Немного об ООП, ФП и логическом программировании
А так же языках: Smalltalk, Prolog, Erlang, Haskell и, возможно Go, Rust и Scala.Некоторое время назад я увидел на одном известном форуме тему «Почему не выстрелил Smalltalk». Заинтересовавшись (а я мельком изучал его когда искал «язык под себя» в вышеперечисленном списке, но бросил когда увидел, что идея посылки сообщений там фактически не используется), вступил в дискуссию апеллируя к тому что автор языка фактически не использует важнейшую, на мой взгляд, особенность языка — посылку сообщений. Собеседники парировали тем что там имеются такие важные особенности как метаклассы и рефлексия. В общем-то ответить на это было нечем, я бросил изучение языка еще до полного понимания системы классов.
Поразмышляв, я сел разбираться в системе классов Smalltalk«a. Поначалу мне показалось это невообразимым ужасом: экземпляр, объект, класс объекта, метакласс объекта, класс метаклассов. Подумав о могучей фантазии автора языка, я все же немного стал понимать, что к чему, а далее наткнулся на такой текст:
«То, что мы рассмотрели, не отвечает на главный вопрос: как объект, получивший сообщение, находит метод, который надо выполнить? Остановимся подробно на механизмах поиска по сообщению необходимого метода и его выполнения. Итак, как уже отмечалось, выполнение любого действия в системе Смолток осуществляется с помощью посылки объекту сообщения. Получив сообщение, получатель ищет метод с соответствующим сообщению шаблоном, начиная поиск обычно со своего класса. Если объект — класс, то метод ищется среди методов класса, а если объект — экземпляр класса, то среди методов экземпляра класса. Если метод с соответствующим шаблоном находится в классе получателя, то он выполняется, и как результат его выполнения обязательно возвращается некоторый объект, который информирует того, кто послал сообщение, что выполнение метода завершилось с содержащимся в возвращаемом объекте результатом.
А если метода с нужным шаблоном нет в классе? Тогда к работе подключается иерархия классов, а точнее, цепочка суперклассов для класса объекта-получателя. Если в классе подходящего метода нет, метод ищется в ближайшем его суперклассе. Если нужного метода нет в суперклассе, то поиск продолжается в следующем по иерархии суперклассе и так далее, пока не доберемся до класса Object.»
Вот оно, что-то внутри подсказало что последний абзац это очень важная часть. Поразмыслив, а как же я бы сделал это на привычных функциональных языках я довольно быстро сообразил, как сделать подобное на Эрланге:
«Цепочки функций» Fun1(pattern1) → ans1, Fun1(pattern2) → ans2.Создали функцию которая делает обычную вещь: возвращает какое-то значение в ответ на предъявляемый ей паттерн. Но вдруг нам понадобилась какая то функция похожая на эту, но немного отличающаяся, создаем:
Fun2(pattern3) → ans3, Fun2(P) → Fun1(P).
Что произошло? Мы сделали аналог функции:
Fun2(pattern1) → ans1, Fun2(pattern2) → ans2, Fun2(pattern3) → ans3.
Но не стали писать её с нуля, а просто «унаследовали» кое-что от предыдущей. Теперь после того как проверится pattern3 произойдет вызов старой функции и она нужный нам результат.
Комбинировать можно произвольно:
Fun3(pattern4) → ans4.
Fun4(pattern5) → ans5, Fun4(P) → Fun1(P), Fun4(P) → Fun3(P).
Тут мы скомбинировали функции Fun1 и Fun3, добавив к ним pattern5.
Можно и заменять части:
Fun5(pattern1) → new_ans1, Fun5(P) → Fun1(P).
Тут произойдет замена части Fun1, когда придет pattern1 функция просто вернет значение и только когда придет pattern2 она передаст его дальше.(Я не отвлекаюсь на некоторые нюансы языка, такие что придет аргумент который не может обработаться и функции нечего будет вернуть)
Интересная концепция, опять подумалось мне, можно сколько угодно и как угодно, а главное быстро дописывать новый функционал. Но потом придется использовать методы Геракла что бы расчищать такие Авгиевы конюшни. На этом можно было бы и закончить, ну, новый способ (выстрелить в старую добрую ногу) программирования, что тут еще может быть.
Но в голову пришла новая светлая мысль. Я подумал, а что из себя представляют такой код? И понял: это множества функций. А ведь есть язык программирования в котором такое написание кода вполне естественно и он как раз построен на теории множеств. Это был Prolog. Синтаксис его почти повторяет синтаксис эрланга за тем исключением что мы можем написать вот так:
Fun1(pattern1) → ans1, Fun1(pattern1) → ans2.
И он вернет нам на pattern1 оба варианта разом: Ans1Ans2
Немного не то что нам сейчас нужно, но это быстро исправляется используя механизм отсечения с помощью синтаксиса »!»:
Fun1(pattern1) → ans1, !, Fun1(pattern1) → ans2.
Если программа дошла до ans1, то она возвращается его, останавливаясь на »!». Теперь у нас есть почти есть почти эквивалентная запись. Получается, что Smalltalk это такой Prolog с отсечениями? Похоже, очень похоже. Тут можно было остановится и просто сказать: «Smalltalk это Prolog недобитый» или «ООП это покоцанное логическое программирование», но мысли пошли еще дальше.
«Множества» А ведь множества я видел кое где еще, и правильно, алгебраические типы данных в Haskell: Data color = red | green | blueТип данных color может принимать одно из трех значений, «логическое «или»
Data coordinates = (Integer, Integer)
И имеется «и», этот тип содержит уже два числовых значения (можно сделать более легкий доступ к ним с помощью синтаксического сахара и будет что-то типа обращения по именам (x, y), но это сейчас не важно).
С помощью такого конструктора очень удобно составлять нужные нам типы данных, в них будет только то что необходимо нам, так почему бы не взять и не использовать его для функций?
Quadruple = double. doubleDouble x = x * 2
Логическое «и» из того же haskell«a, не очень то необходимо, но оно есть, заменяет например:
Quadruple x = double (double x)
Что почти мелочь, но все равно приятно. Далее мы ищем что нам обеспечит «цепочку функций» и находим:>>=Возвращает результат функции либо Nothing
Data fun = fun_result | nothing
(Те кто знают Haskell, сейчас очень плохо подумали обо мне, но что поделать в этой части языка я еще не совсем разобрался, просто идем дальше)
Тем не менее, это позволяет строить нам так необходимые «цепочки функций»
Fun3 = fun1 >>= fun2Fun4Fun5 = fun3 >>= fun4
При вызове fun5 оно пробегает по цепочке fun1 → fun2 → fun4 и если ни одна из функций не применяется то возвращает нам Nothing (>>= — это кстати монада). Должен добавить, что при правильном (и необходимом нам) подходе выполнится ровно одна функция из цепочки или цепочки цепочек (ровно то что надо нужно) либо вернется Nothing.
Хорошо, теперь у нас есть множества типов (алгебраические типы данных), есть множества функций («цепочки функций» и «цепочки цепочек функций» организованные с помощью одной из монад) и что же дальше? А дальше мы выразим из этого всего еще одну концепцию — объект.
«Объекты» Объект — это множество возможных состояний (выраженных через алгебраические типы данных) и множество функций (объединенных с помощью монады >>= в «цепочку функций»). В общем-то как в реальности, у объекта есть набор свойств и набор действий который он может делать или с ним могут произвести, прекрасно подходит под наше интуитивное представление о реальности. Или еще можно сказать что у него есть множество возможных состояний и множество путей перехода от одного состояния к другому, на вскидку вспоминается суперпозиция из физики. И это уже похоже на стандартное: Object1Method1Method2…Attribute1Attribute2…
Только с новой базой под собой (Тут я уже не могу привести аналоги из Haskell«a кодом, на ум приходит разве что монада State. Но в том же Erlang«e эта сущность есть, называется процессом, имеет внутренние состояние, конструируется по сути с использованием чистых функций).
Спрашивается, а в чем собственно преимущества всего этого? В базе на которой мы построили все это, теории множеств. Подведя определение объекта под множество мне, например, стало намного легче понять как наиболее эффективно конструировать программы, сводя количество повторов кода к минимуму (возможно даже что с помощью языков средств программа сможет нам подсказывать как лучше сделать тот или иной кусок кода, тут нам ум приходит строчка из википедии «Система проверки типов языка Agda дает программисту полезную информацию о ещё не написанных частях программы»).
Далее, я уже упомянул эрланг, а процессы («объекты» по нашем модели, построенные на модели акторов) довольно-таки легкий способ разрабатывать высокопараллельные и даже распределенные системы (например тот же WhatsApp использует эрланг), но можно использовать и другие техники для многопоточного программирования.
(Я могу путать смежные да и некоторые другие термины, поэтому попробуйте просто понять суть.)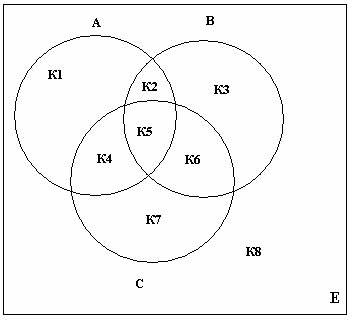 Можно отвлечься и еще раз повторить то как можно конструировать объекты, используя данное изображение можно сказать что A, B, C это простые функции, K2, K4, K6 это цепочки из двух функций, K5 это цепочка из трех функций. Точно так же и с типами данных, комбинировать можно произвольно. А объектом будет комбинация из функций, «цепочек функций» и атрибутов и их комбинаций (может быть несколько атрибутов на основе одного комбинированного типа данных).
Можно отвлечься и еще раз повторить то как можно конструировать объекты, используя данное изображение можно сказать что A, B, C это простые функции, K2, K4, K6 это цепочки из двух функций, K5 это цепочка из трех функций. Точно так же и с типами данных, комбинировать можно произвольно. А объектом будет комбинация из функций, «цепочек функций» и атрибутов и их комбинаций (может быть несколько атрибутов на основе одного комбинированного типа данных).
Наверно выглядит как-то так: есть части тела в виде объектов и есть само тело как объект. Далее, если использовать например посылку сообщений, мы посылаем объекту тело какое-нибудь сообщение, а он (оно) отправляет ноге или руке. Можно еще представить, что нога и рука обращаются к голове, и с помощью блокировки рука получает доступ к объекту тело. Или почти так же оно выглядело бы с STM.
Отступление (Тут смутно вспоминается книжка «О ловкости и её развитии» в которой описывается как наша голова обходит такие «блокировки». Собственно делает она это с помощью выделения нескольких уровней сознательности движений, начиная с почти неподконтрольного нам общего мышечного тонуса и осанки, и заканчивая построением новых движений. Идет оно примерно так: новое движение все больше автоматизируется и все меньше требует сознательного контроля. Для изменения старого движения нужно поднять его на сознательный уровень и почти заново проделать тот же путь что и с изучением нового движения. Можно объединить концепции и назвать «ловкое параллельное программирование»… В общем никогда не знаешь знания из какой области могут пригодиться.)
«Немного о языках»
Smalltlak: идея хорошая, а вот реализация, по моему, так себе.
Pic
 Prolog: идея отличная и реализация неплохая, хотя медленная (что починили в Mercury), но он вообще к привычному ООП никаким боком, что опять же не мешает зная все это на нем реализовать подобие ООП (не делайте этого). Сам я вижу скрытый источник идей в нём и его потомках.
Prolog: идея отличная и реализация неплохая, хотя медленная (что починили в Mercury), но он вообще к привычному ООП никаким боком, что опять же не мешает зная все это на нем реализовать подобие ООП (не делайте этого). Сам я вижу скрытый источник идей в нём и его потомках.
Erlang: легко писать чистые функции, так же легко создать процессы (объекты, в понимании этой статьи или акторы в понимании других людей), но есть проблема с конструкторами данных, хотя в последней версии начали добавлять какую-то структуру для более легкой работы с ними — maps. Сам я вижу большой потенциал, потому что его изучение сопоставимо по сложности с изучением других популярных языков (никаких синхрофазотронных конструкций в стиле Haskell`a). И у него масса других преимуществ.
Go: мельком посмотрел его, есть возможность конструировать структуры данных подобным ADT способом и кажется есть способ конструировать так же функции (методы), но они опять же прибиты гвоздями к структурам (Если оно так то см. Smalltalk).
Rust: посмотрел так же мельком, говорят там есть ADT (что очень хорошо если так) и есть чистые и «грязные» функции, что тоже очень хорошо. Все это в принципе позволяет собрать то что нам нужно (главное, что бы опять не получился Smalltalk).
Lisp: нет ничего кроме (скобочек) функций. Но есть мощная макросистема прекрасно использующая (скобочки) синтаксис языка и вероятно реализовать подобие на макросах (но можно и просто скачать Haskell).
Haskell: синхрофазотронные (по-началу) конструкции на любой вкус, почти уверен что есть все что нужно для конструирования объектов в таком стиле, дополняя это статической проверкой типов, получаем достаточно быстрый и хорошо спроектированный язык. Тут мы можем разложить по полочкам все необходимые нам сущности и использовать все новейшие технологии программирования поверх них. (Сам я в текущее время буду одолевать его, что бы добраться до Idris«a и Agda«ы).
Scala: и подобные ему где функции — это объекты. Лучшее из двух миров. Как мы видим функции это не объекты, не стоит брать молоток и прибивать гвоздями одно к другому (см. smalltalk).
Pic
 Впрочем, есть любители и такого.«Заключение»
Если посмотреть на нашу концепцию мы увидим, что алгебраические типы данных нужны и вполне обоснованы, как очень удобный способ описания, комбинирования и составления новых типов данных. К ним не привязаны лишние сущности и они ровно то что нужно.Чистые функции так же вполне обоснованы из них очень удобно составлять необходимые нам «цепочки функций» и опять же к ним не привязано ничего лишнего.
Впрочем, есть любители и такого.«Заключение»
Если посмотреть на нашу концепцию мы увидим, что алгебраические типы данных нужны и вполне обоснованы, как очень удобный способ описания, комбинирования и составления новых типов данных. К ним не привязаны лишние сущности и они ровно то что нужно.Чистые функции так же вполне обоснованы из них очень удобно составлять необходимые нам «цепочки функций» и опять же к ним не привязано ничего лишнего.
Строгая система типов. Она плавно вытекает из использования алгебраических типов данных, а так же, если например сделать модуль с типами данных, поможет использовать модуль с функциями использующие этот модуль (возможность делать отдельно модули с типами данных, чистыми функциями и «объектами» лично мне очень импонирует), в общем она помогает «связывать типа данных и чистые функции что бы они сильно не разлетались».
Монады, это из чего клепаются наши объекты, там происходят все вычисления с состоянием. Как концепция то что надо, а вот как оно позволяет реализовать данную концепцию (удобно или нет), я сказать пока не могу. Но синтаксис выглядит приятно.
Ленивость или энергичность. Я не забыл про них, но пока смутные представления на счет того что лучше. Возможность иметь такую как бы «подгрузку данных по мере необходимости» с разных источников выглядит привлекательно. Остаются как всегда детали реализации.
Наследование. Вообще возможность создать «почти такой объект» мне нравится, проблема в том что создавать легко, а поддерживать потом такие «династии», по которым размазано ровным слоем все тело объекта может оказаться очень тяжело. Интересным мне видится возможность с помощью IDE делать обычное наследование, но что бы потом оно конструировало объект аналогичный объекту построенному на ADT и чистых функциях, что бы вся сущность была в одном месте (вообще может быть можно сделать какое-нибудь динамическое представление объекта, что бы автоматически отлавливать например похожие объекты и выносить общий код в ADT и цепочки функций).
