Настоящий детектив: загадочные таймауты на проде
 © Сериал «Настоящий детектив»
© Сериал «Настоящий детектив»
Привет! Меня зовут Алексей, я работаю в команде Антиспама Почты Mail.ru, и сегодня хочу поделиться интересным опытом нашей команды по поиску проблем на бою.
Многие из нас любят детективные истории: интрига, драйв, захватывающий сюжет, который держит в напряжении до самого конца, когда раскрывается загадка. Ровно такие же ощущения испытываешь, когда разбираешься с проблемами на проде.
Этот пост — детектив со всеми его элементами: загадочная история с превышением времени до таймаута, круг подозреваемых (среди которых сервисы, прокси и сеть), команда разработчиков и админов — сыщиков, собирающих и изучающих улики и ставящих следственные эксперименты, и непредсказуемая развязка.
Завязка
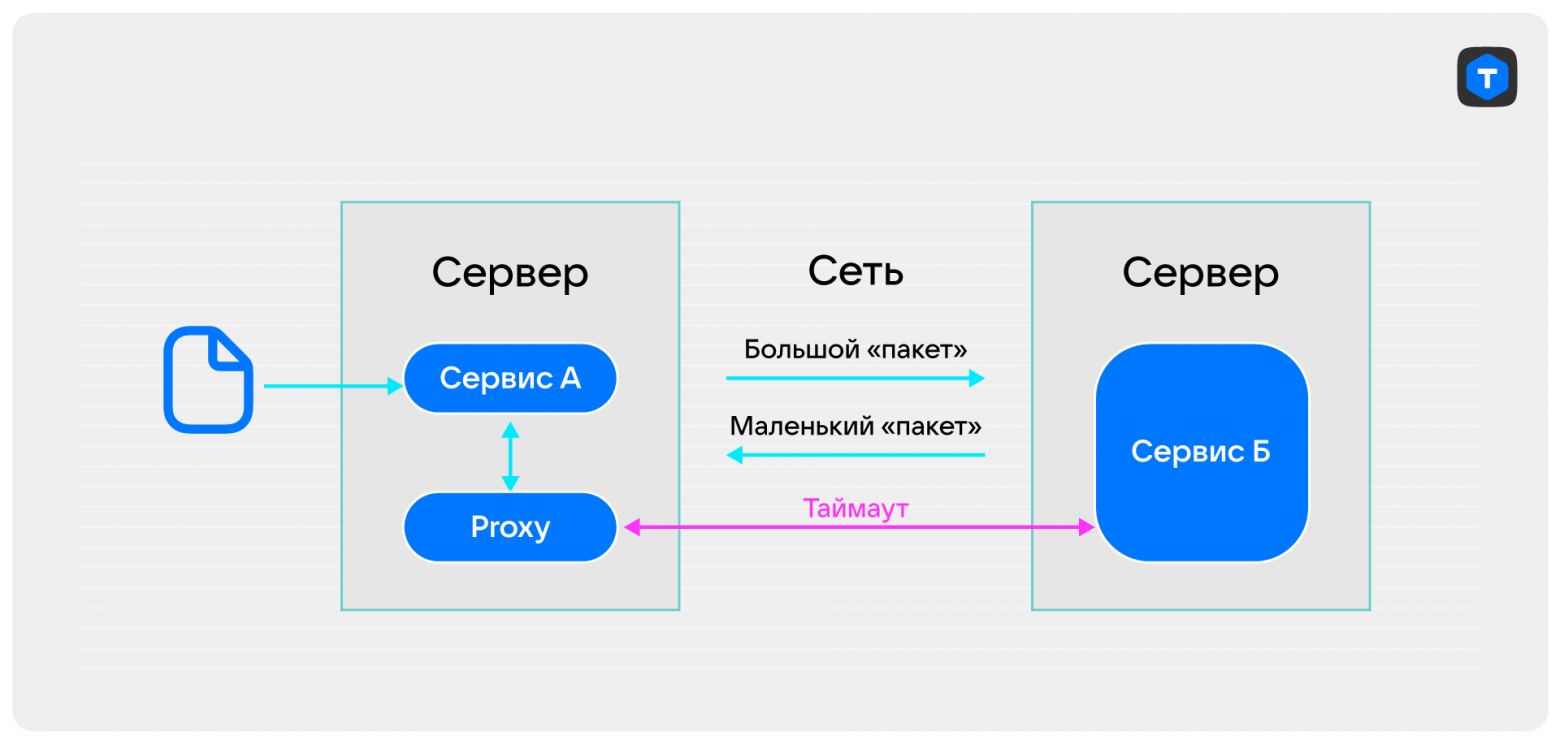
Представляю вам главных героев нашей истории — сервис А и сервис Б. Отношения между ними можно описать следующим образом: сервис А получает от клиента сообщение, дальше через локальную прокси (стоит на той же машине, что и сервис А) отправляет его сервису Б по сети и с нетерпением ожидает ответа в течение установленного таймаута. Сообщения от сервиса А могут быть различного объема — от сотен килобайт до десятков мегабайт. Ответ же от сервиса Б всегда скудный и сухой, и укладывается в несколько десятков килобайт.
Все было гладко в этом общении, пока в какой-то момент не сработал алерт, что сервис Б начал запаздывать с ответом и перестал укладываться в таймаут. С течением времени такие алерты стали появляться все чаще и чаще. Взволнованный сервис А обратился в детективное агентство с целью провести расследование, почему сервис Б не хочет с ним общаться.
Ложный след
Итак, мы представили действующих лиц и описали завязку. Настало время кого-то подозревать. Первым очевидным подозреваемым стал сервис Б.
Опишем его портрет: Б — большой сервис (в простонародье — «монолит»). Его деятельность можно сравнить с обязанностями рецензента научной работы: принять «работу», проанализировать (запуск бизнес-логики) и выдать свое заключение по ней.
Был проведен допрос сервиса Б через grep логов. Обнаружилось, что в подавляющем большинстве случаев подозреваемый работает корректно, но иногда наблюдались отклонения в поведении — аномалии, связанные со временем работы. Детальное изучение аномалий показало, что проблема проявляется только на сообщениях, объем которых измеряется десятками мегабайт. На первый взгляд, самая очевидная причина — сервис зависает где-то в недрах бизнес-логики и не укладывается в отведенный таймаут.
И каково же было наше удивление, когда мы все так же по логам обнаружили, что львиная доля времени тратится на чтение сообщения от сервиса А. Это было первым и далеко не последним сюрпризом в нашем расследовании.
Число подозреваемых стало увеличиваться:
Сервис Б некорректно читает сообщения;
Прокси некорректно отправляет данные;
Проблема с сетью.
Проблемы во взаимодействии между сервисом А и прокси мы сразу отмели: логи подтверждали, что на этом участке цепи тратится минимум времени.
Допрос подозреваемых
Мы решили до конца разобраться с сервисом Б, прежде чем переходить к другим подозреваемым. Для этого нам пришлось более плотно познакомится с его серверной частью.
Сервис Б написан на С++, серверная часть однопоточная, для приема сообщений использует под капотом boost: asio. Сервер принимает соединение от клиента, в течение отведенного таймаута асинхронно вычитывает сообщение (сообщение считываем chunk-ами и складываем их в tmpfs, чтобы долго не блокироваться и давать возможность вычитывать данные из других клиентов). После этого сообщение передается на обработку воркеру.
Было выдвинуто несколько гипотез, но лишь одна казалась состоятельной: размер буфера выбран неэффективно. Это вызывает множество прерываний и загружает процессор, что в свою очередь сказывается на производительности системы и приводит к росту таймаутов.
На dev мы не смогли воспроизвести исходную проблему, поэтому попытались сделать это на машине в песочнице в изолированной боевой сети. Все было тщетно: мы никак не могли увидеть торможение сервиса Б на чтении больших сообщений.
Тогда мы взяли изолированный пул боевых машин (песочница) и на них стали увеличивать размер буфера для считывания chunk-a —, но время считывания значимо не изменялось. Смущал еще и тот факт, что прокси с тем же серверным механизмом бодро считывала сообщение от сервиса А. Поэтому сервис Б был вычеркнут из списка подозреваемых.
Следующей на очереди была прокси, но ее код был настолько тривиальным, что не вызывал подозрений, и интерес следствия к ней быстро остыл.
Оставалась сеть.
Загадка сети
С появлением нового подозреваемого необходимо раскрыть читателю чуть больше деталей, чтобы картина предстала перед ним такой, какой ее видел детектив .
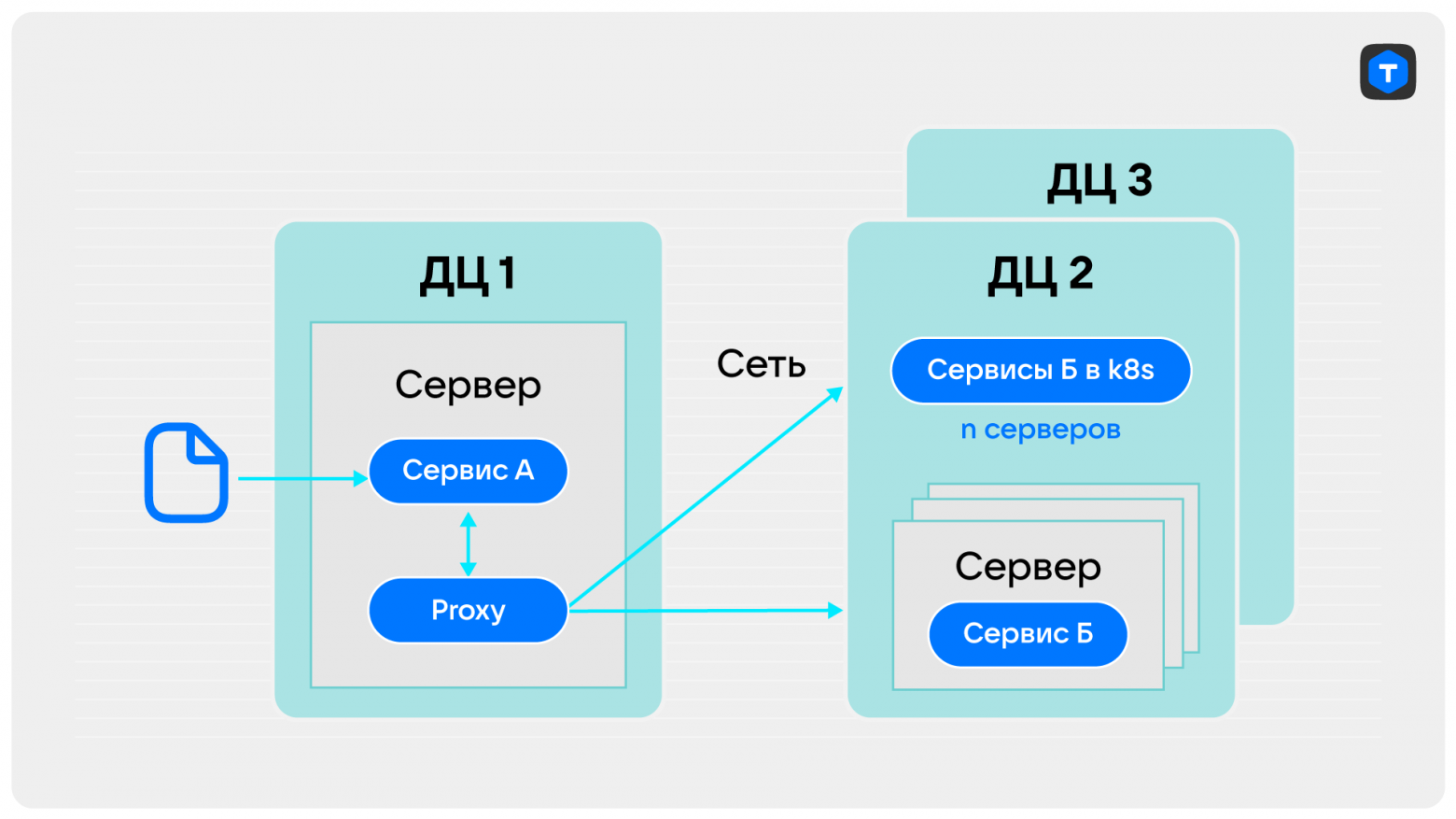
Сервис А получает сообщение от клиента по сети и отправляет его в локальную прокси, которая, как мы помним, стоит на той же машине, что и сервис А. И вот самый напряженный момент: прокси отправляет сообщение в сервис Б. Сервис Б расположен в разных ДЦ, при этом часть его инстансов крутилась на железе, а часть работала в K8S, что вносило еще больше энтропии в расследование. (К слову, сейчас сервис Б к нашему превеликому восторгу уже целиком расположился в k8s: 1200 подов сплошного наслаждения, раскатить которые можно по щелчку пальцев).
Но вернемся к делу. Сейчас читатель может взять паузу и подумать, что бы он сделал в этой ситуации.
Сеть. Сужение круга подозреваемых
Итак, мы принялись локализовывать проблему.
По логам выяснили, что проблема общая. Неважно, крутится ли сервис в k8s или на железе: мы видим торможение на считывании сообщения и там, и там. Это значит, что из рассмотрения можно выкинуть оверхед виртуализации на работу с сетью.
Проверили, нет ли корреляции проблемы с ДЦ. Корреляции обнаружено не было: проблема была во всех ДЦ, где был сервис Б.
Убедились, что есть сервера, на которых проблема воспроизводится (серверов с сервисом А около сотни, с Б — и того больше, так что было важно найти «проблемные сервера»).
После всех этих этапов мы решили взять сервер с сервисом А, сервер с сервисом Б, на котором воспроизводится проблема, и начать более детальное исследование.
Подчеркну важный момент, который был пропущен при тестировании в песочнице. Важно выбирать только сервера, на которых есть проблема. Впоследствии выяснилось, что сервера, которые были в песочнице, не были подвержены проблеме, именно поэтому мы на них ничего и не могли воспроизвести.
Итак, в этой точке начинается новая глава нашего расследования.
Отчаяние
Мы взяли два сервера, на которых наблюдали проблему, и начали думать, что делать. Первое, за что мы взялись, воспользовавшись iperf/iperf3, — это проверка скорости передачи данных между серверами. Результаты запуска не показали никаких проблем, скорость и канал были в норме.
Мы еще раз вернулись к изучению логов и графиков, чтобы понять, не происходят ли торможения в определенное время (кучно) — например, большие пакеты приходят одномоментно в большом количестве, и мы упираемся в канал. Но и тут логи были неумолимы: проблема происходит постоянно, нет никаких закономерностей. Залезли в графики node_exportera и по ним убедились, что запас канала у нас достаточный. Проверили, что никаких аномалий с tcp тоже не наблюдается.
Мы были близки к отчаянию.
Кульминация
В этот момент пришла идея вернуться к истокам и более детально изучить флоу тормозящего пакета. И я начал считать. Получалось следующее: сообщение в 20 МБ от сервиса А до прокси проходило почти мгновенно (еще бы, localhost), а вот от прокси до сервиса Б шло порядка двух секунд. То есть скорость нашего канала должна быть 10 МБ/сек или 80 Мбит/сек — и это в 21 веке, при пропускной способности 1 Гбит/сек…. Что-то тут не так. И это при том, что наши удачные запуски iperf проблем не обнаружили.
Следующим ключевым звеном в расследовании стало подтверждение гипотезы, что даже маленькие письма — например, в 1 МБ — будут так же медленно передаваться. Стало уже почти очевидно, что проблема не связана с размером передаваемого сообщения (на маленьких сообщениях мы укладывались в таймаут, и поэтому не видели проблему).
Чтобы окончательно вычеркнуть из подозреваемых прокси и сервис Б, вместе с нашими коллегами-админами мы провели эксперимент: сгенерировали файл размером в 20 МБ и заслали его с одного сервера на другой с помощью nc.
В этот момент я еще раз убедился, что неправильно проведенный эксперимент дорого обходится: сначала мы допустили ошибку, сохранив файл на жесткий диск, и при отправке уперлись в скорость диска, поэтому получили неверные цифры. Обнаружив эту оплошность, мы исправили ее, записав файл в shm (данная схема максимальна близка к той по которой происходит взаимодействие между нашими сервисами), и отправляли его уже оттуда. И вот он, момент истины: сервис Б точно не виноват — сообщение в 20 МБ передавалось почти две секунды.

Оставалось понять, что же не так с сетью. Мы начали снимать tcpdump и отфильтровали пакеты, которые относились к одному сообщению. Проанализировав tcpdump с помощью wireshark мы подтвердили, что скорость действительно низкая. Параллельно изучая tcpdump, админы начали анализировать настройки TCP стека и заметили, что на машине, на которой крутился сервис А, была выключена опция «tcp_window_scaling» (на серверах Б она была включена), и включили ее. Мы повторили тест — сообщение передавалось почти мгновенно. Мы ликовали — тайна была раскрыта.
Немного про опцию «tcp_window_scaling»: она позволяет более эффективно утилизировать пропускную способность. По умолчанию размер окна не может превысить 65535 байт из-за ограничения TCP заголовка. Опция «tcp_window_scaling» позволяет работать с окном больше 65 КБ за счет добавления коэффициента «масштабирования» (масштабирование окна происходит за счет умножения коэффициента масштабирования на размер окна). Так, например, можно «отмасштабировать» окно вплоть до 1 ГБ. Чтобы «масштабирование» работало, нужно, чтобы опция была включена на стороне отправителя и получателя. Подробнее о том, на что именно влияет опция и как с ней работать, можно почитать тут: https://en.wikipedia.org/wiki/TCP_window_scale_option
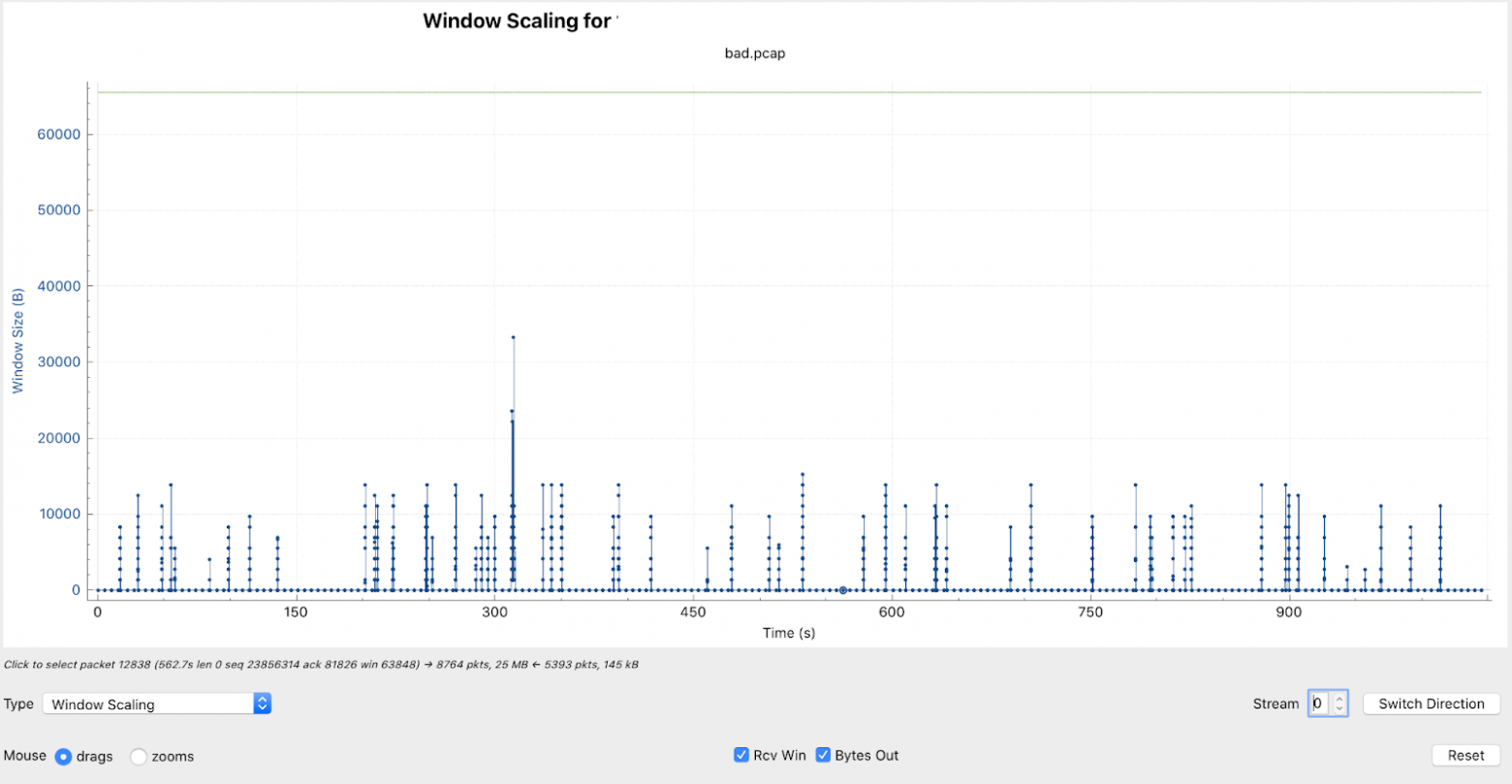 wireshark. График window_size с отключенным tcp_window_scaling
wireshark. График window_size с отключенным tcp_window_scaling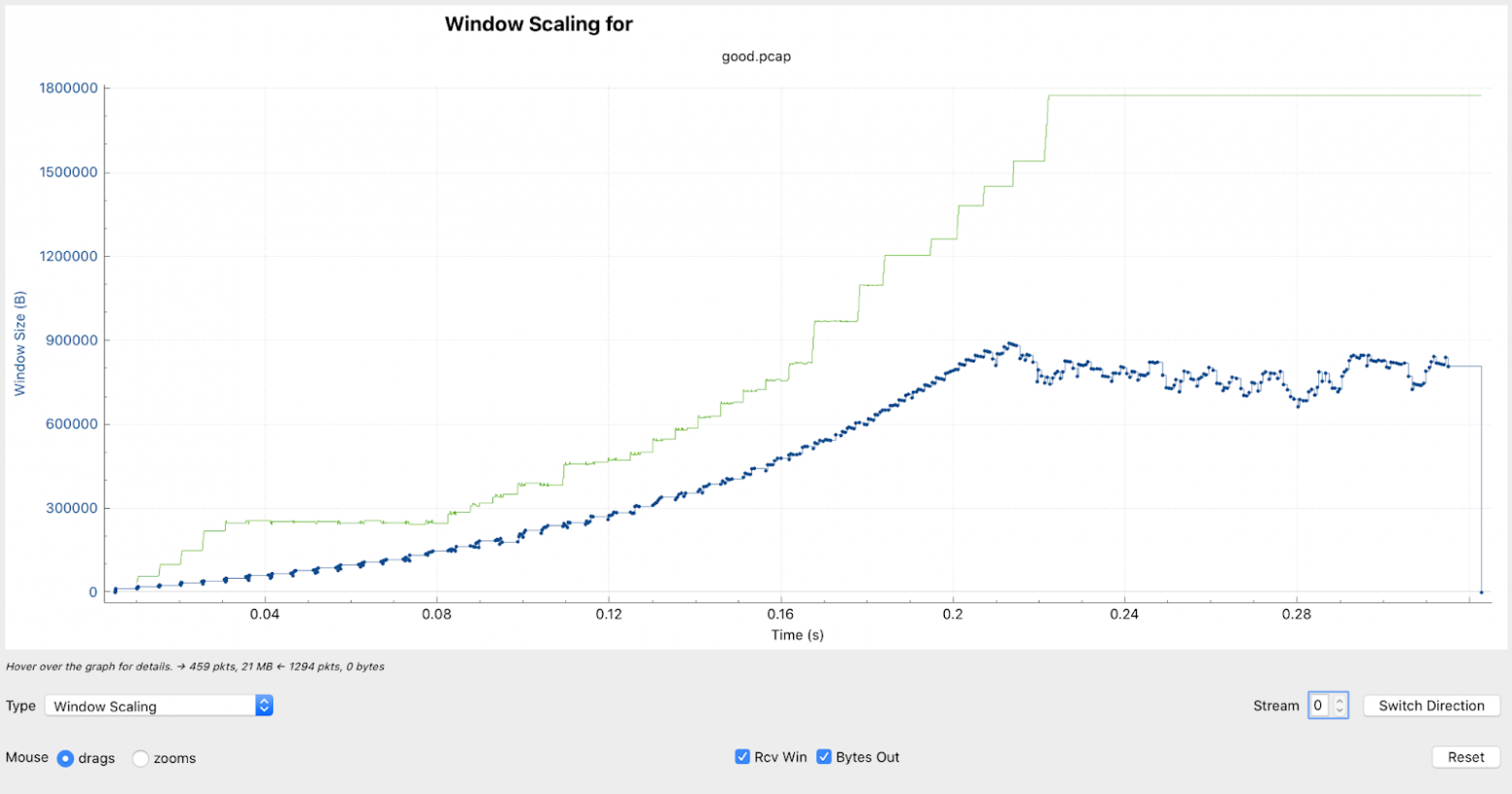 wireshark. График window_size с включенным tcp_window_scaling
wireshark. График window_size с включенным tcp_window_scaling
Оставалось лишь включить эту ручку на всех серверах, что мы и сделали. В результате исправления проблемы сервис А начал получать от нашего «рецензента» — сервиса Б — на 55 тысяч больше «заключений» в сутки .
В заключение
Хочется поблагодарить всех, кто был причастен к расследованию — было реально интересно и драйвово!
Выводы для себя: пытайся воспроизвести проблему в dev, если не получилось — всегда бери машины, где ты видишь проблему.
Iperf не всегда показывает проблему. Проведя исследования, мы смогли заметить на iperf деградацию, только когда сервис оказывался в сильно удаленных ДЦ, где был высокий rtt.
