На что способны виртуальные потоки Java в обработке файлов
Привет, Хабр!
Предисловие
Начнем с того, что я не специалист по Java и у меня нет коммерческого опыта на этом языке. Я просто обычный кодер, который по вечерам пилит проекты на Java, а основной мой стек состоит из PHP и смеси Python + Go. В данной статье хочу вам поделиться опытом с использованием виртуальных потоках (Virtual Threads) в обработке файлов.
Ссылки на ресурсы:
Конфигурация машины:
Количество ядер — 8
Частота процессора — 1200MHz
RAM — 32G
Операционная система — Manjaro Linux 6.5.13–7
Версия Java — 21.0.2
Поехали
Мотивация
Одним прекрасным днем, коллега мне подходит и говорит:
Смотри, тут есть один проект (sourcegraph), по сути он дам должен облегчить жизнь, давай развернем и попробуем.
Суть проекта — индексация и поиск по git-проектам (и не только). Но потом оказалось что нет встроенной интеграции с Gitea, а мы как раз его использовали.
И тут я подумал — почему же бы не написать свою собственную поисковую систему, я же все таки программист-велосипедист (но в первых версиях я так и не добавил поддержку Gitea).
Проект
Исходники проекта — FugitiveDarkness (в описание предоставлена документация по запуску проекта).
Суть проекта очень проста — реализация git команды git grep на Java 21 для поиска по git проектам. В первых версиях я не сильно уделял внимания создание красивого и удобного интерфейса, а больше всего уделял внимания поисковым движкам и проверки гипотезы что это реально создать.
Первый поисковой движок
Первый поисковой движок был основан на библиотеке jgit:
org.eclipse.jgit
org.eclipse.jgit
6.7.0.202309050840-r
И были взяты базовые параметры из команды git grep:
Также были добавлены новые параметры для удобства использования поискового движка:
include-extension-files— включить в поиск файлов, которые входят в список их расширений.
exclude-extension-files — исключить из поиска файлов, которые входят в список их расширений.
pattern-for-include-file — включить в поиск файлов, которые совпадают с регулярным выражением.
pattern-for-exclude-file — исключить из поиска файлов, которые совпадают с регулярным выражением.
Реализация
Ключевым моментом данного поискового движка является следующие параметры:
Обход дерева одной ревизии и чтение двоичного объекта.
Проход регулярного выражения каждой строки каждого blob объекта на поиск совпадения
Упрощенная реализация:
void read() {
try (Git git = Git.open("/full/path/repository")) {
Repository repository = git.getRepository();
try (ObjectReader objectReader = repository.newObjectReader()) {
// Получаем последнюю ревизию
ObjectId commitId = repository.resolve(Constants.HEAD)
revWalk(objectReader, commitId);
}
}
}
void revWalk(ObjectReader objectReader, ObjectId commitId) {
try (RevWalk revWalk = new RevWalk(objectReader)) { // Обход графика фиксации
try (TreeWalk treeWalk = new TreeWalk(objectReader)) {
RevCommit commit = revWalk.parseCommit(commitId);
CanonicalTreeParser treeParser = new CanonicalTreeParser();
treeParser.reset(objectReader, commit.getTree());
while (treeWalk.next()) {
AbstractTreeIterator it = treeWalk.getTree(treeIndex, AbstractTreeIterator.class);
ObjectId objectId = it.getEntryObjectId();
ObjectLoader objectLoader = objectReader.open(objectId);
readObject(objectLoader.openStream());
}
}
}
}
void readObject(InputStream input stream) {
try (final BufferedReader buf = new BufferedReader(stream)) {
for (String line; (line = buf.readLine()) != null; ) {
// Далее выполняется поиск совпадений у каждой строки по регулярному выражению
}
}
}Полный код данного функционала предоставлен в реализации класса SearchEngineJGitGrepImpl, пакета fugitive-darkness-provider-git.
Но данный функционал как оказалось хорошо подходит только для небольших проектах.
Тестирование
Немного статистики и тестирования поискового движка:
Скрипты для подсчета
Найти количество файлов:
find ./ -type f | wc -lНайти общее количество строк во всех файлах:
( find ./ -type f -print0 | xargs -0 cat ) | wc -lПаттерн регулярного выражения (C|c)ore на котором мы будем тестировать движок.
Проект tiangolo/fastapi
Ссылка на проект.
Базовая информация:
После небольшого разогрева jvm выдал следующие результаты. Скорость выполнения 0.45с:

Результат выполнения поиска на проекте tiangolo/fastapi
Проект go-giea/gitea
Ссылка на проект.
Базовая информация:
После небольшого разогрева jvm выдал следующие результаты. Скорость выполнения 2с:

Результат выполнения поиска на проекте go-giea/gitea
Проект gitlabhq/gitlabhq
Ссылка на проект.
Базовая информация:
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 18.7с, уже начинает немного тормозить:

Результат выполнения поиска на проекте gitlabhq/gitlabhq
Проект openjdk/jdk
Ссылка на проект.
Базовая информация:
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 42.8с, уже начинает тормозить, я бы сказал даже бы очень:

Результат выполнения поиска на проекте openjdk/jdk
Проблемы уже начинаются при больших репозиториев и движок не выдерживает нагрузки.
Возможно я где-то упустил момент и пакет jgit предоставляет функционал для реализации параллельной обработки обхода дерева фиксации (буду очень признателен если сообщите что я плохо изучил документацию).
А потом я понял что пишу на Java 21…
Новый поисковой движок
В Java 21 подвезли виртуальные потоки (если быть еще точнее, то подвезли в Java 19 JEP 425) JEP 444 и было прописано следующее:
… Virtual threads are suitable for running tasks that spend most of the time blocked, often waiting for I/O operations to complete
… single JVM might support millions of virtual threads.
И тут я подумал, почему бы не проверить и реализовать новый поисковой движок основанный на виртуальных потоках и так ли это, что они отлично подходят для не длительных I/O операциях. Но тут появились следующие сомнения:
Будут ли сборщики мусора нормально очищать кучу при интенсивной работе с I/O операциями в виртуальных потоках (по умолчанию уборщик мусора стоит G1, возможно в данном случае будет уместен и параллельная обработка мусора — возможно это будет разобрано в следующей части), так как ресурс процессора будет занят практически всегда 100% — мое первое предположение.
Как раз мы и проверим!
Реализация
Механизм нового поискового движка на самом деле очень прост — выдать каждому виртуальному потоку по одному файлу и запустить разом (обратная совместимость старого поискового движка осталась и принцип работы практически идентичен).
Полный код данного функционала предоставлен в реализации класса SearchEngineIOGitGrepImpl, пакета fugitive-darkness-provider-git.
За создание и запуск виртуальных потоков будет отвечать Executors с методом newVirtualThreadPerTaskExecutor:
public void call() {
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
...
}
}Далее мы должны создать задачи для обработки каждого отдельного файла:
public void call(Collection sources) {
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
List> callables = new ArrayList<>();
sources.forEach(source -> {
callables.add(new SearchIOFileCallable(source));
});
}
} Исходники класса SearchIOFileCallable.
И далее мы должны запустить через метод invokeAll и ждать выполнения.
public void call(Collection sources) {
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
List> callables = new ArrayList<>();
sources.forEach(source -> callables.add(new SearchIOFileCallable(source)));
executor.invokeAll(callables);
}
} Вот так все просто!
Я скрыл реализации самого поискового движка и остановился только на реализации и запуска виртуальных потоках (чтобы не было слишком много кода, также прикрепил ссылки к исходникам проектам и к файлам движкам).
Тестирование
Тестировать будем на двух достаточно крупных проектах по нарастающее: проект openjdk/jdk и gitlabhq/gitlabhq, а также на tiangolo/fastapi и go-giea/gitea, с тем же регулярным выражением (C|c)ore (базовые параметры проект те же, что и при тестирование первого поиского движка).
Проект tiangolo/fastapi
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 0.2с, практически в 2 раза быстрее!

Результат выполнения поиска на проекте tiangolo/fastapi
Небольшой статистики профилирования:
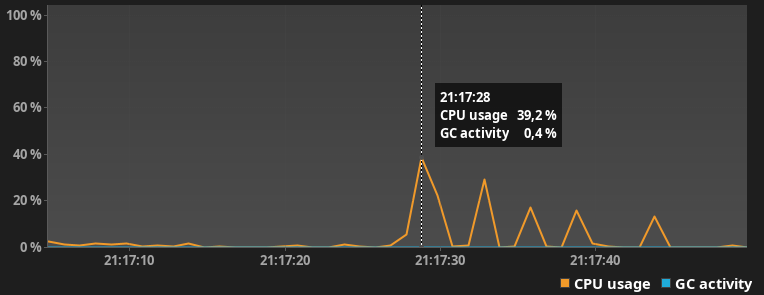
Нагрузка на CPU

Размер выделенной и используемой кучи
Проект go-gitea/gitea
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 0.6с, практически в 3 раза быстрее!

Результат выполнения поиска на проекте go-giea/gitea
Небольшой статистики профилирования:
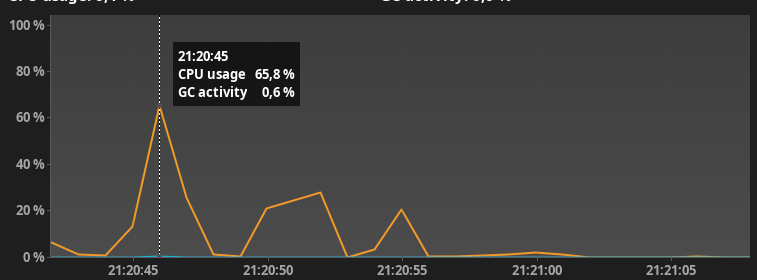
Нагрузка на CPU
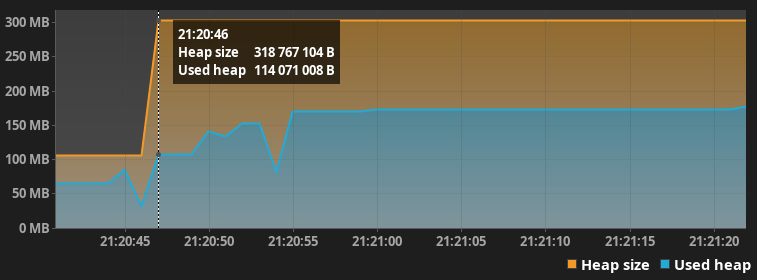
Размер выделенной и используемой кучи
Проект gitlabhq/gitlabhq
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 5.2с, практически в 3.5 раза быстрее!

Результат выполнения поиска на проекте gitlabhq/gitlabhq
Небольшой статистики профилирования:
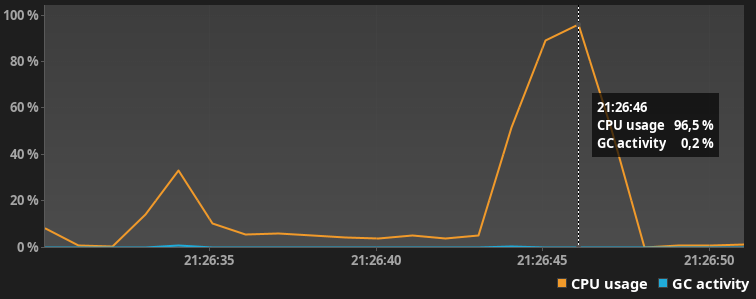
Нагрузка на CPU
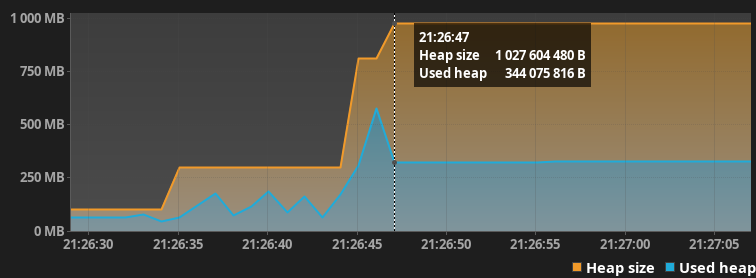
Размер выделенной и используемой кучи
Проект openjdk/jdk
После небольшого разогрева jvm выдал следующие результаты со следующим. Скорость выполнения 10.8с, практически в 4 раза быстрее! (все равно медленнее, хочется быстрее)

Результат выполнения поиска на проекте openjdk/jdk
Небольшой статистики профилирования:

Нагрузка на CPU
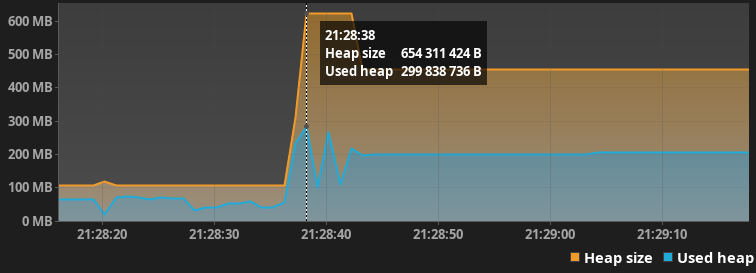
Размер выделенной и используемой кучи
Куча почему-то в данном случае выросла только в 6 раз, хотя количество файлов и суммарное количество строк составляет намного больше чем в проекте gitlabhq/gitlabhq.
Как оказалось ресурс процессора не всегда занят на 100% и сборщик мусора справляется со своей задачей. Возможно ситуация изменится если проекты будут очень огромных размеров и будут в себе содержать сотни тысяч файлов и будут все время занимать весь ресурс процесс.
Немного полезной информации
Если вы собираете статистику при помощи JFR Java Flight Recorder (для того чтобы его включить требуется установить флаг при запуске программы — XX: StartFlightRecording), то по умолчанию события для регистрации виртуальных потоков отключены. Для того чтобы их включить требуется указать следующие параметры:
Итоги
Можем сделать следующий вывод — виртуальные потоки и в правду подходят для не длительных I/O операций и очень хорошо работают.
Возможно в следующей части мы поэкспериментируем с разными средами исполнения Java — например как Docker с ограниченными ресурсами и поработаем с настройкой конфигурации Java для производительности (такие как — выбор оптимального уборщика мусора, кучи и тд) и проверим как будут работать в данном случае виртуальные потоки и будет больше статистика как работает JVM!
Так что попробуем выжать все соки из виртуальных потоков!
Ссылки на ресурсы:
Всем спасибо!
