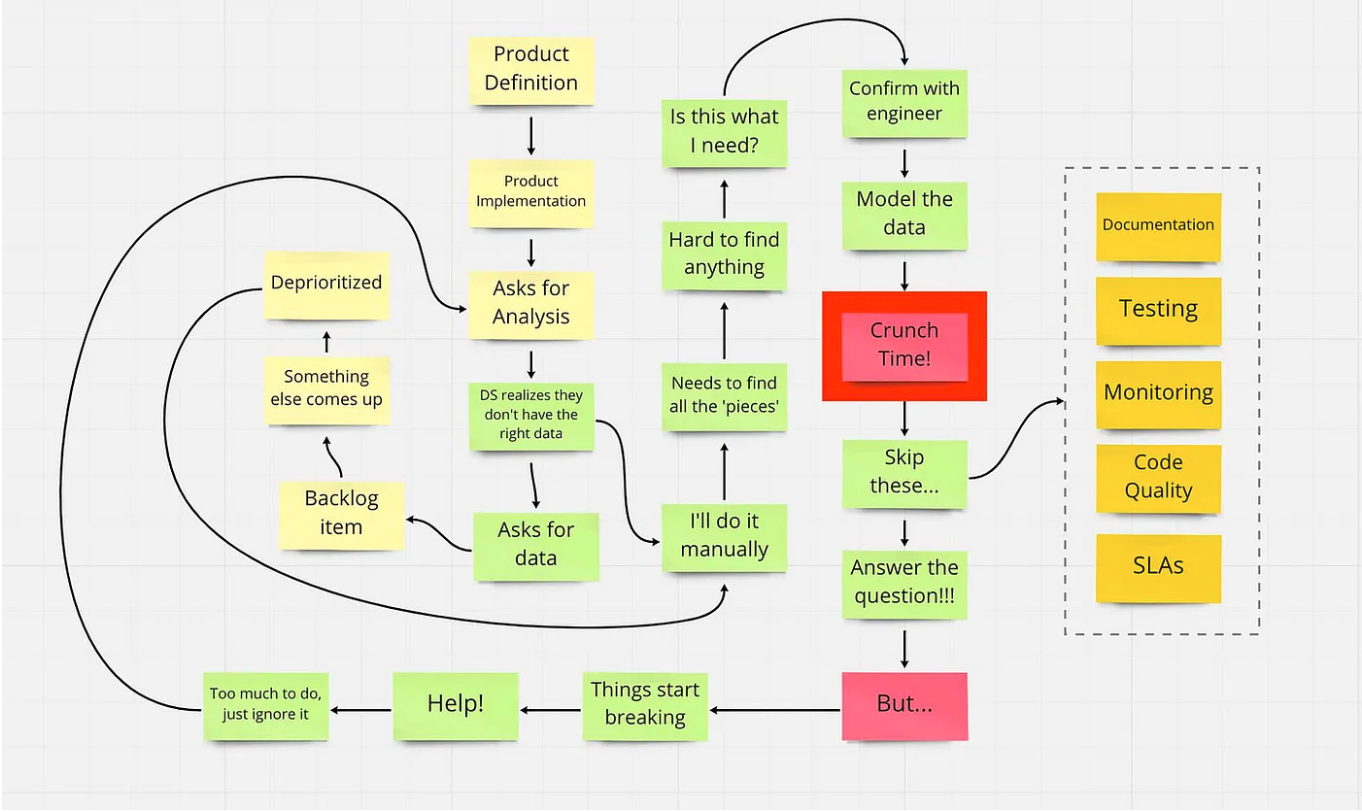
Порочный круг работы дата-сайентиста. Источник
Incident management for data teams
В тексте подробно и с картинками рассказывают про работу с инцидентами в аналитических командах. В целом, отличий от аналогичной работы в других сферах мало. Сначала выявляем, потом сообщаем о фактах и выясняем корневую причину. Исправляем и делаем выводы, в идеале — улучшаем процессы. Но, как и везде, есть свои нюансы.

Практика
Несите трубы! Как мы строили пайплайн ML-эксперимента
Время текстов с Хабра. На этот раз был замечен кейс коллег из «Контура» — в ряде продуктов они используют ML-модели. В тексте с неоновыми котиками на обложке довольно четко и толково расписали структуру пайплайна. Особенно интересно, что используют ClearML, кластер Ceph и ONNX. Про последний мы писали в обзоре инструментов для ускорения вывода ML-моделей в продакшен.
Apache Druid, TiDB, ClickHouse, or Apache Doris? Comparing the OLAP Tools We Have Used
А тут у нас представлен кейс от производителей автомобилей NIO из Китая. У них история, которую я где-то уже видел: эволюция аналитического стека, который завершился хэппи-эндом с использованием СУБД Apache Doris. При этом стадии эволюции «Druid → TiDB → ClickHouse → Doris» мне точно встречались в статьях других компаний из поднебесной. Можно ли рассматривать это как тенденцию? Как бы то ни было, ребята описали плюсы и минусы использования каждой СУБД конкретно в их кейсе — может, кому-то пригодится.
Как устроен massively parallel processing (MPP) в Trino
Коллеги из CedrusData, которые разрабатывают аналитическую систему на основе Trino, рассказали про MPP, или массивно-параллельные вычисления. Собственно, сам Trino — это распределенный аналитический SQL-движок для выполнения федеративных запросов. На его примере нам и предложено погрузиться в тему и основные принципы работы этого класса инструментов.
Исследования
Survey: Massive Retooling Around Large Language Models Underway
Компания Arize AI провела исследование вокруг Large Language Models (LLM). Выяснилось, что 53,5% респондентов планируют добавить LLM в прод в ближайший год. Это, в свою очередь, может подстегнуть развитие MLOps и культуры проектирования ML-систем. Ведь LLM руками из Jupyter в прод не закатишь. Ну и prompt engineering тащит за собой среду разработки LangChain или векторные БД.
Navigating the High Cost of AI Compute
Не ожидал увидеть такой текст в блоге венчурного фонда Andreesen and Horowitz, но хайп есть хайп. Умные аналитики провели исследование и прикинули стоимость владения LLM. Помимо всего, в статье есть обзор провайдеров с ценами и рассуждения о тяжкой доле финансовых директоров. Жирным выделена фраза: There is no sign that the GPU shortage we have today will abate in the near future (дословно: «Нет никаких признаков того, что нехватка графических процессоров, которая у нас есть сегодня, снизится в ближайшем будущем»).
The Data Streaming Landscape 2023
Отличное исследование инструментов для реализации потоковой обработки данных. По сути получилось подробное описание экосистемы вокруг Kafka и разных способов ее потребления — от self-hosted до PaaS и SaaS. Есть описание решений разных вендоров и альтернатив Kafka, а еще много красивых схем и картинок.
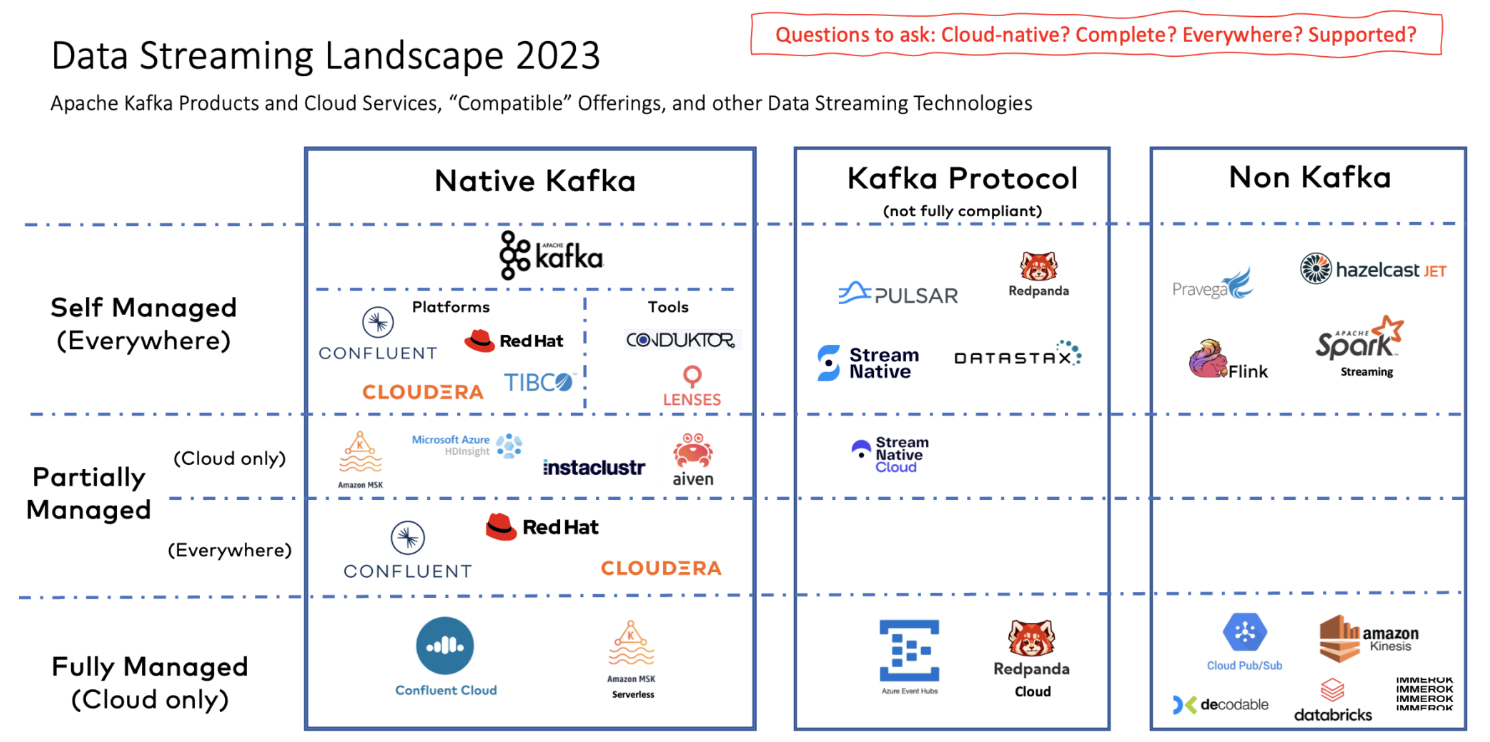
Landscape приложений для потоковой передачи данных. Источник
Мнение
ChatGPT, ZeroETL, and Other Data Engineering Disruptors
Автор текста начинает с того, что практически заявляет: если плохо относитесь к изменениям — в дата-инженеры вам не надо. Ведь они постоянно сталкиваются с изменениями, инновациями и изобретанием велосипедов. Собственно, о велосипедах (зачеркнуто) инновациях и речь в тексте. В качестве самых свежих трендов рассматриваются три:
- «Нулевой» ETL,
- Большие языковые модели над одной широкой таблицей с корпоративными данными,
- Контейнеризация дата-продуктов (прости господи).
Очень интересно, но не все до конца понятно.
Pro GPU System vs Consumer GPU System for Deep Learning
Если любите всякие тексты-сравнения, то вот он перед вами. Автор сравнивает между собой несколько моделей GPU: GTX 1070, Tesla T4, RTX A6000 и две RTX A6000. Методика тестирования устроит не всех, но докапываться до чисел, кажется, нет смысла. У нас на Хабре тоже, кстати, был текст, где мы сравнивали десктопные и серверные модели видеокарт — он хотя бы на русском языке, если для вас это важно.
Выводы в тексте на Medium достаточно ожидаемые:
- если нужно много памяти, то нужны профессиональные карты,
- если нужно уменьшить потребление при масштабировании, то нужны профессиональные карты,
- если задачи не требуют большого объема памяти, обычных GPU достаточно.
Добавим в эту копилку еще несколько советов. Если нужно одновременно выполнять несколько задач на GPU, то нужны профессиональные карты (MIG, Time Slicing). А если нужно делить GPU на виртуальные кусочки, то нужны профессиональные карты и лицензии GRID.
Dashboards are dead: 3 years later
Под кликбейтным заголовком — продолжение поста трехлетней давности про переоцененность дашбордов. Предыдущий текст получил много внимания, и автор решил повторить успех. Как обычно бывает под такими заголовками, никто не умер, но есть некие предпосылки для того, чтобы перестать использовать дашборды как стандартный способ коммуникации аналитиков с бизнесом.
В эссе — мысли по поводу того, что дашборды — не всегда лучший способ донести информацию и ценность до бизнеса, а аналитики — не клепатели визуализаций. В общем-то, сложно с этим не согласиться.
Инструменты
Streamline Production ML With BentoML And Kubeflow
BentoML активно развивается и интегрируется со сторонними инструментами. Недавно решение научилось использовать Triton Inference Server, а теперь интегрировалось с Kubeflow 1.7. Собственно, в тексте как раз показан пример использования BentoML в связке с этой платформой. Теперь можно отказаться от KServe как инструмента из коробки!
Neptyne: The Programmable Spreadsheet
Следующий лот — Neptyne, очередная попытка переизобрести Excel/Google Sheets. На этот раз целевая аудитория — аналитики и дата-сайентисты, которые знают Python. Ключевая фишка продукта — возможность дополнять кнопки, доступные в интерфейсе, своими функциями. Например, затолкать набор ячеек в DataFrame, обработать с помощью Pandas или других библиотек и вывести в другой набор ячеек. Ну и куда без интерфейса для обращений к ChatGPT (или аналогичным сервисам)?
Introducing Data Prism, The Automatic Chart Builder
Знакомы ли вы с онлайн-аналогом Jupyter — Noteable? Недавно они выпустили автоматическую генерацию визуализаций по пользовательским датасетам. Выглядит это все пока не сильно впечатляюще, но сама идея неплоха. Посмотреть можно вноутбуке с примерами.
The Truth about Prefect, Mage, and Airflow
Автор сравнивает самый популярный, по его мнению, оркестратор Airflow с новыми аналогами — Prefect и Mage. В итоге для новых проектов советуетMage. Инструмент выглядит действительно интересно — эдакий Jupyter для пайплайнов. Причем писать можно как на Python и R, так и на SQL. Обратите внимание что доступ к тексту по ссылке платный, но есть бесплатная подписка на неделю — хватит, чтобы ознакомиться с текстом.
Build Elegant Web Apps Right From Jupyter Notebook with Mercury
Mercury — это еще одно решение для для того, чтобы «продуктолизировать» Jupyter-ноутбуки, превращая их в веб-приложения. В статье рассказывают, как работать с инструментом и что он вообще может. Разработчики пытаются обойти конкурента Streamlit по всем фронтам. Так, инструмент сразу интегрирован с Jupyter, умеет экспортировать PDF, может собирать презентации.
Quality Assurance for all AI models
Если вы ищете инструмент для тестирования ML-моделей, то есть тут что-то интересное — Giskard. Во-первых, это open source и self-hosted. Также решение поддерживает возможность создания собственных test suite и его можно интегрировать в довольно большое количество ML-инструментов. В основе — коллаборативная модель поиска слабых мест с возможностью комментирования.
Видео
Accelerating MLOps and CI/CD for tinyML on Arm
Время просмотра: 1 час 2 мин.
Познавательный вебинар от Эрика Сонди (Eric Sondi) — старшего менеджера в Arm (да-да, компании, которая разрабатывает процессоры на той самой архитектуре). В видео он рассказал про технологию Virtual Hardware и ближе к концу описал сценарии ее использования для MLOps. Показательно, что даже такие «железячники» уже начинают делать нативные решения для production ML.
MLOps: Going from Good to Great
Время просмотра: 51 мин.
Тексты по MLOps в нашей подборке уже становятся традицией. Что сказать — животрепещущая тема. При это каждый раз она раскрывается все хардкорнее. Как вам семинар о том, как развивают MLOps в CERN — знаменитом центре ядерных исследований? Это, конечно, не адронный коллайдер, но и тут без многоуровневых формул не обошлось. Самое то, если хотите почувствовать себя интеллектуально униженным.
Возможно, эти тексты тоже вас заинтересуют:→ 6 дисплеев, 192 ядра и 3 ТБ ОЗУ DDR5: на что способен «ноутбук» от Mediaworkstations и другие подобные системы
→ Что изменилось в инструментах OpenStack? Рассказываем о самых важных обновлениях в релизе Antelope
→ Как улучшать продукты, опираясь на мнение пользователей, или загадка плавающего IP-адреса
