Мультимодельные СУБД — основа современных информационных систем?
Современные информационные системы достаточно сложны. Не в последнюю очередь их сложность обусловлена сложностью обрабатываемых в них данных. Сложность же данных зачастую заключается в многообразии используемых моделей данных. Так, например, когда данные становятся «большими», одной из доставляющих неудобства характеристик считается не только их объем («volume»), но и их разнообразие («variety»).
Если вы пока не находите изъяна в рассуждениях, то читайте дальше.

Polyglot persistence
Сказанное выше приводит к тому, что порою в рамках даже одной системы приходится для хранения данных и решения различных задач по их обработке использовать несколько различных СУБД, каждая из которых поддерживает свою модель данных. С легкой руки М. Фаулера, автора ряда известных книг и одного из соавторов Agile Manifesto, такая ситуация получила название многовариантного хранения («polyglot persistence»).
Фаулеру принадлежит и следующий пример организации хранения данных в полнофункциональном и высоконагруженном приложении в сфере электронной коммерции.

Пример этот, конечно, несколько утрированный, но некоторые соображения в пользу выбора той или иной СУБД для соответствующей цели можно найти, например, здесь.
Понятно, что быть служителем в таком зоопарке нелегко.
- Объем кода, выполняющего сохранение данных, растет пропорционально числу используемых СУБД; объем кода, синхронизирующего данные, — хорошо если не пропорционально квадрату этого числа.
- Кратно числу используемых СУБД возрастают затраты на обеспечение enterprise-характеристик (масштабируемости, отказоустойчивости, высокой доступности) каждой из используемых СУБД.
- Невозможно обеспечить enterprise-характеристики подсистемы хранения в целом — особенно транзакционность.
С точки зрения директора зоопарка все выглядит так:
- Кратное увеличение стоимости лицензий и техподдержки от производителя СУБД.
- Раздутие штата и увеличение сроков.
- Прямые финансовые потери или штрафные санкции из-за несогласованности данных.
Короче говоря, происходит значительный рост совокупной стоимости владения системой. Есть ли из ситуации «многовариантного хранения» какой-то выход?
Мультимодельность
Термин «многовариантное хранение» вошел в обиход в 2011 году. Осознание проблем подхода и поиск решения заняли несколько лет, и к 2015 году устами аналитиков Gartner ответ был сформулирован:
- Из «Market Guide for NoSQL DBMSs — 2015»:
Будущее СУБД, их архитектур и способов использования — мультимодельность.
- Из «Magic Quadrant for ODBMS — 2016»:
Ведущие операционные СУБД будут предлагать несколько моделей — реляционную и нереляционные — в составе единой платформы.
И похоже, что на этот раз аналитики Gartner не ошиблись. Если зайти на страницу с основным рейтингом СУБД на DB-Engines, можно увидеть, что большая часть его лидеров позиционирует себя именно как мультимодельные СУБД. То же можно увидеть и на странице с любым частным рейтингом.
В таблице ниже приведены СУБД — лидеры в каждом из частных рейтингов, заявляющие о своей мультимодельности. Для каждой СУБД указаны первоначальная поддерживаемая модель (бывшая когда-то единственной) и наряду с ней модели, поддерживаемые сейчас. Также перечислены СУБД, позиционирующие себя как «изначально мультимодельные», не имеющие по заявлениям создателей какой-либо первоначальной унаследованной модели.
Далее для каждого из этих классов мы покажем, как реализуется поддержка нескольких моделей в СУБД, относящихся к этому классу. Наиболее важными будем считать реляционную, документную и графовую модели, и на примере конкретных СУБД показывать, как реализуются «недостающие».
Звездочками в таблице помечены утверждения, требующие оговорок:
- СУБД PostgreSQL не поддерживает графовую модель данных, однако ее поддерживает такой продукт на ее основе, как, например, AgensGraph.
- Применительно к MongoDB правильнее говорить скорее о наличии графовых операторов в языке запросов (
$lookup,$graphLookup), чем о поддержке графовой модели, хотя, конечно, их введение потребовало некоторых оптимизаций на уровне физического хранения в направлении поддержки графовой модели. - Применительно к Redis имеется в виду расширение RedisGraph.
Мультимодельные СУБД на основе реляционной модели
Ведущими СУБД в настоящее время являются реляционные, и прогноз Gartner нельзя было бы считать сбывшимся, если бы РСУБД не демонстрировали движения в направлении мультимодельности. И они демонстрируют. К слову, соображения о том, что мультимодельная СУБД подобна швейцарскому ножу, которым ничего нельзя сделать хорошо, можно направлять сразу Ларри Эллисону.
Автору, однако, больше нравится реализация мультимодельности в Microsoft SQL Server, на примере которого и будет вестись рассказ.
Документная модель в MS SQL Server
О том, как в MS SQL Server реализована поддержка документной модели, на Хабре уже было две отличных статьи, поэтому ограничимся кратким пересказом и комментарием:
Способ поддержки документной модели в MS SQL Server достаточно типичен для реляционных СУБД: JSON-документы предлагается хранить в обычных текстовых полях. Поддержка документной модели заключается в предоставлении специальных операторов для разбора этого JSON:
JSON_VALUEдля извлечения скалярных значений атрибутов,JSON_QUERYдля извлечения поддокументов.
Вторым аргументом обоих операторов является выражение в JSONPath-подобном синтаксисе.
Абстрактно можно сказать, что хранимые таким образом документы не являются в реляционной СУБД «сущностями первого класса», в отличие от кортежей. Конкретно в MS SQL Server в настоящее время отсутствуют индексы по полям JSON-документов, что делает затруднительными операции соединения таблиц по значениям этих полей и даже выборку документов по этим значениям. Впрочем, возможно создать по такому полю вычислимый столбец и индекс по нему.
Дополнительно MS SQL Server предоставляет возможность удобно конструировать JSON-документ из содержимого таблиц с помощью оператора FOR JSON PATH — возможность, в известном смысле противоположную предыдущей, обычному хранению. Понятно, что какой бы быстрой ни была РСУБД, такой подход противоречит идеологии документных СУБД, по сути хранящих готовые ответы на популярные запросы, и может решать лишь проблемы удобства разработки, но не быстродействия.
Наконец, MS SQL Server позволяет решать задачу, обратную конструированию документа: можно разложить JSON по таблицам с помощью OPENJSON. Если документ не совсем плоский, потребуется использовать CROSS APPLY.
Графовая модель в MS SQL Server
Поддержка графовой (LPG) модели реализована в Microsoft SQL Server тоже вполне предсказуемо: предлагается использовать специальные таблицы для хранения узлов и для хранения ребер графа. Такие таблицы создаются с использованием выражений CREATE TABLE AS NODE и CREATE TABLE AS EDGE соответственно.
Таблицы первого вида сходны с обычными таблицами для хранения записей с тем лишь внешним отличием, что в таблице присутствует системное поле $node_id — уникальный в пределах базы данных идентификатор узла графа.
Аналогично, таблицы второго вида имеют системные поля $from_id и $to_id, записи в таких таблицах понятным образом задают связи между узлами. Для хранения связей каждого вида используется отдельная таблица.
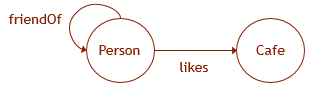 Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
CREATE TABLE Person (
ID INTEGER NOT NULL,
name VARCHAR(100)
) AS NODE;
CREATE TABLE Cafe (
ID INTEGER NOT NULL,
name VARCHAR(100),
) AS NODE;
CREATE TABLE likes (
rating INTEGER
) AS EDGE;
CREATE TABLE friendOf
AS EDGE;
ALTER TABLE likes
ADD CONSTRAINT EC_LIKES CONNECTION (Person TO Cafe);Основная специфика таких таблиц заключается в том, что в запросах к ним возможно использовать графовые паттерны с Cypher-подобным синтаксисом (впрочем,»*» и пр. пока не поддерживаются). Можно также предположить, что механизм хранения данных в этих «таблицах» отличен от механизма хранения данных обычных таблиц и оптимизирован для выполнения подобных графовых запросов.
SELECT Cafe.name
FROM Person, likes, Cafe
WHERE MATCH (Person-(friendOf)-(likes)->Cafe)
AND Person.name = 'John';Более того, довольно трудно при работе с такими таблицами эти графовые паттерны не использовать, поскольку в обычных SQL-запросах для решения аналогичных задач потребуется предпринимать дополнительные усилия для получения системных «графовых» идентификаторов узлов ($node_id, $from_id, $to_id; по этой же причине запросы на вставку данных не приведены здесь как излишне громоздкие).
Подводя итог описанию реализаций документной и графовой моделей в MS SQL Server, я бы отметил, что подобные реализации одной модели поверх другой не кажутся удачными в первую очередь с точки зрения языкового дизайна. Требуется расширять один язык другим, языки не вполне «ортогональны», правила сочетаемости могут быть довольно причудливы.
Мультимодельные СУБД на основе документной модели
В этом разделе хочется проиллюстрировать реализацию мультимодельности в документных СУБД на примере не наиболее популярной MongoDB (как было сказано, в ней есть лишь условно графовые операторы $lookup и $graphLookup, не работающие к тому же на шардированных коллекциях), а на примере более зрелой и «энтерпрайзной» СУБД MarkLogic.
Итак, пусть коллекция содержит набор XML-документов следующего вида (хранить JSON-документы MarkLogic тоже позволяет):
John
Smith
Реляционная модель в MarkLogic
Реляционное представление коллекции документов можно создать с помощью шаблона отображения (содержимым элементов value в примере ниже может быть произвольный XPath):
/Person
Person
SSN
@SSN
string
name
name
surname
surname
К созданному представлению можно адресовать SQL-запрос (например, через ODBC):
SELECT name, surname FROM Person WHERE name="John"К сожалению, созданное с помощью шаблона отображения реляционное представление доступно только для чтения. При обработке запроса к нему MarkLogic попытается использовать документные индексы. Прежде в MarkLogic были и ограниченные реляционные представления, целиком основанные на индексах и доступные на запись, но сейчас они считаются deprecated.
Графовая модель в MarkLogic
С поддержкой графовой (RDF) модели все обстоит примерно так же. С помощью опять-таки шаблона отображения можно создать RDF-представление коллекции документов из примера выше:
/Person
PREFIX
"http://example.org/example#"
sem:iri( $PREFIX || @SSN ) sem:iri( $PREFIX || surname )
sem:iri( $PREFIX || @SSN ) sem:iri( $PREFIX || name )
К полученному RDF-графу можно адресовать SPARQL-запрос:
PREFIX :
SELECT ?name ?surname {
:631803299804 :name ?name ; :surname ?surname .
} В отличие от реляционной, графовую модель MarkLogic поддерживает еще двумя другими способами:
- СУБД может быть полноценным отдельным хранилищем RDF-данных (триплеты в нем будут называться managed в противоположность описанным выше extracted).
- RDF в специальной сериализации может быть попросту вставлен в XML- или JSON-документы (и триплеты тогда будут называться unmanaged). Вероятно, это такая альтернатива механизмам
idrefи пр.
Хорошее представление о том, как «на самом деле» все устроено в MarkLogic, дает Optic API, в этом смысле оно низкоуровневое, хотя назначение его скорее обратное — попробовать абстрагироваться от используемой модели данных, обеспечить согласованную работу с данными в различных моделях, транзакционность и пр.
Мультимодельные СУБД «без основной модели»
На рынке также представлены СУБД, позиционирующие себя как изначально мультимодельные, не имеющие никакой унаследованной «основной» модели. К их числу относятся ArangoDB, OrientDB (c 2018 года компания-разработчик принадлежит SAP) и CosmosDB (сервис в составе облачной платформы Microsoft Azure).
На самом деле «основные» модели в ArangoDB и OrientDB есть. Это в том и в другом случае собственные модели данных, являющиеся обобщениями документной. Обобщения заключаются в основном в облегчении возможности производить запросы графового и реляционного характера.
Эти модели являются в указанных СУБД единственно доступными для использования, для работы с ними предназначены собственные языки запросов. Безусловно, такие модели и СУБД перспективны, однако отсутствие совместимости со стандартными моделями и языками делает невозможным использование этих СУБД в унаследованных системах — замену ими уже используемых СУБД.
Про ArangoDB и OrientDB на Хабре уже есть замечательная статья: JOIN в NoSQL базах данных.
ArangoDB
ArangoDB заявляет поддержку графовой модели данных.
Узлы графа в ArangoDB — это обычные документы, а ребра — документы специального вида, имеющие наряду с обычными системными полями (_key, _id, _rev) системные поля _from и _to. Документы в документных СУБД традиционно объединяются в коллекции. Коллекции документов, представляющих ребра, в ArangoDB называются edge-коллекциями. К слову, документы edge-коллекций — это тоже документы, поэтому ребра в ArangoDB могут выступать также и узлами.
Пусть у нас есть коллекция persons, документы которой выглядят так:
[
{
"_id" : "people/alice" ,
"_key" : "alice" ,
"name" : "Алиса"
},
{
"_id" : "people/bob" ,
"_key" : "bob" ,
"name" : "Боб"
}
]Пусть также есть коллекция cafes:
[
{
"_id" : "cafes/jd" ,
"_key" : "jd" ,
"name" : "Джон Донн"
},
{
"_id" : "cafes/jj" ,
"_key" : "jj" ,
"name" : "Жан-Жак"
}
]Тогда коллекция likes может выглядеть следующим образом:
[
{
"_id" : "likes/1" ,
"_key" : "1" ,
"_from" : "persons/alice" ,
"_to" : "cafes/jd",
"since" : 2010
},
{
"_id" : "likes/2" ,
"_key" : "2" ,
"_from" : "persons/alice" ,
"_to" : "cafes/jj",
"since" : 2011
} ,
{
"_id" : "likes/3" ,
"_key" : "3" ,
"_from" : "persons/bob" ,
"_to" : "cafes/jd",
"since" : 2012
}
]Запрос в графовом стиле на используемом в ArangoDB языке AQL, возвращающий в человекочитаемом виде сведения о том, кому какое кафе нравится, выглядит так:
FOR p IN persons
FOR c IN OUTBOUND p likes
RETURN { person : p.name , likes : c.name }В реляционном стиле, когда мы скорее «вычисляем» связи, а не храним их, этот запрос можно переписать так (к слову, без коллекции likes можно было бы обойтись):
FOR p IN persons
FOR l IN likes
FILTER p._key == l._from
FOR c IN cafes
FILTER l._to == c._key
RETURN { person : p.name , likes : c.name }Результат в обоих случаях будет один и тот же:
[
{ "person" : "Алиса" , likes : "Жан-Жак" } ,
{ "person" : "Алиса" , likes : "Джон Донн" } ,
{ "person" : "Боб" , likes : "Джон Донн" }
]Если кажется, что формат результата выше характерен больше для реляционной СУБД, чем для документной, можно попробовать такой запрос (либо можно воспользоваться COLLECT):
FOR p IN persons
RETURN {
person : p.name,
likes : (
FOR c IN OUTBOUND p likes
RETURN c.name
)
}Результат будет иметь следующий вид:
[
{ "person" : "Алиса" , likes : ["Жан-Жак" , "Джон Донн"] } ,
{ "person" : "Боб" , likes : ["Джон Донн"] }
]OrientDB
В основе реализации графовой модели поверх документной в OrientDB лежит возможность полей документов иметь помимо более-менее стандартных скалярных значений еще и значения таких типов, как LINK, LINKLIST, LINKSET, LINKMAP и LINKBAG. Значения этих типов — ссылки или коллекции ссылок на системные идентификаторы документов.
Присваиваемый системой идентификатор документа имеет «физический смысл», указывая позицию записи в базе, и выглядит примерно так: @rid : #3:16. Тем самым значения ссылочных свойств — действительно скорее указатели (как в графовой модели), а не условия отбора (как в реляционной).
Как и в ArangoDB, в OrientDB ребра представляются отдельными документами (хотя если у ребра нет своих свойств, его можно сделать легковесным, и ему не будет соответствовать отдельный документ).
В формате, приближенном к формату дампа базы OrientDB, данные из предыдущего примера для ArangoDB выглядели бы примерно так:
[
{
"@type": "document",
"@rid": "#11:0",
"@class": "Person",
"name": "Алиса",
"out_likes": [
"#30:1",
"#30:2"
],
"@fieldTypes": "out_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#12:0",
"@class": "Person",
"name": "Боб",
"out_likes": [
"#30:3"
],
"@fieldTypes": "out_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#21:0",
"@class": "Cafe",
"name": "Жан-Жак",
"in_likes": [
"#30:2",
"#30:3"
],
"@fieldTypes": "in_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#22:0",
"@class": "Cafe",
"name": "Джон Донн",
"in_likes": [
"#30:1"
],
"@fieldTypes": "in_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#30:1",
"@class": "likes",
"in": "#22:0",
"out": "#11:0",
"since": 1262286000000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
},
{
"@type": "document",
"@rid": "#30:2",
"@class": "likes",
"in": "#21:0",
"out": "#11:0",
"since": 1293822000000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
},
{
"@type": "document",
"@rid": "#30:3",
"@class": "likes",
"in": "#21:0",
"out": "#12:0",
"since": 1325354400000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
}
]Как мы видим, вершины тоже хранят сведения о входящих и исходящих ребрах. При использовании Document API за ссылочной целостностью приходится следить самому, а Graph API берет эту работу на себя. Но посмотрим, как выглядят обращение к OrientDB на «чистых», не интегрированных в языки программирования, языках запросов.
Запрос, аналогичный по назначению запросу из примера для ArangoDB, в OrientDB выглядит так:
SELECT name AS person_name, OUT('likes').name AS cafe_name
FROM Person
UNWIND cafe_nameРезультат будет получен в следующем виде:
[
{ "person_name": "Алиса", "cafe_name": "Джон Донн" },
{ "person_name": "Алиса", "cafe_name": "Жан-Жак" },
{ "person_name": "Боб", "cafe_name": "Жан-Жак" }
]Если формат результата опять кажется чересчур «реляционным», нужно убрать строку с UNWIND():
[
{ "person_name": "Алиса", "cafe_name": [ "Джон Донн", "Жан-Жак" ] },
{ "person_name": "Боб", "cafe_name": [ "Жан-Жак" ' }
]Язык запросов OrientDB можно охарактеризовать как SQL c Gremlin-подобными вставками. В версии 2.2 появилась Cypher-подобная форма запроса, MATCH:
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe}
RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name
GROUP BY person_nameФормат результата будет таким же, как в предыдущем запросе. Подумайте, что нужно убрать, чтобы сделать его более «реляционным», как в самом первом запросе.
Azure CosmosDB
В меньшей степени сказанное выше об ArangoDB и OrientDB относится к Azure CosmosDB. CosmosDB предоставляет следующие API доступа к данным: SQL, MongoDB, Gremlin и Cassandra.
SQL API и MongoDB API используются для доступа к данным в документной модели. Gremlin API и Cassandra API — для доступа к данным соответственно в графовой и колоночной. Данные во всех моделях сохраняются в формате внутренней модели CosmosDB: ARS («atom-record-sequence»), которая также близка к документной.

Но выбранная пользователем модель данных и используемый API фиксируются в момент создания аккаунта в сервисе. Невозможно получить доступ к данным, загруженным в одной модели, в формате другой модели, что иллюстрировалось бы примерно таким рисунком:

Тем самым мультимодельность в Azure CosmosDB на сегодняшний день представляет собой лишь возможность использовать несколько баз данных, поддерживающих различные модели, от одного производителя, что не решает всех проблем многовариантного хранения.
Мультимодельные СУБД на основе графовой модели?
Обращает на себя внимание тот факт, что на рынке пока нет мультимодельных СУБД, имеющих в основе графовую модель (если не считать мультимодельностью поддержку одновременно двух графовых моделей: RDF и LPG; см. об этом в предыдущей публикации). Наибольшие затруднений вызывает реализация поверх графовой модели документной, а не реляционной.
Вопрос о том, как реализовать поверх графовой модели реляционную, рассматривался еще во времена становления этой последней. Как говорил, например, Дэвид Макговерен:
There is nothing inherent in the graph approach that prevents creating a layer (e.g., by suitable indexing) on a graph database that enables a relational view with (1) recovery of tuples from the usual key value pairs and (2) grouping of tuples by relation type.
При реализации же документной модели поверх графовой нужно иметь в виду, например, следующее:
- Элементы JSON-массива считаются упорядоченными, исходящие из вершины ребра графа — нет;
- Данные в документной модели обычно денормализованы, хранить несколько копий одного и того же вложенного документа все же не хочется, а идентификаторов у поддокументов обычно нет;
- С другой стороны, идеология документных СУБД в том и заключается, что документы являются готовыми «агрегатами», которые не нужно каждый раз строить заново. Требуется обеспечить в графовой модели возможность быстро получить подграф, соответствующий готовому документу.
Автор статьи имеет отношение к разработке СУБД NitrosBase, внутренняя модель которой является графовой, а внешние модели — реляционная и документная — являются её представлениями. Все модели равноправны: практически любые данные доступны в любой из них с использованием естественного для неё языка запросов. Более того, в любом представлении данные могут быть изменены. Изменения отразятся во внутренней модели и, соответственно, в других представлениях.
Как выглядит соответствие моделей в NitrosBase — опишу, надеюсь, в одной из следующих статей.
Надеемся, что общие контуры того, что называется мультимодельностью, стали читателю более-менее ясны. Мультимодельными называются достаточно разные СУБД, и «поддержка нескольких моделей» может выглядеть по-разному. Для понимания того, что называют «мультимодельностью» в каждом конкретном случае, полезно ответить на следующие вопросы:
- Идет ли речь о поддержке традиционных моделей или же о некоей одной «гибридной» модели?
- «Равноправны» ли модели, или же одна из них является подлежащей для других?
- «Безразличны» ли модели друг другу? Могут ли данные, записанные в одной модели, быть прочитанными в другой или даже перезаписаны?
По-видимому, на вопрос об актуальности мультимодельных СУБД уже можно дать положительный ответ, однако интересен вопрос о том, какие именно их разновидности будут более востребованы в ближайшее время. Похоже, более востребованы будут мультимодельные СУБД, поддерживающие традиционные модели, в первую очередь, реляционную; популярность же мультимодельных СУБД, предлагающих новые модели, сочетающие в себе достоинства различных традиционных, — дело более отдаленного будущего.
