Нотариусы, которые хранят кучу сканов 50 лет: выбираем хранилище на следующие лет 20–30

Приходят к нам нотариусы (в штате больше восьми тысяч человек). У них буквально каждый пользователь ежедневно грузит в корпоративный архив множество сканов и файлов, из-за чего этот самый архив стремительно разрастается. Все хранимые документы по требованиям регуляторов должны храниться не менее 50 лет, а некоторые — и дольше. Хотят новое хранилище для этого. Вводных совсем мало: для старта нужны два маленьких инстанса по 500 ТБ в двух разных ЦОДах и безлимитное масштабирование — в общем, всё выглядит хорошо. Вопрос только один: какое, собственно, хранилище выбрать?
Нам нужно было решить, что же им подойдёт лучше всего, то есть провести подбор решений и сравнить их. Начали мы с методологии — очень подробно собрали требования:
- Масштабируемое неограниченно (главная особенность — количество «холодных» данных будет постоянно нелинейно расти).
- Нечувствительное к потере частей, то есть катастрофоустойчивое и устойчивое к поломкам. Почти как хранилище на космический корабль.
- Способность экономически оправданно эволюционировать вместе с частями информационной системы, то есть в идеале — замена железа и обновление софта, а не переход к другим архитектурам и переносы в другие форматы хранения.
- Единообразный доступ к данным независимо от платформы исполнения.
Текущая инфраструктура развёрнута на двух площадках на расстоянии 10 км друг от друга. Стоят по две ленточные библиотеки, два драйва LTO 7, хранилище Oracle ZFS-2, дисковая полка. Дисковые хранилища используются для работы БД, ленточные хранилища — для хранения резервных копий. Для уменьшения объёмов БД необходимо редко запрашиваемые данные перемещать на более дешёвые и медленные устройства хранения с возможностью автоматического извлечения с доступом по API. Плюс централизованное управление конфигами и мониторинг.
В общем, пришлось немного почесать голову. Но выбор мы сделали, и сейчас это всё уже переходит в продакшн. Так что заходите в пост, обстоятельно расскажу, что и как.
Шаг 1: требования к системе
Первое, что нужно сделать, — это сформировать техзадание на хранилище. У заказчика его на самом деле нет, потому что они не знают финального состояния системы, которая будет эволюционировать десятилетиями. Мы тоже не знаем, но нам нужно получить хоть какой-то план, чтобы потом закладывать варианты отклонений от него.
До того как они решили делать объектное хранилище, они шли в сторону классического хранения на базе Oracle. Но в процессе стало понятно, что данные растут быстрее, чем это может обеспечить существующая система. В начале работ мы поехали на аудит площадки, и выяснилось, что они в целом не планируют идти дальше таким путём и подходы нужно менять.
Анамнез осложняется ПО собственной разработки, которое пишет сейчас в базу данных. Главный вопрос был в том, по каким протоколам с ним работать в будущем. К счастью, когда разработчики услышали знакомую фразу «S3», выбор быстро был сделан. Оставалось только выбрать зарекомендованное вендорское решение и оставить на первое время возможность переносить данные по стандартным файловым протоколам CIFS/NFS.
В результате были составлены довольно подробные требования для сравнения решений на рынке и выбора нужного варианта. Перечень приводить не буду, но интересующиеся могут запросить отдельно по почте в подписи.
Шаг 2: подбор вариантов реализаций на базе доступных на рынке вендоров с поддержкой
Сразу было поставлено условие, что система должна довольно долго поддерживаться и развиваться, поэтому нужно рассматривать только зарекомендованные и проверенные годами вендорские решения от крупных компаний, существующие не первый год и обладающие качественной техподдержкой. В связи с этим были выбраны три основных решения, существующие на рынке.
Первый вариант (от вендора А) — платформа для распределённого хранилища контента.
Она может быть разделена на множество виртуальных логических разделов (tenants), каждый из которых будет иметь свои пространства имён, хранить свои группы объектов со своими политиками хранения. Доступ к каждому такому разделу и объектам, так же как и управление ими, может осуществляться независимо.
Каждый хранящийся в системе файл представляет собой объект. Помимо самих данных, в системе хранятся различные метаданные — как системные, например, время создания, размер и срок хранения, так и пользовательские, которые могут формироваться пользователями или приложениями, оперирующими этим объектом. Подлинность хранящихся данных гарантируется специальными алгоритмами: при записи объекта в систему происходит расчёт хэш-функции этого объекта, после чего эта информация записывается в метаданные. Каждый раз при обращении происходит сверка хэш-функций. Механизм расчёта хэш-функций может быть сконфигурирован исходя из требований предприятия к стандартам шифрования.
Диски объединены в массив RAID-6 для сохранности данных при выходе из строя любых двух дисков в группе. Дополнительно для целостности информации и защиты от катастроф проводится периодический аудит хранящихся объектов и используются технологии репликации на уровне объектов через глобальную сеть. Срок хранения данных задаётся специальными политиками, которые позволяют определить критерии для сроков доступности объектов. Политики могут формироваться приложениями или пользователями, например, можно установить, что файлы определённого типа должны храниться определённый ограниченный период времени.
Система обеспечивает хранение нескольких версий одного и того же объекта, что, например, позволяет отслеживать весь жизненный цикл документа. Механизмы NENR (невозможность перезаписи и удаления) и WORM (одна запись, многократное чтение), которые можно задействовать, способны гарантировать неизменяемость объектов. Это важно для хранения информации, подлежащей нормативному регулированию.
Решение частично соответствует требованиям заказчика. Оно строится отказоустойчиво с дублированием данных и возможностью их последующей репликации, позволяет автоматически перемещать объекты внутри и вне системы в зависимости от частоты обращения к ним, а также обладает продвинутыми механизмами сжатия и дедупликации. Предполагает полноценный доступ по HTTP/REST API и обладает нужной масштабируемостью.
Но система не предусматривает подключения существующих библиотек в качестве архивного уровня хранения. Часть требований может быть выполнена только при использовании дополнительного ПО.
Второй вариант — объектное хранилище NetApp StorageGrid:
- Обеспечивает непрерывный доступ к данным в любое время.
- Устраняет физические границы хранения и поддерживает большие объёмы данных.
- Упрощает аварийное восстановление независимо от физического расположения.
- Поддерживает хранение данных в облаке.
- Поддерживает протоколы S3, Swift RESTful API, NFS, CIFS, HTTP/HTTPS.
Очень упрощая, весь сторедж грид — это в самом начале три сервака (или виртуалки) с подключёнными дисками, которые объединены в единую объектную СХД. И все данные размазаны между этими тремя узлами. Любой из этих трёх узлов может страдать, в них могут вылететь любые диски, но данные сохранятся. Может вылететь узел целиком, и всё продолжит работать.
SG использует четыре типа нод: Admin Node обеспечивает управление сервисами, например, системная конфигурация, мониторинг и логгирование, распределение трафика по Storage Node. Storage Node управляет объектным хранением и хранит метаданные, обеспечивая отказоустойчивость данных. API Gateway Node (опционально) выполняет роль балансировщика между разными приложениями и нодами хранения данных, разгружая админ-ноды. Archive Nodes (опционально) обеспечивает архивацию данных на ленты. NAS Bridge — виртуальная машина, которая позволяет использовать NFS/SMB-шары и конвертирует запросы в S3 API.
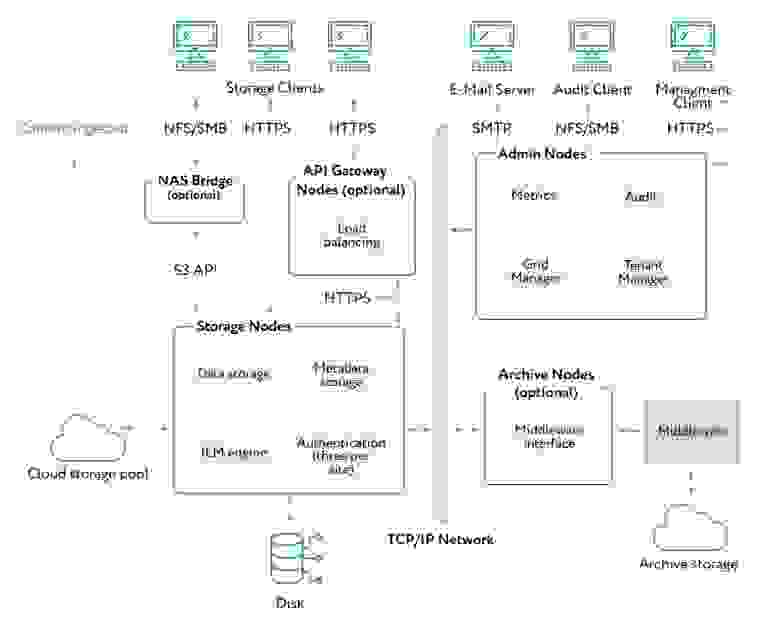
Возможно расположение на одной или на нескольких геораспределённых площадках.
Управление данными обеспечивается с помощью политик жизненного цикла (ILM, Information lifecycle management). Каждый объект, который попадает в систему SG, проверяется в соответствии с правилами и активной политикой ILM. Правила ILM по метаданным объекта определяют, какие действия предпринять при их хранении и копировании.
ILM-правило определяет расположение объекта, тип используемого хранилища, тип защиты от потери, применяемый к объекту (репликация или erasure coding), количество сделанных копий, изменения со временем расположения, хранения и защиты от потери.
Репликация — один из двух механизмов, используемых решением для хранения объектных данных. Когда оно с помощью ILM-правила определяет, что объект необходимо реплицировать, система создаёт копию объекта и сохраняет её на другую Storage Node.
Возможна репликация как на одной площадке на разные ноды в едином пуле, так и на разные площадки на разные ноды. Распределение по разным площадкам повышает катастрофоустойчивость.
Erasure coding — это ещё один способ хранения данных, альтернатива обычным копиям. Когда поступает объект, с помощью ILM-политики определяется, на сколько фрагментов он будет разделён, рассчитываются дополнительные парити-фрагменты и сохраняются на разные ноды. Когда происходит обращение к этому объекту, он собирается из фрагментов обратно.
Если фрагмент данных или парити будет испорчен или потерян, то алгоритм erasure-coding восстановит недостающий фрагмент и восстановит целостность данных. Принцип работы похож на RAID из дисков.
На рисунке показан пример работы алгоритма. На этом примере ILM-правило использует 6+3 erasure coding-схему. Каждый объект делится на шесть одинаковых фрагментов, и три парити-фрагмента вычисляются из данных. Каждый из девяти фрагментов сохраняется на разных нодах и даже разных площадках, что позволяет защититься от выхода из строя ноды или площадки целиком.
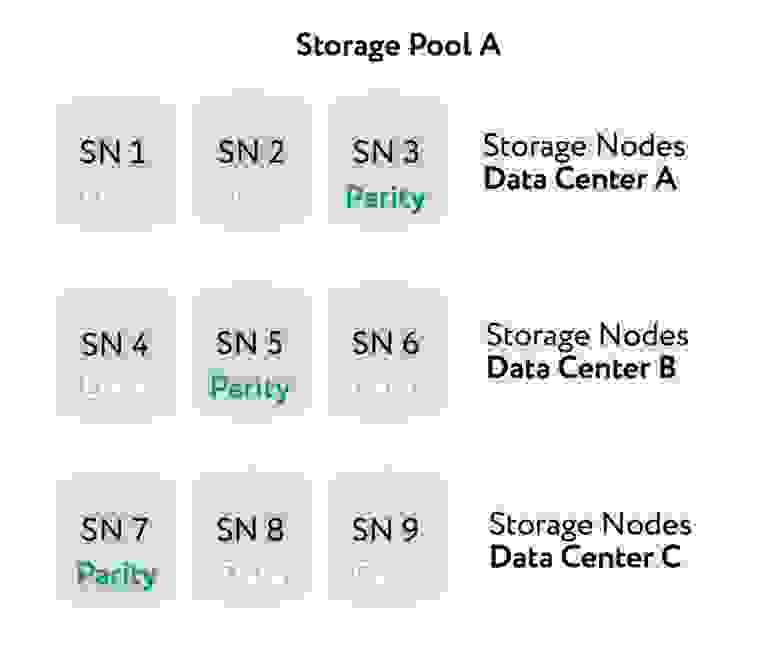
На данном примере может быть потеря до трёх фрагментов без потери данных.
Решение полностью соответствует всем требованиям в техническом задании. Система хранения на его основе высокодоступна и производительна, с простой настройкой, встроенным мониторингом, гибкой настройкой политик под сроки хранения и расположение файлов, репликацией и доступом по API.
Помимо этого, для заказчика обнаружились критически важные вещи:
- Синхронная репликация между площадками даже при задержках, которые накладывают шифровальщики.
- Возможность задублировать каждый компонент именно железом (ноду управления, свитчи, диски, всё что можно).
Третий вариант (от вендора С) — универсальная объектная платформа хранения данных. Решение можно использовать по одной из нескольких моделей: как программно-определяемую систему или как готовое устройство. Оно позволяет хранить неструктурированные данные и управлять ими с минимальными затратами в любых масштабах и в течение любого периода времени.
Есть поддержка нескольких протоколов — одна система хранения с поддержкой всех объектных протоколов (S3, CAS, Atmos, OpenStack и т. п.). Есть встроенная поддержка файлов — встроенная поддержка HDFS и NFS без необходимости использовать шлюзы. Управление метаданными — поддержка расширенных метаданных, индексирования и аналитики с помощью встроенного механизма поиска и управления метаданными. Плюс высокая эффективность системы хранения: благодаря использованию алгоритма распространения информации повышается эффективность системы хранения, и появляется возможность подключения большего количества площадок.
Архитектура решения состоит из нескольких основных компонентов:
- Основанный на API web-интерфейс и CLI для автоматизации, отчётности и управления нодами ECS. Этот уровень также позволяет выполнять операции, связанные с лицензированием, аутентификацией, предоставлением ресурсов и созданием пространства имён.
- Cервисы, инструменты и API для доступа к объектам и файлам в системе.
- Основной сервис, отвечающий за хранение и извлечение данных, управление транзакциями, защиту и репликацию данных локально и между сайтами.
- Служба кластеризации для управления работоспособностью, конфигурацией, обновлением и оповещениями.
- ОС, SLES 12 или другие поддерживаемые.
- Appliance или другое сертифицированное оборудование.
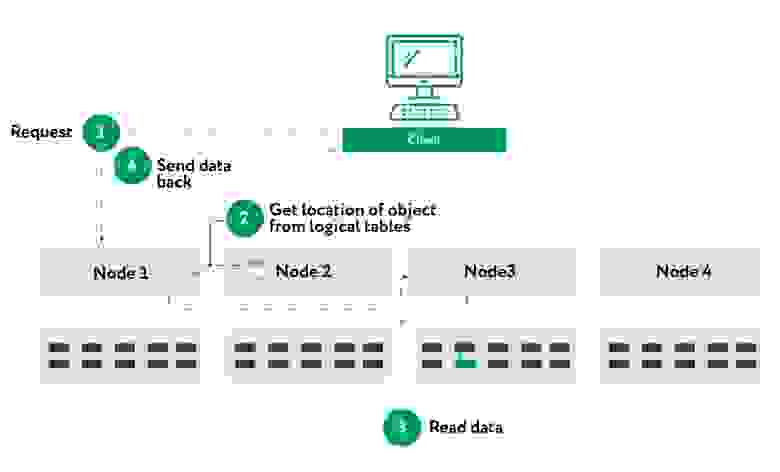
С точки зрения клиента схема взаимодействия выглядит следующим образом:
- Запрос на чтение объекта отправляется от клиента к ноде 1.
- Нода 1 использует хэш-функцию, используя имя объекта, чтобы определить, какой узел является владельцем раздела логической таблицы, в которой находится информация об этом объекте. В этом примере нода 2 является владельцем, и таким образом она выполнит поиск в логических таблицах, чтобы определить местоположение фрагмента. В некоторых случаях поиск может происходить на двух разных узлах, например, когда местоположение не кэшируется в логических таблицах ноды 2.
- На предыдущем шаге местоположение чанка предоставляется ноде 1, которая затем отправит запрос чтения смещения байтов узлу, который содержит данные, в этом примере — ноде 3, и отправит данные ноде 1.
- Нода 1 отправляет данные запрашивающему клиенту.
Решение частично соответствует требованиям ТЗ, платформа обладает достаточной отказоустойчивостью и гибкостью. Использует программно-определяемую архитектуру, и за счёт этого вычислительные ресурсы и ресурсы хранения гибко масштабируются. Все данные в ECS контейнеризированы; нет аппаратной зависимости, необходимости перекодировать или перенастраивать приложения, поскольку ECS обеспечивает поддержку нескольких протоколов.
Дальше мы показываем таблицу заказчику и предлагаем выбор:
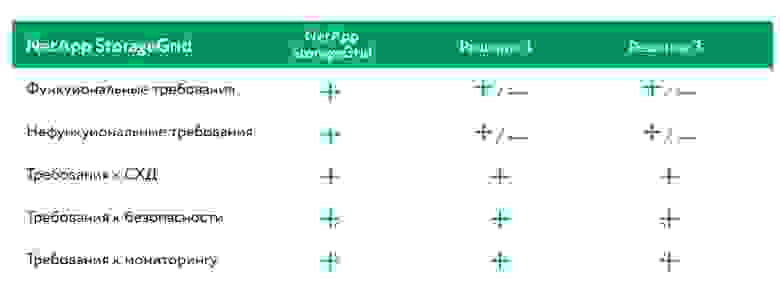
NetApp StorageGrid:
- Мультипротокольный доступ к системе.
- Отказоустойчивое решение (erasure decoding).
- Полная поддержка Amazon S3 API.
- Автоматическое определение типа данных по их метаданным.
- Поддержка ленточных библиотек.
- Синхронная запись данных на две площадки.
- Дедупликация.
- Возможности масштабирования наращиванием объёмов (только полками в 6000-йсерии).
- Возможность увеличения производительности (SSD pool).
- 4×25 GBs-порта для клиентского трафика и репликации.
Но часть функционала возможна только при использовании дополнительных виртуалок.
Вендор А:
- Расширенный набор протоколов для доступа к системе.
- Отказоустойчивое решение.
- Встроенная поддержка HDFS и NFS.
- Поддержка расширенных метаданных.
- Поддержка нескольких namespace (=tenant).
Но отсутствуют возможности использования ленточных библиотек; часть критичного функционала (HA-режим, отказоустойчивость NFS) доступна только при использовании балансировщиков нагрузки.
Вендор С:
- Мультипротокольный доступ к системе.
- Отказоустойчивое решение.
- Продвинутые механизмы компрессии и дедупликации.
- Механизмы NENR (невозможность перезаписи и удаления) и WORM (однократная запись — многократное чтение).
Но часть функционала возможна только при использовании специализированного ПО, что влечёт дополнительные финансовые издержки; отсутствуют возможности использования ленточных библиотек. А также отсутствие синхронной репликации данных между площадками.
NetApp StorageGRID собрал все плюсы по требованиям заказчика. Особенность выбора ещё в том, что мы не топили ни за какого вендора (что стало шоком для клиентов, потому что они привыкли, что ИТ-компании и интеграторы всегда стараются продать какое-то конкретное решение).
В итоге заказчик решает, что если строить систему на века, то лучше взять то, где больше соответствия цели. И останавливается на Гриде.
Шаг 3: ещё больше деталей
На самом деле для каждого решения оценивалась архитектура куда более детально. Позже она ещё больше прорабатывалась до уровня «а как мы это потом будем эксплуатировать». Поэтому тут я расскажу про особенности эксплуатации выбранного решения.
StorageGrid работает с разделёнными неструктурированными данными, управляется из одной панели. Есть CDMI, S3 и Swift для интеграции с облачными провайдерами, есть поддержка ленточных библиотек. Данные свободно ходят между всеми инстансами независимо от их реализации: лента, облако и дисковое/ssd хранилище имеют одинаковые интерфейсы.
Erasure Coding (EC) — аналог RAID, обеспечивающий сохранность данных по Риду-Соломону. Система дробит объекты на k фрагментов, из которых два или более — избыточные. При потере любых двух фрагментов возможно восстановление чистой копии. Затем система распределяет данные по инстансам так, чтобы при потере, например, одной из геоплощадок данные можно было восстановить на другой. На практике используются различные схемы, например, 6 + 3, где шесть частей — это фрагменты исходных данных, а ещё три части — избыточные данные для восстановления, построенные на основе вычислений над первыми шестью частями.
Аналогично есть 3 + 1, 4 + 2 и так далее с разными значения полезных блоков и блоков чётности. Читать при этом можно сразу с двух площадок. Есть Geo Distributed Erasure Coding — это тот же EC, но снижающий трафик: данные не передаются между площадками, а восстанавливаются из избыточных на текущей, что позволяет снижать трафик. К примеру, для четырёх геоточек можно использовать схему 9 + 3. Следующий уровень — Hierarchical Erasure Coding, который делает глобальный GDEC и локальный EC на уровне конкретных устройств.
Ещё ниже в аппаратной реализации лежит Dynamic Disk Pools — аналог RAID в группе на локальной системе, где данные дробятся и распределяются между множеством физических носителей для быстрого чтения. Это позволяет сохранять скорость при просадке части дисков и значительно быстрее восстанавливать сломанные диски, чем классический RAID. При размере дисков в 16 ТБ это действительно имеет значение. Сама технология хорошо сочетается с алгоритмами EC.
Есть эмуляция NAS, что даёт обычный файловый доступ поверх объектного. При этом сам Грид двигает файлы по уровням хранения в зависимости от настроек ILM полностью прозрачно для пользователя.
Лицензирование решения — по сырому дисковому пространству, количество узлов на цену не влияет, в коробке сразу много нужных вещей вроде интеграции с Active Directory.
Протокол для приложений — стандартный S3 Restful API, то есть все бэкапы и другой софт автоматизации подключаются без проблем.
При ограниченном бюджете части или весь StorageGrid можно развернуть/задублировать и на виртуалках, так как это софт. В нашем случае заказчик сначала настаивал, что ему необходимо всё на железе, но, проверив работу НА между физической и виртуальной Admin Node, решил не докупать вторую железку.
К тому же, если у компании уже есть NetApp FAS/AFF, то они могут с помощью технологии FabricPool тирить в автоматическом режиме холодные данные с продуктивной СХД на StorageGrid.
- Размещение файлов на хранение и запрос ранее размещённых файлов (очевидно).
- Метки «не использую».
- Необходимый набор поддерживаемых систем хранения данных: ленточные накопители, дисковые массивы различной скорости доступа и размещения, существующие решения компании, облачные сервисы.
- Гибкие политики хранения.
- Фоновая миграция.
- Удаление файлов в соответствии с политиками (просроченных документов).
- Понятный API.
- Единая точка управления распределённой системой.
- Подходит для хранения сканов, видео, архивов документов, прочих бинарных данных.
- Обеспечение 99,999% гарантии сохранности данных в течение всего срока их хранения. Предельный срок хранения данных — 75 лет или более.
- Масштабирование системы по числу и объёму используемых СХД.
- Масштабирование системы по производительности запросов на обслуживание.
- Геораспределение.
- Защита от устаревания. Возможность масштабирования (расширения) с учётом новых поколений оборудования. Уже закупленное оборудование должно использоваться до истечения полного срока амортизации (защита инвестиций).
- Отказ части контроллеров не приводит к недоступности массива или потере данных. Отказ всех контроллеров не должен приводить к потере данных. Выход из строя одного из «уровней хранения» не должен приводить к потере данных или отказу в обслуживании системы.
- Статистика и прогнозы утилизации. Мониторинг. JSON для выгрузок. Поддержка SMTP и системы уведомлений о проблемах. И так далее.
Теперь переходим к железу!
NetApp StorageGrid может собираться из различных Storage и Admin-нод.
В нашей реализации использовался узел StorageGRID SG1000, который выполняет роль Gateway Node или Admin Node для обеспечения отказоустойчивости и балансировки нагрузки. Ниже — SG1000 без передней панели. Два SSD-диска, выделенные рамкой, используются для ОС StorageGRID и используют RAID1 для отказоустойчивости. Оставшиеся дисковые слоты остаются пустыми. Когда SG1000 настроен как Admin Node, диски используются для хранения аудит логов, метрик и таблиц БД.

Порты для подключения с задней стороны SG1000:
StorageGRID SG6060 — сюда интегрированы вычислительный контроллер и контроллер хранения. Устройство может быть использовано в гибридной структуре с физическими и виртуальными Storage Node. Дополнительно можно расширить дисковой полкой с 60 дисками.

На рисунке изображён SG6060 с передней стороны с вычислительным контроллером и контроллером хранения с красивой «мордой» и без.
Вид сзади на полку расширения для SG6060 с IOM-модулями, вентиляторами и блоками питания:
Если подробнее — каждый StorageGRID SG6000 состоит из вычислительного 1U-контроллера SG6000-CN и двух E-series-контроллеров хранения в корзине 2U или 4U в зависимости от модели. Ниже описана более подробная информация о каждом контроллере.
Вычислительный контроллер SG6000-CN: предоставляет вычислительные ресурсы для системы; включает в себя StorageGRID Appliance Installer; может подключаться ко всем трём сетям, включая Grid Network, Admin Network, Client Network; подключается к контроллерам хранения и выступает инициатором.
Контроллер хранения Е2800: два контроллера для обеспечения отказоустойчивости; управляет хранением данных на дисках; включает в себя SANtricity OS (ОС контроллера); включает в себя SANtricity System Manager для мониторинга состояния оборудования и оповещений, автосаппорта и функции Drive Security; подключается к SG6000-CN и обеспечивает доступ к хранилищу данных.
На рисунке изображён контроллер Е2800 с задней стороны:
IOM (input/output) — модули для расширения полок:
Если вы ещё тут, то поздравляю, вы гик! Ну или IT-специалист по огромным архивам.
Шаг 4: взлетаем
В итоге для старта установлено по три узла SG6060 и одному SG1000 в каждый ЦОД. Всё это объединено продуктивной и менеджмент-сетками. Для репликации используется обычная сеть заказчика с шифрованием трафика между сайтами. Повозившись немного с монтажом и аккуратной коммутацией, запустилось всё гораздо проще, чем ожидали. И спустя буквально час после монтажа уже можно было загружать тестовые объекты.
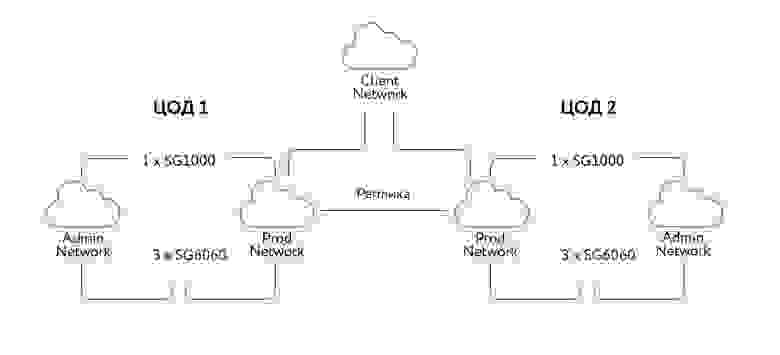
Дальше смотрим на софт.
Tenant Manager или Tenant Management API могут быть использованы для управления консистентностью операций, выполняемых с объектами в S3-бакетах. Уровень консистентности устанавливает баланс между доступностью объектов и их консистентностью на различных узлах хранения и сайтах. В целом следует использовать правило Read-after-new-write для всех бакетов. Если данный уровень (Read-after-new-write) не удовлетворяет потребностям приложений, то уровень консистентности можно поменять в заголовке Consistency-Control. Данный заголовок имеет приоритет над уровнем консистентности, установленным на бакете.
Дашборд:
Платформенные сервисы StorageGRID позволяют реализовать стратегию гибридного облака. Если данные сервисы разрешены в рамках тенанта, то существует возможность интеграции следующих сервисов для S3-бакетов:
1. CloudMirror replication: StorageGRID CloudMirror — это сервис репликации, который используется для зеркалирования отдельных объектов из бакета в отдельное внешнее хранилище.
Например, есть возможность использовать CloudMirror для зеркалирования отдельных пользовательских записей во внешнее S3-облако, чтобы потом использовать облачные сервисы для аналитики данных.
2. Notifications: Нотификации, устанавливаемые на уровне бакетов, используются для того, чтобы отправлять оповещения об определённых действиях, которые выполняются над объектами.
Например, есть возможность сконфигурировать оповещения администратора о каждом объекте определённого типа, добавляемого в бакет, к примеру, при добавлении логов, связанных с определёнными критическими событиями.
3. Search integration service: интеграция с поисковым сервисом используется для отправки метаданных S3-объектов в указанный Elasticsearch-индекс, где они могут быть использованы для поиска либо анализа при помощи внешнего сервиса.
Например, можно сконфигурировать бакеты для отправки S3-метаданных объектов во внешний Elasticsearch-сервис. После этого можно будет выполнять поиск в различных бакетах, а также анализ паттернов, присутствующих в метаданных объектов.
По причине того, что целевая система для платформенных сервисов является, как правило, внешней по отношению к StorageGRID, платформенные сервисы дают возможность использовать мощь и гибкость комбинации внешних ресурсов и поисковых запросов для хранимых данных.
Шаг 5: Полёт
Как масштабировать эту систему? Докупать ещё узлы, включать их в синхронизацию и ждать несколько часов. Потолка, сколько этих узлов может быть, практически нет. Из известных максимумов это 16 сайтов, 400 ПБ ёмкости и 100 миллиардов объектов.
Обновление — узлами нового поколения. Покупаются новые узлы, данные сами мигрируются, старые выводятся из эксплуатации.
Сейчас всё это проверяется на практике. И, как мне кажется, мы собрали нечто, способное выдержать довольно долгий космический перелёт, обновление запчастями на новых планетах и перелёт дальше. В общем, знакомьтесь с технологиями межзвёздных торговых корпораций, использующих релятивистские движки. И спасибо, что дочитали до этого места).
Если вдруг есть вопросы или вы через год-другой захотите узнать, как там наш полёт, — вот моя почта: mk@croc.ru.
