Немного о повышении производительности БД: Практические советы

/ фото Ozzy Delaney CC
Мы в 1cloud много рассказываем о собственном опыте работы над провайдером виртуальной инфраструктуры и тонкостях организации внутренних процессов. Сегодня мы решили немного поговорить об оптимизации БД.
Многие СУБД способны не только хранить и управлять данными, но и исполнять код на сервере. Примером этого служат хранимые процедуры и триггеры. Однако всего одна операция изменения данных может запустить несколько триггеров и хранимых процедур, которые, в свою очередь, «разбудят» еще парочку. В качестве примера можно привести каскадное удаление в базах данных SQL, когда исключение одной строки в таблице приводит к изменению многих других связанных записей.
Очевидно, что пользоваться расширенной функциональностью следует осторожно, чтобы не нагружать сервер, ибо все это может сказаться на производительности клиентских приложений, использующих данную БД.
Взгляните на график ниже. На нем изображены результаты выполнения нагрузочного тестирования приложения, когда число пользователей (синий график), работающих с БД, постепенно увеличивается до 50. Количество запросов (оранжевый), с которыми система может справиться, быстро достигает своего максимума и перестаёт расти, тогда как время ответа (желтый) постепенно увеличивается.
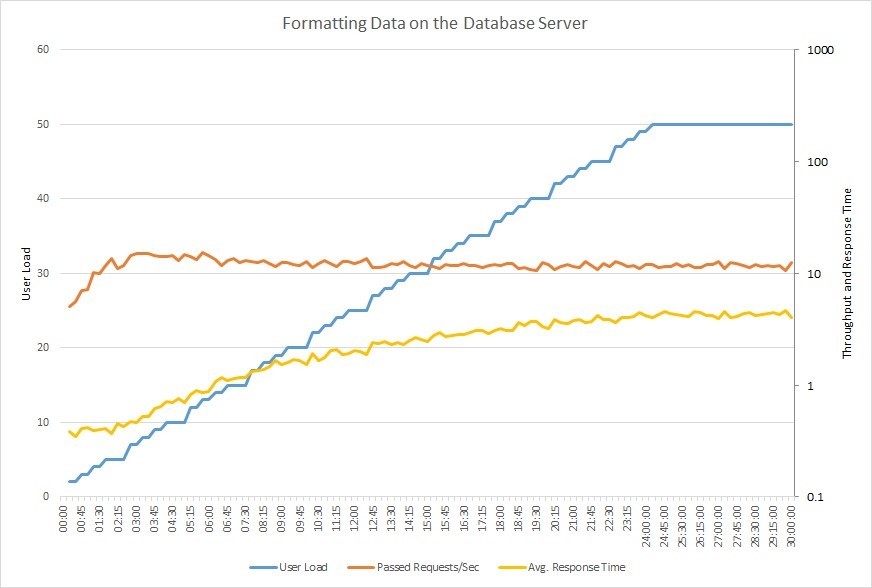
При работе с крупными базами данных даже малейшее изменение способно оказать серьезное влияние на производительность, причем как в положительную, так и отрицательную сторону. В организациях среднего и большого размера настройкой баз данных занимается администратор, но частенько эти задачи ложатся на плечи разработчиков. Поэтому далее мы дадим несколько практических советов, которые помогут повысить производительность баз данных SQL.
Используйте индексы
Индексация — это эффективный способ настройки базы данных, которым часто пренебрегают во время разработки. Индекс ускоряет запросы, предоставляя быстрый доступ к строкам данных в таблице, аналогично тому, как предметный указатель в книге помогает вам быстро найти желаемую информацию.
Например, если вы создадите индекс по первичному ключу, а затем будете искать строку с данными, используя значения первичного ключа, то SQL-сервер сначала найдет значение индекса, а затем использует его для быстрого нахождения строки с данными. Без индекса будет выполнено полное сканирование всех строк таблицы, а это трата ресурсов.
Однако стоит обратить внимание, что, если ваши таблицы «бомбардируются» методами INSERT, UPDATE и DELETE, к индексации нужно отнестись осторожно — она может привести к ухудшению производительности, так как после проведения указанных выше операций все индексы должны быть изменены.
Более того, когда нужно добавить в таблицу большое количество строк (например более миллиона) сразу, администраторы БД часто сбрасывают индексы для ускорения процесса вставки (после вставки индексы создаются заново). Индексация — это обширная и интересная тема, для ознакомления с которой недостаточно столь краткого описания. Больше информации по этой теме вы найдете здесь.
Не используйте циклы с большим количеством итераций
Представьте ситуацию, когда на вашу БД последовательно приходит 1000 запросов:
for (int i = 0; i < 1000; i++)
{
SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES...");
cmd.ExecuteNonQuery();
}
Такие циклы писать не рекомендуется. Пример выше можно переделать, используя один INSERT или UPDATE с несколькими параметрами:
INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9)
UPDATE TableName SET A = CASE B
WHEN 1 THEN 'NEW VALUE'
WHEN 2 THEN 'NEW VALUE 2'
WHEN 3 THEN 'NEW VALUE 3'
END
WHERE B in (1,2,3
)
Убедитесь, что операция WHERE не перезаписывает одинаковые значения. Такая простая оптимизация может ускорить выполнение SQL-запроса, уменьшив количество обновляемых строк с тысяч до сотен. Пример проверки:
UPDATE TableName
SET A = @VALUE
WHERE
B = 'YOUR CONDITION'
AND A <> @VALUE – VALIDATION
Избегайте коррелирующих подзапросов
Коррелирующим подзапросом называют такой подзапрос, который использует значения родительского запроса. Он выполняется построчно, один раз для каждой строки, возвращённой внешним (родительским) запросом, что снижает скорость работы БД. Вот простой пример коррелирующего подзапроса:
SELECT c.Name,
c.City,
(SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName
FROM Customer c
Здесь проблема в том, что внутренний запрос (SELECT CompanyName…) выполняется для каждой строки, которую возвращает внешний запрос (SELECT c.Name…). Чтобы повысить производительность, можно переписать подзапрос через JOIN:
SELECT c.Name,
c.City,
co.CompanyName
FROM Customer c
LEFT JOIN Company co
ON c.CompanyID = co.CompanyID
Старайтесь не использовать SELECT *
Старайтесь не использовать SELECT *! Вместо этого стоит подключать каждый столбец по отдельности. Звучит просто, но на этом моменте спотыкаются многие разработчики. Представьте таблицу с сотнями столбцов и миллионами строк. Если вашему приложению нужно лишь несколько столбцов, нет смысла запрашивать всю таблицу — это большая трата ресурсов.
Например, что лучше: SELECT * FROM Employees или SELECT FirstName, City, Country FROM Employees?
Если вам действительно нужны все столбцы, укажите каждый в явном виде. Это поможет избежать ошибок и дополнительной настройки БД в будущем. Например, если вы используете INSERT… SELECT…, а в исходной таблице появился новый столбец, могут возникнуть ошибки, даже если этот столбец не нужен в конечной таблице:
INSERT INTO Employees SELECT * FROM OldEmployees
Msg 213, Level 16, State 1, Line 1
Insert Error: Column name or number of supplied values does not match table definition.
Во избежание таких ошибок, нужно прописывать каждый столбец:
INSERT INTO Employees (FirstName, City, Country)
SELECT Name, CityName, CountryName
FROM OldEmployees
Однако стоит заметить, что есть ситуации, в которых использование SELECT * допустимо. Примером могут служить временные таблицы.
Пользуйтесь временными таблицами с умом
Временные таблицы чаще всего усложняют структуру запроса. Поэтому их лучше не использовать, если есть возможность оформить простой запрос.
Но если вы пишете хранимую процедуру, выполняющую какие-то действия с данными, которые невозможно оформить в одном запросе, то используйте временные таблицы как «посредников», помогающих получить конечный результат.
Допустим, вам нужно сделать выборку с условиями из большой таблицы. Чтобы увеличить производительность БД, стоит перевести свои данные во временную таблицу и выполнить JOIN уже с ней. Временная таблица будет меньше исходной, поэтому объединение произойдёт быстрее.
Не всегда понятно, в чем разница между временными таблицами и подзапросами. Потому приведем пример: представьте таблицу покупателей с миллионами записей, из которой нужно сделать выборку по региону. Один из вариантов реализации — использовать SELECT INTO с последующим объединением во временную таблицу:
SELECT * INTO #Temp FROM Customer WHERE RegionID = 5
SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID
Но вместо временных таблиц можно использовать подзапрос:
SELECT r.RegionName, t.Name FROM Region r
JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t
ON t.RegionID = r.RegionID
В предыдущем пункте мы обсуждали, что стоит прописывать в подзапросе только нужные нам столбцы, поэтому:
SELECT r.RegionName, t.Name FROM Region r
JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t
ON t.RegionID = r.RegionID
Каждый из трех примеров вернет один и тот же результат, но в случае с временными таблицами вы получаете возможность использовать индексацию. Для более полного понимания принципов работы временных таблиц и подзапросов можете почитать тему на Stack Overflow.
Когда работа с временной таблицей закончена, лучше удалить её и освободить ресурсы tempdb, чем ждать, пока произойдет автоматическое удаление (когда ваше соединение с сервером БД закроется):
DROP TABLE #tempИспользуйте EXISTS ()
Если необходимо проверить существование записи, лучше использовать оператор EXISTS () вместо COUNT (). Тогда как COUNT () проходит по всей таблице, EXISTS () прекращает работу после нахождения первого совпадения. Этот подход повышает производительность и улучшает читаемость кода:
IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0
PRINT 'YES'
или
IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%')
PRINT 'YES'
Вместо заключения
Пользователи приложений любят, когда им не нужно подолгу смотреть на значок загрузки, когда все работает четко и быстро. Применение описанных в этом материале приемов позволит вам повысить производительность базы данных, что положительно скажется на пользовательском опыте.
Хотелось бы подвести небольшой итог и повторить ключевые моменты, описанные в статье:
- Используйте индексы, чтобы ускорить проведение поиска и сортировки.
- Не используйте циклы с большим количеством итераций для вставки данных — используйте INSERT или UPDATE.
- Обходите стороной коррелирующие подзапросы.
- Ограничивайте количество параметров оператора SELECT — указывайте только нужные таблицы.
- Используйте временные таблицы только как «посредников» для объединения крупных таблиц.
- Для проверки на наличие записи пользуйтесь оператором EXISTS (), который заканчивает работу после определения первого совпадения.
Если вам интересна тема производительности баз данных, то на Stack Exchange есть обсуждение, в котором собрано большое количество полезных ресурсов, — вам стоит обратить на него внимание. Еще можете почитать наш материал о том, как работают с данными крупные мировые компании.
Свежие материалы из нашего блога на Хабре:
- Что нужно знать об IaaS-провайдере еще до начала сотрудничества
- Экономика облачных вычислений
- Как сократить расходы на хранение данных
- Немного о трендах в сфере «облачной» безопасности
Комментарии (2)
4 июля 2016 в 10:15
+1↑
↓
Неплохо, в закладки. спасибо 1cloud
1cloud
4 июля 2016 в 10:17
0↑
↓
Спасибо, что читаете блог.Кстати, в комментариях можно было бы обсудить предложения для следующих постов — какие туториалы могли бы быть интересны применительно к теме IaaS, например.
